Добрый день, коллеги. Вот и подошел черед третьей статьи, посвященной Security Operations Center.
Сегодняшняя публикация затрагивает наиболее важный аспект любого SOC – контент, связанный с выявлением и анализом потенциальных инцидентов информационной безопасности. Это, в первую очередь, архитектура корреляционных правил в SIEM-системе, а также сопутствующие листы, тренды, скрипты, настройки коннекторов. В статье я расскажу про весь путь обработки исходных логов, начиная с обработки событий коннекторами SIEM-системы и заканчивая использованием этих событий в корреляционных правилах и дальнейшем жизненном цикле уже инцидентного срабатывания.

Как упоминалось в предыдущих статьях, сердцем нашего SOC является SIEM-система HPE ArcSight ESM. В статье я расскажу о доработках данной платформы за более чем четырехлетний процесс эволюции и опишу текущий вариант настроек.
В первую очередь, доработки были направлены на оптимизацию следующих активностей:
Любая SIEM имеет «из коробки» набор предустановленных правил, которые, сопоставляя события от источников и накапливая пороговые значения, могут оповестить клиента о зафиксированной аномалии – потенциальном инциденте. Зачем же тогда нужно дорогостоящее внедрение этой системы, ее настройка, а также ее поддержка силами интегратора и собственного аналитика?
Для ответа на этот вопрос я расскажу, как устроен жизненный цикл событий, попадающих в SIEM из источников, каков путь от срабатывания правила до создания инцидента и оповещения заказчика.
Первичная обработка событий происходит на коннекторах SIEM-системы. Обработка включает в себя фильтрацию, категоризацию, приоритизацию, агрегирование и нормализацию. Также события могут проходить дополнительную предобработку, например, объединение нескольких событий, содержащих разную информацию.
Например: Логи netscreen juniper для отслеживания arp-спуфинга содержат информацию об ip-адресах и mac-адресах в разных строках:
При написании коннектора можно сразу сделать merge для отображения всей информации в одном событии. При этом ключевое поле merge в данном случае – это iso.3.6.1.4.1.3224.17.1.3.1.*.276.
Далее предобработанное событие отправляется в ядро системы HPE ArcSight, где происходит его последующая обработка. В рамках Solar JSOC мы использовали все этапы обработки событий, чтобы расширить возможности по мониторингу инцидентов и получению информации о конечных системах.
В рамках предобработки событий мы стараемся по максимуму использовать функциональность, связанную с маппингом полей, дополнительной категоризацией и фильтрацией событий на коннекторах.
К сожалению, возможности любой SIEM-системы по количеству обрабатываемых событий в секунду (EPS) и по объему последующих вычислений и обработок исходных событий ограничены. В Solar JSOC на одну инсталляцию ArcSight мы заводим нескольких заказчиков, и поток событий от них достаточно высок. Общий скоуп фиксируемых инцидентов достигает 100-150, что подразумевает использование нескольких сотен правил для вычисления, заполнения листов, генерации инцидентов и прочее. При этом для нас очень важна стабильность работы системы и быстрый поиск событий по active channel`ам.
Постепенно мы пришли к понимаю, что для выполнения описанных выше условий часть обработки можно вынести на уровень коннектора.
Например, вместо использования pre-persistence rules для унификации событий аутентификации в различных системах, в том числе на сетевом оборудовании, мы на уровне map-файлов коннекторов вводим категории.
Map-файл для Cisco Router выглядит так:
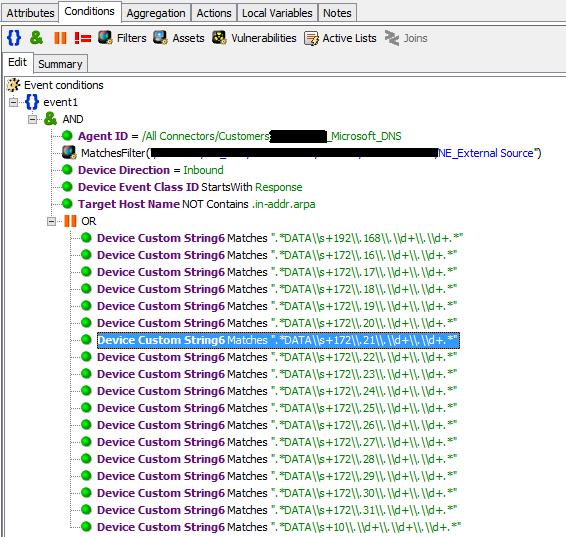
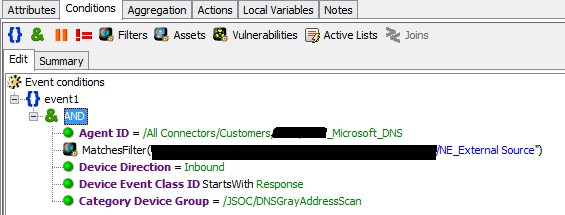
Поток событий с DNS-серверов обычно один из самых высоких, поэтому использование регулярных выражений для отслеживания попыток резолва серых адресов внешними серверами с целью сканирования инфраструктуры становится очень непростой задачей. ArcSight на потоке в 1500 EPS с DNS начинает «плохо себя чувствовать», поэтому регулярные выражения также выносятся в map-файлы и им назначается категория.
Вместо
пишем:
Остальное выносится регулярными выражениями в map-файл.
Яркий пример применения фильтрации событий тоже связан с DNS-серверами. На сервере коннекторов HPE ArcSight SmartConnector мы включаем резолв имен хостов по адресам на коннекторах Windows и сетевом оборудовании. Таким образом количество DNS-запросов с сервера коннекторов бывает очень значительным, и все эти события явно не нужны для выявления инцидентов, поэтому их можно успешно фильтровать для снижения нагрузки на ESM.
Второй, зачастую даже более важной причиной использования категоризации, является работа с большим количеством различных устройств, систем и прикладного ПО.
Когда необходимо подключить, например, NetScreen, который не очень популярен у российских компаний, к Solar JSOC можно добавлять события «permit» во все правила, касающиеся, например:
А можно использовать категоризацию или готовые фильтры. В Solar JSOC используются оба метода в разных случаях. В данном случае мы используем фильтр Firewall_Pass:

Как видно из вышеприведенных примеров, мы используем как штатную категоризацию ArcSight, если она подходит под наши требования, так и собственную, которая нам показалась универсальной.
Контент корреляционных правил
В рамках Solar JSOC мы пришли к выводу, что связка «базовые-профилирующие-инцидентные правила» отлично работает. Давайте остановимся на каждом типе по порядку.
Базовые правила
Базовые правила служат для добавления в события недостающей информации – имени пользователя, информации о владельце учетной записи из кадровой системы, дополнительного описания хостов из CMDB. Все это реализовано в Solar JSOC и помогает нам быстрее разбирать инциденты и получать всю необходимую информацию в ограниченном пуле событий. Сделано это для того, чтобы у нашей первой линии всегда была возможность уложиться в отведенные по SLA 20 минут на критичные инциденты и сделать при этом действительно качественный и полный разбор.
Профилирующие правила
Профилирующие правила для самых разных активностей играют одну из важнейших ролей. Они формируют первичные данные, записываемые в active list и в дальнейшем используемые в следующих ситуациях:
Инцидентные правила
В Solar JSOC мы используем следующие типы регистрации аномальных активностей:
Остановимся подробнее на каждом из вариантов.
Самый простой способ использования корреляционных правил – срабатывание при возникновении единичного события с источника. Это прекрасно работает, если SIEM-система используется в связке с настроенными СЗИ. Многие компании ограничиваются этим способом.
Одним из самых простых инцидентов является модификация критичных файлов на хосте.
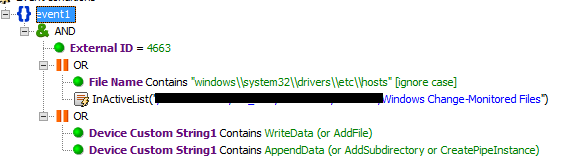
Правило смотрит безусловно файл /etc/hosts, а также все критичные файлы, указанные в active list и согласованные с клиентом.
Последовательное срабатывание корреляционных правил по нескольким событиям за период идеально ложится в инфраструктурную безопасность.
Вход под одной учетной записью на рабочую станцию и дальнейший вход в целевую систему под другой (или такой же сценарий с VPN и информационной системой) говорит о возможной краже данных учетных записей. Подобная потенциальная угроза встречается часто, особенно в повседневной работе администраторов (domain: a.andronov, Database: oracle_admin), и вызывает большое количество ложных срабатываний, поэтому требуются создание «белых списков» и дополнительное профилирование.
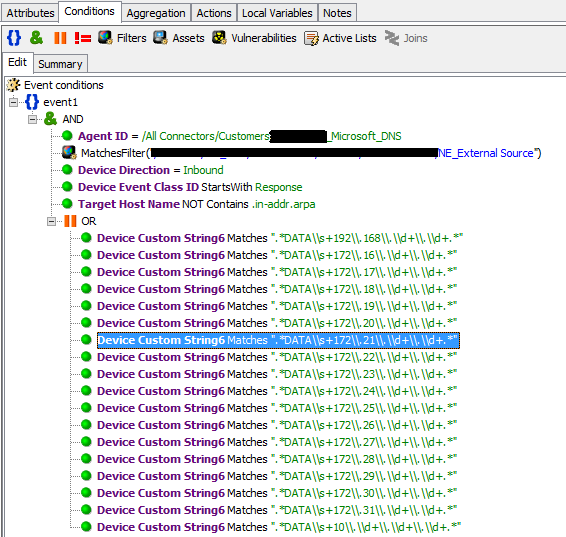
Ниже приведен пример срабатывания на доступ к неразрешенному сегменту сети из пула vpn:

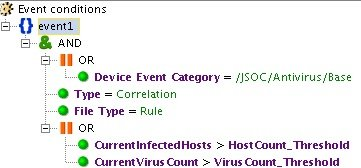
А вот пример третьего типа инцидентных правил, которое настроено на детектирование события обнаружения вируса и последующего отсутствия событий его удаления/излечения/помещения на карантин:

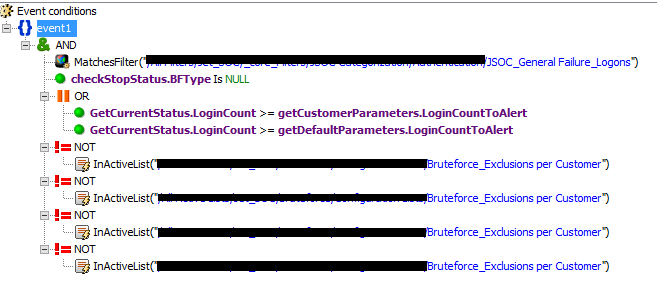
Четвертый способ настройки правил отлично подходит для выявления различных сканирований, брутфорса, эпидемий и прочего.
Правило по выявлению брутфорса, универсальное для всех систем, является квинтэссенцией всех описанных выше методов. При настройке источников мы всегда используем map-файлы для категоризации, чтобы они подпадали под фильтр Failure Logons, далее существуют базовые правила, которые записываются в лист и по ним осуществляется счет, отдельно используются конфигурационные листы, чтобы выставлять пороговые значения по различным заказчикам, а также критичным и некритичным пользователям. Также предусмотрены исключения и стоп-лист, чтобы первую линию не завалило однотипными инцидентами по одному пользователю.
Отклонение от среднестатистических показателей используется в сценариях детектирования DDoS-атак, вирусных эпидемий, утечек информации из корпоративной сети и многих других.
В качестве примера можно привести корреляционное правило «INC_AV_Virus Anomaly Activity», которое отслеживает превышение среднего показателя срабатываний антивируса (вычисляется на основании профиля) за определенный период.
Что касается проверки индикаторов компрометации, то их стоит выделить отдельным пунктом, потому что в их отношении осуществляется целый комплекс работ:
Первый пункт включает в себя в первую очередь работу с трендами и репортами, так как в них хранится информация за 6-12 месяцев о посещении интернет-сайтов, запуске процессов, md5-суммах запускаемых в инфраструктуре исполняемых файлах, получаемых от специализированных средств защиты или некоторых антивирусных вендоров.
Второй и третий пункт тесно связаны между собой. При этом пересмотр осуществляется в зависимости от количества, частотности и подтвержденности того, что срабатывания были боевые. В случае большого количества ложных срабатываний и отсутствия боевых, индикаторы через определенное время удаляются.
Развивая Solar JSOC, мы извлекли определенные уроки, ставшие основой для предоставления сервиса:
Заключение
В качестве заключения хотелось бы подвести итог по рекомендациям при организации собственного SOC в компании:
В данной статье я не затрагивал вопросов регистрации инцидента, его обработки первой линией, критериев фильтрации ложных срабатываний, механизма оповещения клиентов и проведения дополнительных расследований. Этому будет посвящена следующая статья из цикла.
Сегодняшняя публикация затрагивает наиболее важный аспект любого SOC – контент, связанный с выявлением и анализом потенциальных инцидентов информационной безопасности. Это, в первую очередь, архитектура корреляционных правил в SIEM-системе, а также сопутствующие листы, тренды, скрипты, настройки коннекторов. В статье я расскажу про весь путь обработки исходных логов, начиная с обработки событий коннекторами SIEM-системы и заканчивая использованием этих событий в корреляционных правилах и дальнейшем жизненном цикле уже инцидентного срабатывания.

Как упоминалось в предыдущих статьях, сердцем нашего SOC является SIEM-система HPE ArcSight ESM. В статье я расскажу о доработках данной платформы за более чем четырехлетний процесс эволюции и опишу текущий вариант настроек.
В первую очередь, доработки были направлены на оптимизацию следующих активностей:
- Сокращение времени подключения нового клиента и настройки коннекторов.
- Профилирование основных активностей в инфраструктуре.
- Снижение количества ложных срабатываний.
- Повышение информативности и полноты оповещений клиента о зафиксированных потенциальных инцидентах.
Любая SIEM имеет «из коробки» набор предустановленных правил, которые, сопоставляя события от источников и накапливая пороговые значения, могут оповестить клиента о зафиксированной аномалии – потенциальном инциденте. Зачем же тогда нужно дорогостоящее внедрение этой системы, ее настройка, а также ее поддержка силами интегратора и собственного аналитика?
Для ответа на этот вопрос я расскажу, как устроен жизненный цикл событий, попадающих в SIEM из источников, каков путь от срабатывания правила до создания инцидента и оповещения заказчика.
Первичная обработка событий происходит на коннекторах SIEM-системы. Обработка включает в себя фильтрацию, категоризацию, приоритизацию, агрегирование и нормализацию. Также события могут проходить дополнительную предобработку, например, объединение нескольких событий, содержащих разную информацию.
Например: Логи netscreen juniper для отслеживания arp-спуфинга содержат информацию об ip-адресах и mac-адресах в разных строках:
iso.3.6.1.4.1.3224.17.1.3.1.2.274 = IpAddress: 192.168.30.94
iso.3.6.1.4.1.3224.17.1.3.1.2.275 = IpAddress: 172.16.9.231
iso.3.6.1.4.1.3224.17.1.3.1.2.276 = IpAddress: 172.16.9.232
iso.3.6.1.4.1.3224.17.1.3.1.3.274 = Hex-STRING: AC 22 0B 74 91 4C
iso.3.6.1.4.1.3224.17.1.3.1.3.275 = Hex-STRING: 20 CF 30 9A 17 11
iso.3.6.1.4.1.3224.17.1.3.1.3.276 = Hex-STRING: 80 C1 6E 93 A0 56
При написании коннектора можно сразу сделать merge для отображения всей информации в одном событии. При этом ключевое поле merge в данном случае – это iso.3.6.1.4.1.3224.17.1.3.1.*.276.
Далее предобработанное событие отправляется в ядро системы HPE ArcSight, где происходит его последующая обработка. В рамках Solar JSOC мы использовали все этапы обработки событий, чтобы расширить возможности по мониторингу инцидентов и получению информации о конечных системах.
Настройки коннекторов
В рамках предобработки событий мы стараемся по максимуму использовать функциональность, связанную с маппингом полей, дополнительной категоризацией и фильтрацией событий на коннекторах.
К сожалению, возможности любой SIEM-системы по количеству обрабатываемых событий в секунду (EPS) и по объему последующих вычислений и обработок исходных событий ограничены. В Solar JSOC на одну инсталляцию ArcSight мы заводим нескольких заказчиков, и поток событий от них достаточно высок. Общий скоуп фиксируемых инцидентов достигает 100-150, что подразумевает использование нескольких сотен правил для вычисления, заполнения листов, генерации инцидентов и прочее. При этом для нас очень важна стабильность работы системы и быстрый поиск событий по active channel`ам.
Постепенно мы пришли к понимаю, что для выполнения описанных выше условий часть обработки можно вынести на уровень коннектора.
Например, вместо использования pre-persistence rules для унификации событий аутентификации в различных системах, в том числе на сетевом оборудовании, мы на уровне map-файлов коннекторов вводим категории.
Map-файл для Cisco Router выглядит так:
event.eventClassId,set.event.deviceAction,set.categoryOutcome,set.event.categoryDeviceGroup
SEC_LOGIN:LOGIN_SUCCESS,Login,Success,/JSOC/Authentication
SEC_LOGIN:LOGIN_FAILURE,Login,Failure,/JSOC/Authentication
SYS:LOGOUT,Logout,Success,/JSOC/Authentication
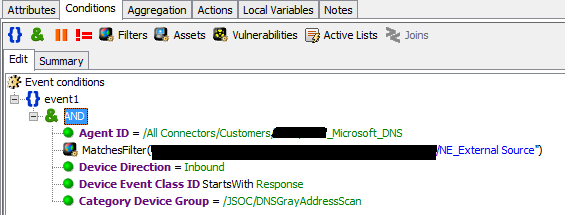
Поток событий с DNS-серверов обычно один из самых высоких, поэтому использование регулярных выражений для отслеживания попыток резолва серых адресов внешними серверами с целью сканирования инфраструктуры становится очень непростой задачей. ArcSight на потоке в 1500 EPS с DNS начинает «плохо себя чувствовать», поэтому регулярные выражения также выносятся в map-файлы и им назначается категория.
Вместо
пишем:
Остальное выносится регулярными выражениями в map-файл.
Яркий пример применения фильтрации событий тоже связан с DNS-серверами. На сервере коннекторов HPE ArcSight SmartConnector мы включаем резолв имен хостов по адресам на коннекторах Windows и сетевом оборудовании. Таким образом количество DNS-запросов с сервера коннекторов бывает очень значительным, и все эти события явно не нужны для выявления инцидентов, поэтому их можно успешно фильтровать для снижения нагрузки на ESM.
Второй, зачастую даже более важной причиной использования категоризации, является работа с большим количеством различных устройств, систем и прикладного ПО.
Когда необходимо подключить, например, NetScreen, который не очень популярен у российских компаний, к Solar JSOC можно добавлять события «permit» во все правила, касающиеся, например:
- прямого доступа в интернет в обход прокси;
- обращения к потенциально опасным хостам по версиям различных репутационных баз;
- сканирования протоколов прикладного уровня и многого другого.
А можно использовать категоризацию или готовые фильтры. В Solar JSOC используются оба метода в разных случаях. В данном случае мы используем фильтр Firewall_Pass:
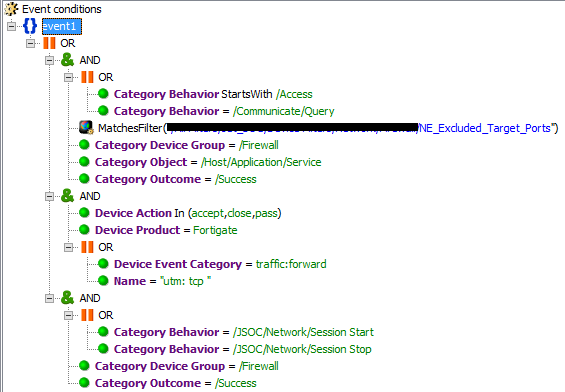
Как видно из вышеприведенных примеров, мы используем как штатную категоризацию ArcSight, если она подходит под наши требования, так и собственную, которая нам показалась универсальной.
Контент корреляционных правил
В рамках Solar JSOC мы пришли к выводу, что связка «базовые-профилирующие-инцидентные правила» отлично работает. Давайте остановимся на каждом типе по порядку.
Базовые правила
Базовые правила служат для добавления в события недостающей информации – имени пользователя, информации о владельце учетной записи из кадровой системы, дополнительного описания хостов из CMDB. Все это реализовано в Solar JSOC и помогает нам быстрее разбирать инциденты и получать всю необходимую информацию в ограниченном пуле событий. Сделано это для того, чтобы у нашей первой линии всегда была возможность уложиться в отведенные по SLA 20 минут на критичные инциденты и сделать при этом действительно качественный и полный разбор.
Профилирующие правила
Профилирующие правила для самых разных активностей играют одну из важнейших ролей. Они формируют первичные данные, записываемые в active list и в дальнейшем используемые в следующих ситуациях:
- Быстрый ретроспективный поиск активностей.
К данным профилирующим правилам, например, относится Profile_IA_Internet Access (Proxy). Это правило пишет в лист все переходы на сайты через прокси-сервер. Данный лист содержит следующие поля:

Но лист имеет ограничение в 3 млн записей, поэтому ежедневно в ночное время мы заносим данные в тренд, который имеет на порядок большее место для хранения.
Данный лист используется как при стандартном расследования инцидентов, так и при ретроспективной проверке индикаторов компрометации за длительный промежуток времени – до 1 года.
- Создание и фиксация профилей.
Например, профили аутентификации или сетевого взаимодействия по критичным хостам. Сбор такого профиля занимает от одной до двух недель, после чего выгружается и отправляется клиенту. Происходит согласование и фиксация профиля, далее настраивается инцидентное правило. Появление любой активности, не попадающей в профиль по заданным параметрам, вызывает срабатывание этого правила, разбор инцидента первой линией и оповещение клиента.
Для удобства изменения статуса мы используем конфигурационный файл.

При статусе InProgress идет сбор профиля, при статусе Finished – начинает работает инцидентное правило.
- Расчет средних, максимальных и флуктуационных показателей.
Правило «Аномальная статистика вирусной активности» работает именно по этому принципу. Мы считаем за определенный период статистику по вирусным заражениям инфраструктуры клиента, и если в какой-либо день происходит всплеск – мы оповещаем клиента об аномалии, так как она может свидетельствовать о направленных злонамеренных действиях со стороны злоумышленника.


Инцидентные правила
В Solar JSOC мы используем следующие типы регистрации аномальных активностей:
- По одиночному событию с источника.
- По нескольким последовательным событиям с одного или нескольких источников за выделенный период.
- По наступлению одного и не наступлению другого события за определенный период.
- По достижению порогового значения событий одного типа.
- По отклонению статистических показателей от эталонного или среднего значения.
- Особняком стоит проверка индикаторов компрометации.
Остановимся подробнее на каждом из вариантов.
Самый простой способ использования корреляционных правил – срабатывание при возникновении единичного события с источника. Это прекрасно работает, если SIEM-система используется в связке с настроенными СЗИ. Многие компании ограничиваются этим способом.
Одним из самых простых инцидентов является модификация критичных файлов на хосте.
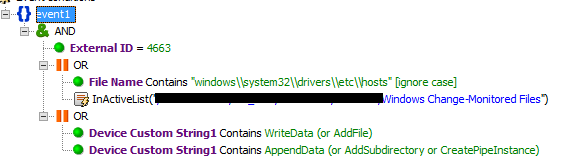
Правило смотрит безусловно файл /etc/hosts, а также все критичные файлы, указанные в active list и согласованные с клиентом.
Последовательное срабатывание корреляционных правил по нескольким событиям за период идеально ложится в инфраструктурную безопасность.
Вход под одной учетной записью на рабочую станцию и дальнейший вход в целевую систему под другой (или такой же сценарий с VPN и информационной системой) говорит о возможной краже данных учетных записей. Подобная потенциальная угроза встречается часто, особенно в повседневной работе администраторов (domain: a.andronov, Database: oracle_admin), и вызывает большое количество ложных срабатываний, поэтому требуются создание «белых списков» и дополнительное профилирование.
Ниже приведен пример срабатывания на доступ к неразрешенному сегменту сети из пула vpn:

А вот пример третьего типа инцидентных правил, которое настроено на детектирование события обнаружения вируса и последующего отсутствия событий его удаления/излечения/помещения на карантин:
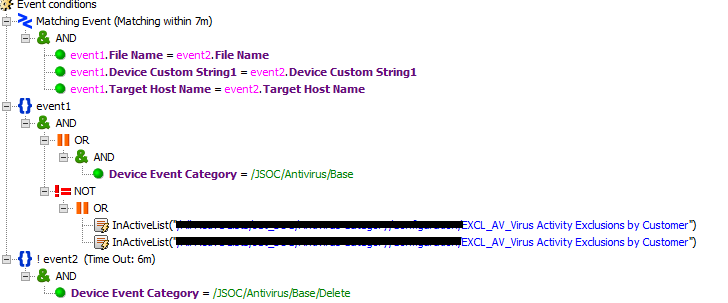
Четвертый способ настройки правил отлично подходит для выявления различных сканирований, брутфорса, эпидемий и прочего.
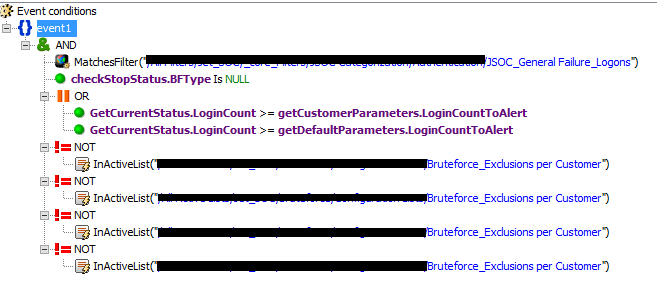
Правило по выявлению брутфорса, универсальное для всех систем, является квинтэссенцией всех описанных выше методов. При настройке источников мы всегда используем map-файлы для категоризации, чтобы они подпадали под фильтр Failure Logons, далее существуют базовые правила, которые записываются в лист и по ним осуществляется счет, отдельно используются конфигурационные листы, чтобы выставлять пороговые значения по различным заказчикам, а также критичным и некритичным пользователям. Также предусмотрены исключения и стоп-лист, чтобы первую линию не завалило однотипными инцидентами по одному пользователю.
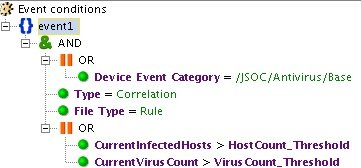
Отклонение от среднестатистических показателей используется в сценариях детектирования DDoS-атак, вирусных эпидемий, утечек информации из корпоративной сети и многих других.
В качестве примера можно привести корреляционное правило «INC_AV_Virus Anomaly Activity», которое отслеживает превышение среднего показателя срабатываний антивируса (вычисляется на основании профиля) за определенный период.
Что касается проверки индикаторов компрометации, то их стоит выделить отдельным пунктом, потому что в их отношении осуществляется целый комплекс работ:
- проводится ретроспективная проверка индикаторов;
- индикаторы заносятся в специальные листы для их детектирования в дальнейшем;
- по истечении времени проводится пересмотр актуальности индикаторов компрометации.
Первый пункт включает в себя в первую очередь работу с трендами и репортами, так как в них хранится информация за 6-12 месяцев о посещении интернет-сайтов, запуске процессов, md5-суммах запускаемых в инфраструктуре исполняемых файлах, получаемых от специализированных средств защиты или некоторых антивирусных вендоров.
Второй и третий пункт тесно связаны между собой. При этом пересмотр осуществляется в зависимости от количества, частотности и подтвержденности того, что срабатывания были боевые. В случае большого количества ложных срабатываний и отсутствия боевых, индикаторы через определенное время удаляются.
Развивая Solar JSOC, мы извлекли определенные уроки, ставшие основой для предоставления сервиса:
- Взаимодействие с клиентом и обратная связь от него является важнейшим элементом в работе Security Operations Center. Оно позволяет лучше понять процессы внутри заказчика, а значит – создавать списки исключений для различных инцидентных правил и снизить количество ложных срабатываний в несколько раз. Для одного клиента может быть абсолютно нормальным использование TOR на хосте, а для другого это прямой путь к увольнению сотрудника. У одних VPN-доступ имеют только доверенные администраторы, которые могут работать со всей инфраструктурой, у других доступ есть у половины сотрудников, но работают они только со своей станцией.
- Сбор профилей. Подавляющее большинство сотрудников компании работают по одному и тому же сценарию ежедневно. Его легко профилировать, следовательно, и аномалии выявлять достаточно просто. Поэтому в Solar JSOC мы используем единые правила, но параметры, списки, фильтры в них индивидуальны для каждого клиента.
- Сложные правила не работают. Чем больше количество уточняющих условий и вовлекаемых в корреляционное правило исходных событий, тем меньше шансов, что такой сценарий «взлетит из коробки» у всех заказчиков. Необходимо делать универсальные правила, а «подстройку» делать на уровне исключений.
- SIEM должна решать только свои задачи. Не нужно пытаться заставлять SIEM-систему решать задачу Zabbix или решения по детектированию DDoS. Последнее мало того, что сильно «съедает» ресурсы системы, так еще и не поможет предотвратить этот самый DDoS.
При этом хочется отметить: как бы хорошо ни была настроена SIEM-система, false positive события будут присутствовать всегда. Если их нет, значит, SIEM мертв. Но false-positive также бывают разные. Сброс пароля топ-менеджера ночью может объясняться как неожиданным решением поработать из дома и невозможностью вспомнить пароль, так и действиями злоумышленника. Но бывают и ситуации, когда ложноположительные срабатывания возникают на уровне техники и на текущий момент не добавлены в инцидентное правило как штатные исключения. Именно поэтому важно наличие квалифицированных инженеров мониторинга, способных выявить реальный инцидент. Специалист должен обладать набором знаний по информационной безопасности, предвидеть векторы возможных атак и знать конечные системы для анализа событий.
Заключение
В качестве заключения хотелось бы подвести итог по рекомендациям при организации собственного SOC в компании:
- Важнейшим звеном SOC является SIEM-система, о вопросах ее выбора говорилось в первой статье цикла, но наиболее важным моментом является ее настройка под требования бизнеса и особенности инфраструктуры.
- Создание корреляционных правил для обнаружения различных сценариев атак и деятельности злоумышленников – это огромный пласт работ, которые никогда не заканчиваются в связи с постоянным развитием угроз. Именно поэтому необходимо наличие собственного квалифицированного аналитика в штате компании.
- Первая линия инженеров мониторинга должна формироваться на базе отдела информационной безопасности. Специалист должен уметь отличать ложноположительные срабатывания от реальных инцидентов и проводить базовый разбор событий. Для этого необходимы навыки в сфере ИБ и понимание возможных векторов атак.
В данной статье я не затрагивал вопросов регистрации инцидента, его обработки первой линией, критериев фильтрации ложных срабатываний, механизма оповещения клиентов и проведения дополнительных расследований. Этому будет посвящена следующая статья из цикла.
