Эта статья открывает цикл публикаций, посвященных функционированию центра по мониторингу и реагированию на инциденты информационной безопасности – Security Operations Center (SOC). В них мы будем рассказывать о том, что надо учитывать при создании SOC, о процессе подготовки инженеров мониторинга, регистрации инцидентов и практических кейсах, с которыми сталкивается Solar JSOC.
Цель данных статей не самореклама, а описание практических аспектов в реализации сервисной модели оказания услуг в области информационной безопасности. Первая статья будет иметь вводный характер, но она необходима для погружения в тему, которая все еще является достаточно новой для российского рынка информационной безопасности.
Что такое SOC, чем он отличается от SIEM, и зачем вообще он нужен, я описывать не буду – слишком много статьей в последнее время написано на эту тему. Причем в статьях можно было встретить взгляд с любой стороны: эксперта, вендора SIEM, владельца или сотрудника SOC.
В качестве вводной информации стоит упомянуть статистику по данным исследований, проведенных ФРИИ, а также компаниями Group-IB и Microsoft:
Также хотелось бы упомянуть статистику по нашим клиентам, которая отражается в ежеквартальных отчетах JSOC Security Flash Report:
Если же вспомнить последние публичные инциденты – «Металлинвестбанк», «Русский международный банк», вывод денег через уязвимости SWIFT и атака на энергоотрасль Украины, абсолютно логичной и понятной становится идея о том, что за безопасностью необходимо следить, а инциденты ИБ − выявлять и анализировать.
В качестве одного из наиболее популярных решений последних лет для контроля и выявления инцидентов является SIEM-система, которая становится ядром SOC. Данный выбор, прежде всего, обусловлен значительным объемом задач, которые можно решить с помощью SIEM-системы:
Согласно модели, предложенной HP SIOC, существует несколько уровней зрелости SOC − SOMM (Security Operations Maturity Model):

Рис. 1. Уровни SOMM
К сожалению, большинство компаний как в России, так и в мире, сделав первый шаг на пути к построению собственного Security Operations Center, на нем и останавливается. По оценкам HP, 24% SOC в мире не дотягивают до 1 уровня, и только 30% SOC соответствуют базовому (2) уровню. Статистика распределения уровней SOMM в зависимости от сферы бизнеса компаний, собранная в 13 странах мира (включая Канаду, США, Китай, Великобританию, Германию, ЮАР и др.) такова:

Рис. 2. Распределение уровней SOMM по сферам бизнеса
Наиболее проторенный в России путь – приобрести SIEM-систему для мониторинга инцидентов. По этому пути прошли практически все крупные российские компании. При этом говорить об успешном запуске центра мониторинга и реагирования инцидентов возможно, в лучшем случае, в 5-10%. Что же мешает? Основные сложности при построении собственного SOC наблюдаются в трех направлениях:
Оценка существующей на рынке потребности в создании SOC'ов вкупе с описанными выше нюансами привели нас сначала к идее, а потом и к фактическому построению собственного коммерческого SOC.
Одним из главных вопросов на этапе строительства Security Operations Center для нас был выбор SIEM-системы. Мы сформировали ряд требований к ней:
Свой выбор мы остановили на одном из лидеров в классе SIEM – HP ArcSight и, несмотря на различные сложности в жизни системы, о своем решении ни разу не пожалели.
Вслед за сервисом по мониторингу инцидентов Solar JSOC дополнялся новыми сервисами:
Технологически Solar JSOC − уже давно не только HP ArcSight. SIEM'овское ядро постепенно обрастало различными полезными аддонами и фичами. Были добавлены средство мониторинга трафика и решение класса Security Intelligence Solar inView, которое является:
Одним из основных нововведений последнего года является переход на внешнюю систему кейс-менеджмента. В качестве платформы мы выбрали Kayako, которая оптимально подходит под наши задачи, имеет удобный и гибкий инструмент кастомизации и отличный API.
Важным инструментом в рамках задач по мониторингу и выявлению инцидентов являются репутационные базы различных отечественных и зарубежных вендоров и CERT. Базы могут содержать как сетевые, так и хостовые индикаторы компрометации (IOC) различных вредоносов, либо описывать схему работы злоумышленников. В зависимости от поставляемых данных, мы используем различные инструменты выявления индикаторов: сетевые заносятся в ArcSight для ретроспективного поиска и контроля в будущем, хостовые превращаются в индикаторы сканеров защищенности. Самыми значимыми партнерами в этой области являются FinCERT и Kaspersky Lab.
Интеграция с репутационными базами Kaspersky Threat Intelligence осуществляется через API, разработанный совместно с Kaspersky Lab. Благодаря этому мы получаем наиболее актуальную информацию – база «фидов» обновляется раз в несколько часов, что сопоставимо со скоростью получения новых антивирусных сигнатур (иногда быстрее). Это позволяет оперативно выявлять zero-day вирусы, попадающие в инфраструктуру заказчиков за счет их callback'ов.
Интересным форматом предоставляемой информации являются APT Reports, в которых вендором или CERT'ом описывается хронология атаки, инструментарий, сопутствующее использование уязвимостей и, конечно, цель злоумышленников. Данный формат позволяет нам по-новому взглянуть на точки контроля и детектирования инцидентов, подкрутить существующие или создать новые корреляционные правила.
Используя указанный выше инструментарий, мы сформировали следующие направления оказания сервисов ИБ:

После выбора основной технологической платформы необходимо было решить задачи по созданию инфраструктуры и определить площадку размещения. Опыт наших западных коллег показывает, что целевая доступность архитектуры должна составлять не менее 99,5% (причем с максимальной катастрофоустойчивостью).
При этом принципиальным оставался вопрос географии: collocation возможен только в границах РФ, что исключало возможность использования популярных западных провайдеров. Сюда же наложились естественные вопросы обеспечения ИБ инфраструктуры на всех уровнях доступа. Поэтому было решено обратиться к нашему партнеру Jet Infosystems, и в рамках большого колокейшена для JSOC было выделено несколько стоек в физически изолированном от других серверов фрагменте, где мы смогли развернуть свою архитектуру, одновременно ужесточив уже существующие в рамках ВЦОД профили безопасности. ИТ-инфраструктура развернута в Tier 3 дата-центре, и ее показатели доступности составляют 99,8%. В результате мы смогли выйти на целевые показатели доступности нашего сервиса и получили существенную свободу действий в работе и адаптации системы под себя.
На начальном этапе команда JSOC состояла из 3 человек: двух инженеров мониторинга, закрывающих временной интервал с 8 до 22 часов, и одного аналитика/администратора, который занимался развитием правил. SLA по услуге, обозначенный клиентам, тоже был достаточно мягким: время реакции на обнаруженный инцидент – до 30 минут, время на разбор, подготовку аналитической справки и информирование клиента – до 2 часов. Но, по прошествии первых месяцев работы, мы сделали несколько очень существенных выводов:
Эти выводы существенно повлияли на структуру департамента JSOC в компании Solar Security и помогли сформировать трехуровневую модель реагирования на инциденты. Сейчас подразделение насчитывает уже более 40 человек, имеет сформировавшуюся структуру (см. рис. 4) и включает в себя:

Рис. 4 – Организационная структура JSOC
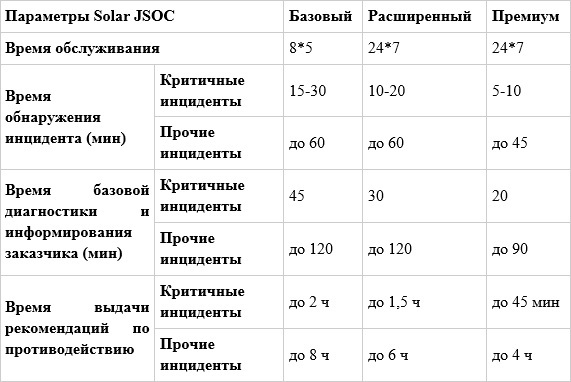
Такая организационная структура позволила нам выйти на целевые показатели SLA:
За последние 4 года развития наш Security Operations Center прошел следующие важные этапы:
2012 год
2013 год
2014 год
2015 год
На этом первая, вводная статья из серии подошла к концу. В ближайших планах – материалы о технических аспектах работы Solar JSOC:
Оставайтесь с нами!
Цель данных статей не самореклама, а описание практических аспектов в реализации сервисной модели оказания услуг в области информационной безопасности. Первая статья будет иметь вводный характер, но она необходима для погружения в тему, которая все еще является достаточно новой для российского рынка информационной безопасности.
Зачем нужен SOC
Что такое SOC, чем он отличается от SIEM, и зачем вообще он нужен, я описывать не буду – слишком много статьей в последнее время написано на эту тему. Причем в статьях можно было встретить взгляд с любой стороны: эксперта, вендора SIEM, владельца или сотрудника SOC.
В качестве вводной информации стоит упомянуть статистику по данным исследований, проведенных ФРИИ, а также компаниями Group-IB и Microsoft:
- Потери экономики РФ от киберпреступности за 2015 год оцениваются в 123,5 млрд рублей.
- 60% российских компаний отметили рост числа киберинцидентов на 75%, а размера ущерба — в два раза.
Также хотелось бы упомянуть статистику по нашим клиентам, которая отражается в ежеквартальных отчетах JSOC Security Flash Report:
- Двукратный рост количества инцидентов информационной безопасности в первом квартале 2016 года по отношению к аналогичному периоду 2015 года.
- Значительный рост инцидентов, связанных с утечками конфиденциальной информации.
- Увеличение критичных инцидентов с 26% до 32% по отношению к общему скоупу.
- Рост числа различных кибергруппировок, работающих по известным схемам мошенничества.
Если же вспомнить последние публичные инциденты – «Металлинвестбанк», «Русский международный банк», вывод денег через уязвимости SWIFT и атака на энергоотрасль Украины, абсолютно логичной и понятной становится идея о том, что за безопасностью необходимо следить, а инциденты ИБ − выявлять и анализировать.
В качестве одного из наиболее популярных решений последних лет для контроля и выявления инцидентов является SIEM-система, которая становится ядром SOC. Данный выбор, прежде всего, обусловлен значительным объемом задач, которые можно решить с помощью SIEM-системы:
- замкнуть инциденты, фиксируемые другими системами самостоятельно, в рамках единого ядра инцидент-менеджмента;
- получить удобный инструмент для поиска необходимых событий, разбора инцидентов, хранения собранных данных;
- выявлять статистические отклонения и медленно развивающиеся инциденты за счет анализа больших интервалов и объемов информации с конкретных средств защиты;
- сопоставлять и коррелировать данные из разных систем, и, как следствие, строить сложные цепочки сценариев по обнаружению инцидентов, «обогащать» информацию в логах одних систем данными из других.
Немного методологии
Согласно модели, предложенной HP SIOC, существует несколько уровней зрелости SOC − SOMM (Security Operations Maturity Model):
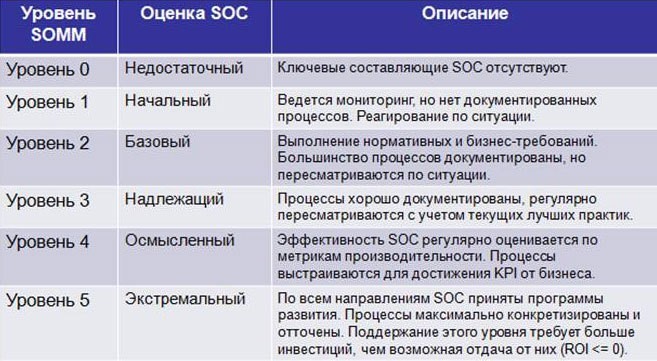
Рис. 1. Уровни SOMM
К сожалению, большинство компаний как в России, так и в мире, сделав первый шаг на пути к построению собственного Security Operations Center, на нем и останавливается. По оценкам HP, 24% SOC в мире не дотягивают до 1 уровня, и только 30% SOC соответствуют базовому (2) уровню. Статистика распределения уровней SOMM в зависимости от сферы бизнеса компаний, собранная в 13 странах мира (включая Канаду, США, Китай, Великобританию, Германию, ЮАР и др.) такова:
Рис. 2. Распределение уровней SOMM по сферам бизнеса
Проблематика собственного SOC
Наиболее проторенный в России путь – приобрести SIEM-систему для мониторинга инцидентов. По этому пути прошли практически все крупные российские компании. При этом говорить об успешном запуске центра мониторинга и реагирования инцидентов возможно, в лучшем случае, в 5-10%. Что же мешает? Основные сложности при построении собственного SOC наблюдаются в трех направлениях:
- Количественная и качественная нехватка персонала. Причины самые различные: от кадрового голода и отсутствия профильных вузов до сложности получения требуемых компетенций. В рамках среднестатистического отдела (департамента) информационной безопасности сегодня работает 3−5 человек, которые должны осуществлять весь цикл работ по обеспечению безопасности компании (от администрирования средств защиты и обеспечения соответствия требованиям регуляторов до постоянного анализа рисков и разработки стратегии развития тематики в компании). Естественно, при такой загрузке уделить должное время задачам SOC практически невозможно.
- Невозможность построения эффективного процесса мониторинга с внутренними SLA. Помимо необходимости выделения персонала, запуск SOC подразумевает создание в подразделении IT-security полноценной дежурной смены, работающей в режиме 12/5 или 24/7, а это от 2 до 5 новых штатных единиц. При этом выделение персонала напрямую связано с необходимостью постоянного контроля кадровой текучки (крайне редко ИБ-специалисты готовы работать в ночной смене), выстраивания процессов и внутреннего контроля качества выполняемых работ.
- Развитие SOC должно осуществляться на постоянной основе: разработка новых сценариев под векторы угроз, подключение новых источников информации, агрегация и использование репутационных баз. Статический SOC совершенно неэффективен, а для динамического развития нужен аналитик. Наличие в штате человека, являющегося архитектором SOC в режиме full time, – большая роскошь даже для крупной компании.
Оценка существующей на рынке потребности в создании SOC'ов вкупе с описанными выше нюансами привели нас сначала к идее, а потом и к фактическому построению собственного коммерческого SOC.
Выбор платформы
Одним из главных вопросов на этапе строительства Security Operations Center для нас был выбор SIEM-системы. Мы сформировали ряд требований к ней:
- SIEM должна обладать возможностью строить максимально сложные цепочки и схемы взаимосвязи между событиями, использовать различные справочники и списки (в том числе подгружаемые по расписанию) для дополнения инцидента важной информацией. При этом набор правил, сценариев и категорий «из коробки» нас интересовал в меньшей степени, нам требовалась платформа для самостоятельного выстраивания контента.
- Система должна позволять физически и логически разделять аккумулируемые данные по разным storage group (в нашем случае − по разным заказчикам) с возможностью разделения полномочий по доступу, а также независимыми друг от друга хранилищами событий и инцидентов различных заказчиков.
- Система должна обладать как достаточным количеством готовых коннекторов (с возможностью изменения маппинга), так и обладать удобным механизмом разработки дополнительных коннекторов к любой системе, которая хоть в каком-то виде умеет отдавать информацию вовне. Так же был важен API для связки с внешними системами инцидент-менеджмента, отчетности и визуализации.
- Одной из важнейших задач, которая должна решать SIEM, – стабильность работы при большой нагрузке как по потоку событий, так и по работе большого количества корреляционных правил, ретроспективных поисков и формируемой отчетности.
- SIEM-система должна позволять кастомизировать внутренние ресурсы под меняющиеся задачи SOC. В частности, создание внутреннего профиля мониторинга источников (System Health), использование на различных этапах работы с фиксируемыми инцидентами внешних скриптов, ведение и кастомизация своего инцидент-менеджмента и т. д.
Свой выбор мы остановили на одном из лидеров в классе SIEM – HP ArcSight и, несмотря на различные сложности в жизни системы, о своем решении ни разу не пожалели.
Компоненты SOC
Вслед за сервисом по мониторингу инцидентов Solar JSOC дополнялся новыми сервисами:
- WAF as a service;
- Anti-DDoS;
- Vulnerability Assessment, где в качестве основного решения мы выбрали Qualys за счет богатого функционала и удобного интерфейса, в том числе для написания сигнатур;
- Сканер программного кода на наличие уязвимостей и НДВ Solar inCode.
Технологически Solar JSOC − уже давно не только HP ArcSight. SIEM'овское ядро постепенно обрастало различными полезными аддонами и фичами. Были добавлены средство мониторинга трафика и решение класса Security Intelligence Solar inView, которое является:
- инструментом высокоуровневого поиска аномалий у клиента и отслеживания общих трендов в активностях и инцидентах;
- системой контроля и визуализации нашего выполнения SLA перед заказчиком;
- эффективным визуальным dashboard и системой отчетности для бизнес-руководства заказчика.
Одним из основных нововведений последнего года является переход на внешнюю систему кейс-менеджмента. В качестве платформы мы выбрали Kayako, которая оптимально подходит под наши задачи, имеет удобный и гибкий инструмент кастомизации и отличный API.
Важным инструментом в рамках задач по мониторингу и выявлению инцидентов являются репутационные базы различных отечественных и зарубежных вендоров и CERT. Базы могут содержать как сетевые, так и хостовые индикаторы компрометации (IOC) различных вредоносов, либо описывать схему работы злоумышленников. В зависимости от поставляемых данных, мы используем различные инструменты выявления индикаторов: сетевые заносятся в ArcSight для ретроспективного поиска и контроля в будущем, хостовые превращаются в индикаторы сканеров защищенности. Самыми значимыми партнерами в этой области являются FinCERT и Kaspersky Lab.
Интеграция с репутационными базами Kaspersky Threat Intelligence осуществляется через API, разработанный совместно с Kaspersky Lab. Благодаря этому мы получаем наиболее актуальную информацию – база «фидов» обновляется раз в несколько часов, что сопоставимо со скоростью получения новых антивирусных сигнатур (иногда быстрее). Это позволяет оперативно выявлять zero-day вирусы, попадающие в инфраструктуру заказчиков за счет их callback'ов.
Интересным форматом предоставляемой информации являются APT Reports, в которых вендором или CERT'ом описывается хронология атаки, инструментарий, сопутствующее использование уязвимостей и, конечно, цель злоумышленников. Данный формат позволяет нам по-новому взглянуть на точки контроля и детектирования инцидентов, подкрутить существующие или создать новые корреляционные правила.
Используя указанный выше инструментарий, мы сформировали следующие направления оказания сервисов ИБ:
- Защита внешних веб-ресурсов компании – здесь в первую очередь мы предоставляем сервис по проактивной эксплуатации WAF и Anti-DDoS решений;
- Комплексное обеспечение безопасности бизнес-приложений – мониторинг инцидентов + анализ исходного кода;
- Инфраструктурный мониторинг инцидентов ИБ;
- Комплектный контроль защищенности и compliance control;
- Выявление направленных атак и zero-day вредоносов – комплектный подход, включающий в себя регулярные сканирования инфраструктуры с помощью сканера защищенности + мониторинг инцидентов + использование целевых фидов + разбор и анализ экземпляров вредоносного ПО;
- Эксплуатация интеллектуальных СЗИ – DAM, Sandbox, NGFW, анализаторы трафика.
Архитектура

После выбора основной технологической платформы необходимо было решить задачи по созданию инфраструктуры и определить площадку размещения. Опыт наших западных коллег показывает, что целевая доступность архитектуры должна составлять не менее 99,5% (причем с максимальной катастрофоустойчивостью).
При этом принципиальным оставался вопрос географии: collocation возможен только в границах РФ, что исключало возможность использования популярных западных провайдеров. Сюда же наложились естественные вопросы обеспечения ИБ инфраструктуры на всех уровнях доступа. Поэтому было решено обратиться к нашему партнеру Jet Infosystems, и в рамках большого колокейшена для JSOC было выделено несколько стоек в физически изолированном от других серверов фрагменте, где мы смогли развернуть свою архитектуру, одновременно ужесточив уже существующие в рамках ВЦОД профили безопасности. ИТ-инфраструктура развернута в Tier 3 дата-центре, и ее показатели доступности составляют 99,8%. В результате мы смогли выйти на целевые показатели доступности нашего сервиса и получили существенную свободу действий в работе и адаптации системы под себя.
Команда
На начальном этапе команда JSOC состояла из 3 человек: двух инженеров мониторинга, закрывающих временной интервал с 8 до 22 часов, и одного аналитика/администратора, который занимался развитием правил. SLA по услуге, обозначенный клиентам, тоже был достаточно мягким: время реакции на обнаруженный инцидент – до 30 минут, время на разбор, подготовку аналитической справки и информирование клиента – до 2 часов. Но, по прошествии первых месяцев работы, мы сделали несколько очень существенных выводов:
- Смена мониторинга должна обязательно работать в режиме 24*7. Несмотря на то, что объем инцидентов в вечерние и ночные часы снижается, самые важные и критичные события (старт DDoS-атак, завершающие фазы медленных атак на проникновение через внешний периметр, злонамеренные действия контрагентов и т. п.) происходят именно в ночное время, и к моменту старта утренней смены уже теряют свою актуальность.
- Время разбора критичного инцидента не должно превышать 30 минут. В противном случае шансы на его предотвращение или минимизацию ущерба катастрофически падают.
- Для обеспечения требуемого времени разбора под каждый инцидент должен быть подготовлен полноценный инструментарий для расследования внутри ArcSight: active channels с отфильтрованными целевыми событиями для разбора, trends, dashboards, демонстрирующие статистические изменения в подозрительных активностях, и целевые аналитические отчеты, позволяющие быстро анализировать активности и принимать оперативные решения, active/session lists для оперативного доступа к информации о хостах, пользователях и пр.
- Команда администрирования средств защиты наших клиентов должна быть отделена от группы мониторинга и выявления инцидентов. В противном случае риск влияния человеческого фактора в цепочке «выполнил изменения конфигурации – зафиксировал инцидент – отметил ложным срабатыванием» мог существенно сказаться на качестве нашей услуги.
Эти выводы существенно повлияли на структуру департамента JSOC в компании Solar Security и помогли сформировать трехуровневую модель реагирования на инциденты. Сейчас подразделение насчитывает уже более 40 человек, имеет сформировавшуюся структуру (см. рис. 4) и включает в себя:
- Две дежурные смены, которые работают 24*7: одна занимается мониторингом и разбором инцидентов, другая – администрированием системы.
- Персональных аналитиков и сервис-менеджеров под клиентов JSOC. По опыту, один аналитик способен вести 3-4 компании.
- Выделенную команду развития, которая позволяет нам сохранять актуальность услуги и профиля мониторинга угроз.

Рис. 4 – Организационная структура JSOC
Такая организационная структура позволила нам выйти на целевые показатели SLA:

Итоги
За последние 4 года развития наш Security Operations Center прошел следующие важные этапы:
2012 год
- зарождение идеи облачного SOC.
2013 год
- формирование команды JSOC, состоящей из 2 инженеров мониторинга в режиме 12/5, одного аналитика и руководителя направления;
- 1 заказчик и 3 пилотных проекта;
- SLA: реакция на инцидент – 30 минут, анализ – 2 часа.
2014 год
- формирование двух площадок: Москва и Нижний Новгород;
- первая линия мониторинга и эксплуатации 24/7;
- выполнение SLA – 98,5%;
- 10 заказчиков.
2015 год
- штат сотрудников достиг 30 человек;
- значительный рост числа заказчиков – 20+, 4 публичных проекта
- выполнение SLA – 99,2%
На этом первая, вводная статья из серии подошла к концу. В ближайших планах – материалы о технических аспектах работы Solar JSOC:
- Доступность SOC: показатели, измерение.
- Solar JSOC: Регистрация инцидентов. Как и почему стоит жить во внешней тикет-системе.
- Solar JSOC: ПРАВИЛьная кухня и др.
- и др.
Оставайтесь с нами!
