В статье об онлайн-курсе «Введение в Linux» на образовательной платформе Stepic мы обещали рассказать о технической реализации нового типа интерактивных задач, который был впервые применен в этом курсе. Этот тип задач позволяет создавать на лету виртуальные серверы с Linux для работы через веб-терминал прямо в окне браузера. Автоматическая проверяющая система следит за корректностью выполнения заданий.
Пример задания из курса:
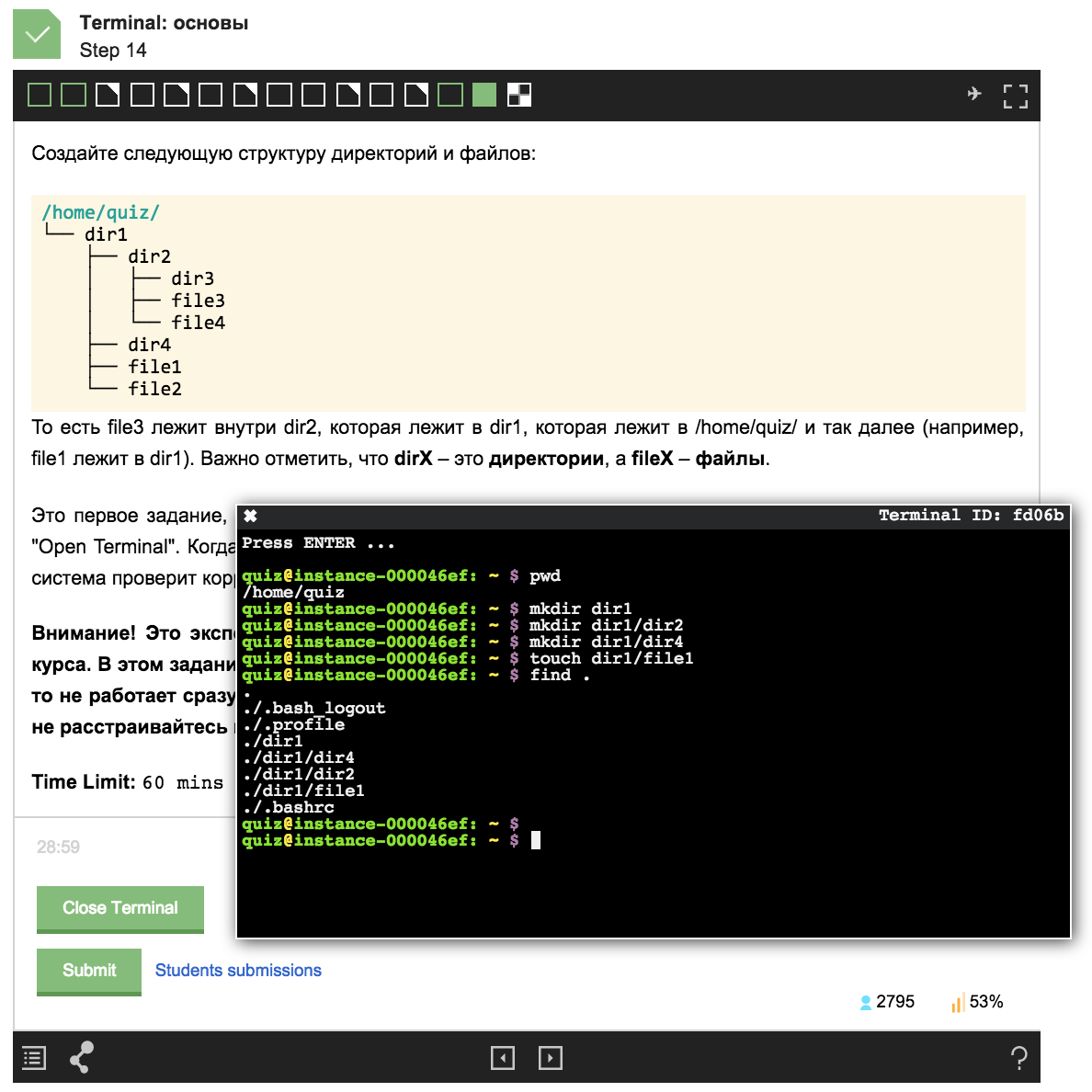
В этой статье я хочу рассказать о проекте, который лег в основу нового типа заданий на Stepic. Я также расскажу о том, из каких компонентов состоит система, и как они взаимодействуют между собой, как и где создаются удаленные сервера, как работает веб-терминал и автоматическая проверяющая система.
Я один из тех многих, кто при поиске работы не любит составлять резюме и писать десятки мотивационных писем IT-компаниям, чтобы пробиться через фильтр HR-специалистов и наконец получить от них заветное приглашение на собеседование. Куда более естественно, вместо того, чтобы писать о себе похвальные слова, показать свой реальный опыт и навыки на примере решения ежедневных задач.
Еще в 2012 году, будучи студентом Матмеха СПбГУ, я вдохновился проектом InterviewStreet, позже эволюционировавшим в проект HackerRank. Ребята разработали платформу, на которой IT-компании могут проводить онлайн-соревнования по программированию. По результатам таких соревнований компании приглашают лучших участников пройти собеседование. В дополнение к рекрутингу целью проекта HackerRank стало создание сайта, на котором любой желающий может развивать навыки программирования через решение задач из разных областей Computer Science, таких как теория алгоритмов, искусственный интеллект, машинное обучение и другие. Уже тогда существовало большое количество других платформ, на которых проводились соревнования для программистов. Активно набирали популярность интерактивные онлайн-платформы для обучения программированию, такие как Codecademy и Code School. К тому моменту я имел достаточный опыт работы системным администратором Linux и хотел видеть подобные ресурсы для упрощения процесса трудоустройства системных инженеров, проведения соревнований по администрированию Linux, ресурсы для обучения системному администрированию путем решения реальных задач в этой области.
После упорного поиска из похожих проектов нашелся только LinuxZoo, разработанный для академических целей в Эдинбургском университете им. Непера (Edinburgh Napier University). Мне также попался на глаза промо-ролик весьма успешного и амбициозного проекта Coderloop, уже тогда заброшенного после покупки компанией Gild. В этом ролике я увидел именно то, о чем тогда мечтал. К сожалению, разработанная в Coderloop технология для создания интерактивных упражнений по системному администрированию так и не увидела свет. Во время переписки с одним из основателей проекта Coderloop я получил много теплых слов и пожеланий по разработке и дальнейшему развитию этой идеи. Моему вдохновению не было предела. Так я начал разработку платформы Root’n'Roll, которой стал посвящать практически все свое свободное время.
Основной целью проекта стало не создание конкретного ресурса для обучения, проведения соревнований или рекрутинга системных инженеров, а нечто большее — создание базовой технической платформы, на которой можно было бы строить и развивать любое из этих направлений.
Ключевыми требованиями базовой платформы стали следующие:
Все перечисленные требования в какой-то мере уже удалось реализовать. Обо всем по порядку.
Для запуска виртуальных машин сначала нужно было определиться с технологией виртуализации. Варианты с гипервизорной виртуализацией: аппаратной (KVM, VMware ESXi) и паравиртуализацией (Xen) — отпали довольно быстро. Эти подходы имеют довольно большие накладные расходы на системные ресурсы, в частности память, т.к. для каждой машины запускается свое отдельное ядро, и стартуют различные подсистемы ОС. Виртуализации такого типа также требуют наличия выделенного физического сервера, к тому же, при заявленном желании запускать сотни виртуалок, с весьма неплохим «железом». Для наглядности можно посмотреть на технические характеристики серверной инфраструктуры, используемой в проекте LinuxZoo.
Далее фокус пал на системы виртуализации уровня операционной системы (OpenVZ и Linux Containers (LXC)). Контейнерную виртуализацию можно очень грубо сравнить с запуском процессов в изолированном chroot окружении. Про сравнение и технические характеристики различных систем виртуализации написано уже огромное количество статей, в том числе на хабре, поэтому не останавливаюсь на подробностях их реализации. Контейнеризация не имеет таких накладных расходов, как полноценная виртуализации, потому что все контейнеры разделяют одно ядро хостовой системы.
Как раз к моменту моего выбора виртуализации успел выйти в Open Source и нашуметь о себе проект Docker, предоставляющий инструменты и среду для создания и управления LXC-контейнерами. Запуск LXC-контейнера под управлением Docker (далее docker-контейнер или просто контейнер) сравним с запуском процесса в Linux. Как и обычному linux-процессу, контейнеру не нужно заранее резервировать оперативную память. Память выделяется и очищается по мере использования. Если нужно, можно установить гибкие ограничения на максимальный объем используемой памяти в контейнере. Огромное преимущество контейнеров в том, что для контроля их памятью используется общая хостовая подсистема управления страницами памяти (в том числе механизм copy-on-write и разделяемые страницы). Это позволяет увеличить плотность размещения контейнеров, то есть можно запускать гораздо больше экземпляров linux-машин, чем при использовании гипервизорных систем виртуализации. Благодаря этому достигается эффективная утилизация ресурсов сервера. С запуском нескольких сотен docker-контейнеров с процессом bash внутри запросто справится даже micro-инстенс в облаке Amazon EC2. Еще один приятный бонус — сам процесс запуска контейнера занимает миллисекунды.
Таким образом, на первый взгляд Docker дешево решал задачу запуска большого количества машин (контейнеров), поэтому для первого proof-of-concept решения я решил остановиться именно на нем. Вопрос о безопасности достоин отдельного обсуждения, пока опустим. Кстати, ребята из Coderloop для создания виртуальных окружений в своих упражнениях также использовали LXC-контейнеры.
Docker предоставляет программный REST-интерфейс для создания и запуска контейнеров. Через этот интерфейс можно управлять только контейнерами, находящимися на том же сервере, на котором запущен сервис docker.
Если заглянуть на один шаг вперед, то хорошо было бы иметь возможность горизонтально масштабироваться, то есть запускать все контейнеры не на одном сервере, а распределить их на несколько серверов. Для этого необходимо иметь централизованное управление docker-хостами и планировщик, позволяющий балансировать нагрузку между несколькими серверами. Наличие планировщика может быть очень полезно во время технического обслуживания сервера, например, установки обновлений, требующих перезагрузку. В таком случае сервер помечается как «в обслуживании», в результате чего новые контейнеры на нем не создаются.
Дополнительные требования к централизованной системе управления — настройка сети в контейнерах и управление квотами системных ресурсов (процессор, память, диск). А ведь эти все требования — это не что иное, как задачи, которые успешно решаются облаками (IaaS). Своевременно летом 2013 вышел пост от разработчиков Docker об интеграции Docker с облачной платформой OpenStack. Новый nova-docker драйвер позволяет с помощью openstack-облака управлять парком docker-хостов: запускать контейнеры, поднимать сеть, контролировать и балансировать потребление системных ресурсов — именно то, что нам нужно!
К сожалению, даже на сегодняшний день nova-docker драйвер все еще довольно «сырой». Часто появляются изменения, несовместимые даже с последней стабильной версией openstack’а. Приходится самостоятельно поддерживать отдельную стабильную ветку драйвера. Пришлось также написать несколько патчей, улучшающих производительность. К примеру, для получения статуса одного docker-контейнера драйвер запрашивал статусы всех запущенных контейнеров (посылал N http-запросов к docker-хосту, где N — число всех контейнеров). В случае запуска нескольких сотен контейнеров создавалась ненужная нагрузка на docker-хосты.
Несмотря на определенные неудобства, выбор OpenStack'а в качестве оркестратора контейнеров в моем случае все же того стоит: появилась централизованная система управления виртуальными машинами (контейнерами) и вычислительными ресурсами с единым API. Большой бонус единого интерфейса заключается еще в том, что добавление в Root’n’Roll поддержки полноценных виртуальных машин на базе KVM не потребует никаких существенных изменений в архитектуре и коде самой платформы.
Из недостатков OpenStack можно отметить лишь довольно высокую сложность разворачивания и администрирования приватного облака. Совсем недавно заявил о себе достойный внимания проект Virtkick — этакая упрощенная альтернатива OpenStack. С нетерпением жду его успешного развития.
Еще на начальном этапе составления требований к платформе Root’n’Roll основной фичей, которую я хотел видеть в первую очередь, была возможность работы с удаленным linux-сервером через окно веб-терминала прямо у себя в браузере. Именно с выбора терминала и началась разработка, а точнее изучение и выбор технических решений для платформы. Веб-терминал является едва ли не единственной точкой входа пользователя во всю систему. Это именно то, что он в первую очередь видит и с чем работает.
Одним из немногих в то время онлайн-проектов, в которых активно использовался веб-терминал был PythonAnywhere. Он стал эталоном, на который я периодически посматривал. Это сейчас уже появилось огромное количество веб-проектов и облачных сред разработки, в которых можно увидеть терминалы: Koding, Nitrous, Codebox, Runnable и др.
Любой веб-терминал состоит из двух основных частей:
Было рассмотрено множество эмуляторов терминала: Anyterm, Ajaxterm, Shellinabox (используется в PythonAnywhere), Secure Shell, GateOne и tty.js. Последние два оказались наиболее функциональными и активно развивающимися. Из-за распространения под более свободной лицензией MIT выбор остановился на tty.js. Tty.js является client-side эмулятором терминала (разбор сырого вывода терминала, в том числе управляющих последовательностей, выполняется на клиенте с помощью JavaScript).
Серверная часть tty.js, написанная на Node.js, была беспощадно отломана и переписана на Python. Транспорт Socket.IO был заменен на SockJS, о подобном удачном опыте уже писали в блоге PythonAnywhere.
Наконец дошли до движка платформы Root’n’Roll. Проект построен по принципам микросервисной архитектуры. Основной язык разработки серверной части — Python.
Диаграмма связей сервисов платформы Root’n’Roll:

Микросервисы носят имена основных героев научно-фантастического телесериала «Светлячок» (Firefly). Основные герои фильма — экипаж межпланетного космического корабля «Серенити» класса Светлячок. Назначение и место персонажа на корабле в некоторой степени отражает предназначение и функционал соответствующего его имени сервиса.
 Mal — владелец и капитан корабля. На нашем корабле Mal является ключевым сервисом, координирующим работу всех остальных сервисов. Это приложение на Django, которое реализует бизнес-логику платформы Root’n’Roll. Mal выполняет роль API-клиента приватного OpenStack-облака и в свою очередь предоставляет высокоуровневый REST интерфейс для выполнения следующих действий:
Mal — владелец и капитан корабля. На нашем корабле Mal является ключевым сервисом, координирующим работу всех остальных сервисов. Это приложение на Django, которое реализует бизнес-логику платформы Root’n’Roll. Mal выполняет роль API-клиента приватного OpenStack-облака и в свою очередь предоставляет высокоуровневый REST интерфейс для выполнения следующих действий:
 Kaylee — механик корабля. Сервис Kaylee является двигателем процесса коммуникации веб-терминала с удаленной виртуальной машиной. Это асинхронный веб-сервер на Python и Tornado, реализующий серверную часть tty.js.
Kaylee — механик корабля. Сервис Kaylee является двигателем процесса коммуникации веб-терминала с удаленной виртуальной машиной. Это асинхронный веб-сервер на Python и Tornado, реализующий серверную часть tty.js.
С одной стороны, клиентская часть tty.js (терминальное окно) устанавливает соединение с Kaylee по протоколу SockJS. С другой стороны, Kaylee устанавливает соединение с терминальным устройством виртуальной машины. В случае с docker-контейнерами соединение устанавливается по протоколу HTTPS с управляющим pty-устройством работающего в контейнере процесса, как правило, это процесс bash. После чего Kaylee выполняет простую функцию прокси-сервера между двумя установленными соединениями.
Для аутентификации клиента и получения данных о виртуальной машине Kaylee общается с Mal по REST API.
 Zoe — помощник капитана на борту, во всем ему безоговорочно доверяет. Zoe является автоматической проверяющей системой, выполняющей тестирование конфигураций виртуальных машин. Сервис Zoe в виде celery-таски получает от Mal’а задание на запуск тестового сценария. По окончанию проверки сообщает по REST API обратно Mal’у результаты тестирования. Как правило, Zoe ошибок не прощает (многие участники курса по Linux на Stepic’е уже успели в этом убедиться).
Zoe — помощник капитана на борту, во всем ему безоговорочно доверяет. Zoe является автоматической проверяющей системой, выполняющей тестирование конфигураций виртуальных машин. Сервис Zoe в виде celery-таски получает от Mal’а задание на запуск тестового сценария. По окончанию проверки сообщает по REST API обратно Mal’у результаты тестирования. Как правило, Zoe ошибок не прощает (многие участники курса по Linux на Stepic’е уже успели в этом убедиться).
Тестовый сценарий представляет из себя не что иное, как Python-скрипт с набором тестов, написанных с использованием фреймворка для тестирования py.test. Для py.test был разработан специальный плагин, который обрабатывает результаты запуска тестов и посылает их Mal'у по REST API.
Пример сценария для упражнения, в котором нужно написать и запустить простой одностраничный сайт на веб-фреймворке Django:
Для удаленного выполнения команд на тестируемой виртуальной машине Zoe использует библиотеку Fabric.
Вскоре на платформе Stepic любой желающий сможет создавать свои курсы и интерактивные упражнения по работе в Linux с использованием всех тех технологий, о которых я рассказал в статье.
В следующей статье я напишу о своем успешном участии в JetBrains EdTech хакатоне, об особенностях и проблемах интеграции Root’n’Roll в Stepic и, по вашему желанию, раскрою глубже любую из затронутых тем.
Пример задания из курса:
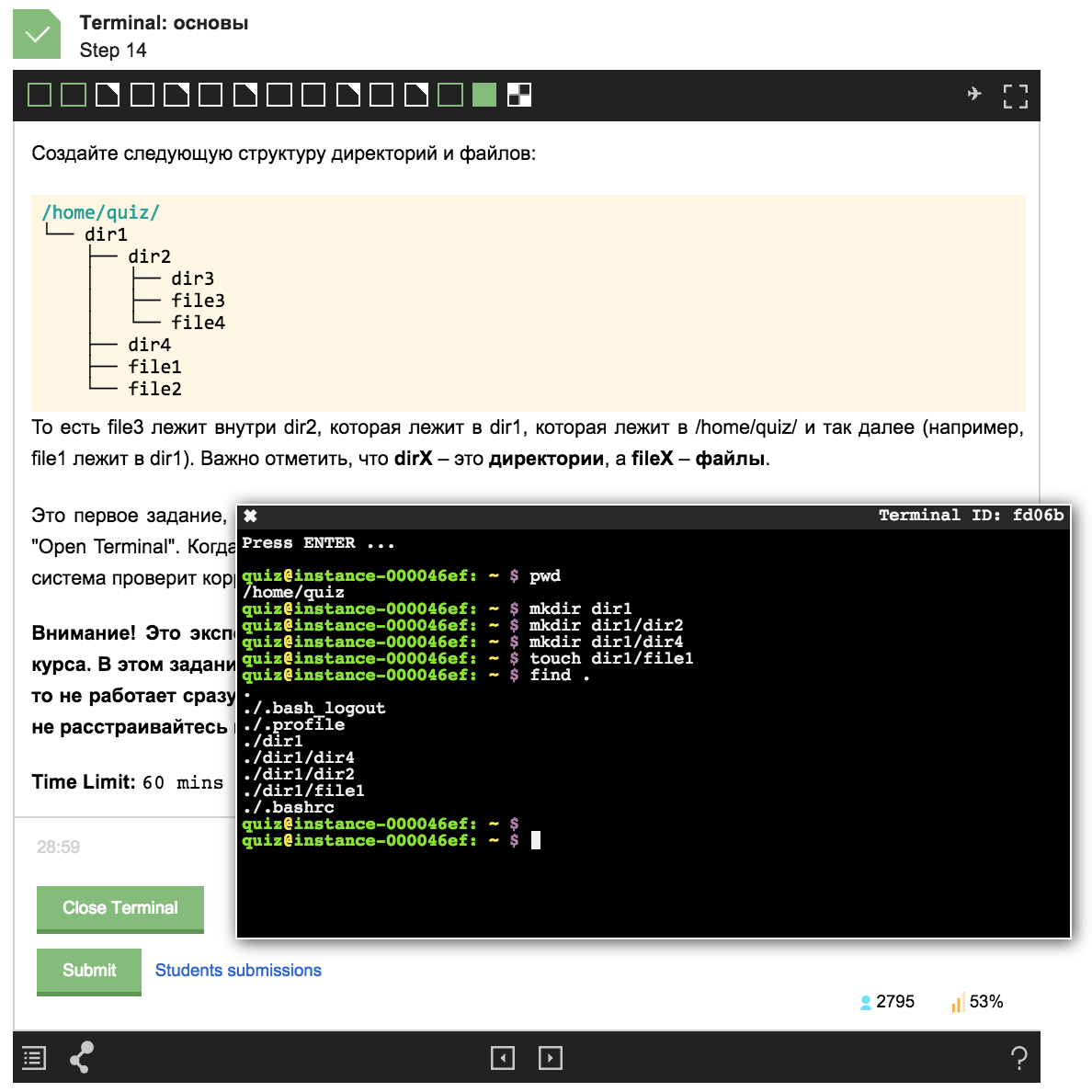
В этой статье я хочу рассказать о проекте, который лег в основу нового типа заданий на Stepic. Я также расскажу о том, из каких компонентов состоит система, и как они взаимодействуют между собой, как и где создаются удаленные сервера, как работает веб-терминал и автоматическая проверяющая система.
Вдохновение
Я один из тех многих, кто при поиске работы не любит составлять резюме и писать десятки мотивационных писем IT-компаниям, чтобы пробиться через фильтр HR-специалистов и наконец получить от них заветное приглашение на собеседование. Куда более естественно, вместо того, чтобы писать о себе похвальные слова, показать свой реальный опыт и навыки на примере решения ежедневных задач.
Еще в 2012 году, будучи студентом Матмеха СПбГУ, я вдохновился проектом InterviewStreet, позже эволюционировавшим в проект HackerRank. Ребята разработали платформу, на которой IT-компании могут проводить онлайн-соревнования по программированию. По результатам таких соревнований компании приглашают лучших участников пройти собеседование. В дополнение к рекрутингу целью проекта HackerRank стало создание сайта, на котором любой желающий может развивать навыки программирования через решение задач из разных областей Computer Science, таких как теория алгоритмов, искусственный интеллект, машинное обучение и другие. Уже тогда существовало большое количество других платформ, на которых проводились соревнования для программистов. Активно набирали популярность интерактивные онлайн-платформы для обучения программированию, такие как Codecademy и Code School. К тому моменту я имел достаточный опыт работы системным администратором Linux и хотел видеть подобные ресурсы для упрощения процесса трудоустройства системных инженеров, проведения соревнований по администрированию Linux, ресурсы для обучения системному администрированию путем решения реальных задач в этой области.
После упорного поиска из похожих проектов нашелся только LinuxZoo, разработанный для академических целей в Эдинбургском университете им. Непера (Edinburgh Napier University). Мне также попался на глаза промо-ролик весьма успешного и амбициозного проекта Coderloop, уже тогда заброшенного после покупки компанией Gild. В этом ролике я увидел именно то, о чем тогда мечтал. К сожалению, разработанная в Coderloop технология для создания интерактивных упражнений по системному администрированию так и не увидела свет. Во время переписки с одним из основателей проекта Coderloop я получил много теплых слов и пожеланий по разработке и дальнейшему развитию этой идеи. Моему вдохновению не было предела. Так я начал разработку платформы Root’n'Roll, которой стал посвящать практически все свое свободное время.
Цели Root’n’Roll
Основной целью проекта стало не создание конкретного ресурса для обучения, проведения соревнований или рекрутинга системных инженеров, а нечто большее — создание базовой технической платформы, на которой можно было бы строить и развивать любое из этих направлений.
Ключевыми требованиями базовой платформы стали следующие:
- Иметь возможность максимально быстро и дешево запускать одновременно сотни или даже тысячи виртуальных машин с минимальной Linux-системой, которые можно безопасно вместе с root-правами отдать на растерзание пользователям. Дешево — значит минимизировать количество потребляемых системных ресурсов на одну виртуальную машину. Отсутствие какого-либо существенного бюджета подразумевает отказ от использования облачного хостинга вроде Amazon EC2 или Rackspace по принципу «одна виртуальная машина» = «один облачный инстенс».
- Позволять работать с виртуальной машиной через веб-терминал прямо в окне браузера. Никакие внешние программы для этого не требуются, только веб-браузер.
- Наконец, иметь интерфейс для тестирования конфигурации любой виртуальной машины. Тестирование конфигурации может включать в себя как проверку состояния файловой системы (лежат ли нужные файлы на своих местах, корректно ли их содержимое), так и проверки сервисов и сетевой активности (запущены ли какие-то сервисы, правильно ли они настроены, корректно ли отвечают на определенные сетевые запросы и т.д.).
Все перечисленные требования в какой-то мере уже удалось реализовать. Обо всем по порядку.
Запуск виртуальных машин
Для запуска виртуальных машин сначала нужно было определиться с технологией виртуализации. Варианты с гипервизорной виртуализацией: аппаратной (KVM, VMware ESXi) и паравиртуализацией (Xen) — отпали довольно быстро. Эти подходы имеют довольно большие накладные расходы на системные ресурсы, в частности память, т.к. для каждой машины запускается свое отдельное ядро, и стартуют различные подсистемы ОС. Виртуализации такого типа также требуют наличия выделенного физического сервера, к тому же, при заявленном желании запускать сотни виртуалок, с весьма неплохим «железом». Для наглядности можно посмотреть на технические характеристики серверной инфраструктуры, используемой в проекте LinuxZoo.
Далее фокус пал на системы виртуализации уровня операционной системы (OpenVZ и Linux Containers (LXC)). Контейнерную виртуализацию можно очень грубо сравнить с запуском процессов в изолированном chroot окружении. Про сравнение и технические характеристики различных систем виртуализации написано уже огромное количество статей, в том числе на хабре, поэтому не останавливаюсь на подробностях их реализации. Контейнеризация не имеет таких накладных расходов, как полноценная виртуализации, потому что все контейнеры разделяют одно ядро хостовой системы.
Как раз к моменту моего выбора виртуализации успел выйти в Open Source и нашуметь о себе проект Docker, предоставляющий инструменты и среду для создания и управления LXC-контейнерами. Запуск LXC-контейнера под управлением Docker (далее docker-контейнер или просто контейнер) сравним с запуском процесса в Linux. Как и обычному linux-процессу, контейнеру не нужно заранее резервировать оперативную память. Память выделяется и очищается по мере использования. Если нужно, можно установить гибкие ограничения на максимальный объем используемой памяти в контейнере. Огромное преимущество контейнеров в том, что для контроля их памятью используется общая хостовая подсистема управления страницами памяти (в том числе механизм copy-on-write и разделяемые страницы). Это позволяет увеличить плотность размещения контейнеров, то есть можно запускать гораздо больше экземпляров linux-машин, чем при использовании гипервизорных систем виртуализации. Благодаря этому достигается эффективная утилизация ресурсов сервера. С запуском нескольких сотен docker-контейнеров с процессом bash внутри запросто справится даже micro-инстенс в облаке Amazon EC2. Еще один приятный бонус — сам процесс запуска контейнера занимает миллисекунды.
Таким образом, на первый взгляд Docker дешево решал задачу запуска большого количества машин (контейнеров), поэтому для первого proof-of-concept решения я решил остановиться именно на нем. Вопрос о безопасности достоин отдельного обсуждения, пока опустим. Кстати, ребята из Coderloop для создания виртуальных окружений в своих упражнениях также использовали LXC-контейнеры.
Управление контейнерами
Docker предоставляет программный REST-интерфейс для создания и запуска контейнеров. Через этот интерфейс можно управлять только контейнерами, находящимися на том же сервере, на котором запущен сервис docker.
Если заглянуть на один шаг вперед, то хорошо было бы иметь возможность горизонтально масштабироваться, то есть запускать все контейнеры не на одном сервере, а распределить их на несколько серверов. Для этого необходимо иметь централизованное управление docker-хостами и планировщик, позволяющий балансировать нагрузку между несколькими серверами. Наличие планировщика может быть очень полезно во время технического обслуживания сервера, например, установки обновлений, требующих перезагрузку. В таком случае сервер помечается как «в обслуживании», в результате чего новые контейнеры на нем не создаются.
Дополнительные требования к централизованной системе управления — настройка сети в контейнерах и управление квотами системных ресурсов (процессор, память, диск). А ведь эти все требования — это не что иное, как задачи, которые успешно решаются облаками (IaaS). Своевременно летом 2013 вышел пост от разработчиков Docker об интеграции Docker с облачной платформой OpenStack. Новый nova-docker драйвер позволяет с помощью openstack-облака управлять парком docker-хостов: запускать контейнеры, поднимать сеть, контролировать и балансировать потребление системных ресурсов — именно то, что нам нужно!
К сожалению, даже на сегодняшний день nova-docker драйвер все еще довольно «сырой». Часто появляются изменения, несовместимые даже с последней стабильной версией openstack’а. Приходится самостоятельно поддерживать отдельную стабильную ветку драйвера. Пришлось также написать несколько патчей, улучшающих производительность. К примеру, для получения статуса одного docker-контейнера драйвер запрашивал статусы всех запущенных контейнеров (посылал N http-запросов к docker-хосту, где N — число всех контейнеров). В случае запуска нескольких сотен контейнеров создавалась ненужная нагрузка на docker-хосты.
Несмотря на определенные неудобства, выбор OpenStack'а в качестве оркестратора контейнеров в моем случае все же того стоит: появилась централизованная система управления виртуальными машинами (контейнерами) и вычислительными ресурсами с единым API. Большой бонус единого интерфейса заключается еще в том, что добавление в Root’n’Roll поддержки полноценных виртуальных машин на базе KVM не потребует никаких существенных изменений в архитектуре и коде самой платформы.
Из недостатков OpenStack можно отметить лишь довольно высокую сложность разворачивания и администрирования приватного облака. Совсем недавно заявил о себе достойный внимания проект Virtkick — этакая упрощенная альтернатива OpenStack. С нетерпением жду его успешного развития.
Выбор веб-терминала
Еще на начальном этапе составления требований к платформе Root’n’Roll основной фичей, которую я хотел видеть в первую очередь, была возможность работы с удаленным linux-сервером через окно веб-терминала прямо у себя в браузере. Именно с выбора терминала и началась разработка, а точнее изучение и выбор технических решений для платформы. Веб-терминал является едва ли не единственной точкой входа пользователя во всю систему. Это именно то, что он в первую очередь видит и с чем работает.
Одним из немногих в то время онлайн-проектов, в которых активно использовался веб-терминал был PythonAnywhere. Он стал эталоном, на который я периодически посматривал. Это сейчас уже появилось огромное количество веб-проектов и облачных сред разработки, в которых можно увидеть терминалы: Koding, Nitrous, Codebox, Runnable и др.
Любой веб-терминал состоит из двух основных частей:
- Клиентской: динамическое JavaScript приложение, занимающееся перехватом нажатий клавиш и отсылкой их серверной части, приемом данных от серверной части и их отрисовкой в веб-браузере пользователя.
- Серверной: веб-сервис, который принимает сообщения о нажатиях клавиш от клиента и отправляет их в управляющее терминальное устройство (pseudo terminal или PTY) связанного с терминалом процесса, например bash. Сырой вывод терминала из pty-устройства пересылается неизменным в клиентскую часть или обрабатывается на стороне сервера, в этом случае в клиентскую часть передается уже преобразованным, например, в формате HTML.
Было рассмотрено множество эмуляторов терминала: Anyterm, Ajaxterm, Shellinabox (используется в PythonAnywhere), Secure Shell, GateOne и tty.js. Последние два оказались наиболее функциональными и активно развивающимися. Из-за распространения под более свободной лицензией MIT выбор остановился на tty.js. Tty.js является client-side эмулятором терминала (разбор сырого вывода терминала, в том числе управляющих последовательностей, выполняется на клиенте с помощью JavaScript).
Серверная часть tty.js, написанная на Node.js, была беспощадно отломана и переписана на Python. Транспорт Socket.IO был заменен на SockJS, о подобном удачном опыте уже писали в блоге PythonAnywhere.
Полет «Светлячка»
Наконец дошли до движка платформы Root’n’Roll. Проект построен по принципам микросервисной архитектуры. Основной язык разработки серверной части — Python.
Диаграмма связей сервисов платформы Root’n’Roll:
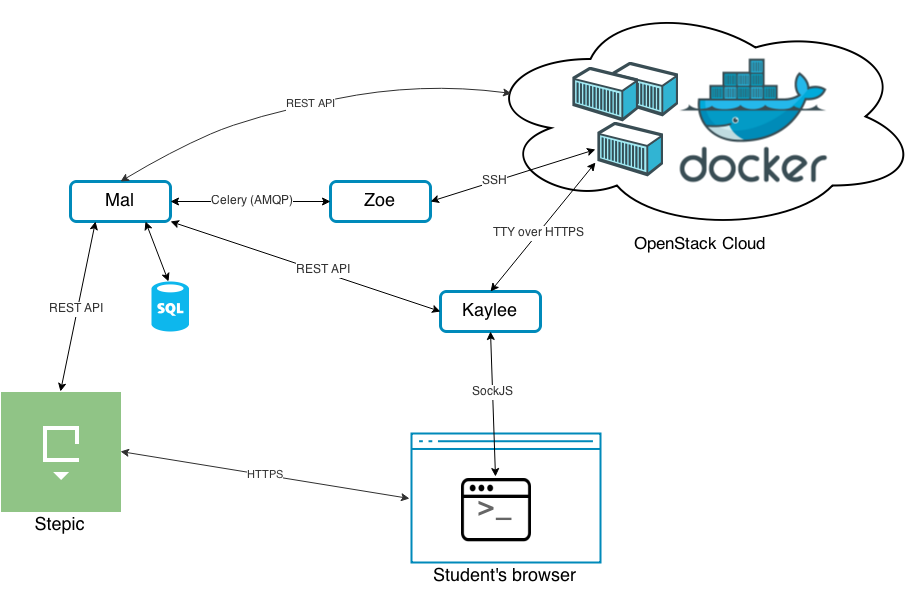
Микросервисы носят имена основных героев научно-фантастического телесериала «Светлячок» (Firefly). Основные герои фильма — экипаж межпланетного космического корабля «Серенити» класса Светлячок. Назначение и место персонажа на корабле в некоторой степени отражает предназначение и функционал соответствующего его имени сервиса.
Mal – backend API
 Mal — владелец и капитан корабля. На нашем корабле Mal является ключевым сервисом, координирующим работу всех остальных сервисов. Это приложение на Django, которое реализует бизнес-логику платформы Root’n’Roll. Mal выполняет роль API-клиента приватного OpenStack-облака и в свою очередь предоставляет высокоуровневый REST интерфейс для выполнения следующих действий:
Mal — владелец и капитан корабля. На нашем корабле Mal является ключевым сервисом, координирующим работу всех остальных сервисов. Это приложение на Django, которое реализует бизнес-логику платформы Root’n’Roll. Mal выполняет роль API-клиента приватного OpenStack-облака и в свою очередь предоставляет высокоуровневый REST интерфейс для выполнения следующих действий:- Создание/удаление виртуальной машины (контейнера). Запрос преобразовывается и делегируется облаку.
- Создание и подключение терминала к контейнеру.
- Запуск тестового сценария для проверки конфигурации виртуальной машины. Запрос делегируется микросервису проверяющей системы.
- Получение результатов проверки конфигурации.
- Аутентификация клиентов и авторизация различных действий.
Kaylee – мультиплексор терминалов
 Kaylee — механик корабля. Сервис Kaylee является двигателем процесса коммуникации веб-терминала с удаленной виртуальной машиной. Это асинхронный веб-сервер на Python и Tornado, реализующий серверную часть tty.js.
Kaylee — механик корабля. Сервис Kaylee является двигателем процесса коммуникации веб-терминала с удаленной виртуальной машиной. Это асинхронный веб-сервер на Python и Tornado, реализующий серверную часть tty.js.С одной стороны, клиентская часть tty.js (терминальное окно) устанавливает соединение с Kaylee по протоколу SockJS. С другой стороны, Kaylee устанавливает соединение с терминальным устройством виртуальной машины. В случае с docker-контейнерами соединение устанавливается по протоколу HTTPS с управляющим pty-устройством работающего в контейнере процесса, как правило, это процесс bash. После чего Kaylee выполняет простую функцию прокси-сервера между двумя установленными соединениями.
Для аутентификации клиента и получения данных о виртуальной машине Kaylee общается с Mal по REST API.
Zoe – check-система
 Zoe — помощник капитана на борту, во всем ему безоговорочно доверяет. Zoe является автоматической проверяющей системой, выполняющей тестирование конфигураций виртуальных машин. Сервис Zoe в виде celery-таски получает от Mal’а задание на запуск тестового сценария. По окончанию проверки сообщает по REST API обратно Mal’у результаты тестирования. Как правило, Zoe ошибок не прощает (многие участники курса по Linux на Stepic’е уже успели в этом убедиться).
Zoe — помощник капитана на борту, во всем ему безоговорочно доверяет. Zoe является автоматической проверяющей системой, выполняющей тестирование конфигураций виртуальных машин. Сервис Zoe в виде celery-таски получает от Mal’а задание на запуск тестового сценария. По окончанию проверки сообщает по REST API обратно Mal’у результаты тестирования. Как правило, Zoe ошибок не прощает (многие участники курса по Linux на Stepic’е уже успели в этом убедиться).Тестовый сценарий представляет из себя не что иное, как Python-скрипт с набором тестов, написанных с использованием фреймворка для тестирования py.test. Для py.test был разработан специальный плагин, который обрабатывает результаты запуска тестов и посылает их Mal'у по REST API.
Пример сценария для упражнения, в котором нужно написать и запустить простой одностраничный сайт на веб-фреймворке Django:
import re
import requests
def test_connection(s):
assert s.run('true').succeeded, "Could not connect to server"
def test_is_django_installed(s):
assert s.run('python -c "import django"').succeeded, "Django is not installed"
def test_is_project_created(s):
assert s.run('[ -x /home/quiz/llama/manage.py ]').succeeded, "Project is not created"
def test_hello_lama(s):
try:
r = requests.get("http://%s:8080/" % s.ip)
except:
assert False, "Service is not running"
if r.status_code != 200 or not re.match(".*Hello, lama.*", r.text):
assert False, "Incorrect response"
Для удаленного выполнения команд на тестируемой виртуальной машине Zoe использует библиотеку Fabric.
Заключение
Вскоре на платформе Stepic любой желающий сможет создавать свои курсы и интерактивные упражнения по работе в Linux с использованием всех тех технологий, о которых я рассказал в статье.
В следующей статье я напишу о своем успешном участии в JetBrains EdTech хакатоне, об особенностях и проблемах интеграции Root’n’Roll в Stepic и, по вашему желанию, раскрою глубже любую из затронутых тем.
