Мои коллеги уже писали о разработке онлайн редакторов TeamLab на canvas. Сегодня посмотрим на рабочий процесс глазами специалистов по тестированию, ведь не только продукт с точки зрения разработчиков был инновационен благодаря выбранной технологии, но и задача проверки качества продукта оказалась новой, ранее никем еще не решаемой.

Последние 8 месяцев своей жизни я и мои коллеги провели, тестируя абсолютно новый редактор документов, написанный на HTML5. Тестировать инновационные продукты сложно, хотя бы потому что до нас этого никто не делал.
Для реализации всех наших идей нам потребовались сторонние инструменты:
А дальше понеслось самое важное и интересное. Нажать на кнопку и ввести текст достаточно просто, а вот как верифицировать то, что было создано? Как проверить, что все выполненное автоматическими тестами сделано правильно?
Много копий было сломано в процессе поиска нужного метода сравнения с эталоном. В результате мы пришли к выводу, что информацию о произведенных действиях и, соответственно, об успешности прохождения тестов можно получать двумя способами:
1. С помощью API самого приложения.
2. С помощью своего собственного парсера документов.
Положительные стороны:
Отрицательные стороны:
Положительные стороны:
Отрицательные стороны:
В итоге мы выбрали оба варианта, но использовали их в разных пропорциях: около 90 % верификации тестов реализовано посредством парсера и только 10% — посредством API. Это позволило быстро написать первые тесты с помощью API и постепенно развивать функциональные тесты совместно с разработкой парсера.
В качестве формата для парсинга был выбран DOCX. Связано это с тем, что:
Стороннюю библиотеку для парсинга DOCX, которая поддерживала бы необходимый нам набор функций, мы найти так и не смогли. Впоследствии аналогичная ситуация сложилась и с другим форматом, когда при тестирровании редактора таблиц нам потребовался парсер XLSX.
За парсер отвечает только один специалист. Основной костяк функционала был реализован примерно за месяц, но до сих пор постоянно поддерживается — исправляются баги (которых, к слову, для существующего функционала почти не осталось), а также добавляется поддержка для нового функционала, введенного в редактор документов.
Пример:
Рассмотрим простой пример: документ из одного абзаца с размером текста 20, шрифтом Times New Roman и выставленными опциями Bold и Italic. Для такого документа парсер вернет приведенную ниже структуру:
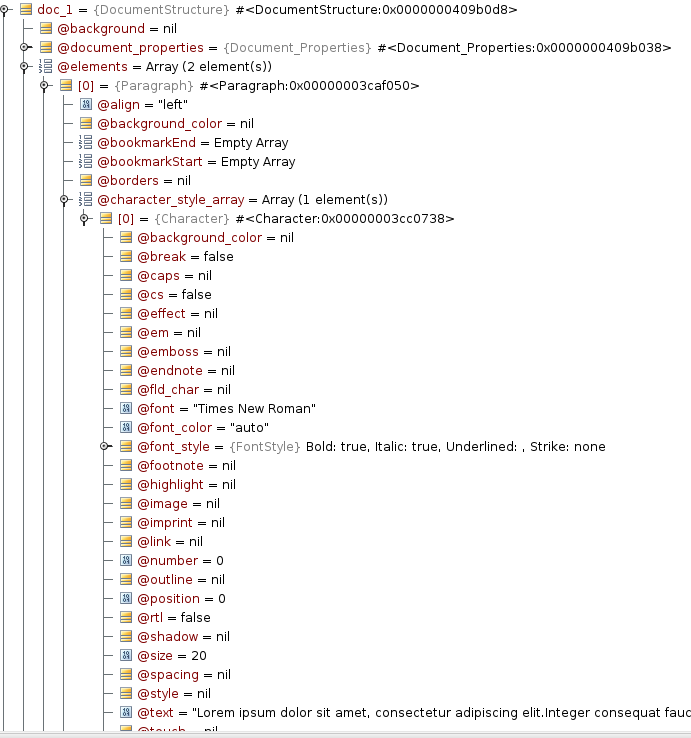
Документ состоит из набора элементов (elements) — это могут быть абзацы текста, изображения, таблицы.
Каждый абзац состоит из несколько character_styles — кусков текста с польностью одинаковыми свойствами в данном отрезке. Таким образом, если у нас в одном абзаце весь текст набран в одном стиле, то в нем будет только один character_style. Если же первое слово абзаца будет, например, выделено жирным, а остальные курсивом, то абзац будет состоять из двух character_style: один для первого слова, второй для всех остальных.
Внутри character_style находятся все нужные свойства текста, такие как size = 20 — размер шрифта, font = «Times New Roman» — тип шрифта, font_style — класс с свойствами стиля шрифта (Bold, Italic, Underlined, Strikeout), а также все прочие свойства документа.
В итоге для того, чтобы верифицировать данный документ, нам следует написать данный код:
doc.elements.first.character_styles_array.first.size.should == 20
doc.elements.first.character_styles_array.first.font.should ==" Times New Roman"
doc.elements.first.character_styles_array.first.font_style.should == FontStyle.new(true, true, false, false)
Для того, чтобы иметь репрезентативную выборку файлов в формате DOCX, было принято решение, что также надо написать генератор DOCX файлов — приложение, которое бы позволяло создавать документы с произвольным содержимым и с произвольными значениями параметров. Для этого тоже был выделен один специалист. Генератор не рассматривался как ключевая часть системы тестирования, а скорее как некая вспомогательная утилита, которая бы позволяла нам увеличить покрытие тестами.
На основе его разработки были сделаны следущие выводы:
При создании или автоматизации тестов не пытайтесь покрыть сразу весь возможный функционал формата. Это создаст дополнительные трудности, особенно на ранней стадии разработки тестируемого приложения.
Тяжело отличить некорректные результаты от тестов, функционал которых пока еще не поддерживается приложением.
И как следствие предыдущих пунктов: писать генератор следует ближе к концу разработки тестируемого приложения (а не в начале, как сделали это мы), когда будет реализовано максимальное количество функций в редакторе.
Несмотря на вышесказанное, генератор позволил найти ошибки, которые практически невозможно было найти при ручном тестировании, например некорректная обработка параметров, значения которых не входят в множество допустимых.
В качестве основы для framework был взят Selenium Webdriver. На Ruby для него есть отличная альтернатива — Watir, но так сложилось, что в момент создания фрэймворка мы о нем не знали. Единственный раз, когда мы пожалели, что не воспользовались Watir, имел место при интеграции тестов в самый любимый и лучший браузер — IE. Selenium просто отказывался кликать на кнопочки и делать что-либо, в итоге пришлось написать костыль, чтобы в случае запуска тестов на IE вызывались методы Watir.
До разработки этого framework тестирование web приложений было построено на языке Java, и все элементы XPath и другие идентификаторы объектов были вынесены в отдельный файл xml, для того чтобы при смене XPath не надо было перекомпилировать весь проект.
У Ruby такой проблемы с перекомпиляцией быть не могло, поэтому уже в следущем нашем проекте автоматизации мы отказались от единого XML файла.
Функции в Selenium Webdriver были перегружены, потому что приходилось работать с файлом, содержащим 1200 элементов xPath. Мы переработали их:
Было
Стало
На наш взгляд, очень важно перед тем, как начать автоматизацию, проанализировать идентификаторы объектов на странице, и, если видно, что они генерируются автоматически (id наподобие «docmenu-1125»), обязательно попросите разработчиков добавить id, которые не будут меняться, иначе придется переделывать XPath при каждом новом билде.
В класс SeleniumCommands были добавлены более специфичные функции. Часть из них уже присутствовала в Watir по умолчанию, но тогда мы этого еще не знали, например, клик по по порядковому номеру одного из нескольких элементов, получение одного аттрибута сразу от нескольких элементов. Важно, чтобы к работе с таким ключевым классом, как SeleniumCommands допускался только один специалист по тестированию, иначе при возникновении даже несущественной ошибки может упасть весь проект, и, само собой, это произойдет именно тогда, когда нужно максимально быстро прогнать все тесты.
Более высокий уровень framework — это работа с меню программы, интерфейсом приложения. Это очень большой (около 300) набор функций, распределенный на классы. Каждая из них реализует определенную функцию в интерфейсе, которая доступна пользователю (например выбор шрифта, междустрочные интервалы и тд.).
Все эти функции имеют максимально простые наглядные имена и принимают аргументы в самом простом виде (например, когда есть возможность передать не какой-либо класс, а просто объекты String, надо передавать их). Это позволяет писать тесты гораздо проще, чтобы даже ручные тестировщики без опыта программирования могли справиться. Это, кстати, не шутка и не преувеличение: у нас есть рабочие тесты, написанные человеком, который в программировании полный ноль.
В процессе написания данных функций была создана первая категория Smoke тестов, сценарий которых для всех функций выглядит так:
1.Создается новый документ.
2. Вызывается одна (именно только одна) написанная функция, которой передается какое-то конкретное корректное значение (не случайное, а именно конкретное и корректное, чтобы отбросить на этом шаге функционал который работает правильно только на части возможных значений)
3. Скачиваем документ
4. Верифицируем
5. Заносим результаты в систему отчетов
6. PROFIT!
Итак, подводя итог, давайте разберемся с категориями тестов, которые присутствуют в нашем проекте.
1. Smoke тесты
Их цель протестировать продукт на каком-то малом количестве вводимых данных и, главное, проверить, что сам Framework работает корректно на новом билде (не сменились ли элементы xPath, не изменилась ли логика построения меню интерфейса приложения.

Эта категория тестов хорошо работает, но иногда тесты зависали в непонятные моменты в ожидании некоторых элементов интерфейса. При повторении сценария теста вручную выяснялось, что тесты зависали по причине ошибок работы интерфейса меню, например, при нажатии кнопки открытия списка шрифтов сам список не появлялся. Так и возникла вторая категория тестов.
2. Тесты интерфейса
Это очень простой набор тестов, задача которых проверить, что при нажатии на все контролы происходит действие, за которое данный контрол отвечает (на уровне интерфейса). То есть, если мы нажимаем на кнопку Bold, мы не проверяем, сработало ли выделение жирным, мы только проверяем, что кнопка стала отображаться как нажатая. Аналогично, проверяем, чтобы открывались все выпадающие меню и все списки.

3. Перебор всех значений параметров
Для каждого параметра выставляются все возможные значения (например, перебираются все размеры шрифта), и затем это верифицируется. В одном документе должны присутствовать только изменения одного параметра, никаких связок при этом не тестируется. Впоследствии из этих тестов появилась еще одна подкатегория тестов.
3.1 Визуальная верификация рендеринга
В процессе прогонки тестов по перебору всех значений параметров мы поняли, что требуется верифицировать рендеринг всех значений параметров визуально. Тест выставляет значение параметра (например, выбирается шрифт), делает скриншот. На выходе имеем группу скриншотов (около 2 тысяч) и недовольного ручника, которому придется посмотреть большое слайдшоу.
Впоследствии верификацию рендеринга мы сделали с помощью системы эталонов, которая позволила нам отследить регрессию.
4. Функциональные тесты
Одна из самых важных категорий тестов. Покрывает весь функционал приложения. Для лучших результатов составлением сценариев должны заниматься тест-дизайнеры.
5. Pairwise
Тесты на проверку связок параметров. Например, полная проверка гарнитур шрифта со всеми стилями и размерами (две и более функций с параметрами). Генерируются автоматически. Запускаются очень редко в силу своей продолжительности (минимум 4-5 часов, некоторые еще дольше).
6. Регулярные тесты на рабочем сервере
Самая последняя категория тестов, которая появилась после первого релиза. В основном это проверка корректности работы связи компонентов, а именно того, что файлы всех форматов открываются на редактирование и корректно скачиваются во все форматы. Тесты короткие, но запускаются дважды в день.
На первых порах проекта вся отчетность собиралась вручную. Тесты запускались напрямую из RubyMine по памяти (или пометкам, комментариям в коде), устанавливалось, стал ли новый билд хуже или лучше предыдущего, и на словах результаты передавались менеджеру тестирования.
Но когда количество тестов разрослось (что случилось достаточно быстро), стало понятно, что долго это продолжаться не может. Память не резиновая, держать кучу данных на бумажках или заносить вручную в электронную табличку очень неудобно. Поэтому в качестве сервера отчетности было решено выбрать Testrail, который почти идеально подходит для нашей задачи — хранить отчетность по каждой версии редактора.
Добавление отчетности происходит через API testrail. В начале каждого теста на Rspec добавляется строчка, ответственная за инициализацию TestRun на Testrail. Если написан новый тест, который еще не присутствует на Testrail, он автоматически добавляется туда. По завершению теста автоматически определяется результат и добавляется в базу.
По сути весь процесс отчетности полностью автоматизирован, на Testrail следует заходить только для получения результата. Выглядит это так:

В заключение немного статистики:
Возраст проекта — 1 год
Количество тестов — около 2000
Количество пройденных кейсов — около 350 000
Команда — 3 человека
Количество найденных багов — около 300

Последние 8 месяцев своей жизни я и мои коллеги провели, тестируя абсолютно новый редактор документов, написанный на HTML5. Тестировать инновационные продукты сложно, хотя бы потому что до нас этого никто не делал.
Для реализации всех наших идей нам потребовались сторонние инструменты:
- язык Ruby для автоматизации. Он скриптовый, отлично работает с большими объемами данных, и, не буду лукавить, был небольшой опыт работы с ним.
- Gem Rspec для прогона тестов
- драйвер Selenium Webdriver для работы с браузерами
1. Верификация
Много копий было сломано в процессе поиска нужного метода сравнения с эталоном. В результате мы пришли к выводу, что информацию о произведенных действиях и, соответственно, об успешности прохождения тестов можно получать двумя способами:
1. С помощью API самого приложения.
2. С помощью своего собственного парсера документов.
API
Положительные стороны:
- Быстрое получение результатов, т.к. отпадает необходимость лишнего обращения к серверу при скачивании документов.
- Возможность работать непосредственно с функциями API интерфейса. Для нас это стало оптимальным решением — мы работаем в дружественном климате с программистами, и они быстро предоставили нам эти функции.
Отрицательные стороны:
- Отсутствие возможности четкой локализации бага в программе, т.е.в коде редакторов или при вызове/реализации интерфейса, т.е.е в коде интерфейса.
- Зависимость от программистов. Если у разработчиков произойдет такая ситуация, что методы API сильно изменятся или перестанут работать вообще, процесс автоматического тестирования тоже встанет. А вот исправление API на стороне сервера может быть далеко не приоритетной задачей (учитывая, что это не публичное API и используется только для тестов).
- Невозможность автоматизации тестирования всего функционала в существующей архитектуре приложения.
Парсинг скачанного документа
Положительные стороны:
- Надежный подход, потому что мы проверям конечный результат работы приложения.
- Независимость от разработчиков. Мы написали открытие формата docx своими инструментами, условно говоря создали свой собственный небольшой document converter.
- Возможность реализации тестов любых уровней сложности, т.к. поддерживается весь существующий в приложении функционал.
Отрицательные стороны:
- Сложность в реализации.
Окончательный вариант верификации
В итоге мы выбрали оба варианта, но использовали их в разных пропорциях: около 90 % верификации тестов реализовано посредством парсера и только 10% — посредством API. Это позволило быстро написать первые тесты с помощью API и постепенно развивать функциональные тесты совместно с разработкой парсера.
В качестве формата для парсинга был выбран DOCX. Связано это с тем, что:
- В самом редакторе поддержка формата DOCX была реализована лучше всего, поддерживалось максимальное количество функций и сохранение в него происходило наиболее качественно и надежно.
- Сам формат DOCX, в отличие от DOC, является более открытым и имеет более простую структуру. По сути это ZIP архив с XML файлами.
Стороннюю библиотеку для парсинга DOCX, которая поддерживала бы необходимый нам набор функций, мы найти так и не смогли. Впоследствии аналогичная ситуация сложилась и с другим форматом, когда при тестирровании редактора таблиц нам потребовался парсер XLSX.
За парсер отвечает только один специалист. Основной костяк функционала был реализован примерно за месяц, но до сих пор постоянно поддерживается — исправляются баги (которых, к слову, для существующего функционала почти не осталось), а также добавляется поддержка для нового функционала, введенного в редактор документов.
Пример:
Рассмотрим простой пример: документ из одного абзаца с размером текста 20, шрифтом Times New Roman и выставленными опциями Bold и Italic. Для такого документа парсер вернет приведенную ниже структуру:

Документ состоит из набора элементов (elements) — это могут быть абзацы текста, изображения, таблицы.
Каждый абзац состоит из несколько character_styles — кусков текста с польностью одинаковыми свойствами в данном отрезке. Таким образом, если у нас в одном абзаце весь текст набран в одном стиле, то в нем будет только один character_style. Если же первое слово абзаца будет, например, выделено жирным, а остальные курсивом, то абзац будет состоять из двух character_style: один для первого слова, второй для всех остальных.
Внутри character_style находятся все нужные свойства текста, такие как size = 20 — размер шрифта, font = «Times New Roman» — тип шрифта, font_style — класс с свойствами стиля шрифта (Bold, Italic, Underlined, Strikeout), а также все прочие свойства документа.
В итоге для того, чтобы верифицировать данный документ, нам следует написать данный код:
doc.elements.first.character_styles_array.first.size.should == 20
doc.elements.first.character_styles_array.first.font.should ==" Times New Roman"
doc.elements.first.character_styles_array.first.font_style.should == FontStyle.new(true, true, false, false)
2. Генератор документов
Для того, чтобы иметь репрезентативную выборку файлов в формате DOCX, было принято решение, что также надо написать генератор DOCX файлов — приложение, которое бы позволяло создавать документы с произвольным содержимым и с произвольными значениями параметров. Для этого тоже был выделен один специалист. Генератор не рассматривался как ключевая часть системы тестирования, а скорее как некая вспомогательная утилита, которая бы позволяла нам увеличить покрытие тестами.
На основе его разработки были сделаны следущие выводы:
При создании или автоматизации тестов не пытайтесь покрыть сразу весь возможный функционал формата. Это создаст дополнительные трудности, особенно на ранней стадии разработки тестируемого приложения.
Тяжело отличить некорректные результаты от тестов, функционал которых пока еще не поддерживается приложением.
И как следствие предыдущих пунктов: писать генератор следует ближе к концу разработки тестируемого приложения (а не в начале, как сделали это мы), когда будет реализовано максимальное количество функций в редакторе.
Несмотря на вышесказанное, генератор позволил найти ошибки, которые практически невозможно было найти при ручном тестировании, например некорректная обработка параметров, значения которых не входят в множество допустимых.
3. Framework для запуска тестов
Взаимодействие с Selenium
В качестве основы для framework был взят Selenium Webdriver. На Ruby для него есть отличная альтернатива — Watir, но так сложилось, что в момент создания фрэймворка мы о нем не знали. Единственный раз, когда мы пожалели, что не воспользовались Watir, имел место при интеграции тестов в самый любимый и лучший браузер — IE. Selenium просто отказывался кликать на кнопочки и делать что-либо, в итоге пришлось написать костыль, чтобы в случае запуска тестов на IE вызывались методы Watir.
До разработки этого framework тестирование web приложений было построено на языке Java, и все элементы XPath и другие идентификаторы объектов были вынесены в отдельный файл xml, для того чтобы при смене XPath не надо было перекомпилировать весь проект.
У Ruby такой проблемы с перекомпиляцией быть не могло, поэтому уже в следущем нашем проекте автоматизации мы отказались от единого XML файла.
Функции в Selenium Webdriver были перегружены, потому что приходилось работать с файлом, содержащим 1200 элементов xPath. Мы переработали их:
Было
get_attribute(xpath, attribute)
@driver.find_element(:xpath, xpath_value)
attribute_value = element.attribute(attribute)
return attribute_value
end
get_attribute('//div/div/div[5]/span/div[3]', 'name')
Стало
get_attribute(xpath_name, attribute)
xpath_value =@@xpaths.get_value(xpath_name)
elementl = @driver.find_element(:xpath, xpath_value)
attribute_value = element.attribute(attribute)
return attribute_value
end
get_attribute('admin_user_name_xpath', 'name')
На наш взгляд, очень важно перед тем, как начать автоматизацию, проанализировать идентификаторы объектов на странице, и, если видно, что они генерируются автоматически (id наподобие «docmenu-1125»), обязательно попросите разработчиков добавить id, которые не будут меняться, иначе придется переделывать XPath при каждом новом билде.
В класс SeleniumCommands были добавлены более специфичные функции. Часть из них уже присутствовала в Watir по умолчанию, но тогда мы этого еще не знали, например, клик по по порядковому номеру одного из нескольких элементов, получение одного аттрибута сразу от нескольких элементов. Важно, чтобы к работе с таким ключевым классом, как SeleniumCommands допускался только один специалист по тестированию, иначе при возникновении даже несущественной ошибки может упасть весь проект, и, само собой, это произойдет именно тогда, когда нужно максимально быстро прогнать все тесты.
Взаимодействие с меню
Более высокий уровень framework — это работа с меню программы, интерфейсом приложения. Это очень большой (около 300) набор функций, распределенный на классы. Каждая из них реализует определенную функцию в интерфейсе, которая доступна пользователю (например выбор шрифта, междустрочные интервалы и тд.).
Все эти функции имеют максимально простые наглядные имена и принимают аргументы в самом простом виде (например, когда есть возможность передать не какой-либо класс, а просто объекты String, надо передавать их). Это позволяет писать тесты гораздо проще, чтобы даже ручные тестировщики без опыта программирования могли справиться. Это, кстати, не шутка и не преувеличение: у нас есть рабочие тесты, написанные человеком, который в программировании полный ноль.
В процессе написания данных функций была создана первая категория Smoke тестов, сценарий которых для всех функций выглядит так:
1.Создается новый документ.
2. Вызывается одна (именно только одна) написанная функция, которой передается какое-то конкретное корректное значение (не случайное, а именно конкретное и корректное, чтобы отбросить на этом шаге функционал который работает правильно только на части возможных значений)
3. Скачиваем документ
4. Верифицируем
5. Заносим результаты в систему отчетов
6. PROFIT!
4. Тесты
Итак, подводя итог, давайте разберемся с категориями тестов, которые присутствуют в нашем проекте.
1. Smoke тесты
Их цель протестировать продукт на каком-то малом количестве вводимых данных и, главное, проверить, что сам Framework работает корректно на новом билде (не сменились ли элементы xPath, не изменилась ли логика построения меню интерфейса приложения.
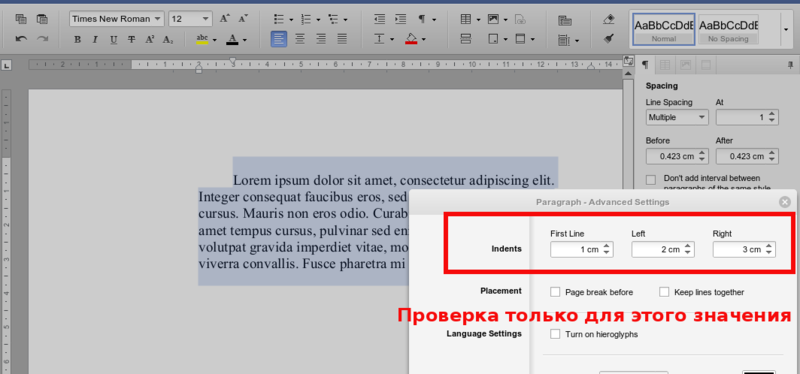
Эта категория тестов хорошо работает, но иногда тесты зависали в непонятные моменты в ожидании некоторых элементов интерфейса. При повторении сценария теста вручную выяснялось, что тесты зависали по причине ошибок работы интерфейса меню, например, при нажатии кнопки открытия списка шрифтов сам список не появлялся. Так и возникла вторая категория тестов.
2. Тесты интерфейса
Это очень простой набор тестов, задача которых проверить, что при нажатии на все контролы происходит действие, за которое данный контрол отвечает (на уровне интерфейса). То есть, если мы нажимаем на кнопку Bold, мы не проверяем, сработало ли выделение жирным, мы только проверяем, что кнопка стала отображаться как нажатая. Аналогично, проверяем, чтобы открывались все выпадающие меню и все списки.

3. Перебор всех значений параметров
Для каждого параметра выставляются все возможные значения (например, перебираются все размеры шрифта), и затем это верифицируется. В одном документе должны присутствовать только изменения одного параметра, никаких связок при этом не тестируется. Впоследствии из этих тестов появилась еще одна подкатегория тестов.
3.1 Визуальная верификация рендеринга
В процессе прогонки тестов по перебору всех значений параметров мы поняли, что требуется верифицировать рендеринг всех значений параметров визуально. Тест выставляет значение параметра (например, выбирается шрифт), делает скриншот. На выходе имеем группу скриншотов (около 2 тысяч) и недовольного ручника, которому придется посмотреть большое слайдшоу.
Впоследствии верификацию рендеринга мы сделали с помощью системы эталонов, которая позволила нам отследить регрессию.
4. Функциональные тесты
Одна из самых важных категорий тестов. Покрывает весь функционал приложения. Для лучших результатов составлением сценариев должны заниматься тест-дизайнеры.
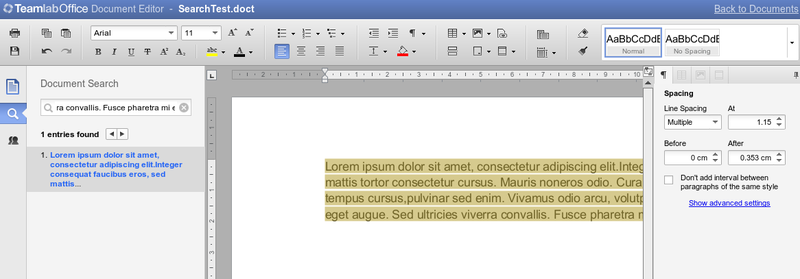
5. Pairwise
Тесты на проверку связок параметров. Например, полная проверка гарнитур шрифта со всеми стилями и размерами (две и более функций с параметрами). Генерируются автоматически. Запускаются очень редко в силу своей продолжительности (минимум 4-5 часов, некоторые еще дольше).

6. Регулярные тесты на рабочем сервере
Самая последняя категория тестов, которая появилась после первого релиза. В основном это проверка корректности работы связи компонентов, а именно того, что файлы всех форматов открываются на редактирование и корректно скачиваются во все форматы. Тесты короткие, но запускаются дважды в день.
5. Отчетность
На первых порах проекта вся отчетность собиралась вручную. Тесты запускались напрямую из RubyMine по памяти (или пометкам, комментариям в коде), устанавливалось, стал ли новый билд хуже или лучше предыдущего, и на словах результаты передавались менеджеру тестирования.
Но когда количество тестов разрослось (что случилось достаточно быстро), стало понятно, что долго это продолжаться не может. Память не резиновая, держать кучу данных на бумажках или заносить вручную в электронную табличку очень неудобно. Поэтому в качестве сервера отчетности было решено выбрать Testrail, который почти идеально подходит для нашей задачи — хранить отчетность по каждой версии редактора.
Добавление отчетности происходит через API testrail. В начале каждого теста на Rspec добавляется строчка, ответственная за инициализацию TestRun на Testrail. Если написан новый тест, который еще не присутствует на Testrail, он автоматически добавляется туда. По завершению теста автоматически определяется результат и добавляется в базу.
По сути весь процесс отчетности полностью автоматизирован, на Testrail следует заходить только для получения результата. Выглядит это так:

В заключение немного статистики:
Возраст проекта — 1 год
Количество тестов — около 2000
Количество пройденных кейсов — около 350 000
Команда — 3 человека
Количество найденных багов — около 300
