
В этой статье я хочу рассказать про ещё один этап развития DWH в Тинькофф Банке.
Ни для кого не секрет, что требования к наличию Disaster Recovery (далее DR) в современных бизнес информационных системах относятся к категории «must have». Так, чуть более года назад, команде, занимающейся развитием DWH в банке, была поставлена задача реализовать DR для DWH, на котором построены как offline, так и online процессы банка.

Итак, что было дано:
Задача: обеспечить в течение часа после сбоя, приводящего к неработоспособности Greenplum на основной площадке, работоспособность всех процессов DWH на резервном контуре Greenplum. По сути задача сводится к тому, что бы построить hot standby для Greenplum.
Примерно месяц был отведен нам на исследование и проработку концепции.
Конечно же, первое, что пришло нам в голову — это покопать в направлении вендора — Pivotal, т.е. EMC. В результате проведенных исследований, мы выяснили, что Greenplum не имеет штатного инструмента для построения hot standby, а решение DR для Greenplum потенциально можно построить с помощью EMC Data Domain. Но при более глубоком изучении Data Domain, пришло понимание, что эта технология заточена на создание большого количества бэкапов и в виду этого достаточно дорогая. Также Data Domain “из коробки” не имеет функциональных возможностей поддержки второго контура в актуальном состоянии. От рассмотрения EMC Data Domain мы отказались.
Второй вариант, который мы проработали — это использование стороннего инструмента репликации GreenplumToGreenplum. Вариант довольно быстро изжил себя, т.к. на тот момент в природе не существовало инструментов репликации, поддерживающих Greenplum как источник.
Третий вариант, за который мы взялись — это решение класса Dual Apply. Подсмотрев у Teradata и Informatica их решение под названием Informatica dual load for Teradata dual active solution (Teradata Magazine), начали исследовать рынок технологий, что бы построить аналогичное решение для Greenplum. Но ничего готового не нашли.
После проведенных исследований, решили, что лучшим вариантом будет собственная разработка. Так мы взялись за написание собственной системы и назвали её Dual ETL (в кругах разработчиков проект получил название “Duet”).
В основу концепции построения системы вошел принцип: как только ETL отстроил таблицу на основном контуре Greenplum, система должна отловить это событие и передать данные этой таблицы на резервный контур Greenplum. Таким образом, соблюдая этот принцип, мы синхронно, с некоторой временной задержкой, строим DWH на двух контурах в двух территориально удаленных дата-центрах.

Рис.1 Концептуальная архитектура
В ходе проработки архитектуры система была разбита на шесть компонент:
Для того, что бы сообщать системе о готовности таблицы, была реализована очередь, в которую мы научили наш ETL добавлять объект (т.е. таблицу) как только он закончил её построение. Таким образом была реализована функциональность передачи события системе, после которого система должна была отстроить эту таблицу на резервном контуре Greenplum.
В силу того, что наш планировщик ETL-заданий написан на SAS, плюс у команды DWH имеется в наличии большая экспертиза работы с языком SAS Macro, было принято решение писать управляющий механизм на SAS.
Реализованный механизм производит такие простые действия, как: получить новую таблицу из очереди, запустить компоненту Backup, отправить полученный dump таблицы на резервную площадку, запустить компоненту Restore. В дополнение к этому реализована многопоточность, при том что, кол-во потоков можно регулировать для каждого вида заданий (Backup, транспорт, Restore, перенос buckup-ов на СХД), и конечно же такая необходимая функциональность, как журналирование и e-mail нотификации.
Компонента Backup, для переданной таблицы, вызывает утилиту gp_dump. Мы получаем dump таблицы, размазанный по сегмент-серверам Greenplum основной площадки. Пример вызова утилиты gp_dump:
Основная задача транспортной компоненты — быстро передавать dump-файлы с сегмент-серверов Greenplum основной площадки на соответствующие сегмент-сервера Greenplum резервной площадки. Здесь мы столкнулись с сетевым ограничением, а именно: сегменты основного контура не видят по сети сегменты резервного контура. Благодаря знаниям наших администраторов DWH был придуман способ как, это обойти с помощью SSH-туннелей. Были подняты SSH-туннели на secondary master серверах Greenplum каждого из контуров. Таким образом каждый кусочек dump-а таблицы передавался с сегмент-сервера основной площадки на сегмент-сервер резервной площадки.
После завершения работы транспортной компоненты, мы получаем dump таблицы, размазанный по сегмент-серверам Greenplum резервной площадки. Для этой таблицы компонента Restore запускает утилиту gp_restore. В результате мы получаем обновленную таблицу на резервной площадке. Далее приведен пример вызова утилиты gp_restore:
После завершения разработки основных компонент и первых запусков мы получили в целом работающую систему. Таблицы отстраивались на резервной площадке, журналирование работало, приходили письма на почту и вроде как система работала, но прозрачного понимания того, что в конкретный момент времени происходит внутри у нас не было. Мы озаботились вопросом мониторинга, который разбили на два шага: выделение метрик для мониторинга системы и технологическая составляющая реализации мониторинга.
Метрики выделили довольно быстро, которые на наш взгляд должны были в целом однозначно давать понять в конкретный момент времени что происходит в системе:
С технической реализацией определились тоже довольно быстро — Graphite + Graphana. Развернуть Graphite на отдельной виртуальной машине и запрограммировать придуманные метрики не составило труда. А при помощи Graphana над работающим Graphite был разработан красивый dashboard.
Все вышеперечисленные метрики обрели визуализацию и, что не мало важно, онлайновость:
Рис.2 Количество объектов в статусах
Рис.3 Количество ошибок в статусах

Рис.4 Отставание от момента попадания в очередь

Рис.5 Задержка на старте этапа

Рис.6 Средняя продолжительность этапа (по 10 последним объектам)

Рис.7 Количество работающих потоков на каждом из этапов
После завершения процесса restore dump-файлы переносятся на СХД, на резервной площадке. Между СХД на резервной площадке и СХД на основной площадке настроена репликация, эта репликация реализована на основе технологии NetApp SnapMirror. Тем самым если на основной площадке происходит сбой, требующий восстановления данных, у нас уже имеется подготовленный бэкап на СХД для проведения этих работ.
Система была разработана и получилось все очень даже не плохо. Задачи, которые была призвана решать система, закрываются ей полностью. После завершения разработки, было разработано некоторое количество регламентов, которые позволяли в рамках процесса поддержки DWH осуществлять переход на резервную площадку.
Основное, что мы получили, это конечно же возможность в течение 30 минут переехать на резервную площадку в случае сбоя на основной, что значительно минимизирует простой DWH как информационной системы и как следствие дает возможность бизнесу непрерывно работать с отчетами, данными для анализа, выполняя ad-hoc и не останавливать ряд online процессов. Система также позволила нам отказаться от процедуры ежедневного регламентного бэкапа, в пользу бэкапа, получаемого системой Dual ETL.
Через систему в день проходит около 6500 объектов (таблиц) суммарным объемом около 20ТБ.
На примере метрики «Отставание от момента попадания в очередь» (см. рис.8)
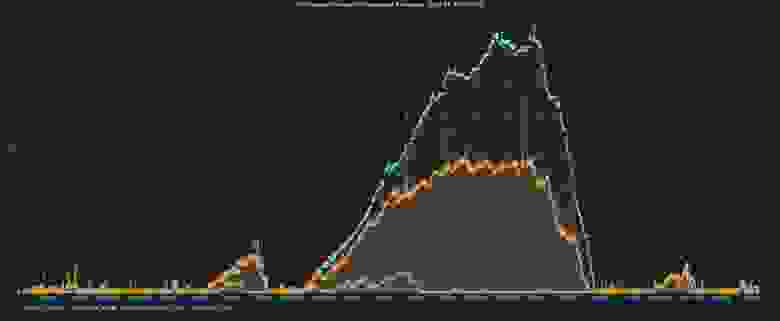
Рис.8 Отставание от момента попадания в очередь
можно наблюдать отставание резервной площадки от основной. Во время работы ночного планировщика, когда ETL активно строит хранилище, отставание в пике доходит до 2-3 часов. К моменту завершения построения хранилища, 10-и утра, отставание снижается и держится на уровне 5-10 минут. В течение дня могут появляться всплески отставания во время работы online планировщика, в пределах 30 минут.
А также относительно недавно у нашей системы случился маленький юбилей, через неё пролетел 1 000 000 (миллионный) объект!
Команда DWH в Тинькофф Банке берет стратегический курс в направлении Hadoop. В следующих статьях планируем осветить темы «ETL/ELT на Hadoop» и «Ad-hoc отчетность на Hadoop».
Ни для кого не секрет, что требования к наличию Disaster Recovery (далее DR) в современных бизнес информационных системах относятся к категории «must have». Так, чуть более года назад, команде, занимающейся развитием DWH в банке, была поставлена задача реализовать DR для DWH, на котором построены как offline, так и online процессы банка.

Постановка задачи
Итак, что было дано:
- Система захвата изменений на стороне источников данных и применение их в слой Online Operational Data (далее OOD) — Attunity Replicate;
- Загрузка, преобразование данных, IN/OUT интеграция данных, расчет витрин и весь ETL/ELT — SAS Data Integration Studio, ~1700 ETL заданий;
- Основная СУБД на которой построено DWH в банке — MPP DBMS Pivotal Greenplum, объем данных ~30ТБ;
- Отчетность, Business Intelligence, Ad-hoc — SAP BusinessObjects + SAS Enterprise Guide;
- Два дата-центра, территориально разнесенных по разным концам Москвы, между которыми есть сетевой канал.
Задача: обеспечить в течение часа после сбоя, приводящего к неработоспособности Greenplum на основной площадке, работоспособность всех процессов DWH на резервном контуре Greenplum. По сути задача сводится к тому, что бы построить hot standby для Greenplum.
Исследование
Примерно месяц был отведен нам на исследование и проработку концепции.
Конечно же, первое, что пришло нам в голову — это покопать в направлении вендора — Pivotal, т.е. EMC. В результате проведенных исследований, мы выяснили, что Greenplum не имеет штатного инструмента для построения hot standby, а решение DR для Greenplum потенциально можно построить с помощью EMC Data Domain. Но при более глубоком изучении Data Domain, пришло понимание, что эта технология заточена на создание большого количества бэкапов и в виду этого достаточно дорогая. Также Data Domain “из коробки” не имеет функциональных возможностей поддержки второго контура в актуальном состоянии. От рассмотрения EMC Data Domain мы отказались.
Второй вариант, который мы проработали — это использование стороннего инструмента репликации GreenplumToGreenplum. Вариант довольно быстро изжил себя, т.к. на тот момент в природе не существовало инструментов репликации, поддерживающих Greenplum как источник.
Третий вариант, за который мы взялись — это решение класса Dual Apply. Подсмотрев у Teradata и Informatica их решение под названием Informatica dual load for Teradata dual active solution (Teradata Magazine), начали исследовать рынок технологий, что бы построить аналогичное решение для Greenplum. Но ничего готового не нашли.
После проведенных исследований, решили, что лучшим вариантом будет собственная разработка. Так мы взялись за написание собственной системы и назвали её Dual ETL (в кругах разработчиков проект получил название “Duet”).
Duet и как мы его строили
Концептуальная архитектура
В основу концепции построения системы вошел принцип: как только ETL отстроил таблицу на основном контуре Greenplum, система должна отловить это событие и передать данные этой таблицы на резервный контур Greenplum. Таким образом, соблюдая этот принцип, мы синхронно, с некоторой временной задержкой, строим DWH на двух контурах в двух территориально удаленных дата-центрах.
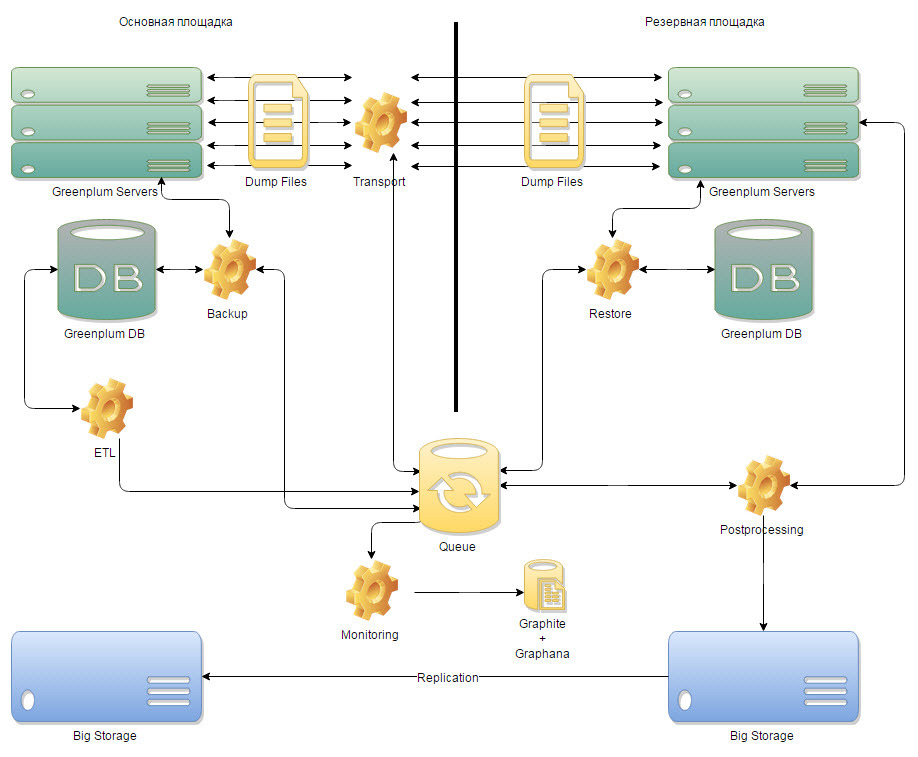
Рис.1 Концептуальная архитектура
В ходе проработки архитектуры система была разбита на шесть компонент:
- Компонента Backup, которая должна работать на основной площадке и отвечать за получение данных;
- Транспортная компонента, отвечающая за передачу данных между основной и резервной площадками;
- Компонента Restore, которая должна работать на резервной площадке и отвечать за применение данных;
- Компонента переноса на СХД и сбора дневного backup;
- Управляющая компонента, которая должна рулить всеми процессами системы;
- И компонента мониторинга, которая должна была давать понимание, что происходит в системе и на сколько резервная площадка отстаёт от основной площадки.
Доработка существующего ETL
Для того, что бы сообщать системе о готовности таблицы, была реализована очередь, в которую мы научили наш ETL добавлять объект (т.е. таблицу) как только он закончил её построение. Таким образом была реализована функциональность передачи события системе, после которого система должна была отстроить эту таблицу на резервном контуре Greenplum.
Реализация управляющей компоненты
В силу того, что наш планировщик ETL-заданий написан на SAS, плюс у команды DWH имеется в наличии большая экспертиза работы с языком SAS Macro, было принято решение писать управляющий механизм на SAS.
Реализованный механизм производит такие простые действия, как: получить новую таблицу из очереди, запустить компоненту Backup, отправить полученный dump таблицы на резервную площадку, запустить компоненту Restore. В дополнение к этому реализована многопоточность, при том что, кол-во потоков можно регулировать для каждого вида заданий (Backup, транспорт, Restore, перенос buckup-ов на СХД), и конечно же такая необходимая функциональность, как журналирование и e-mail нотификации.
Реализация компоненты Backup
Компонента Backup, для переданной таблицы, вызывает утилиту gp_dump. Мы получаем dump таблицы, размазанный по сегмент-серверам Greenplum основной площадки. Пример вызова утилиты gp_dump:
gp_dump --username=gpadmin --gp-d=$DIRECTORY --gp-r=$REPORT_DIR $COMPRESS -t $TABLE db_$DWH_DP_MODE &> /tmp/gp_dump_$NOW
Реализация транспортной компоненты
Основная задача транспортной компоненты — быстро передавать dump-файлы с сегмент-серверов Greenplum основной площадки на соответствующие сегмент-сервера Greenplum резервной площадки. Здесь мы столкнулись с сетевым ограничением, а именно: сегменты основного контура не видят по сети сегменты резервного контура. Благодаря знаниям наших администраторов DWH был придуман способ как, это обойти с помощью SSH-туннелей. Были подняты SSH-туннели на secondary master серверах Greenplum каждого из контуров. Таким образом каждый кусочек dump-а таблицы передавался с сегмент-сервера основной площадки на сегмент-сервер резервной площадки.
Реализации компоненты Restore
После завершения работы транспортной компоненты, мы получаем dump таблицы, размазанный по сегмент-серверам Greenplum резервной площадки. Для этой таблицы компонента Restore запускает утилиту gp_restore. В результате мы получаем обновленную таблицу на резервной площадке. Далее приведен пример вызова утилиты gp_restore:
gp_restore $COMPRESS --gp-d=$SOURCE --gp-r=$REPORT_DIR --gp-k=$KEY -s --status=$SOURCE -d db_$DWH_DP_MODE > /tmp/gp_restore_$(echo $KEY)_$RAND 2>>/tmp/gp_restore_$(echo $KEY)_$RAND
Реализация мониторинга
После завершения разработки основных компонент и первых запусков мы получили в целом работающую систему. Таблицы отстраивались на резервной площадке, журналирование работало, приходили письма на почту и вроде как система работала, но прозрачного понимания того, что в конкретный момент времени происходит внутри у нас не было. Мы озаботились вопросом мониторинга, который разбили на два шага: выделение метрик для мониторинга системы и технологическая составляющая реализации мониторинга.
Метрики выделили довольно быстро, которые на наш взгляд должны были в целом однозначно давать понять в конкретный момент времени что происходит в системе:
- Количество объектов в статусах;
- Количество ошибок в статусах;
- Отставание от момента попадания в очередь;
- Задержка на старте этапа;
- Средняя продолжительность этапа (по 10 последним объектам);
- А также мониторинг количества работающих потоков на каждом из этапов.
С технической реализацией определились тоже довольно быстро — Graphite + Graphana. Развернуть Graphite на отдельной виртуальной машине и запрограммировать придуманные метрики не составило труда. А при помощи Graphana над работающим Graphite был разработан красивый dashboard.
Все вышеперечисленные метрики обрели визуализацию и, что не мало важно, онлайновость:
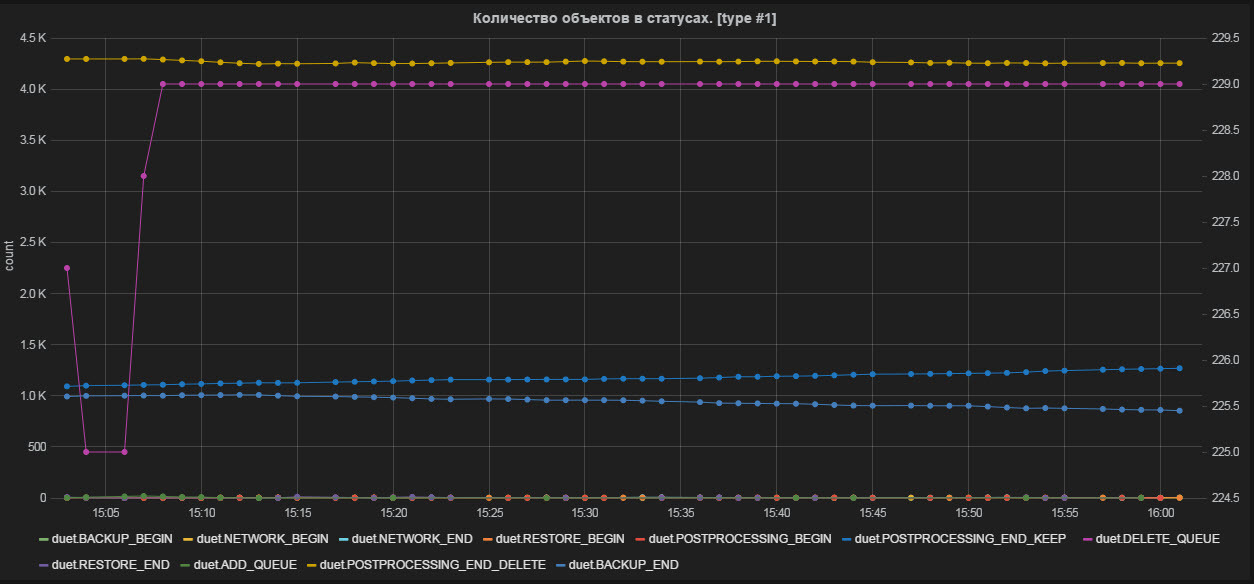
Рис.2 Количество объектов в статусах
Рис.3 Количество ошибок в статусах

Рис.4 Отставание от момента попадания в очередь
Рис.5 Задержка на старте этапа
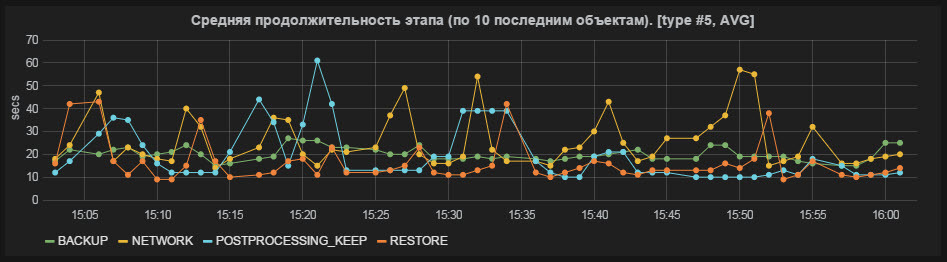
Рис.6 Средняя продолжительность этапа (по 10 последним объектам)

Рис.7 Количество работающих потоков на каждом из этапов
Постобработка
После завершения процесса restore dump-файлы переносятся на СХД, на резервной площадке. Между СХД на резервной площадке и СХД на основной площадке настроена репликация, эта репликация реализована на основе технологии NetApp SnapMirror. Тем самым если на основной площадке происходит сбой, требующий восстановления данных, у нас уже имеется подготовленный бэкап на СХД для проведения этих работ.
Итоги
Что мы получили
Система была разработана и получилось все очень даже не плохо. Задачи, которые была призвана решать система, закрываются ей полностью. После завершения разработки, было разработано некоторое количество регламентов, которые позволяли в рамках процесса поддержки DWH осуществлять переход на резервную площадку.
Основное, что мы получили, это конечно же возможность в течение 30 минут переехать на резервную площадку в случае сбоя на основной, что значительно минимизирует простой DWH как информационной системы и как следствие дает возможность бизнесу непрерывно работать с отчетами, данными для анализа, выполняя ad-hoc и не останавливать ряд online процессов. Система также позволила нам отказаться от процедуры ежедневного регламентного бэкапа, в пользу бэкапа, получаемого системой Dual ETL.
Статистика работы
Через систему в день проходит около 6500 объектов (таблиц) суммарным объемом около 20ТБ.
На примере метрики «Отставание от момента попадания в очередь» (см. рис.8)
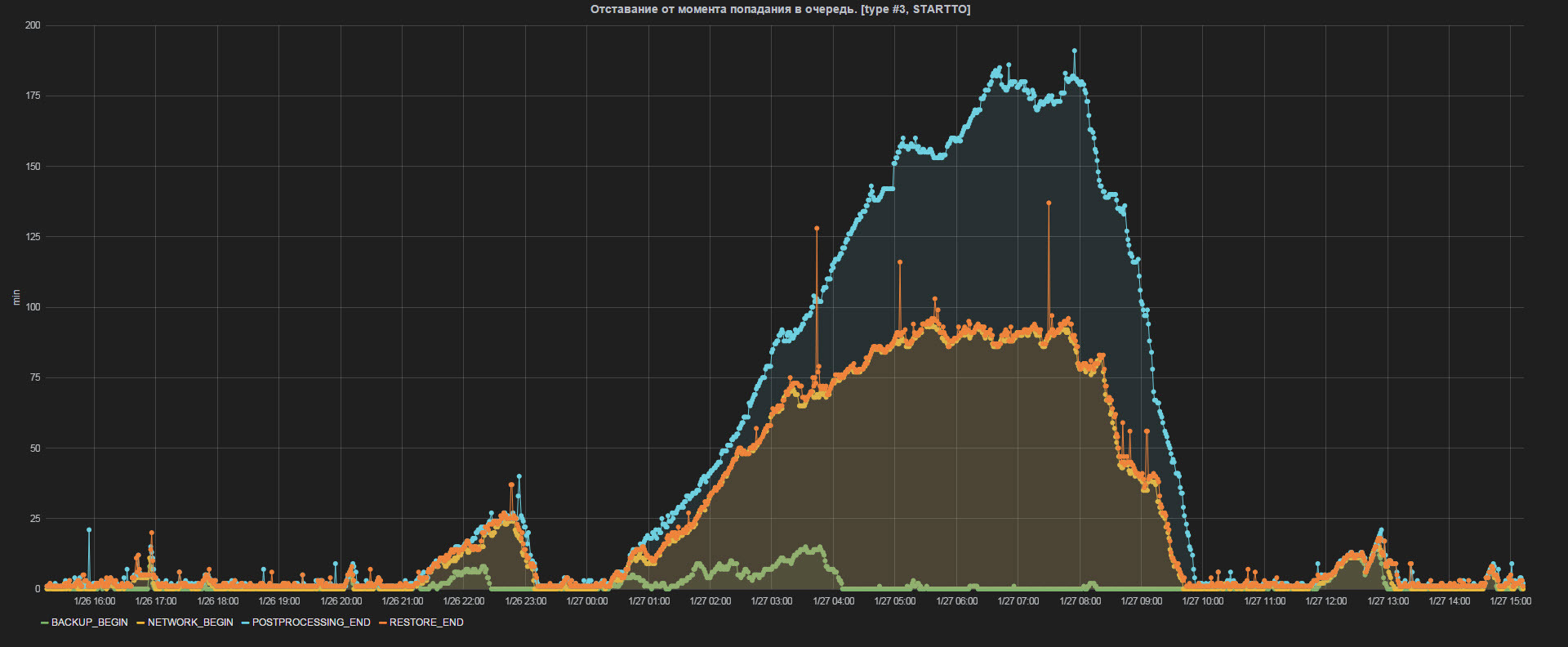
Рис.8 Отставание от момента попадания в очередь
можно наблюдать отставание резервной площадки от основной. Во время работы ночного планировщика, когда ETL активно строит хранилище, отставание в пике доходит до 2-3 часов. К моменту завершения построения хранилища, 10-и утра, отставание снижается и держится на уровне 5-10 минут. В течение дня могут появляться всплески отставания во время работы online планировщика, в пределах 30 минут.
А также относительно недавно у нашей системы случился маленький юбилей, через неё пролетел 1 000 000 (миллионный) объект!
Эпилог
Команда DWH в Тинькофф Банке берет стратегический курс в направлении Hadoop. В следующих статьях планируем осветить темы «ETL/ELT на Hadoop» и «Ad-hoc отчетность на Hadoop».
