

Не так давно мы рассказали о запуске нашей новой облачной услуги – объектного хранилища Техносерв Cloud, совместимого с S3. Сегодня мы хотим перейти к конкретным техническим моментам в работе с нашей услугой, а в частности к настройкам системы резервного копирования для работы с S3-совместимым хранилищем. Сейчас практически все современные СРК имеют встроенную поддержку протокола S3 API, но не все об этом знают и, соответственно, не в полной мере используют функциональность систем.
Недавнее исследование Taneja Group определило приоритеты в использовании объектных хранилищ среди пользователей, согласно которому хранение резервных копий занимает первое место. В качестве примера для сегодняшнего поста мы взяли СРК Commvault. Подробнее об исследовании, о Commvault и настройке подключения облака к системе в нашем новом материале.
Поскольку объемы накапливаемых компаниями данных растут более чем на 50% в год, а свыше 80% — это неструктурированные данные, объектное хранение приобретает несомненную ценность. Это единственная технология, которая позволяет поспевать за увеличивающейся емкостью хранилищ, оставаясь в рамках бюджета.

Согласно результатам исследования, резервное копирование файлов и архивное хранение – наиболее типичные задачи (их отметили 57% респондентов). Причина, вероятно, кроется в высоком спросе на масштабируемое резервное копирование файлов и архивирование документов, а также экономически эффективное долгосрочное хранение данных в целях соблюдения нормативных требований. Объектное хранилище идеально подходит для крупномасштабного хранения неструктурированных данных, поскольку оно легко наращивается по емкости (до петабайт и выше) простым добавлением узлов хранения. Такой подход устраняет узкое место в производительности, которое ограничивает одно- и двуконтроллерные архитектуры традиционных файловых хранилищ. Кроме того, объектное хранение обеспечивает независимость от аппаратной платформы, поэтому компании могут увеличить емкость за счет добавления оборудования.
На втором месте — хранение объектов (Storage as a service), ее выделили 44% опрошенных. Хранилище объектов предоставляет поставщикам услуг экономичный способ управления резервными копиями с использованием надежной, масштабируемой и многоарендной архитектуры. И поскольку это «услуга», компании экономят на расходах на персонал, оборудование и центры обработки данных. ИТ-администратор просто арендует пространство для хранения на основе стоимости за гигабайт и затрат на передачу данных.
Третье место по популярности занимает аналитика больших данных (35% респондентов). Объектное хранилище предназначено для больших наборов данных, что делает его идеальным для задач аналитики больших данных. В недавнем опросе выяснилось, что около 30% респондентов накапливают 100 ТБ или более «больших данных», причем объем этих данных каждый месяц существенно увеличивается. Тем не менее, для поддержки большой аналитики данных и искусственного интеллекта для корреляции и интерпретации данных нужно тесно интегрировать объектное хранилище с хранилищем с низкой задержкой и системами высокопроизводительных вычислений.
Наконец, еще один распространенный вариант применения объектного хранилища — безопасное совместное использование файлов (его также указали 35% респондентов).
| Amazon Infrequent Access | Google Nearline | Amazon Glacier | Google Coldline | |
|---|---|---|---|---|
| Durability | 99,999999999% | 99,999999999% | 99,99% | 99,999999999% |
| Availability SLA | 99,9% | 99,9% | N/A | 99% |
| Access Time | Milliseconds | Milliseconds | 5 min-12 hrs | Milliseconds |
| Minimum Time | 30 | 30 | 90 | 90 |
| Amazon S-3 Standard | Google Multiregional | Amazon Reduced Redundancy | Google Regional | |
|---|---|---|---|---|
| Durability | 99,999999999% | 99,999999999% | 99,99% | 99,999999999% |
| Availability SLA | 99,95% | 99,95% | 99% | 99% |
| Access Time | Milliseconds | Milliseconds | Milliseconds | Milliseconds |
| Minimum Time | None | None | None | None |
Большинство объектных хранилищ также предлагают очень высокую отказоустойчивость с защитой от отказов сайта, узла и нескольких дисков.
Поэтому сегодня речь пойдет именно о таком направлении применения объектных хранилищ как хранение резервных копий, а в качестве примера системы резервного копирования, как уже было отмечено, мы выбрали Commvault как одного из лидеров в данном сегменте и самое популярное решение среди корпоративных клиентов.

Лидеры в сегменте решений резервного копирования для ЦОД (Gartner, июль 2017 г.).
Немного о Commvault
Commvault – это масштабируемая программная платформа для РК баз данных, приложений, файлов, виртуальных машин и ОС.

Cистемы резервного копирования, поддерживающие S3.
Сегодня практически все современные системы резервного копирования имеют встроенную поддержку протокола S3 API, но не все об этом знают и, соответственно, не в полной мере используют функциональность системы.
Система Commvault поддерживает резервное копирование в облако Amazon S3 и другие S3-совместимые хранилища. А ядро облачного хранилища Техносерв Cloud не только построено с использованием технологий S3, но и поддерживает все команды S3 API, что гарантирует совместимость с приложениями клиента — как сейчас, так и в будущем.
Далее на примере нашего облака покажем, как выполнять резервное копирование из Commvault в S3-совместимое хранилище. Данная инструкция применима к любому S3-совместимому хранилищу.
Настройка подключения хранилища Техносерв Cloud к системе резервного копирования Commvault
Для подключения облачного хранилища Техносерв Cloud к системе резервного копирования Commvault необходимо выполнить три простых шага.
1.Войти в консоль управления облачными ресурсами (https://storage.technoserv.cloud) и создать контейнер для хранения данных. Для этого необходимо перейти на вкладку «Корзины и объекты», затем ввести название корзины в поле «Корзина» и выбрать «Создать», а остальные поля оставить заполненными по умолчанию.
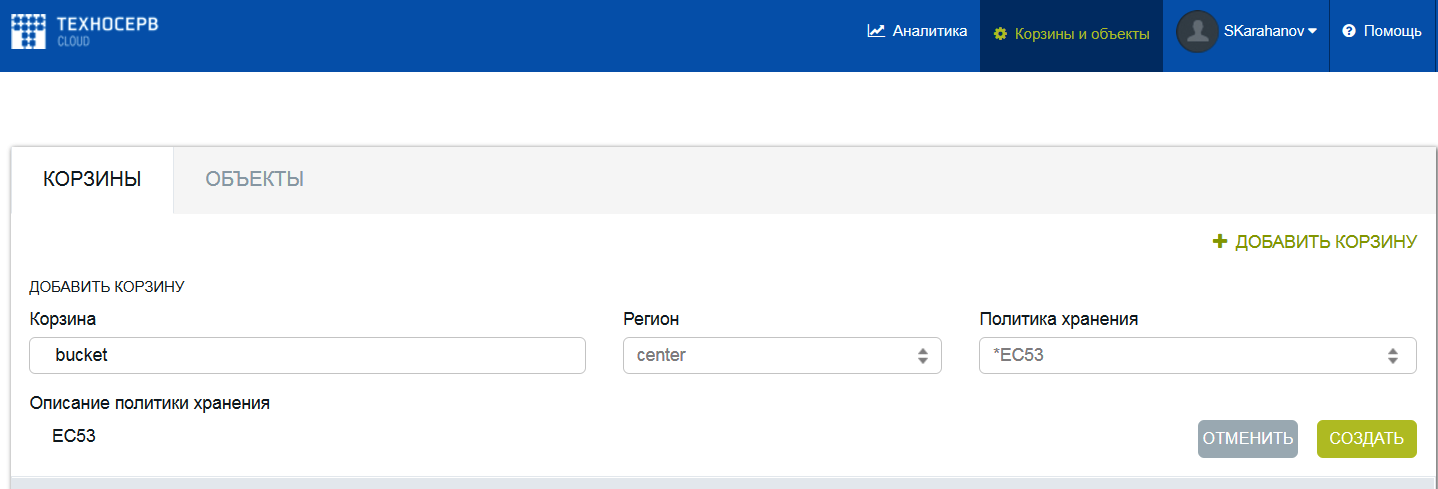
В данном примере мы назвали корзину «bucket».
2.После этого необходимо узнать ключ доступа и пароль к облачному хранилищу. Для этого нужно перейти на вкладку «Управление паролями».
В открывшемся окне будет указана информация, необходимая для подключения облачного хранилища к системе резервного копирования, а именно:
• информация о сервисе (Service Host);
• ключ доступа (Access Key ID);
• и секретный ключ (Secret Access Key).

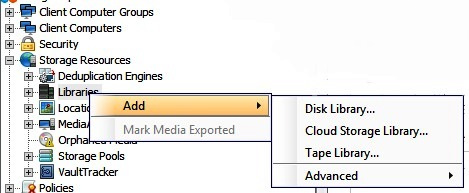
3.Теперь нужно создать облачную библиотеку в системе резервного копирования Commvault. Для этого необходимо в консоли Commcell нажать правой кнопкой мыши на вкладке Libraries и выбрать Add -> Cloud Storage Library.
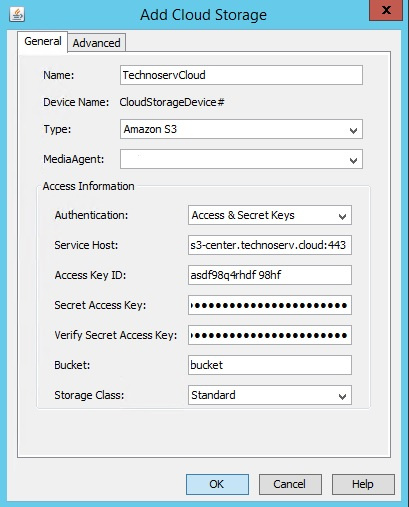
В открывшемся окне во вкладке «General» следует заполнить все поля:
• Name — указать название создаваемой облачной библиотеки;
• Type — из выпадающего списка выбрать Amazon S3;
• MediaAgent — выбрать медиа-сервер, который будет подключаться к облачному хранилищу;
• Access Information — указать упомянутые выше адрес сервера, ключ доступа и пароль. В поле Bucket указать название созданной ранее корзины.
Если для подключения к интернету используется прокси-сервер, то нужно перейти на вкладку «Advanced» и указать параметры прокси-сервера.
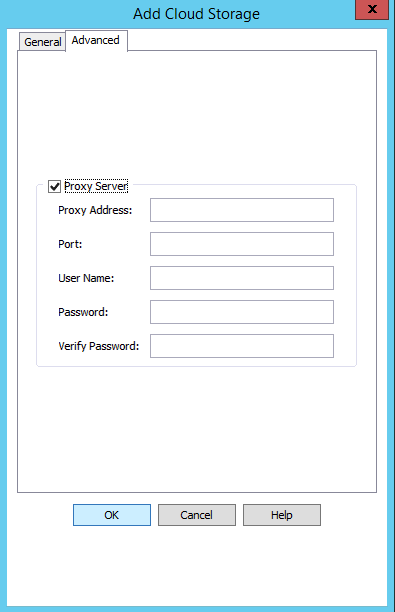
Вот, собственно, и все. На этом интеграция облачного хранилища Техносерв Cloud с системой Commvault завершена.
Для отправки резервных копий в облачное хранилище необходимо в консоли системы резервного копирования задать политику хранения, в которой указать созданную облачную библиотеку. После этого остается назначить политику хранения заданию резервного копирования и запустить его.

Использование объектных облачных хранилищ системой Commvault.
Вот таким, как видите, простым путём мы подключили свое облачное хранилище к системе резервного копирования Commvault, когда запускали услугу резервное копирование в облаке.
Таким образом, можно быстро реализовать преимущества резервного копирования данных в облако, используя его как расширение вашей ИТ-инфраструктуры. В числе преимуществ такого решения:
• Быстрое и надежное резервное копирование и восстановление данных.
• Нет необходимости в дорогостоящих шлюзах и сложных промежуточных решениях.
• Можно заменить ленту облачным хранилищем.
• Можно использовать облако для аварийного восстановления.
По прогнозу IDC, мировой рынок облачного хранения (Cloud Storage) будет расти на 25% в год.
А что думаете вы? Нам интересно ваше мнение: был ли материал полезен? Нужна ли подобная инструкция по резервному копированию из другой системы? Из какой именно? Ждем ваших комментариев!
