В ходе работы DLP-система ежедневно перехватывает огромные массивы информации – это и письма сотрудников, и информация о действиях пользователей на рабочих станциях, и сведения о хранящихся в сети организации файловых ресурсах, и оповещения о несанкционированном выводе данных за пределы организации. Но полезной эта информация будет только в случае, если в DLP реализован качественный механизм поиска по всему массиву перехваченных коммуникаций. С тех пор, как в 2000 году увидела свет первая версия нашего DLP-решения, мы несколько раз меняли механизм поиска по архиву. Сегодня мы хотим рассказать о том, какие технологии мы использовали, какие видели в них преимущества и недостатки, и почему мы от них в итоге отказывались. Возможно, кому-то наш опыт окажется полезен.

В самых общих чертах наши требования к механизму поиска таковы: он должен быть удобным и позволять пользователю быстро ориентироваться во всем массиве собранной информации, а именно:
Начало пути и базовые потребности: Oracle ConText, Tsearch2 и Russian context optimizer
На первых шагах становления продукта, когда мы контролировали только корпоративную почту, для хранения перехваченных данных использовалась СУБД Oracle. Поиск был достаточно простым, и реализован он был на стандартном Oracle ConText (позднее – Oracle Text), который поставлялся в составе Oracle Database. Мы использовали это решение много лет, т.к. в то время оно вполне отвечало нашим потребностям.
Пользователь мог задавать поисковый запрос по множеству атрибутов перехваченных данных (размеры письма и частей, имена файлов, типы данных, значения произвольных почтовых и mime-заголовков и их параметров, количество вложений) и выполнять поиск по тексту писем даже несмотря на отсутствие в Oracle ConText русской морфологии. Выдача на такие запросы была вполне качественной, но у этого механизма были критичные для нас недостатки – низкая скорость выполнения поисковых запросов и отсутствие русской морфологии.
Позже, с укреплением позиций PostgreSQL на рынке, мы начали использовать его в качестве альтернативы Oracle. Вместе с PostgreSQL мы получили модуль полнотекстового поиска Tsearch2, который уже поддерживал русскую морфологию и наконец позволил нам реализовать полнотекстовый поиск по перехваченным письмам с использованием форм слов. Это значительно сократило время, которое офицеру безопасности приходилось тратить на работу с системой. Больше не надо было выполнять множество запросов, самостоятельно перебирая возможные словоформы. К тому же, на малых объемах данных Tsearch работал быстрее, чем Oracle ConText, и для некоторых заказчиков это был более удобный вариант.
Но были и серьезные недостатки:
В ожидании новых решений мы занимались собственными исследованиями и постоянно анализировали появляющиеся на рынке поисковые механизмы. В какой-то момент мы нашли альтернативу Oracle Text – продукт Russian context optimizer, который позволял строить индекс context'а с учетом русской морфологии. Он был чуть медленнее, но теперь мы могли реализовать поиск с использованием различных словоформ, в том числе, и по базам данных под управлением Oracle.
Скорость работы критически важна: Sphinx
Время шло, мы осваивали перехват новых каналов коммуникации, начали контролировать действия пользователей на рабочих станциях и мониторить правила хранения документов в локальной сети. Появилось большое количество разнотипных данных, выросли объемы хранения, из-за чего старые механизмы поиска стали работать медленно и неэффективно.
Стандартными средствами СУБД уже невозможно было увеличить скорость, и встал вопрос о создании внешнего индекса. После ряда исследований для этих целей была выбрана поисковая машина Sphinx (англ. SQL Phrase Index). Его можно было использовать для БД под управлением и Oracle, и PostgreSQL.
С помощью Sphinx мы выполняли полнотекстовый поиск. Для оптимизации поиска и возможности создания сложных запросов мы сначала искали с использованием внешнего индекса – выполняли полнотекстовый поиск по словоформам, а потом уже в найденном делали поиск по атрибутам писем в БД. Благодаря Sphinx скорость выполнения ряда запросов удалось существенно повысить — с десятков минут (вплоть до часов) до нескольких минут. Но это потребовало больших доработок с нашей стороны.
Кроме того, мы видели у Sphinx еще ряд недостатков:
Мы продолжали мониторинг рынка на предмет интересных механизмов поиска и, среди прочего, проводили протестировали поисковую машину SOLR на файловом хранилище DLP. Скажем коротко, что по сравнению со Sphinx SOLR никаких преимуществ не продемонстрировал, и мы остались на Sphinx.
Не только быстрый, но и умный: Elastic Search
В какой-то момент наше внимание привлек Elastic Search. Он изначально обладал множеством возможностей, которые в Sphinx нам приходилось реализовывать самостоятельно. В частности, Elastic Search поддерживал распределенную архитектуру. Он позволил нам выполнять действительно быстрый поиск – уже не за минуты, а за секунды – за счет создания индекса наиболее часто используемых данных. Нагрузочные тестирования, которые мы проводили, показали, что скорость поиска с помощью Elastic Search на 17 млн сообщений составляет менее секунды. При этом пользователь все так же мог делать запросы по заголовкам и структурной информации, и это тоже реализовано средствами БД.
В общем, переход на Elastic Search позволил не только «разогнать» поиск, но и разгрузить разработку, которой больше не приходилось дорабатывать его, чтобы предоставить пользователям необходимые инструменты. При этом Elastic Search – это не только механизм поиска и хранилище, но и различные аналитические инструменты, такие как визуализация, сборщик логов и т.п.
Мы считаем, что очень важное направление развития DLP, над которым надо активно работать, – это автоматизация деятельности пользователя, т.е. безопасника. А одно из необходимых условий автоматизации – это наличие готовых срезов данных для принятия решений, которые позволяют не делать каждый раз вручную типовые запросы, а сразу получать информацию из преднастроенного дашборда.
Только средствами Elastic Search мы создали рабочий стол руководителя и администратора со множеством дашбордов, на которых представлены самые интересные с точки зрения информационной безопасности данные. Это и снижение «уровня доверия» персоны, и статистика по самым часто пересылаемым файлам, и нехарактерные контакты сотрудника относительно его окружения. Вся зона событий и инцидентов также реализована на инструментах Elastic Search. Вот как это выглядит:

Рабочий стол руководителя
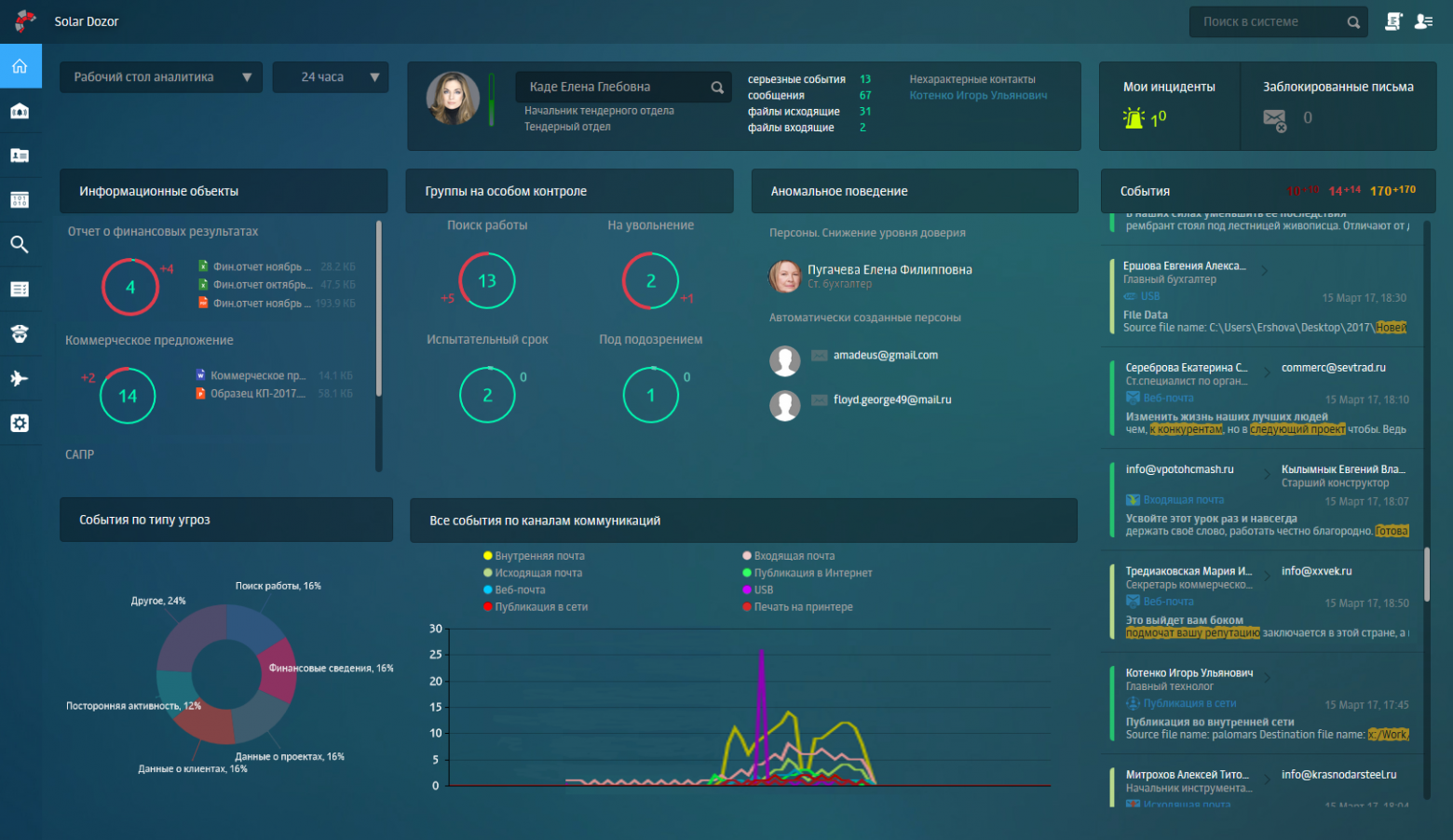
Рабочий стол аналитика

Тепловая карта коммуникаций

Изменение уровня доверия в «Досье» сотрудника
В общем, как показал наш опыт, для решения задач DLP Elastic Search рядом с его предшественником Sphinx – это концепт-кар рядом с «Ладой Калиной». Но, конечно, с оговоркой, что поиск применяется к огромным архивам DLP для такой специфической и сложной задачи, как расследование инцидентов информационной безопасности. Если перед вами, как разработчиком, такие задачи не стоят, то Sphinx может быть вполне приемлемым вариантом.
Планы на будущее
Но, как бы ни был хорош Elastic Search, мы продолжаем проводить различные исследования в части улучшения его поисковых механизмов. Сейчас мы занимаемся оптимизацией существующих инструментов Elastic Search и ведем исследования по использованию нейронных сетей в качестве инструмента поиска. Так что кто знает – возможно когда-нибудь мы продолжим эту статью главой об искусственном интеллекте…

В самых общих чертах наши требования к механизму поиска таковы: он должен быть удобным и позволять пользователю быстро ориентироваться во всем массиве собранной информации, а именно:
- Проводить расследования, не упуская даже мельчайших деталей.
- Быстро производить поиск интересующей информации по множеству параметров.
- Иметь возможность учета морфологии русского языка.
Начало пути и базовые потребности: Oracle ConText, Tsearch2 и Russian context optimizer
На первых шагах становления продукта, когда мы контролировали только корпоративную почту, для хранения перехваченных данных использовалась СУБД Oracle. Поиск был достаточно простым, и реализован он был на стандартном Oracle ConText (позднее – Oracle Text), который поставлялся в составе Oracle Database. Мы использовали это решение много лет, т.к. в то время оно вполне отвечало нашим потребностям.
Пользователь мог задавать поисковый запрос по множеству атрибутов перехваченных данных (размеры письма и частей, имена файлов, типы данных, значения произвольных почтовых и mime-заголовков и их параметров, количество вложений) и выполнять поиск по тексту писем даже несмотря на отсутствие в Oracle ConText русской морфологии. Выдача на такие запросы была вполне качественной, но у этого механизма были критичные для нас недостатки – низкая скорость выполнения поисковых запросов и отсутствие русской морфологии.
Позже, с укреплением позиций PostgreSQL на рынке, мы начали использовать его в качестве альтернативы Oracle. Вместе с PostgreSQL мы получили модуль полнотекстового поиска Tsearch2, который уже поддерживал русскую морфологию и наконец позволил нам реализовать полнотекстовый поиск по перехваченным письмам с использованием форм слов. Это значительно сократило время, которое офицеру безопасности приходилось тратить на работу с системой. Больше не надо было выполнять множество запросов, самостоятельно перебирая возможные словоформы. К тому же, на малых объемах данных Tsearch работал быстрее, чем Oracle ConText, и для некоторых заказчиков это был более удобный вариант.
Но были и серьезные недостатки:
- Отсутствие поиска по фразам.
- Скорость выполнения поисковых запросов хоть и была выше, чем у Oracle ConText, все еще оставляла желать лучшего.
В ожидании новых решений мы занимались собственными исследованиями и постоянно анализировали появляющиеся на рынке поисковые механизмы. В какой-то момент мы нашли альтернативу Oracle Text – продукт Russian context optimizer, который позволял строить индекс context'а с учетом русской морфологии. Он был чуть медленнее, но теперь мы могли реализовать поиск с использованием различных словоформ, в том числе, и по базам данных под управлением Oracle.
Скорость работы критически важна: Sphinx
Время шло, мы осваивали перехват новых каналов коммуникации, начали контролировать действия пользователей на рабочих станциях и мониторить правила хранения документов в локальной сети. Появилось большое количество разнотипных данных, выросли объемы хранения, из-за чего старые механизмы поиска стали работать медленно и неэффективно.
Стандартными средствами СУБД уже невозможно было увеличить скорость, и встал вопрос о создании внешнего индекса. После ряда исследований для этих целей была выбрана поисковая машина Sphinx (англ. SQL Phrase Index). Его можно было использовать для БД под управлением и Oracle, и PostgreSQL.
С помощью Sphinx мы выполняли полнотекстовый поиск. Для оптимизации поиска и возможности создания сложных запросов мы сначала искали с использованием внешнего индекса – выполняли полнотекстовый поиск по словоформам, а потом уже в найденном делали поиск по атрибутам писем в БД. Благодаря Sphinx скорость выполнения ряда запросов удалось существенно повысить — с десятков минут (вплоть до часов) до нескольких минут. Но это потребовало больших доработок с нашей стороны.
Кроме того, мы видели у Sphinx еще ряд недостатков:
- Один индекс можно было обновлять только в один поток. Соответственно нельзя было строить индекс параллельно из нескольких процессов, и индекс просто не успевал за новыми данными. Для решения этой проблемы нам пришлось дописывать функционал, позволяющий масштабировать поиск с учетом параллельного построения индекса на нескольких машинах.
- Поддержка только русского и самых популярных европейских языков. Для нас этот недостаток не был проблемой, но, если у вас в планах работа на международном рынке, имейте в виду, что поддерживаемых встроенных и предусмотренных плагинами языков вам будет явно недостаточно.
- Отсутствие возможностей для аналитики – построение агрегатов, статистики, топов, графиков. Все эти аналитические функции нам пришлось самостоятельно создавать с использованием СУБД, а не внешнего индекса.
- Направленность Sphinx на индексацию web-ресурсов, а не архивов сообщений. «Это не баг, это фича», но нам с этой фичей крайне трудно было смириться, поскольку для DLP-системы это совершенно чуждый функционал.
Мы продолжали мониторинг рынка на предмет интересных механизмов поиска и, среди прочего, проводили протестировали поисковую машину SOLR на файловом хранилище DLP. Скажем коротко, что по сравнению со Sphinx SOLR никаких преимуществ не продемонстрировал, и мы остались на Sphinx.
Не только быстрый, но и умный: Elastic Search
В какой-то момент наше внимание привлек Elastic Search. Он изначально обладал множеством возможностей, которые в Sphinx нам приходилось реализовывать самостоятельно. В частности, Elastic Search поддерживал распределенную архитектуру. Он позволил нам выполнять действительно быстрый поиск – уже не за минуты, а за секунды – за счет создания индекса наиболее часто используемых данных. Нагрузочные тестирования, которые мы проводили, показали, что скорость поиска с помощью Elastic Search на 17 млн сообщений составляет менее секунды. При этом пользователь все так же мог делать запросы по заголовкам и структурной информации, и это тоже реализовано средствами БД.
В общем, переход на Elastic Search позволил не только «разогнать» поиск, но и разгрузить разработку, которой больше не приходилось дорабатывать его, чтобы предоставить пользователям необходимые инструменты. При этом Elastic Search – это не только механизм поиска и хранилище, но и различные аналитические инструменты, такие как визуализация, сборщик логов и т.п.
Мы считаем, что очень важное направление развития DLP, над которым надо активно работать, – это автоматизация деятельности пользователя, т.е. безопасника. А одно из необходимых условий автоматизации – это наличие готовых срезов данных для принятия решений, которые позволяют не делать каждый раз вручную типовые запросы, а сразу получать информацию из преднастроенного дашборда.
Только средствами Elastic Search мы создали рабочий стол руководителя и администратора со множеством дашбордов, на которых представлены самые интересные с точки зрения информационной безопасности данные. Это и снижение «уровня доверия» персоны, и статистика по самым часто пересылаемым файлам, и нехарактерные контакты сотрудника относительно его окружения. Вся зона событий и инцидентов также реализована на инструментах Elastic Search. Вот как это выглядит:

Рабочий стол руководителя

Рабочий стол аналитика

Тепловая карта коммуникаций

Изменение уровня доверия в «Досье» сотрудника
В общем, как показал наш опыт, для решения задач DLP Elastic Search рядом с его предшественником Sphinx – это концепт-кар рядом с «Ладой Калиной». Но, конечно, с оговоркой, что поиск применяется к огромным архивам DLP для такой специфической и сложной задачи, как расследование инцидентов информационной безопасности. Если перед вами, как разработчиком, такие задачи не стоят, то Sphinx может быть вполне приемлемым вариантом.
Планы на будущее
Но, как бы ни был хорош Elastic Search, мы продолжаем проводить различные исследования в части улучшения его поисковых механизмов. Сейчас мы занимаемся оптимизацией существующих инструментов Elastic Search и ведем исследования по использованию нейронных сетей в качестве инструмента поиска. Так что кто знает – возможно когда-нибудь мы продолжим эту статью главой об искусственном интеллекте…
