В предыдущих статьях «SOC for beginners» мы рассказали, как устроен и как организовать базовый мониторинг инцидентов и контроль защищенности инфраструктуры. Сегодня речь пойдет о Threat Intelligence — использовании внешних источников данных об угрозах.
При всей кажущейся простоте, запуск работы с Threat Intelligence — чуть ли не самый длительный и болезненный процесс. Исключение, наверное, составляют только те случаи, когда у вас на рабочих станциях эталонные образы ОС с включенным Application Control, пользователи — без прав администратора, а доступ в интернет — исключительно по белым спискам. К сожалению, мы за все время работы таких компаний пока не встречали. В связи с этим все интересующиеся темой Threat Intelligence – добро пожаловать под кат.

В случае какой-то глобальной, сложной и страшной атаки всегда печально, если вы оказались в рядах первых жертв. У антивирусов еще нет сигнатур, у СЗИ — блэклистов, у MSSP-провайдеров и SOC’ов — индикаторов и правил, которые могли бы помочь в обнаружении. В этом случае заказчик фактически вынужден бороться с атакой своими силами (возможно, не без покупки дорогих услуг по расследованию инцидентов).
Threat Intelligence в общем случае позволяет «вторым жертвам» успеть подготовиться к отражению атаки. Конечно, это не очередная «серебряная пуля», TI не спасет от всех атак. Но при грамотно построенном процессе и правильно выбранных источниках знаний часто вполне может помочь.
О том, что такое Threat Intelligence, из чего должны состоять «хорошие» и как выглядят «плохие» индикаторы, уже написано немало статей, так что давайте сосредоточимся на том, что из себя представляют эти самые индикаторы и как с ними работать в каждом конкретном случае.
Feeds (они же фиды)
Наверное, самая объемная и часто встречающаяся информация, доступная большинству как в платном, так и в бесплатном варианте. Как правило, это постоянно обновляемые вендором выгрузки по вредоносным адресам, url'ам, e-mail'ам и т.д.
Здесь самое важное не начинать затягивать в SOC все существующие black list'ы. При анализе качества фидов основное внимание рекомендуем обращать на наличие в них расширенной информации по угрозам. Пример ниже:
IOC (Indicators of Compromise, Индикаторы компрометации)
Обычно является составной частью сводного отчета по анализу той или иной угрозы. А это значит, что каждый из индикаторов можно и нужно рассматривать не отдельно, а вместе с другими индикаторами из соответствующего отчета. Кроме того, раз есть некий отчет и аналитика, помимо индикатора мы получаем еще и контекст.
Уязвимости
Детальные описания уязвимостей и ранжирование их по критичности с учетом возможности эксплуатации именно в вашей инфраструктуре позволяет получить информацию о цепочках событий и индикаторах, которые в дальнейшем можно использовать для выявления таких попыток эксплуатации в реальной жизни.
Сценарии атаки
Сценарии атак, как правило, содержат примеры последовательности действий злоумышленника по продвижению системы. Основной пласт таких знаний по TI — это проводимые тесты на проникновение у заказчика и отчеты вендоров по APT-атакам. Получая и анализируя эту информацию, вы можете сравнивать свои текущие сценарии по детекту с теми фазами атаки, которые описаны в отчетах.
Отсюда напрашиваются два вывода:
Пользователи
Security Awareness творит чудеса. Фишинг, социальная инженерия – люди при правильном подходе дадут вам столько сэмплов, сколько ни одна песочница не выловит.
Далее, говоря об IoC/индикаторах, мы будем подразумевать, что помимо самого индикатора у нас есть хотя бы минимальная информация о том, к какому вредоносу/угрозе он относится.
Итак, как правило, индикаторы можно разделить на несколько групп:
В каждой группе индикаторы, как правило, дают разную степень достоверности результата при их обнаружении. И чем больше у вас индикаторов по одной и той же угрозе, тем больше шансов отфильтровать ложные срабатывания.
Но можно ли безусловно доверять информации, пришедшей с любой из подписок на Threat Intelligence? Ведь это обычно разбор вполне конкретных образцов ВПО, сделанный действительно квалифицированными специалистами. Возвращаемся к примерам.
Вывод, на самом деле, простой: информация, поставляемая вендорами, все равно слишком общая. В зависимости от контекста и особенностей работы инфраструктуры каждого конкретного заказчика нужен будет механизм для фильтрации части получаемой информации.
В итоге, если вы начинаете выстраивать работу с Threat Intelligence, нужно будет учитывать следующие моменты:
Настройка логирования и выбор источников событий
Попробуйте определить, какие типы индикаторов вы можете использовать и как вы будете их проверять. Например, у вас есть информация по MD5. Какие СЗИ/логи в вашей инфраструктуре могут содержать соответствующую информацию?
Из нашего опыта:
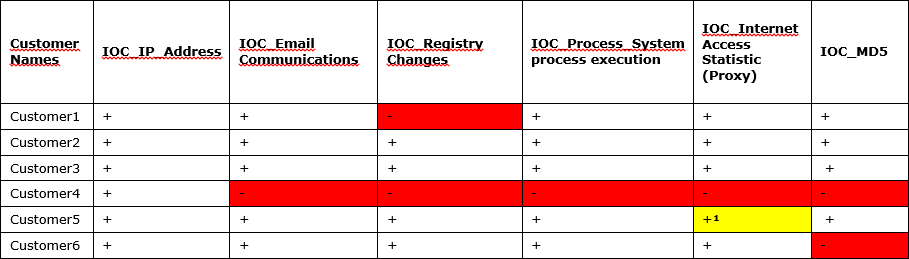
В итоге появится таблица с описанием, какие типы индикаторов на каких источниках будут детектироваться. Например, такая:
Отдельно стоит отметить, что при выборе источников событий важно правильно оценивать полноту информации. К примеру, если на прокси-сервере не включен разбор SSL, то возможности по анализу индикаторов по URL'у будут сильно ограничены, и это нужно учитывать. Например:
Возможности по реагированию
Попробуйте расписать для начала на бумаге примерную последовательность действий при обнаружении каждого индикатора. Вот примерный план:
Покрытие инфраструктуры
Как правило, чтобы обогащение событий внешними данными действительно было эффективным и приносило больше пользы, чем вреда, нужно уметь связывать сетевые индикаторы с хостовыми, а различные индикаторы из одного Threat Intelligence отчета – между собой. Например, при выявлении обращения на вредоносный домен (или даже url), проверять на АРМе/сервере наличие хостовых индикаторов (файлов, веток реестра, MD5, служб), которые относятся к соответствующей угрозе. Это можно делать вручную (подключившись к хосту), либо автоматизированно: посредством скрипта либо сканера безопасности.
Способы работы и опыление знаниями
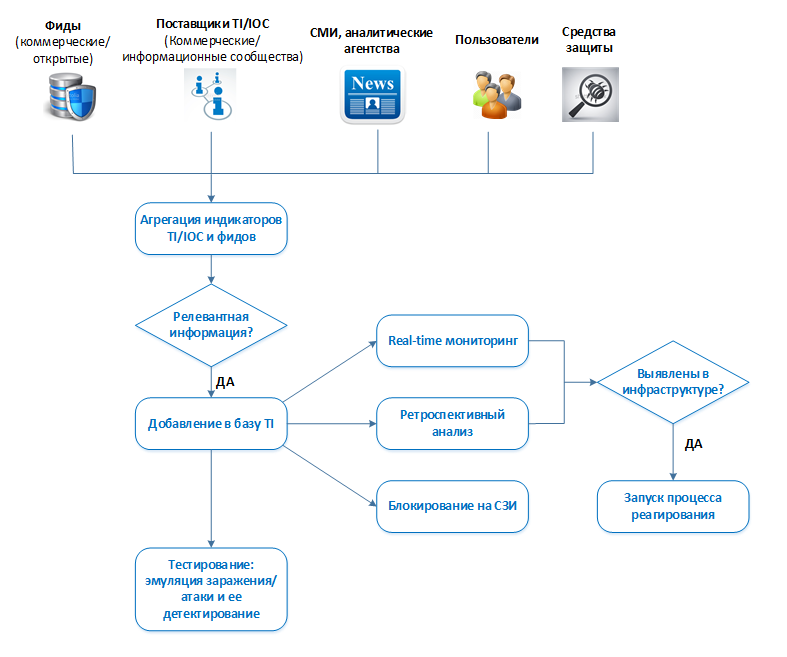
Окей. Источники подключили, данные собираются. Но как с этим работать?
Во-первых, добавляем фиды и индикаторы компрометации по какой-либо новой (или не очень) угрозе в real-time мониторинг. Не забываем при этом предварительно проверить релевантность данных индикаторов как было описано выше, чтобы исключить флудящие и неактуальные индикаторы. По-хорошему, это должен быть непрерывный процесс. Источниками таких индикаторов, помимо платных подписок и услуг специализированных компаний, могут быть, к примеру, публикации ведущих специализированных СМИ, бюллетени ведущих производителей средств защиты и исследовательских групп, анализ вредоносных рассылок, которые рассылаются на сотрудников компании. Они могут поступать в службу ИБ как от бдительных пользователей, так и забираться с антиспамов/почтовых песочниц.
Во-вторых, проводим ретроспективный поиск данных индикаторов с целью выявления фактов заражения инфраструктуры в прошлом (например, за месяц). Поиск может осуществляться по логам событий (сетевые индикаторы, почтовые, процессы), а также сканерами безопасности или скриптами (хостовые индикаторы: файлы, реестр, MD5). Посредством сканера можно сразу собрать информацию по имеющемся на хосте уязвимостям.
В-третьих, отправляем индикаторы компрометации на блокировку в ИТ или в ИБ администраторам соответствующих средств защиты.
В-четвертых, тестируем детектируемость полученных индикаторов в вашей инфраструктуре. Важный этап работы с различными разборами ВПО и атак — это воспроизведение хотя бы части этих атак с целью проверки работы своего контента и средств защиты в «тестовой среде».
Threat Intelligence, без сомнения, является важной частью любого SOC, т.к. позволяет более оперативно реагировать на внешние угрозы. Но нужно с большой тщательностью выбирать поставщиков IOC/TI и четко понимать, как работать с этой информацией в рамках конкретной компании, учитывая и имеющиеся человеческие ресурсы, и существующие технические средства для поиска фактов проявления этих самых индикаторов в инфраструктуре. Иначе весь процесс может превратиться в один кошмарный сон или, в лучшем случае, просто не дать результатов.
При всей кажущейся простоте, запуск работы с Threat Intelligence — чуть ли не самый длительный и болезненный процесс. Исключение, наверное, составляют только те случаи, когда у вас на рабочих станциях эталонные образы ОС с включенным Application Control, пользователи — без прав администратора, а доступ в интернет — исключительно по белым спискам. К сожалению, мы за все время работы таких компаний пока не встречали. В связи с этим все интересующиеся темой Threat Intelligence – добро пожаловать под кат.

В случае какой-то глобальной, сложной и страшной атаки всегда печально, если вы оказались в рядах первых жертв. У антивирусов еще нет сигнатур, у СЗИ — блэклистов, у MSSP-провайдеров и SOC’ов — индикаторов и правил, которые могли бы помочь в обнаружении. В этом случае заказчик фактически вынужден бороться с атакой своими силами (возможно, не без покупки дорогих услуг по расследованию инцидентов).
Threat Intelligence в общем случае позволяет «вторым жертвам» успеть подготовиться к отражению атаки. Конечно, это не очередная «серебряная пуля», TI не спасет от всех атак. Но при грамотно построенном процессе и правильно выбранных источниках знаний часто вполне может помочь.
Структура Threat Intelligence
О том, что такое Threat Intelligence, из чего должны состоять «хорошие» и как выглядят «плохие» индикаторы, уже написано немало статей, так что давайте сосредоточимся на том, что из себя представляют эти самые индикаторы и как с ними работать в каждом конкретном случае.
Feeds (они же фиды)
Наверное, самая объемная и часто встречающаяся информация, доступная большинству как в платном, так и в бесплатном варианте. Как правило, это постоянно обновляемые вендором выгрузки по вредоносным адресам, url'ам, e-mail'ам и т.д.
Здесь самое важное не начинать затягивать в SOC все существующие black list'ы. При анализе качества фидов основное внимание рекомендуем обращать на наличие в них расширенной информации по угрозам. Пример ниже:
Список exit-нод TOR:
torstatus.blutmagie.de — сам источник фидов содержит только TOR-ноды + есть информация по портам exit-нод + информация о статусе (оффлайн/онлайн).
panwdbl.appspot.com/lists/ettor.txt — а здесь у нас только список адресов (хотя это не официальная выгрузка, но не суть).
В первом случае мы можем настроить более узкое и корректное правило. Во втором, скорее всего, правила будут давать большее число ложных срабатываний.
IOC (Indicators of Compromise, Индикаторы компрометации)
Обычно является составной частью сводного отчета по анализу той или иной угрозы. А это значит, что каждый из индикаторов можно и нужно рассматривать не отдельно, а вместе с другими индикаторами из соответствующего отчета. Кроме того, раз есть некий отчет и аналитика, помимо индикатора мы получаем еще и контекст.
Уязвимости
Детальные описания уязвимостей и ранжирование их по критичности с учетом возможности эксплуатации именно в вашей инфраструктуре позволяет получить информацию о цепочках событий и индикаторах, которые в дальнейшем можно использовать для выявления таких попыток эксплуатации в реальной жизни.
Сценарии атаки
Сценарии атак, как правило, содержат примеры последовательности действий злоумышленника по продвижению системы. Основной пласт таких знаний по TI — это проводимые тесты на проникновение у заказчика и отчеты вендоров по APT-атакам. Получая и анализируя эту информацию, вы можете сравнивать свои текущие сценарии по детекту с теми фазами атаки, которые описаны в отчетах.
К примеру, последнее время очень сильно возросло количество шифровальщиков. При этом большая часть из них доставляется все тем же старым способом – через почтовые рассылки с файлом-дроппером во вложении. И несмотря на все «новые» методы использования того же Word'а для выполнения сторонних скриптов, поведение в ОС у всех одинаковое.
Отсюда напрашиваются два вывода:
- Надо обращать внимание на антиспам. Как показывает наша практика, у очень большого числа заказчиков нет даже простейших проверок на спуфинг адресов отправителя.
- Необходимо на регулярной основе повышать осведомленность сотрудников о новых угрозах безопасности и правилах безопасного использования внешних сервисов и внутренних ресурсов самой компании (интернет, почта, свой АРМ и т.п.).
Пользователи
Security Awareness творит чудеса. Фишинг, социальная инженерия – люди при правильном подходе дадут вам столько сэмплов, сколько ни одна песочница не выловит.
Далее, говоря об IoC/индикаторах, мы будем подразумевать, что помимо самого индикатора у нас есть хотя бы минимальная информация о том, к какому вредоносу/угрозе он относится.
Итак, как правило, индикаторы можно разделить на несколько групп:
- Сетевые индикаторы (ip, fqdn, url, email, port и т.д.).
- Хостовые индикаторы (имена файлов/процессов/служб, MD5-суммы, описания выполняемых команд, значения ключей реестра, имена пользователей/групп и т.д.).
- Другие (информационные) индикаторы. Например, иногда приходят оповещения из серии «уведомляем вас о том, что в период с Х по Y на вас планируется DDoS-атака» или «темы писем в рамках вредоносной рассылки в том или ином виде содержат слова „налоговая декларация“».
В каждой группе индикаторы, как правило, дают разную степень достоверности результата при их обнаружении. И чем больше у вас индикаторов по одной и той же угрозе, тем больше шансов отфильтровать ложные срабатывания.
Основные проблемы при работе с Threat Intelligence
Но можно ли безусловно доверять информации, пришедшей с любой из подписок на Threat Intelligence? Ведь это обычно разбор вполне конкретных образцов ВПО, сделанный действительно квалифицированными специалистами. Возвращаемся к примерам.
- Отсутствие полной информации по угрозе.
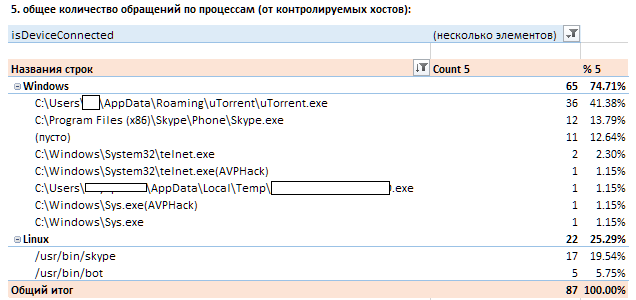
Давайте представим, что из индикаторов у вас есть только IP-адреса управляющих центров малвари. На этих адресах может быть далеко не один домен. И у вас разрешен скайп/где-то торренты или любое другое p2p-приложение. Пример тестирования индикаторов от одного из вендоров:
- Использование злоумышленниками легитимного софта.
Согласно одному из отчетов Kaspersky Lab, атакующие используют в своих целях очередное вполне себе легитимное средство для удаленного доступа — winexec. И все бы ничего, но у вас, допустим, есть СЗИ, которые для инвентаризации хостов использует ровно тот же инструмент. И индикаторы по установке служб winexesvc и запуска соответствующих процессов и обнаружения MD5-сумм будут давать вам сотни срабатываний по всей инфраструктуре.
Вывод, на самом деле, простой: информация, поставляемая вендорами, все равно слишком общая. В зависимости от контекста и особенностей работы инфраструктуры каждого конкретного заказчика нужен будет механизм для фильтрации части получаемой информации.
В итоге, если вы начинаете выстраивать работу с Threat Intelligence, нужно будет учитывать следующие моменты:
- В идеале, перед принятием решения об использовании в своей работе тех или иных баз/поставщиков IOC/TI, желательно провести их пилотирование в вашей инфраструктуре — так сказать, примерить «на живую». Например, на пару месяцев запустить их в работу и провести анализ срабатываний, оценив процент подтвердившихся.
- После выбора поставщиков IOC/TI необходимо ранжировать их по релевантности. В этом случае в зависимости от источника и даже типа индикатора реакция на алерты будет различаться. Для доверенных источников/высокорелевантных индикаторов – запуск процесса реагирования. Для остальных – сбор статистики и алерты при превышении порогов.
- Перед запуском индикаторов в real-time мониторинг лучше всего провести проверку полученной информации. Это может быть быстрая проверка по историческим данным, чтобы исключить явные фолсы, а также проверка релевантности индикаторов. Например, проверка IP-адреса на принадлежность к хостингу (если нет среди индикаторов конкретного url или домена) или проверка хеша MD5 на принадлежность к стандартным утилитам, системным файлам или средствам администрирования.
- Необходимо сразу определить сценарии реагирования на выявление тех или иных индикаторов в инфраструктуре компании, чтобы четко знать, как действовать в каждом случае — какую еще информацию собрать и проанализировать, откуда ее получить и т.п. Это существенно сократит время реагирования.
Как запустить процесс работы с Threat Intelligence
Настройка логирования и выбор источников событий
Попробуйте определить, какие типы индикаторов вы можете использовать и как вы будете их проверять. Например, у вас есть информация по MD5. Какие СЗИ/логи в вашей инфраструктуре могут содержать соответствующую информацию?
Из нашего опыта:
- Kaspersky (да и любой антивирус) хранит информацию о всех исполняемых файлах на каждом хосте (правда только о первом запуске).
- DLP/Антиспам можно настроить на логирование MD5-сумм всех почтовых вложений.
- Sysmon логирует MD5-суммы всех запускаемых процессов.
В итоге появится таблица с описанием, какие типы индикаторов на каких источниках будут детектироваться. Например, такая:

Отдельно стоит отметить, что при выборе источников событий важно правильно оценивать полноту информации. К примеру, если на прокси-сервере не включен разбор SSL, то возможности по анализу индикаторов по URL'у будут сильно ограничены, и это нужно учитывать. Например:
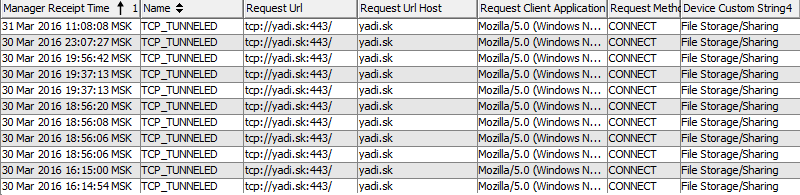
Вредоносный код представляет собой обфусцированный JavaScript-файл «Список документов для ФНС от 20.01.15.docx_I квартал 2015г. Подписано руководителем__ПРОВЕРЕНО Dr.Wеb_ef73f6db_хls.js», располагающийся по ссылке hxxps://yadi.sk/d/AXf0WGaqBpXh.
Без включенного SSL Inspection получаем реакцию на каждый вход на yadi.sk:
При возможности разбирать SSL можем реагировать только на вполне конкретные ссылки, а значит, и использовать URL в корреляции:

Возможности по реагированию
Попробуйте расписать для начала на бумаге примерную последовательность действий при обнаружении каждого индикатора. Вот примерный план:
Сработал сетевой индикатор (допустим, BadRabbit: 1dnscontrol.com/flash_install.php). Что вы будете делать дальше?
- Как будете определять хост?
- Можете ли вы проверить процесс, который инициировал это подключение?
- Будете ли проверять хостовые индикаторы (они у вас есть)?
- Есть ли у вас доступы ко всем хостам в инфраструктуре, чтобы сделать автоматическую проверку при каждом срабатывании?
- Понимаете ли вы, какая ОС на каком хосте, и применимы ли индикаторы из отчета к этой системе?
- Есть ли у вас возможность изолировать машину пользователя в любой момент времени?
- Есть ли возможность автоматизировать все перечисленные выше активности?
Покрытие инфраструктуры
Как правило, чтобы обогащение событий внешними данными действительно было эффективным и приносило больше пользы, чем вреда, нужно уметь связывать сетевые индикаторы с хостовыми, а различные индикаторы из одного Threat Intelligence отчета – между собой. Например, при выявлении обращения на вредоносный домен (или даже url), проверять на АРМе/сервере наличие хостовых индикаторов (файлов, веток реестра, MD5, служб), которые относятся к соответствующей угрозе. Это можно делать вручную (подключившись к хосту), либо автоматизированно: посредством скрипта либо сканера безопасности.
Способы работы и опыление знаниями
Окей. Источники подключили, данные собираются. Но как с этим работать?
Во-первых, добавляем фиды и индикаторы компрометации по какой-либо новой (или не очень) угрозе в real-time мониторинг. Не забываем при этом предварительно проверить релевантность данных индикаторов как было описано выше, чтобы исключить флудящие и неактуальные индикаторы. По-хорошему, это должен быть непрерывный процесс. Источниками таких индикаторов, помимо платных подписок и услуг специализированных компаний, могут быть, к примеру, публикации ведущих специализированных СМИ, бюллетени ведущих производителей средств защиты и исследовательских групп, анализ вредоносных рассылок, которые рассылаются на сотрудников компании. Они могут поступать в службу ИБ как от бдительных пользователей, так и забираться с антиспамов/почтовых песочниц.
Во-вторых, проводим ретроспективный поиск данных индикаторов с целью выявления фактов заражения инфраструктуры в прошлом (например, за месяц). Поиск может осуществляться по логам событий (сетевые индикаторы, почтовые, процессы), а также сканерами безопасности или скриптами (хостовые индикаторы: файлы, реестр, MD5). Посредством сканера можно сразу собрать информацию по имеющемся на хосте уязвимостям.
В-третьих, отправляем индикаторы компрометации на блокировку в ИТ или в ИБ администраторам соответствующих средств защиты.
В-четвертых, тестируем детектируемость полученных индикаторов в вашей инфраструктуре. Важный этап работы с различными разборами ВПО и атак — это воспроизведение хотя бы части этих атак с целью проверки работы своего контента и средств защиты в «тестовой среде».
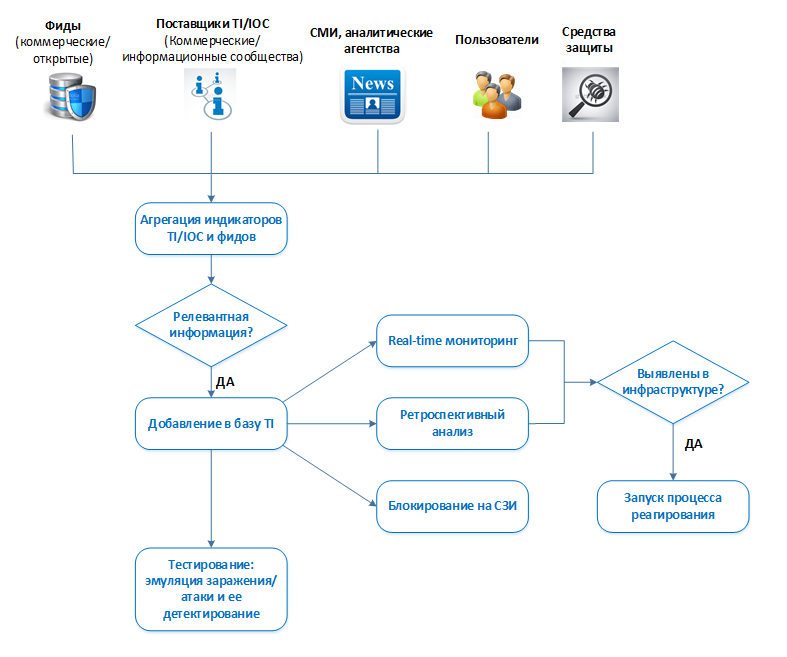
Threat Intelligence, без сомнения, является важной частью любого SOC, т.к. позволяет более оперативно реагировать на внешние угрозы. Но нужно с большой тщательностью выбирать поставщиков IOC/TI и четко понимать, как работать с этой информацией в рамках конкретной компании, учитывая и имеющиеся человеческие ресурсы, и существующие технические средства для поиска фактов проявления этих самых индикаторов в инфраструктуре. Иначе весь процесс может превратиться в один кошмарный сон или, в лучшем случае, просто не дать результатов.
