Почти в самом начале создания платформы (некоего фундамента, фреймворка на котором базируются все прикладные решения) нашего облачного веб-приложения СБИС мы поняли, что без инструмента, позволяющего сообщить пользователю о каком-либо событии с сервера, жить будет довольно-таки трудно. Все мы хотим мгновенно видеть новое сообщение от коллеги (которому лень пройти 10 метров), поднимающую корпоративный дух новость от руководства, очень важную задачу от отдела тестирования или получение поощрения (особенно денежного). Но путь становления был тернист, поэтому расскажем немного про трудности, которые мы встретили при взрослении от 5.0e3 до 1.0e6 одновременных подключений от пользователей.

Начало
Решением «в лоб» может быть периодический опрос из браузера серверной стороны. Но уже тогда (в далёком 2013 году, когда люди ещё снимали клипы под Harlem Shake) у нас были десятки разных сервисов, и их периодический опрос мог бы значительно поднять нам метрики по запросам в секунду. Поэтому встал вопрос о промежуточном супер-сервисе, который бы позволил любому бэкенду какого-либо сервиса отсылать данные любому нужному пользователю (обратное взаимодействие работает по HTTP).
На тот момент уже набрали достаточную популярность веб-сокеты, которые позволяют сократить общую нагрузку и, что более значимо, свести к минимуму задержку доставки информации до браузеров пользователей. Но, к сожалению, не все популярные среди наших любимых пользователей браузеры поддерживали веб-сокеты (также в довесок не все прокси-серверы могли их пропустить), поэтому нужна была поддержка и более распространённых технологий, таких как XHR-polling и XHR-streaming.
Сервис был нужен «ещё вчера», и поэтому, чтобы стратегия разработки не превратилась в «чик-чик и в продакшен», решили поискать существующие решения. Поиск привёл нас в нору к брокеру RabbitMQ, который на тот момент уже имел в своём составе плагины для работы с веб-средой: Web STOMP adapter и SockJS. Первый позволяет связать бинарный протокол AMQP с текстовым STOMP, а второй – наладить websocket-like связь до пользователя (сам заботится о выборе поддерживаемого транспорта). С надеждой на плодотворное сотрудничество развернули и протестировали кластер из нескольких узлов. RabbitMQ не огорчил, и мы решили строить систему оповещения пользователей на его основе. Первое время всё шло хорошо, но развитие функционала в нашем веб-приложении и рост количества активных пользователей начали говорить нам, что утро начинается не с кофе.
Пару слов о RabbitMQ
RabbitMQ – это мультипротокольный брокер сообщений, позволяющий организовать отказоустойчивый кластер с полной репликацией данных на несколько узлов, где каждый узел может обслуживать запросы на чтение и запись. Он написан на языке Erlang и использует протокол AMQP версии 0.9 в качестве основного. Рассмотрим вскользь схему взаимодействия объектов в AMQP:
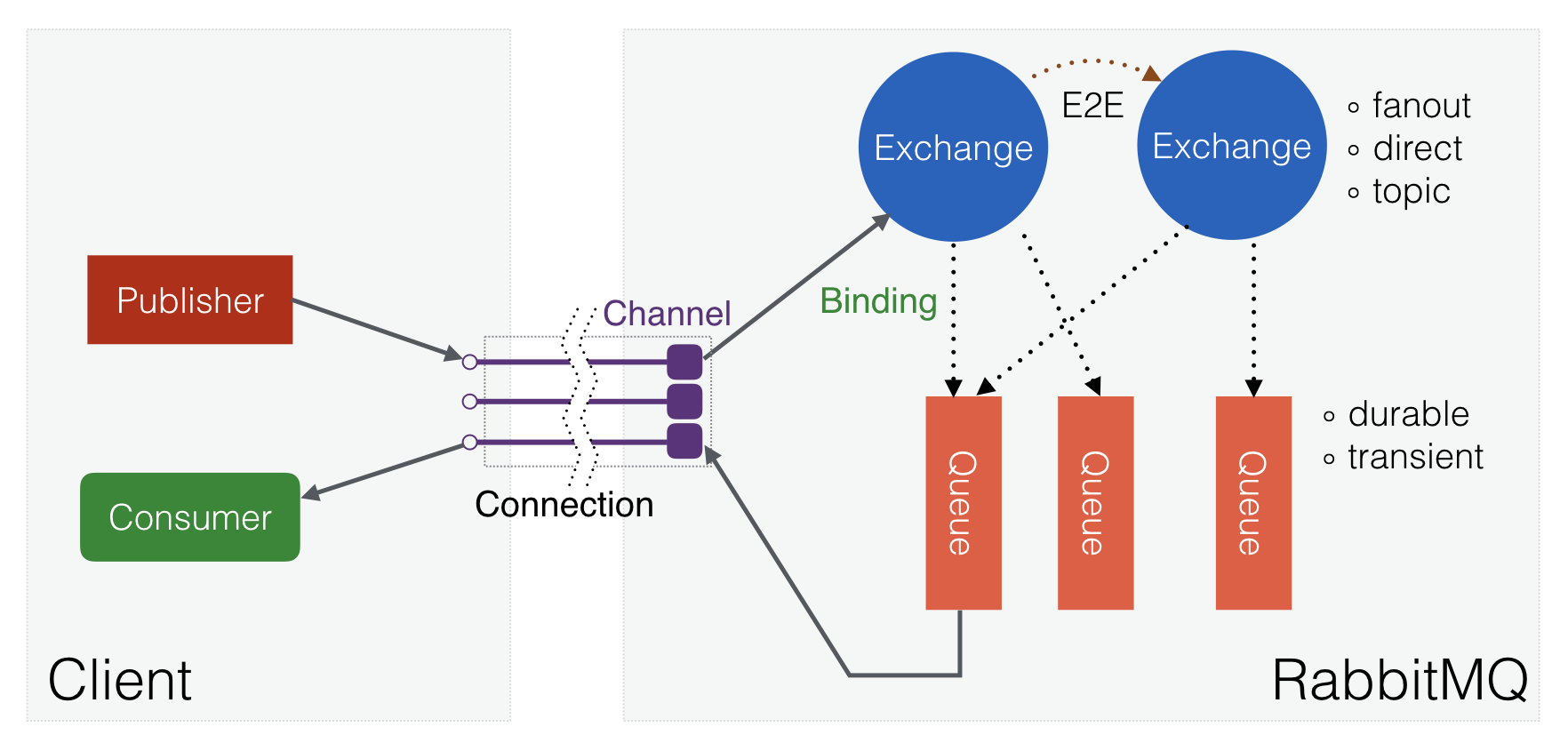
Рис. 1. Взаимодействие объектов в AMQP.
Очередь (queue) хранит и отдаёт потребителям (consumer) все поступающие сообщения. Обменник (exchange) занимается маршрутизацией сообщений (не хранит их) на основе созданных связей (binding) между ним и очередями (или другими обменниками). С точки зрения RabbitMQ, очередь представляет собой Erlang-процесс с состоянием (где могут кэшироваться и сами сообщения), а обменник – это «ссылка» на модуль с кодом, где лежит логика маршрутизации. То есть, к примеру, 10 тысяч обменников будут потреблять около 12 МБ памяти, когда 10 тысяч очередей уже порядка 800 МБ.
В кластерном режиме работы метаинформация копируется на все узлы. То есть каждый узел содержит полный список обменников, очередей, их связей, потребителей и других объектов. Сами процессы с очередями по умолчанию располагаются только на одном узле, но с помощью политик можно включить репликацию (mirrored queues), и данные будут копироваться автоматически на нужное количество узлов.
Наивная реализация
Первая реализация была довольно простой:
- Кластер RabbitMQ из трёх узлов, к которому подключались и бэкенды, и клиенты;
- Бэкенды при старте создавали обменники с именами их событий (включая имя веб-сайта, например, «online.sbis.ru:contacts.new-message») и типом direct;
- Клиенты подключались через SockJS и «слушали» нужные им события путём подписки (subscribe) на соответствующие обменники с ключом равным идентификатору пользователя;
- В момент происхождения события бэкенд отправлял AMQP-сообщение в соответствующий обменник. В качестве ключа маршрутизации (routing key) у сообщения был идентификатор получателя.
Схематично всё это выглядело примерно так:
Рис. 2. Схема подключения.

Рис. 3. Схема объектов в брокере.
В AMQP есть три основных типа обменников: fanout, direct и topic.
Самый простой и быстрый тип – это fanout. Связи с ним не имеют каких-либо параметров, для получения сообщений важно лишь их наличие.
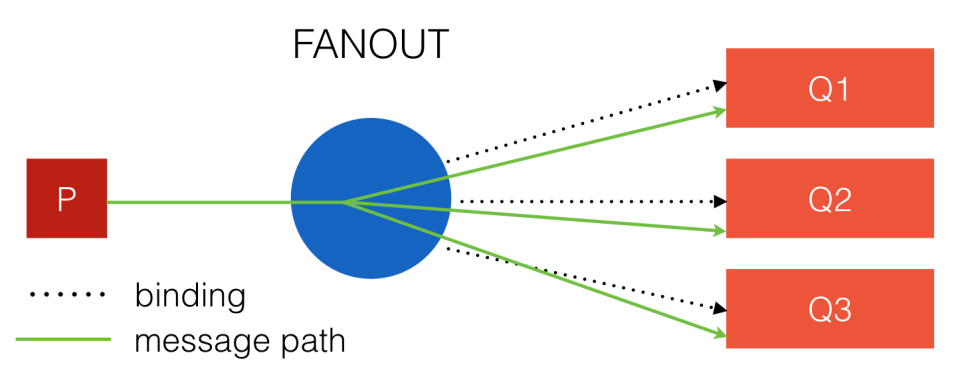
Рис. 4. Fanout обменник.
Здесь пунктиром показана связь, а зелёной линией – путь сообщения. Оно будет скопировано во все очереди.
Для direct обменника при создании связи указывается строковый ключ, который участвует в выборе кандидатов на получение сообщения. Скорость его работы немного уступает скорости fanout’а. При публикации сообщения у него указывается ключ маршрутизации (routing key) и, если этот ключ полностью совпадает с ключом связи, то конечная очередь получит сообщение.

Рис. 5. Direct обменник.
Topic рассматривает ключ не просто как строку, а как набор токенов, разделённых точкой. Можно использовать символ звёздочки для указания неважности значения токена для нас или символ решётки, который заменяет собой ноль и более любых токенов.

Рис. 6. Topic обменник.
Скорость работы такого обменника зависит от сложности ключа и количества токенов в нём, и в простейшем случае аналогична скорости direct обменника.
Существует ещё один тип обменника – headers, но его не рекомендуют использовать из-за скорости работы, так что опустим его.
Рост количества событий
На тот момент клиентский код в браузере «слушал» в среднем около 10 событий на страницу, но их рост не заставил себя ждать (сейчас, например, только на главной странице их около 70 штук). Добавляет боли их непредсказуемая жизнь – событие может потребоваться в любой момент и на любой интервал времени.
Но основную проблему, конечно, создавало то, что при подписке по STOMP на какой-либо обменник автоматически создается очередь, которая уже связывается с обменником. И если таких подписок 30 штук, то будет и 30 очередей (в рамках одного подключения), что не может не отразиться на потребляемых ресурсах и частоте призыва на службу OOM killer'а.
Для решения этой проблемы мы поменяли подход и вынесли название события из имени обменника в заголовок самого AMQP-сообщения. Структура упростилась и стала выглядеть как-то так:

Рис. 7. Структура объектов после первого улучшения.
Тем самым мы убрали зависимость от количества событий на странице, и теперь требовалась всего одна подписка со стороны пользователя. Но пришлось пожертвовать трафиком, так как в новом подходе понять, нужно ли событие пользователю, можно только после его доставки до пользователя.
Области публикаций
В нашей системе существуют понятия «клиент» – какая-либо компания, пользующаяся нашим продуктом, и «пользователь» – сотрудник клиента. Компании совершенно разные, и у кого-то может быть два-три сотрудника, а у кого-то несколько тысяч. Если требовалось отправить сообщение всем пользователям клиента, то приходилось пробегаться по всему списку в цикле, что могло занимать продолжительное время. Поэтому надо было срочно что-то с этим делать.
Решением стало создание трёх областей публикации: пользователь, клиент и глобально всем. Глобальная область требуется для рассылки системной информации, например, просьба перезагрузить страницу после обновления бэкендов. Каждая область была реализована в RabbitMQ как обменник с типом direct и, чтобы не заставлять клиента снова делать несколько подписок, был добавлен ещё один обменник с типом fanout – персональный обменник пользователя.
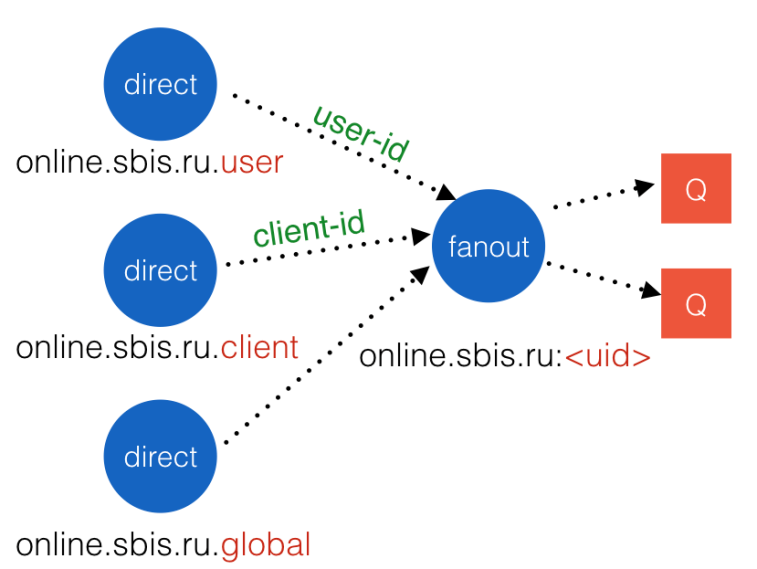
Рис. 8. Структура объектов с областями публикации и персональным обменником.
Персональный обменник связывался с обменниками областей с нужными идентификаторами, и пользователю нужно было просто подключиться к нему без каких-либо параметров. Но теперь нам нужно было создавать персональные обменники до того, как пользователи будут производить подписку, иначе будет ошибка. Предварительно создавать объекты для всех существующих пользователей довольно накладно. Поэтому решили создавать их динамически в момент подключения. Для этого на Nginx (стоял перед RabbitMQ) был сделан Lua-скрипт, дёргающий вспомогательную утилиту перед проксированием запроса на брокер. Утилита проверяла существование всего необходимого и создавала при отсутствии. Позже сделали вызов утилиты только на запрос /info, который является обязательным для SockJS.
Auto-delete очереди
Изначально мы создавали очереди, которые автоматически удалялись после разрыва подключения (auto-delete), но это приводило к двум большим проблемам:
При кратковременном разрыве связи мы теряли сообщения, которые ещё не успели дойти;
- Производилось большое количество операций в системе по созданию/удалению очередей и связей, особенно до момента оптимизации количества подписок. В кластерном режиме такой большой поток операций расползался по всем узлам и создавал повышенную нагрузку. Этот феномен называют binding churn.
В итоге перешли на постоянные (persistent) очереди, которые не удаляются в момент разрыва подключения, но повесили на них политику «протухания» (expire), если пользователя нет более 5 минут. (Система не преследует цели хранить неполученные пользователем данные вечно, а разрабатывается лишь для их оперативной доставки.)
Нагрузка на кластер RabbitMQ снизилась, но рост пользователей продолжился. После перевала в 50 тысяч одновременных пользователей система подходила к своей границе по потреблению ресурсов. Надо было снова что-то менять.
Оповещения 2.0
После пережитых ранее проблем поняли, что в данном случае масштабироваться наращиванием узлов кластера RabbitMQ не очень оптимальный путь, так как проблемы на одном узле влияли на работоспособность других узлов, а какая-то отказоустойчивость на уровне дублирования данных для нашей системы не требовалась. Но с другой стороны для бэкендов очень удобно иметь единую точку для подключения. После недолгих дискуссий пришли к выводу, что систему надо разбить на два слоя: 1) кластер RabbitMQ для подключения бэкендов и 2) независимые узлы RabbitMQ для подключения пользователей. В итоге имеем следующую схему:

Рис. 9. Двухслойная схема подключения.
Независимым узлам дали имя «Web», так как подключение пользователей к ним происходит через веб-протоколы. Сами эти узлы подключаются к кластеру с помощью Federation плагина RabbitMQ.
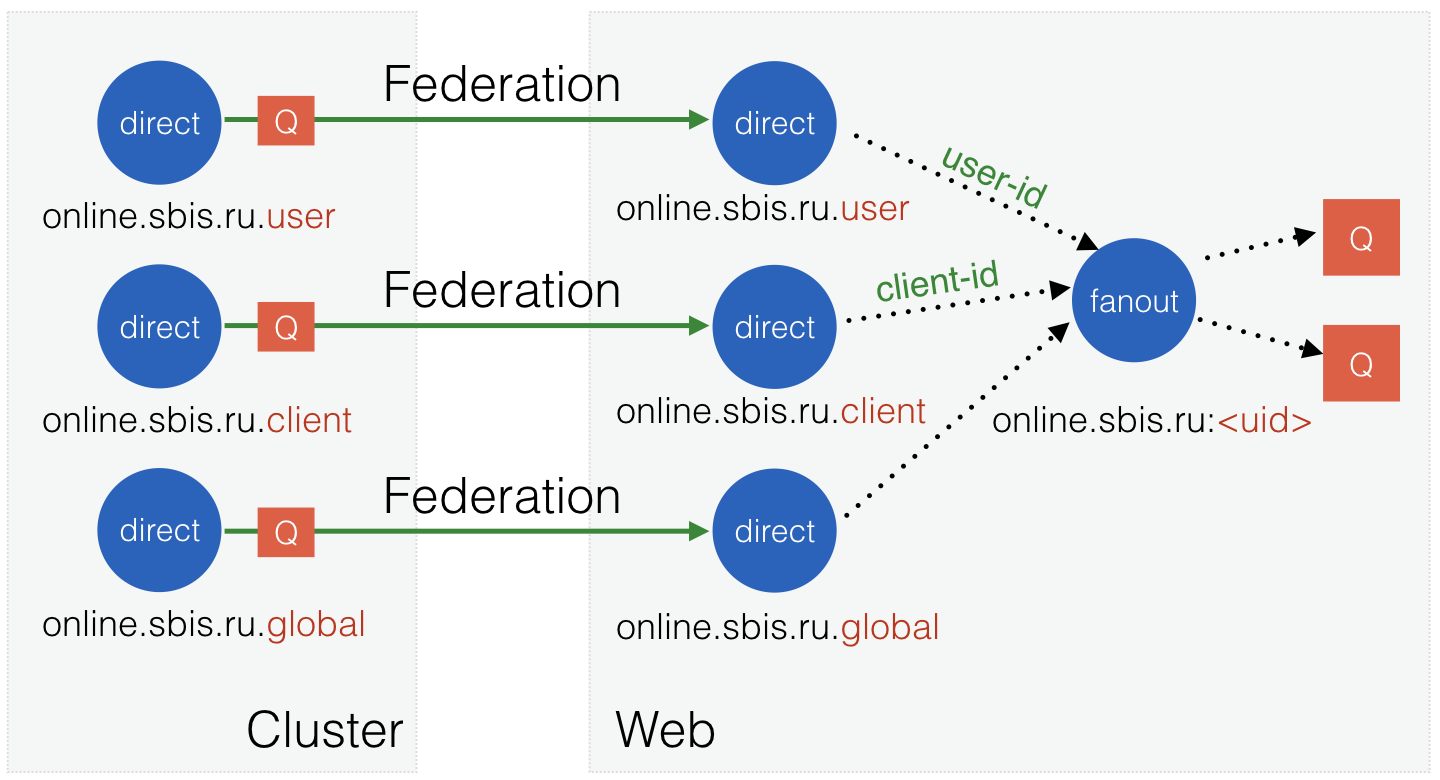
Рис. 10. Структура объектов в двухслойной схеме.
Настройка федерации на web-узлах осуществляется довольно просто:
- Создаём апстрим (upstream, источник), он может состоять как из одного узла, так и из списка узлов для отказоустойчивости;
- Создаём политику, в которой говорим, что обменники с таким-то шаблоном имени должны синхронизироваться с апстримом.
После чего Federation подключится к апстрим узлам, создаст на них свои очереди и подпишет их на нужные обменники, затем начнёт получать сообщения и дублировать их в локальные обменники.
Тем самым сообщение, опубликованное в обменник на кластере, попадёт в такие же обменники на всех веб-узлах. А последние мы можем масштабировать почти линейно в зависимости от количества пользователей. Здорово-то как!
Распределение клиентов
Самым идеальным сценарием было бы равномерное распределение подключений клиентов среди всех web-узлов, а также их «верность» только одному из них, что помогло бы сократить накладные расходы на пользователя. Но не забываем, что узлы выходят из строя, и пользователь не должен ждать, пока этот узел починят. Перед N web-узлами у нас располагаются M диспетчеров (Nginx, проксирующий запрос к нужному бэкенду). И всё, что нам оставалось сделать, это убедиться в идентичности конфигурации на диспетчерах и настроить их на выбор бэкенда по идентификатору пользователя (например, через директиву hash).
Получившаяся схема не лишена недостатков, но в итоге она позволила обслужить большее количество пользователей и выдержать уже порядка 300 тысяч одновременных коннектов к 8-ми web-узлам.
Оповещения 3.0: Новая надежда
Федерация, хватить умничать!
Федерация удобна тем, что создаёт все сама, но её цель – ещё и минимизация трафика между узлами. Поэтому она создаёт связи для своих очередей на апстриме только с ключами, которые есть на подконтрольном ей обменнике. И в нашем случае получалось, что ключей было по количеству пользователей, посетивших тот или иной web-узел. В течение дня их могло набежать по 50 тысяч. А когда на одном из узлов случался коллапс или его просто перегружали, то его пользователи могли «наследить» на других узлах.
Казалось бы, чего тут такого? Но возникают 2 момента:
- На узлах апстрима (на кластерных узлах) было очень большое количество связей, равное общему числу активных пользователей – для любого отправленного сообщения нужно было сначала осуществить поиск заинтересованных очередей web-узлов. С ростом пользователей это не могло не сказаться на производительности.
- И вишенка на торте – синхронизация. После того как web-узел возвращался из перезагрузки или восстанавливал потерянный коннект до апстрима, плагин Federation запускал процесс синхронизации, который обычно длился несколько минут. На протяжении этого времени загрузка процессора на кластерных узлах была высокой и вносила задержки в доставку сообщений.
В качестве замены решили присмотреться к другому схожему плагину – Shovel. Его цель перекачать данные из одного узла в другой без лишних заморочек (ну или между очередями одного узла).
При замене ожидаемо увидели рост сетевой нагрузки, но снижение затрат процессора и уменьшение задержек того стоили. В итоге при переходе на рабочей системе заметили резкое «похудение» кластерных узлов на пару гигабайт памяти, а перезагрузка web-узла не создавала уже дополнительной нагрузки.
Большое количество связей между слоями
Кроме роста числа пользователей и сервисов, также произошёл рост числа веб-сайтов, которые должна была обслуживать наша система оповещения. Если вначале их было 3 штуки, то потом это число выросло до 10, и никто не собирался останавливаться. Как можно понять по последней картинке структуры объектов, в текущей реализации количество подключений зависит от количества обслуживаемых сайтов, да ещё и с коэффициентом 3 (количество областей публикации). Более того, плагин Shovel не работает через политики (как это умеет Federation), и нам нужно создавать все подключения вручную после создания каждого обменника области публикации (этим занимался всё тот же скрипт, выполняющийся при подключении пользователя). А можно ли нам избавиться от такой зависимости и использовать одно подключение для всех сайтов? – Нужно!
Сразу вспомнили об ещё одном типе обменника «из коробки» – headers. Чем он тут не помощник? Принцип его работы таков, что при создании связи к нему задаётся некий набор параметров и их значений, которые также указываются в заголовках сообщений, и если они совпадают, то связь срабатывает. В нашем случае таких параметров получалось два: имя сайта и область публикации. Например, site = "online.sbis.ru" и scope = "user". Эта пара задавалась для связи и для сообщения. Единственное, что останавливало – это приписка в документации, что скорость такого обменника небольшая в сравнении с другими. Но связей с ним у нас было немного, да и количество сообщений не такое уж и большое. Тесты показали, что он достаточно бодренько справляется с нагрузкой. Решили перейти на него.
Это был первый провал такого масштаба, так как тесты оказались недостаточными по продолжительности. Поведение у обменника было очень странное, первые несколько часов всё работало хорошо, а потом скорость обработки медленно снижалась до нуля, хотя количество связей никак не менялось. Пришлось быстренько писать внешний скрипт, который выполнял работу этого обменника. Печалька.
А может свой обменник?
По ходу решения разных проблем с RabbitMQ часто сталкивались с языком Erlang – пришло время изучить его получше. Как оказалось, реализовать свой обменник для RabbitMQ не так уж и сложно. И с этого момента у нас началась новая эра работы с этим брокером.
После изучения кода стандартных обменников (fanout, direct) стало понятно, что от функции route RabbitMQ ждёт список ресурсов, которым нужно отправить копию сообщения. Стандартные обменники добывают этот список ресурсов из внутренней базы связей. Но в нашем случае имена следующих обменников вообще вычисляются на основе входящего сообщения.
route(#exchange{name = #resource{virtual_host = VHost}},
#delivery{message = #basic_message{content = Content}}) ->
Headers = (Content#content.properties)#'P_basic'.headers,
Scope = case rabbit_misc:table_lookup(Headers, <<"scope">>) of
{longstr, Scope} -> Scope;
_ -> <<"user">>
end,
Sites = case rabbit_misc:table_lookup(Headers, <<"sites">>) of
{array, Sites} -> [ Site || {longstr, Site} <- Sites ];
_ -> []
end,
[ rabbit_misc:r(VHost, exchange, <<Site/binary, ".", Scope/binary>>) || Site <- Sites ].Теперь нам нужно всё оформить как плагин для RabbitMQ, что тоже довольно несложно (тогда была версия RabbitMQ 3.5, и было чуть посложней). В итоге всё взлетело и даже работало быстрее fanout'а за счёт отсутствия выборок по базе. Крутяк! Кстати, тип обменника назвали sbis-ep (entry point).
Проблемы при больших сообщениях
В один прекрасный момент web-узлы начали «дохнуть как мухи» из-за нехватки памяти. С помощью плагина rabbitmq_tracing удалось понять, что добрые люди устроили из системы оповещения какой-то CDN и отправляли по 20 Мб данных в одном сообщении. Но их отключение радости не прибавило – падения продолжились (хотя и с меньшей частотой). Самые большие сообщения остались на уровне 400 Кб. Для простого события это тоже довольно много, но система не должна от такого умирать. Первая ночь знакомства с инструментами отладки для Erlang прошла продуктивно, и к утру уже выкатывали исцеляющие патчи. Оказалось, что SockJS использовал для работы с UTF8 модуль xmerl_ucs, который конвертировал всю бинарщину в списки и работал с ними. В итоге это приводило к тому, что 400-килобайтное сообщение во время обработки кушало более 16 Мб памяти. А такие сообщения рассылали сразу нескольким пользователям. В патче работа с UTF8 полностью переделана с использованием только бинарных строк, после чего падений замечено не было. Можно было идти спать.
Отмечаем отсутствующих
Образовалась ещё одна неприятная проблемка из-за того, что в RabbitMQ нет параметра Expire для обменников (только для очередей). Когда пользователь приходил, для него всё создавалось, но, когда уходил, ресурсы не удалялись. Приходилось в профилактических целях периодически перегружать web-узлы. Первый опыт собственного обменника оставил волну позитива – так может сделать ещё один с поддержкой TTL? Wow! А что, если это будет персональный обменник пользователя (он у нас пока fanout), и при своём создании он будет также создавать все остальные объекты, от которых он зависит? Вот это уже совсем по-взрослому! Назовём обменник sbis-user.
Имена вышестоящих обменников и параметры связей зависят от идентификаторов пользователя и клиента, а также от имени сайта, на котором работает пользователь. Их мы можем передать через параметры (arguments) нового обменника при его создании. Ну и добавим возможность управлять временем жизни обменника-сироты тоже через параметр.
Создать обменники и связи – труда много не надо: просто вызывай уже существующие функции RabbitMQ и будет счастье. А вот для организации механизма TTL нужно ещё потрудиться. Дело в том, что обменники не имеют собственного процесса Erlang, где мы могли бы периодически проверять количество текущих пользователей и самоудаляться. Поэтому, кроме реализации модуля обменника, нам нужен ещё и собственный процесс, который бы следил за всеми. Для этого нужно создать Erlang-приложение (application) – оно будет запускаться со стартом нашего нового плагина для брокера и, по сути, содержать один рабочий процесс.
Процесс удаления обменников-сирот мог бы быть реализован наивно: периодически получаем список всех обменников; по каждому из них получаем количество связей; если их нет, то заносим в список на удаление и через нужный интервал удаляем. Но такой подход создаёт большую нагрузку, особенно если у нас десятки или сотни тысяч обменников. В составе API для обменников есть функции, которые брокер вызывает в момент создания или удаления связей. Они как раз то, что поможет нам сделать оптимальное решение. В момент создания новой связи мы всегда удаляем обменник из списка сирот, а в момент удаления связи заносим его туда, если других связей нет.
Последний вопрос: какую структуру нам нужно использовать, чтобы уметь проверять существование обменника в списке, удалять его оттуда, а также искать уже просроченные обменники с наименьшими затратами? После нескольких тестов остановились на комбинации из двух стандартных структур:
- gb_tree, хорош для нахождения минимального значения (обменника с наименьшим временем истечения срока годности, которое сравниваем с текущим временем), в качестве ключа структура {ExpireTime, Exchange}, а значение равно 0 (не используется).
- map (уже работали на Erlang/OTP 18), в качестве ключа Exchange, а в качестве значения ExpireTime, используется для проверки на существования и поиска времени (для удаления из первой структуры).
В дополнение было ограничено количество одновременно удаляемых обменников, чтобы не создавать пиковые нагрузки. Всё, наш второй плагин готов работать на благо пользователей.
Оправдалась ли надежда?
Безусловно да. Мы получаем ещё более простую, красивую и надёжную структуру:
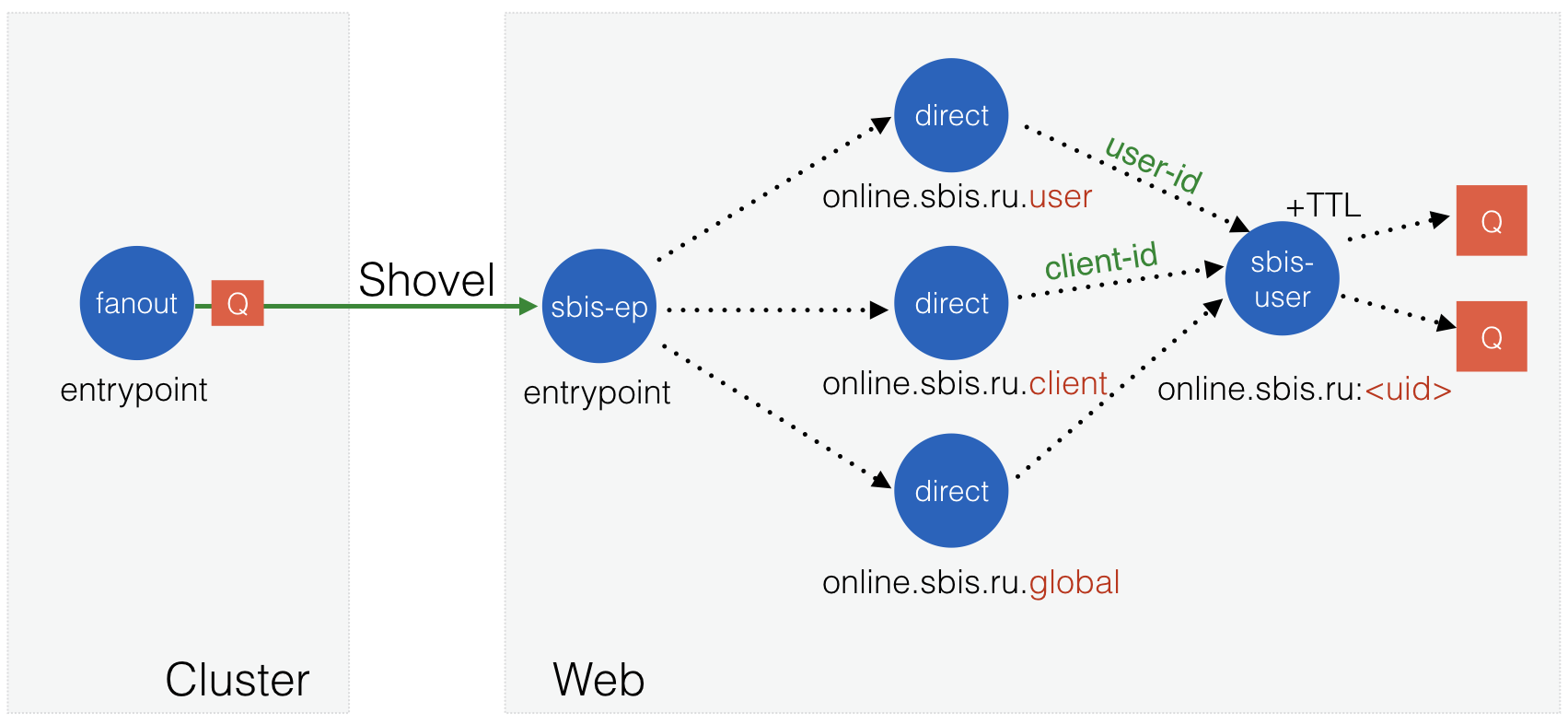
Рис. 11. Структура объектов в схеме с собственными обменниками sbis-ep и sbis-user.
На кластерных узлах у нас остался всего лишь один обменник с типом fanout, между web-узлом и кластером тоже всего лишь одно подключение, схема не зависит от количества сайтов, а после отсутствия пользователя на сайте, выделенные ему ресурсы очищаются. Просто сказка, о чем ещё можно мечтать? В таком виде система прослужила нам до 600 тысяч одновременных коннектов на уже 15 web-узлах, были пики по 300 тысяч исходящих сообщений в секунду. Но это не было её пределом.
Оповещения X: Infinity and beyond
Настало время новых приключений, так как рост пользователей останавливаться не собирался.
Всё внутри
Уже почти все служебные операции работают внутри RabbitMQ (что даёт нам минимальные задержки). Единственная оставшаяся снаружи вещь – это создание персонального обменника пользователя. Но ведь нам ничего не мешает и это реализовать как плагин для RabbitMQ, правда? Так и есть, мы можем использовать уже работающий web-сервер Cowboy и инициировать создание обменников из нашего очередного нового плагина.
Так как браузерной версии SockJS из запроса на /info требуется только флаг websocket, а серверная сторона вообще может обойтись без этого запроса, мы можем не просто перехватывать этот запрос, но и полноценно его обрабатывать. То есть запрос на этот ресурс идёт на наш плагин, а все остальные запросы продолжают ходить только на Web STOMP адаптер RabbitMQ.
64К портов хватит всем
Одной из проблем, из-за которых приходилось поднимать большое количество web-узлов, было ограничение на количество открытых соединений между Nginx и RabbitMQ, стоящих на одном хосте. Nginx'у нельзя было указать исходящий адрес подключения, а на стороне Web STOMP плагина нельзя было указать несколько портов. Кроме того, нужно было видеть, сколько пользователей у нас сейчас живёт на веб-сокетах, а сколько – на XHR-полинге и стриминге. Nginx нам такого не мог рассказать, и приходилось городить не очень хорошие вещи.
Тут на помощь пришёл HAProxy, который позволял нам:
- Отправлять запросы на нужный порт в зависимости от URL (как и Nginx);
- Создавать большое количество коннектов до одного порта (опция source позволяет задать исходящий адрес, а их локально у нас много, 127.0.0.0/8);
- Ограничить максимальное количество коннектов, чтобы защитить сервис от массовых наплывов запросов и сделать его стабильней;
- Получать очень много статистики о работе сервиса (количество текущих подключений по тому или иному транспорту, скорость поступления новых, время ответа, коды ответа, время ожидания запроса в очереди и другие);
- Сэкономить ресурсы. HAProxy потреблял в 3 раза меньше памяти на том же количестве коннектов, а загрузка процессора находилась на 3-5%.
Cache and compress it!
В стандартной поставке RabbitMQ есть удобная веб-консоль управления – Management plugin. Она позволяет обслуживающему персоналу быстро оценить, что сейчас происходит в брокере. Также через её API у нас собирается статистика по работе брокера. Проблема заключается в том, что у неё нет каких-либо кэширующих механизмов, и всю информацию она собирает при каждом запросе. В версии RabbitMQ 3.5 не существует какого-либо постраничного вывода, и всегда отдаётся полный список ресурсов. И ещё по умолчанию включено автообновление данных через 5 секунд. Получается, что при 40 тысячах очередей вся информация по ним может собираться по 10 секунд, кушая немало процессорного времени, и весить по 15-20 Мб (нагрузка на сеть). То есть по умолчанию пользователь будет делать запросы постоянно. А если пользователей несколько? Страшно вспоминать.
До перехода на HAProxy, мы могли бы сделать кэш на Nginx, но сейчас решили попробовать Varnish, так как данных у нас немного и кэширование в памяти более эффективно. Включили кэширование (beresp.ttl) всего контента на 15 секунд (для статики несколько дней) и валидность кэша (beresp.grace) ещё столько же, а также сжатие данных (beresp.do_gzip).
В результате получили:
- Запрос к ресурсу выполняется один раз и не чаще 4 раз в минуту;
- Сжатые данные весят почти в 50 раз меньше исходных (270 КБ против 13 МБ);
- Данные отдавались за считанные миллисекунды (похоже, Varnish отдаёт просроченные данные, если не превышен интервал grace, и в фоне делает запрос к бэкенду за их обновлением – выглядит отлично);
- Нагрузка на брокер не зависит от количества пользователей и поддаётся вычислению.
Свет мой, зеркальце, скажи
После того, как мы оптимизировали web-узлы и научились их хорошо масштабировать, проблемы начали всплывать уже на нижнем слое, на кластерных узлах. Десятки и сотни тысяч исходящих сообщений в секунду в основном случались из-за публикаций в область клиента. Например, в нашей компании в онлайне может быть 5000 человек. Если кто-то будет отправлять по 60 сообщений в секунду на всю компанию, то в итоге будем иметь 60х5000 = 300 тысяч/сек. Для кластерных узлов важен первый множитель – количество публикуемых сообщений бэкендами в RabbitMQ. И в какой-то момент оно также начало расти. Выяснилось, что два узла с полной репликацией (зеркалированием), обслуживающие 18 web-узлов, могли обрабатывать не более 2000 публикаций в секунду, и уже не было возможностей для адекватно масштабирования. Также выросло количество бэкендов, и количество подключений от них превысило отметку в 2500. Схема требовала перемен.
Так как RabbitMQ показал себя достаточно стабильным, а для системы оповещения не требовалась «много девяток после запятой», то решили отказаться от кластера. Тем более бэкенды уже умели работать со списком узлов и повторять запрос на другой узел при отказе какого-то из них. Осталось научить web-узлы подключаться сразу ко всем существующим нижестоящим брокерам, что совсем не является проблемой. Новому типу узлов дали имя route (в будущем на него будут возложены ещё и механизмы маршрутизации), и после перехода на него схема стала выглядеть так:

Рис. 12. Двухслойная схема с некластерными узлами.
Теперь мы можем масштабировать по мере необходимости оба слоя. Вариант с двумя route-узлами такой же конфигурации, как и кластерные узлы, уже обрабатывал около 13 тысяч публикаций в секунду, но это не предел для них!
У вас одно новое сообщение в чате
С развитием и популяризацией чатов в нашем облачном приложении возникла очередная проблема: массовая отправка идентичных сообщений списку пользователей. Если в чате десяток людей, то всё происходит достаточно быстро. Но при нескольких сотнях пользователей публикация сообщений в RabbitMQ могла занимать секунды (а ещё и создавать большую нагрузку). Нужен был механизм, который позволил бы эффективно отправлять сообщение списку получателей.
Сразу стало понятно, что этот список мы можем передать через заголовки AMQP-сообщения (как передаём список сайтов). Проблемой была задача его обработки на web-узлах. Первое решение использовало тот факт, что имена персональных обменников пользователя (sbis-user) как раз и состоят из имени сайта и идентификатора пользователя, и мы можем доработать наш обменник sbis-ep для обработки таких случаев. То есть приходит сообщение со списком сайтов и пользователей, код обменника перемножает эти списки и отдаёт результат RabbitMQ, который ищет по своей базе существующие и направляет в них по копии сообщения. Вариант был прост и быстр в реализации, но имел ряд недостатков:
- Работает только с одной областью публикации (user);
- Создаёт очень избыточный список, так как один web-узел обслуживал только около 5% всех пользователей. Вдобавок они могли жить только на одном сайте, например, из трёх в списке.
Несмотря на все недостатки, решение поступило на рабочие сайты и позволило снизить нагрузку при общении в больших чатах. Единственное, что было добавлено – искусственное ограничение на длину списка пользователей в 50 единиц. Иначе мог получиться большой множитель нагрузки, когда бэкенд опубликовал сообщение за пару миллисекунд, а все web-узлы потом трудились по несколько секунд (с большой силой приходит большая ответственность, но не все разработчики знают и помнят о втором).
Сделаем всё же как надо
Теперь, когда градус последней проблемы немного понижен, можно реализовать механизмы адекватным способом. Правильней всего было бы иметь базу существующих пользователей и производить поиск по ней, вместо генерации большого списка. RabbitMQ уже имеет таблицу во встроенной базе данных Mnesia со списком всех обменников. К сожалению, она организована не лучшим для нашего поиска образом, поэтому придётся делать свою. Новая таблица будет типа set и будет содержать обменник в качестве первичного ключа, за которым будут следовать все остальные нужные идентификаторы для поиска (список которых можно расширять при необходимости).
При обработке сообщений мы теперь строим QLC-запрос, содержащий нужные списки значений, и отдаём его базе на выполнение. Итогом будет список существующих обменников, отвечающих всем критериям. Всё работает корректно, но мы сразу встретили проседание по производительности, хотя ожидали увидеть ускорение. Надо как-то исправлять ситуацию.
Когда мы делаем поиск по первичному ключу, он выполняется почти мгновенно, а для поиска по другим столбцам таблицы приходится проходить по всем её записям. Но ведь в Mnesia существуют вторичные индексы – давайте включим их и насладимся скоростью! И нас ждёт очередное разочарование, ничего не изменилось. Поиск при 50 пользователях и 3 сайтах отрабатывает за 30 миллисекунд. Проблема здесь в том, что мы ищем сразу по двум полям (идентификатор и сайт), и индексы не сильно помогают (так как исходных данных всего около 10 МБ). На выручку приходит тот факт, что для внутренней базы не существует ограничений на типы данных, и мы можем в качестве значения поля вставить кортеж {Site, Ident}. Тогда поиск будет проходить только по одному полю. Теперь вторичный индекс работает в полную силу, но стало ещё хуже, 60 миллисекунд, как так? Дело в том, что нам пришлось развернуть два списка в один большой, и поисковый запрос стал громадным.
Хорошо, зайдём с другой стороны. Mnesia имеет функцию поиска значения по индексу, которая должна отрабатывать за минимальное время, но она работает для одного значения, так что нужно добавить цикл. Вдобавок пустимся во все тяжкие и воспользуемся dirty-операциями в Mnesia для увеличения производительности.
user_find_in_index(Sites, Ids, IndexPos) ->
[ element(2, Item) ||
Site <- Sites,
Id <- Ids,
Item <- mnesia:dirty_index_read(user_route, {Site, Id}, IndexPos) ].Каждый поиск по индексу занимает около 6 микросекунд, то есть при тех же размерах списков мы получим ответ меньше, чем за 1 миллисекунду (при меньших размерах выигрыш ещё больше). Такой результат нас уже устраивает.
Последние сводки с полей
После всех изменений получаем следующую структуру объектов:
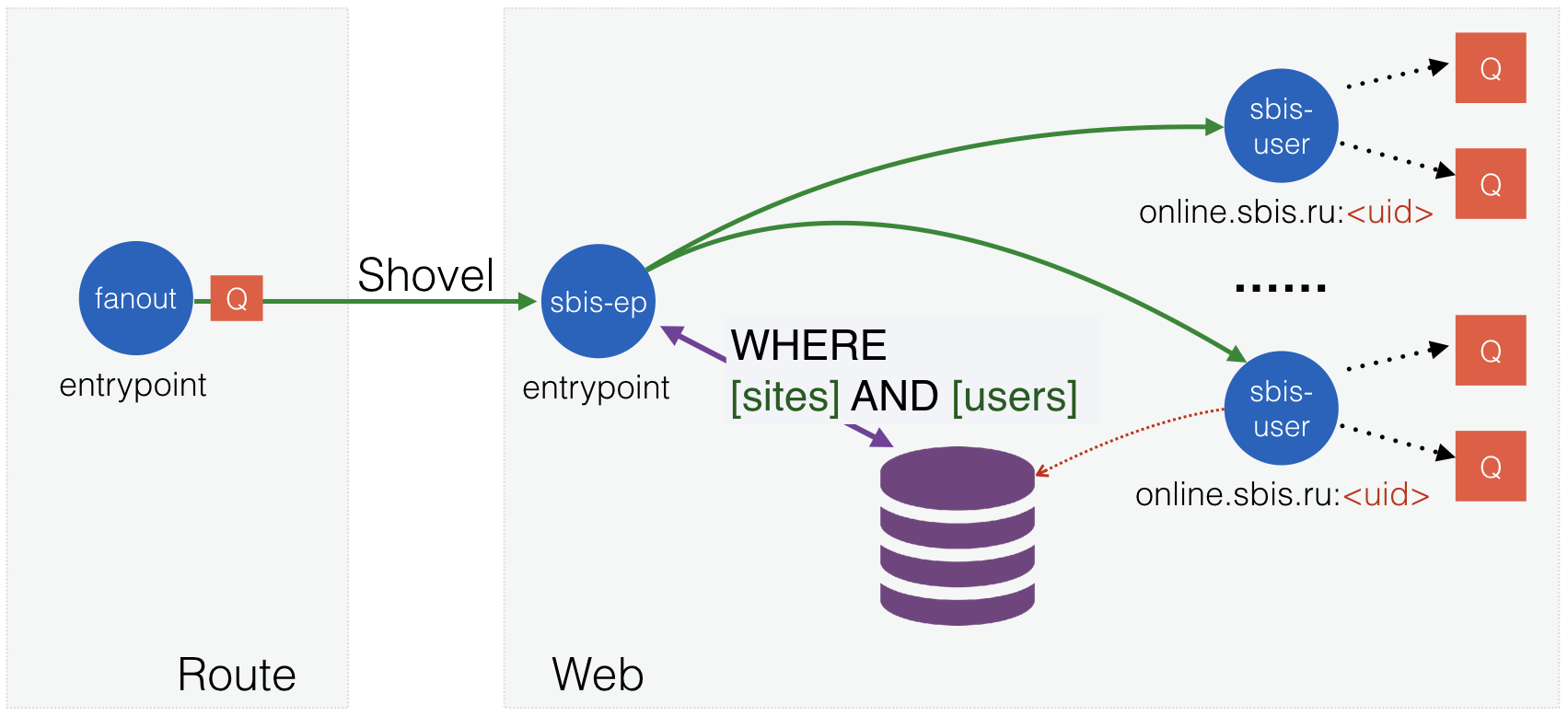
Рис. 13. Конечная структура объектов.
Последняя схема подключения узлов и структура объектов в брокере позволили нам обслужить
1 миллион одновременных веб-сокетов на 21 web-узле (был и 1,1 млн, но агрегация истории в мониторинге не оставила следа от этой цифры):
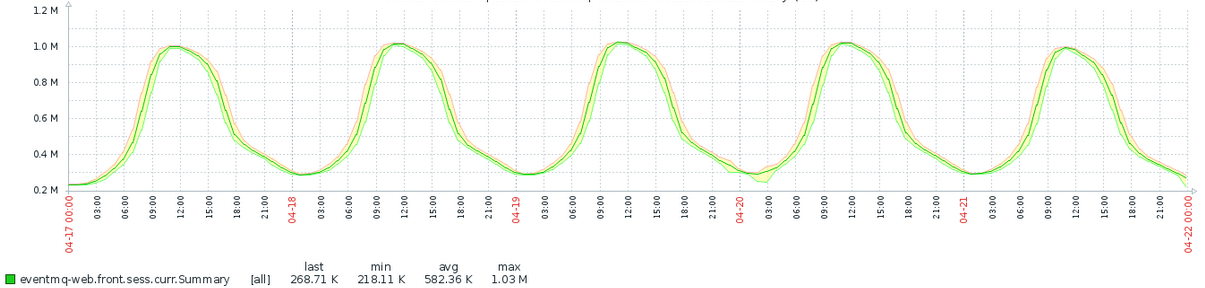
Рис. 14. Общее количество подключений за рабочую неделю.
А также способствовали отправке почти 1,3 миллионов сообщений в секунду до пользователей с суммарным трафиком более 4,2 гигабит/сек:

Рис. 15. Обработка пиковых нагрузок: количество сообщений и мегабайт трафика в секунду.
Заключение
В момент старта построения системы оповещения пользователей с использованием RabbitMQ мы не представляли, насколько большой в итоге получится система, и какой большой объём сообщений сможет обработать. Пусть RabbitMQ и капризничал периодически, но позволил нам реализовать всё с небольшими затратами на разработку (особенно, когда мы овладели кунг-фу по написанию плагинов) и уменьшить время внедрения.
Мы рады поделиться нашим опытом с хабрасообществом и с радостью ответим на все вопросы.
Автор статьи Сергей Яркин
