
Начинаем рассказывать про некоторые проекты нашего хакатона. Сегодня – бот, выдающий нашему ученику в ФБ несколько популярных твитов с только что взятым на изучение словом. Получился эдакий микро-тьюториал по Chatfuel, удобному и простому инструменту сборки таких ботов из «кубиков».
Начнем с дисклеймера: в этом тексте речь идет не о готовом сервисе школы Skyeng, а о прототипе, собранном на коленке за полтора дня. Мы надеемся, что, возможно, кому-то эта история окажется полезной, а кого-то просто развлечет. А может быть, кого-то вдохновит, и он доведет ее до ума — мы будем только рады, это ложится в нашу концепцию «внешнего контура» экосистемы. Как показывает практика, сразу после хакатона все его участники горят желанием доделать свои проекты, но потом наваливается будничная рутина, и эти желания куда-то пропадают…
Идея
В нашем словаре встречаются примеры использования слов, но все они искусственные – их готовили наши методисты, это академические «правильные» примеры. В реальности люди делают со словами все, что им вздумается, поэтому появилась идея показать примеры такого реального использования из «дикой природы». Например, из Твиттера – там люди пишут что угодно и как угодно, там надо писать короткое сообщение сразу, как наболело. Поэтому они получаются живые, люди не задумываются над строением фраз, и в целом это наиболее приближенный к жизни текстовый формат.
Поэтому мы задумали небольшой проект, который бы при помощи нашего открытого Skyeng API отслеживал добавленные нашим студентом слова для изучения, и выдавал ему в мессенджере популярные твиты, их содержащие. Нам хотелось, чтобы наш продукт работал именно в мессенджере, а не на каком-то отдельном сайте или в отдельном приложении, чтобы пользователю не надо было никуда заходить и ничего устанавливать; нужна была точка, которая у него все время работает и сможет самостоятельно его дергать.
Команда состояла из двух серверных программистов и аналитика, имеющего опыт разработки фронтендов. А сам проект, соответственно, из двух частей – маленького серверного приложения и чат-бота. Общее настроение было – давайте не будем упарываться и соберем что-нибудь простое; в конце концов, это хакатон, совмещенный с корпоративом, надо не забывать про собственное удовольствие.
Твиттер
У Твиттера есть поиск, можно зайти на сайт, вбить слова и увидеть содержащие их твиты. Этот поиск сделан и в виде интерфейса Твиттера, и в виде API. Поисковик достаточно умный, почти как Гугл: он понимает словоформы и составные выражения; например, если вбить cut down, он найдет твиты типа I will cut this monstrosity down, где сами слова разнесены. Для реализации нашей затеи нам было достаточно дергать API Твиттера, передавать в него слова, которые ученик добавил на изучение, брать твиты из выдачи и скидывать их куда-то в мессенджер.
Очевидно, что твитов с такими словами будет по сто миллионов, и нам каким-то образом надо отбирать хорошие. В API есть набор параметров запроса, в том числе тип результата (result_type) – либо самые последние, либо самые популярные, либо все подряд. Мы использовали популярные: нам неважно, что твит старый, нам важно, что он понравился читателям. Параметр count по умолчанию равен 15, мы использовали 100, чтобы добавить разнообразие.
Из них мы выбирали три по параметру favorites_count, т.е. по количеству лайков (механизм расчета популярности Твиттера закрытый, но он в любом случае учитывает множество критериев, которые нам не очень полезны, типа числа подписчиков автора, ретвитов и т.д.). Поскольку на Хакатоне времени было мало, мы решили фиксировать свои параметры именно так, просто некогда было придумывать что-то особо умное и продвинутое. При желании в будущем их можно менять, добавлять пользовательские настройки и т.д.
Сервер
Взяли типовой шаблон серверного проекта PHP-фреймворка Yii 2 и сделали в нем три метода.
1. При регистрации пользователя (получения от чатбота адреса e-mail и токена), создается простая табличка, в которую копируется список значений слов, взятых на изучение. Эта таблица нужна из-за того, что наш внешний API не передает время, когда студент добавил значение в свой словарь. Поэтому:
2. второй метод раз в полчаса ходит на сервер словаря и сравнивает локальный список значений пользователя с тем, что хранится там. При обнаружении добавленных значений, этот метод отправляет их дальше; если новых слов больше трех, случайно выбираются три.
3. Третий метод отправляется в API Твиттера искать по три твита на каждое слово по описанному выше алгоритму и отправляет результаты поиска в API чат-бота.
Бот
Изначально мы рассматривали варианты с отправкой твитов в Фейсбук, Твиттер или Телеграм. Однако для того, чтобы писать в Твиттер, нам бы пришлось делать сайт, где студент мог быть дать разрешение на отправку ему твитов. Это требование Твиттера, все делается с помощью SDK, который надо куда-то встроить, в общем, для MVP это было чересчур. Начали разбираться с доками Телеграма, поняли, что Телеграм-бота надо программировать с нуля, готовых решений нет, это надо было бы тестировать, полезли бы баги… Решили остановиться на ФБ-мессенджере. Определились с архитектурой, согласовали структуру базы и семантику методов API, после чего программисты пошли делать свои сервисы, а аналитик занялся самим ботом.
Использовался Chatfuel – штука, которая позволяет без программирования собрать бота для ФБ-мессенджера (была альтернатива в виде Sequel, но он нам не подошёл, поскольку не позволяет использовать сторонний API). У нее визуальный интерфейс, в котором функционал представлен блоками, внутри которых отдельные действия выглядят как карточки, обрабатываемые по очереди. В Chatfuel есть внутренние переменные, что для нас важно.
Первые два блока, которые видит пользователь при создании нового бота – дефолтные сообщение приветствия и ответ на реплику пользователя, на которую ответ не предусмотрен. Сюда вбили одинаковый текст – предложение ввести e-mail, который использовался для регистрации в Skyeng.
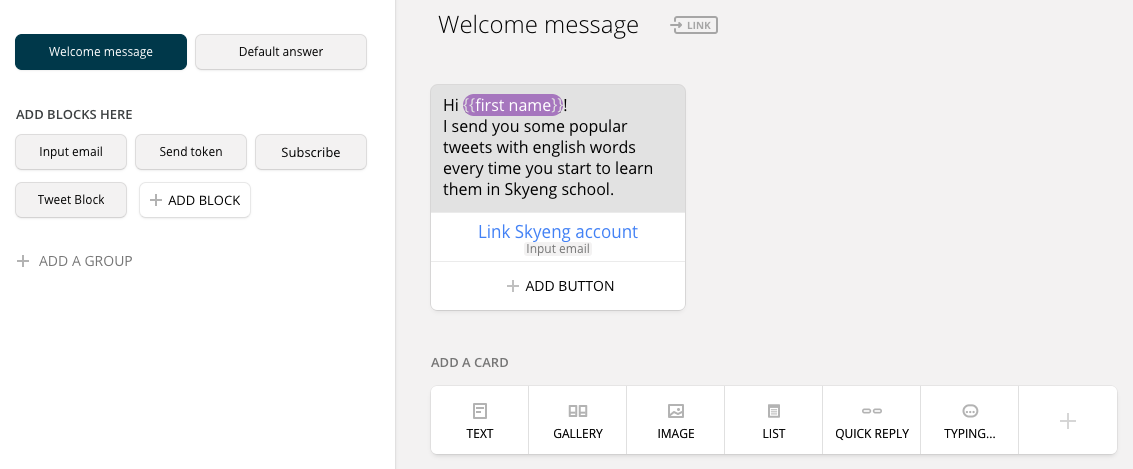
Первый наш кастомный блок – ввод email. Первая карточка этого блока – User input. Она имеет встроенную валидацию, в данном случае проверяет, действительно ли это адрес или что-то совсем другое, после чего адрес сохраняется во внутреннюю переменную, и мы переходим ко второй карточке Go to block, которая, в свою очередь, переносит нас к следующему блоку Send token.
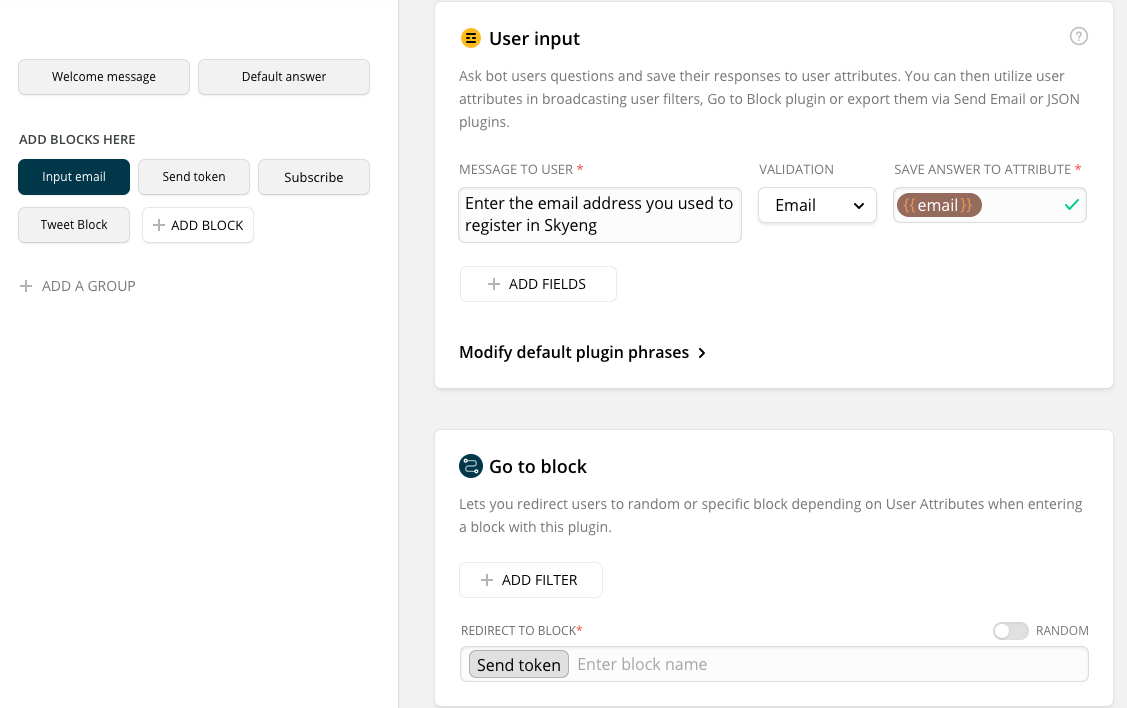
Этот блок вызывает наш внешний API, отправляющий токен на e-mail студента. Первая карточка – «тайпинг» на три секунды, она показывает пользователю активность бота, пока выполняется запрос. Параллельно с ней запускается карточка запроса – JSON API, вызывающая метод нашего внешнего API и передающая ему e-mail студента из переменной.
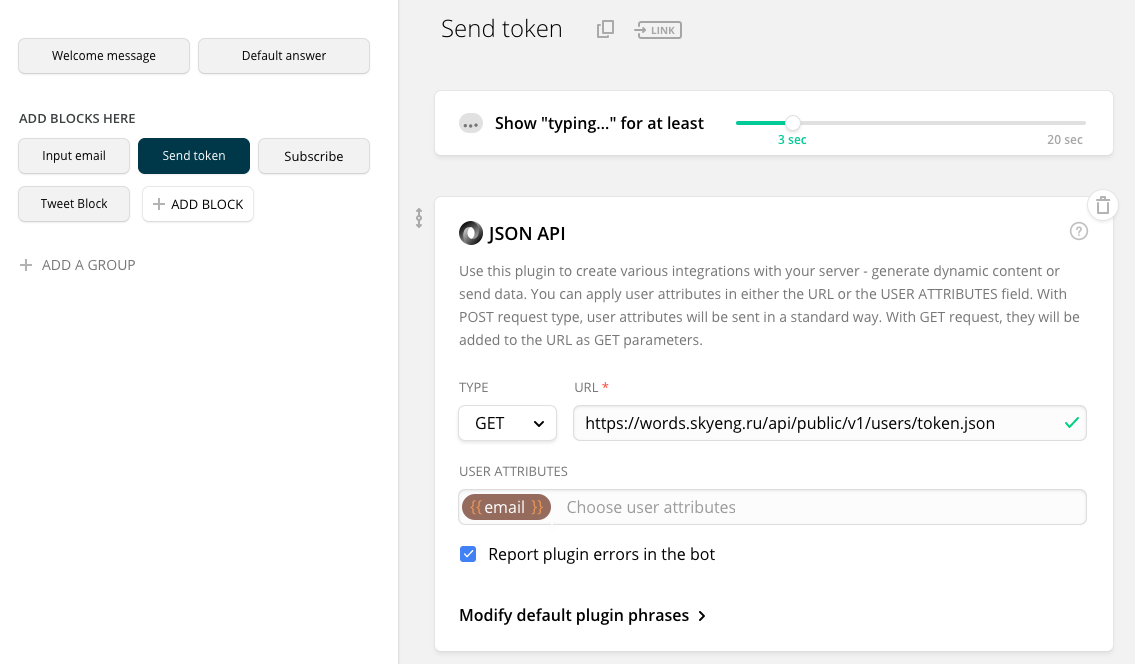
Третья карточка – ввод токена без валидации, с сохранением его в переменную; четвертая – переход к следующему блоку.
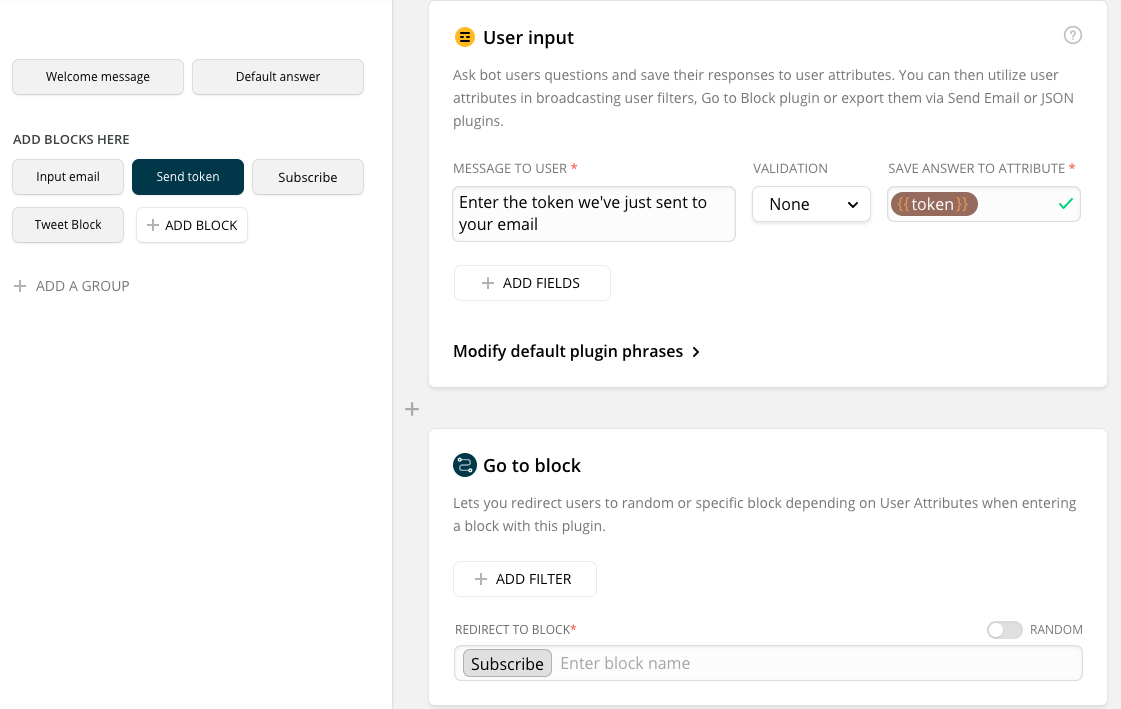
Третий блок – Subscribe, он подписывает пользователя на фид. Здесь опять карточка «тайпинг» (поскольку снова есть запрос, занимающий время), следом – JSON API, где мы передаем нашему новому серверу запрос с e-mail, токеном и идентификатором чата {chatfuel user ID}, ассоциирующий ученика с этим каналом. Этот ID потребуется для вызова Broadcasting API Чатфьюела непосредственно с нашего нового сервера. Получив этот запрос, сервер достает идентификаторы значений слов, находящихся у студента на изучении при помощи другого метода нашего внешнего API, для каждого из них достает слово из нашего словаря, вешает в свое расписание регулярную проверку обновлений и в дальнейшем, при их наличии, сам отправляет твиты в ФБ через Broadcasting API.
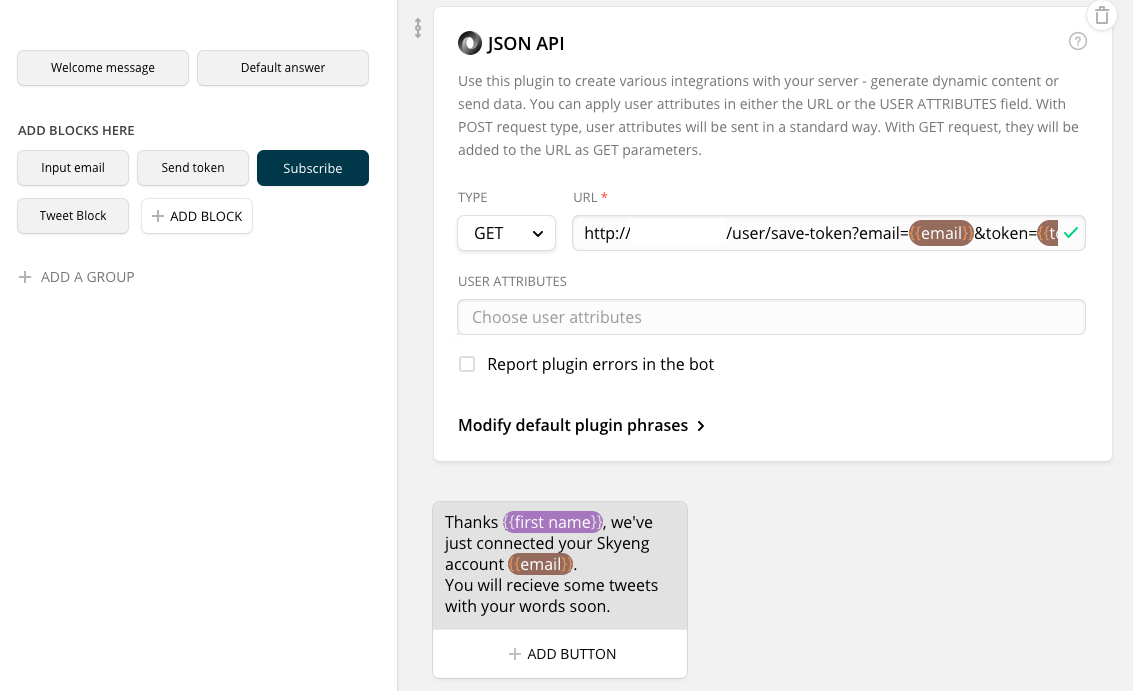
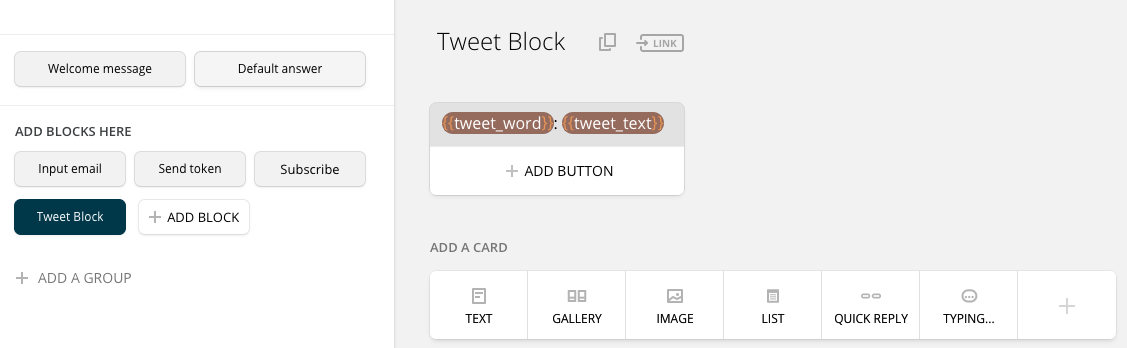
Последний блок выводит эти твиты при получении. Сервер дергает API Chatfuel, передает значения переменных {tweet_word} и {tweet_text}, и бот, получив их, немедленно отправляет сообщение пользователю.
Косяки (куда ж без них)
Никто из нас не имел дела с Chatfuel раньше, мы не знали, что в нем есть Broadcasting API. Поэтому сперва пытались использовать блок RSS, и структура бота была другая – в нем был блок, который подписывает бота на наш RSS и блок, который забирает записи из RSS. Планировалось сделать для каждого юзера уникальный адрес на нашем сервере, по которому выкладывать твиты в виде ленты RSS, а потом импортом их оттуда забирать и пихать в чат.
Мы угробили полдня на то, чтобы это сделать, подключили какую-то серверную PHP библиотеку, которая умеет строить RSS ленту, но она не забиралась. При этом все прекрасно работало с новостной RSS-лентой от vc.ru (взяли ее для тестов), но та же самая лента, точно в том же виде, в том же XML-формате и с HTTP-заголовками, переданная через наш сервер, не отображалась. Почему – так и осталось загадкой, может, у нас сервер не https, может есть еще что-то типа списка доверенных сайтов, но ничего нагуглить не получилось. В итоге нашли в доках про Broadcasting API, и нас постигло озарение: зачем мучиться с XML, когда можно просто передать текст в виде параметра. В результате быстро все собрали, но следы наших RSS-мучений остались в серверном коде.
Довольно много времени потратили на настройку сервера. Сперва подняли на бесплатном сервисе, но оказалось, что он не давал выставлять адрес API наружу. Пришлось просить наших админов, чтобы дали место в нашем облаке Амазон. Но в итоге мы довольно быстро подготовили MVP и успели за два дня хакатона отдохнуть и поразвлекаться.
Что не реализовали, заделы на будущее
Мы договаривались не сидеть ночами, а сделать минимально рабочую версию. Естественно, куча всего осталась на потом:
— нужно поиграться с настройками, чтобы выдавать наиболее полезные твиты. Изначально мы хотели сделать умный фильтр: пробовали вырезать ретвиты, пробовали вырезать твиты со ссылками (потому что это скорее всего пояснение к чему-то, не целостная запись), но довести до ума его не успели: часто при этом Твиттер отдавал слишком мало результатов, поэтому не ко всем словам удавалось находить нужное количество твитов.
— можно упростить логику вычисления новых слов, если добавить во внешний API Words время, когда значение слова было взято на изучение;
— у школы есть свой сервис, который для каждого слова выдает уровень знания языка; если добавить его во внешний API, то можно при помощи него распарсить каждый твит, чтобы понять, все или не все слова соответствуют этому уровню, и предлагать студенту только те твиты, где он, скорее всего, поймет все слова;
— можно было учитывать другую лексику из словаря студента. Это позволило бы выдавать более полезные твиты. В поиск Твиттера можно скормить даже три слова, и он что-то выдаст. Есть два варианта реализации: или составлять все возможные комбинации трех слов из словаря студента и кидать их в поиск Твиттера, после чего смотреть, какой набор лучше сработает; или искать слова по одному, а потом выбирать среди результатов наиболее релевантные;
— есть тонкость, связанная с тем, что наш бот не знает, в каком значении употреблено слово в Твиттере, в результате чего студент учит слово cap как «кепка», а получает твит про Капитана Очевидность; с этим за два дня мы сделать ничего не могли. У команды браузерного расширения есть наработки по контекстному анализу, их можно будет использовать в будущем.
Текущую версию бота можно пощупать здесь: m.me/skyengtweets.
Мы продолжим понемногу рассказывать о проектах хакатона, а пока напоминаем, что находимся в активном поиске клевых людей, готовых влиться в нашу команду!




