
В этой статье я хочу рассказать про следующий этап развития DWH в Тинькофф Банке и о переходе от парадигмы классического DWH к парадигме Data Lake.
Свой рассказ я хочу начать с такой вот веселой картинки:

Да, ещё несколько лет назад картинка была актуальной. Но сейчас, с развитием технологий, входящих в эко-систему Hadoop и развитием ETL платформ правомерно утверждать то, что ETL на Hadoop не просто существует но и то, что ETL на Hadoop ждет большое будущее. Далее в статье расскажу про то, как мы строим ETL на Hadoop в Тинькофф Банке.
Перед управлением DWH была поставлена большая задача – анализировать интересы и поведение интернет посетителей сайта банка. У DWH образовалось два новых источника данных, больших данных – это clickstream с портала (www.tinkoff.ru) и RTB (Real-Time Bidding) платформа банка. Два источника порождают колоссальный объём текстовых полуструктурированных данных, что конечно для традиционного DWH, построенного в банке на массивно параллельной СУБД Greenplum, совсем не подходит. В банке был развернут кластер Hadoop, на основе дистрибутива Cloudera, он то и лег в основу целевого хранилища данных, а точнее озера данных, для внешних данных.
Важно было на начальных этапах продумать и зафиксировали концептуальную архитектуру, которой нужно будет придерживаться в ходе моделирования новых структур для хранения данных и работы по загрузке данных. Мы очень не хотели превратить наше озеро в болото данных :) Как и в классическом DWH, мы выделили основные концептуальные слои данных (см. Рис. 1).
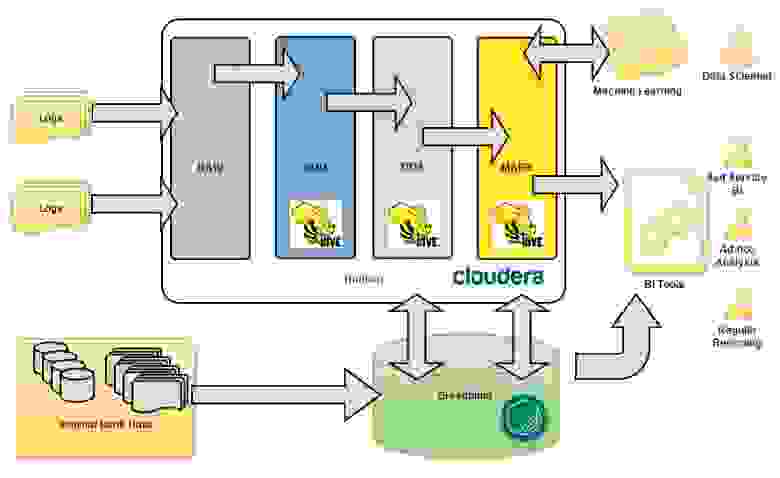
Рис.1 Концепция
Почему Data Vault? У этого подхода есть и свои плюсы, и свои минусы.
Плюсы:
Минусы:
Проанализировав тренды развития технологий Hadoop, мы решили использовать этот подход и засучив рукава принялись моделировать Data Vault для выше озвученной задачи.
Собственно, хочу рассказать несколько концептов, которые мы используем. Например, в загрузке визитов интернет-пользователей по страницам мы не сохраняем каждый раз URL визита. Все URL-ы мы выделили, в терминах Data Vault, в отдельный хаб (см. Рис. 2). Такой подход позволяет значительно сэкономить место в HDFS и более гибко работать с URL-ами на этапе загрузки и дальнейшей обработки данных.
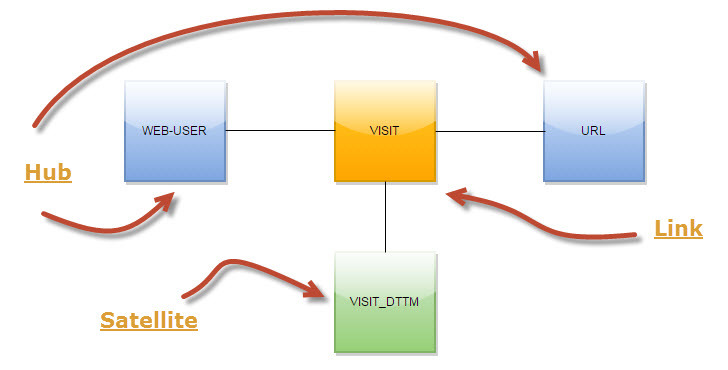
Рис.2 Data Vault для визитов
Ещё один концепт относится к области загрузки интернет пользователей. Мы не получаем на этапе загрузки в DDS единого интернет пользователя, а загружаем данные в разрезе систем источников. Таким образом загрузки в Data Vault из разных источников не зависят друг от друга.
Важно было сразу предусмотреть физическую структуру хранения данных в Hadoop, т.е. сразу хорошо продумать DDL таблиц в Hive. На этом этапе мы зафиксировали два соглашения:
В результате каждый объект (таблица) Data Vault в своем DDL содержит:
и
Вот и подошли к самому интересному. Концепцию продумали, моделирование провели, создали структуры данных, теперь хорошо бы было бы это все наполнить данными.
Для того что бы обеспечить стабильный поток данных (файлов) в слой RAW мы используем Apache Flume. Для обеспечения отказоустойчивости и независимости от кластера Hadoop мы разместили Flume на отдельном сервере – получили такой как бы File Gate, перед кластером Hadoop. Ниже приведу пример настройки агента Flume для передачи портального syslog:
Таким образом, мы получили стабильный поток данных в слой RAW. Дальше нужно разложить эти данные в модель, наполнить Data Vault, ну короче нужен ETL на Hadoop.
Барабанная дробь, гаснет свет, на сцену выходит Informatica Big Data Edition. Не буду в красках и много рассказывать про этот ETL инструмент, постараюсь коротко и по делу.
Лирическое отступление. Хочется сразу отметить, что Informatica Platform (в которую входит BDE), это не та всем знакомая Informatica PowerCenter. Это принципиально новая платформа интеграции данных от корпорации Informatica, на которую сейчас постепенно переносят весь тот большой набор полезных функций из старого и всеми любимого PowerCenter.
Теперь по делу. Informatica BDE позволяет достаточно быстро разрабатывать ETL процедуры (маппинги), среда очень удобная и не требует длительного обучения. Маппинг транслируется в HiveQL и выполняется на кластере Hadoop, Informatica обеспечивает удобный мониторинг, последовательность запуска ETL процессов, обработку ветвлений и исключительных ситуаций.
Например, вот так выглядит маппинг, который наполняет хаб интернет юзеров нашего портала (см. Рис. 3).
Рис.3 Маппинг
Оптимизатор Informatica BDE транслирует этот маппинг в HiveQL и сам определяет шаги исполнения (см. Рис. 4).

Рис.4 План выполнения
Informatica BDE позволяет гибко управлять параметрами среды выполнения. Например, мы у себя настроили следующие параметры:
Маппинги можно объединять в потоки. Например, у нас данные из отдельных систем источников загружаются в отдельных потоках (см. Рис. 5).

Рис.5 Поток загрузки данных
Informatica BDE обладает удобным инструментом администрирования и мониторинга (см. Рис. 6).
Рис.6 Мониторинг исполнения потока данных
Из преимуществ Informatica BDE можно выделить следующее:
Из недостатков можно выделить следующее:
В целом инструмент Informatica BDE весьма хорошо показал себя при работе с Hadoop и у нас на него дальше очень большие планы в части ETL на Hadoop. Думаю, в скором времени напишем ещё более предметные статьи о реализации ETL на Hadoop на Informatica BDE.
Основной результат, который мы получили на данным этапе — это стабильно работающий ETL, наполняющий DDS. Результат был получен за два месяца, командой из двух ETL разработчиков и архитектора. Сейчас мы ежедневно прогоняем через ETL на Hadoop ~100Gb текстовых логов и получаем в Data Vault примерно на порядок меньше данных, на основе которых собираются витрины данных. Загрузка в модель происходит на ночном регламенте, загружается дневной инкремент данных. Длительность загрузки составляет ~2 часа. С этими данными, выполняя Ad-hoc запросы, работают аналитики через Hue и IPython.
Свой рассказ я хочу начать с такой вот веселой картинки:

Да, ещё несколько лет назад картинка была актуальной. Но сейчас, с развитием технологий, входящих в эко-систему Hadoop и развитием ETL платформ правомерно утверждать то, что ETL на Hadoop не просто существует но и то, что ETL на Hadoop ждет большое будущее. Далее в статье расскажу про то, как мы строим ETL на Hadoop в Тинькофф Банке.
От задачи к реализации
Перед управлением DWH была поставлена большая задача – анализировать интересы и поведение интернет посетителей сайта банка. У DWH образовалось два новых источника данных, больших данных – это clickstream с портала (www.tinkoff.ru) и RTB (Real-Time Bidding) платформа банка. Два источника порождают колоссальный объём текстовых полуструктурированных данных, что конечно для традиционного DWH, построенного в банке на массивно параллельной СУБД Greenplum, совсем не подходит. В банке был развернут кластер Hadoop, на основе дистрибутива Cloudera, он то и лег в основу целевого хранилища данных, а точнее озера данных, для внешних данных.
Концепция построения озера
Важно было на начальных этапах продумать и зафиксировали концептуальную архитектуру, которой нужно будет придерживаться в ходе моделирования новых структур для хранения данных и работы по загрузке данных. Мы очень не хотели превратить наше озеро в болото данных :) Как и в классическом DWH, мы выделили основные концептуальные слои данных (см. Рис. 1).
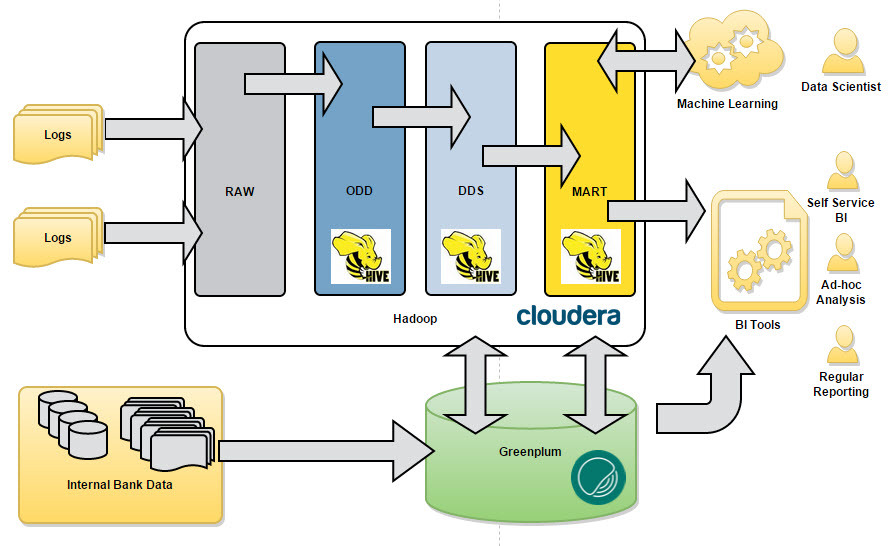
Рис.1 Концепция
- RAW – слой сырых данных, сюда загружаем файлы, логи, архивы. Форматы могут быть абсолютно различные: tsv, csv, xml, syslog, json и т.д. и т.п.;
- ODD — Operational Data Definition. Сюда мы загружаем данные в формате приближенном к реляционному. Данные здесь могут являться результатом предобработки данных из RAW перед загрузкой в DDS;
- DDS — Detail Data Store. Здесь мы собираем консолидированную модель детальных данных. Для хранения данных в этом слое мы выбрали концепцию Data Vault;
- MART – витрины данных. Здесь мы собираем прикладные витрины данных.
Data Vault и как мы его готовим
Почему Data Vault? У этого подхода есть и свои плюсы, и свои минусы.
Плюсы:
- Гибкость моделирования
- Быстрая и удобная разработка ETL процессов
- Отсутствие избыточности данных, а для больших данных это весьма важный аргумент
Минусы:
- Основной минус для нас был обусловлен средой хранения (а точнее и обработки) данных и как следствие производительностью работы join операций. Как известно Hive не очень любит операции join, в силу того, что в итоге всё выливается в медленный map reduce.
Проанализировав тренды развития технологий Hadoop, мы решили использовать этот подход и засучив рукава принялись моделировать Data Vault для выше озвученной задачи.
Собственно, хочу рассказать несколько концептов, которые мы используем. Например, в загрузке визитов интернет-пользователей по страницам мы не сохраняем каждый раз URL визита. Все URL-ы мы выделили, в терминах Data Vault, в отдельный хаб (см. Рис. 2). Такой подход позволяет значительно сэкономить место в HDFS и более гибко работать с URL-ами на этапе загрузки и дальнейшей обработки данных.
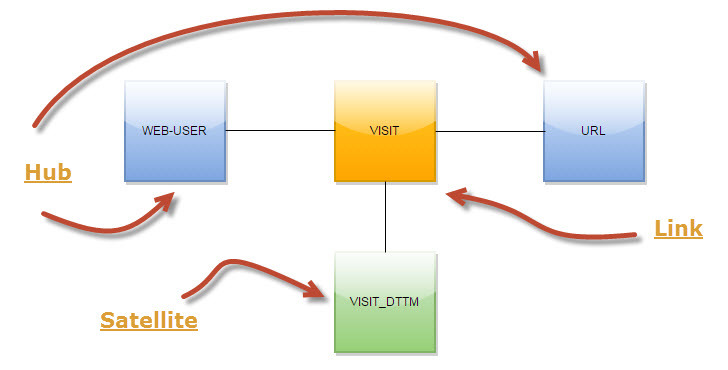
Рис.2 Data Vault для визитов
Ещё один концепт относится к области загрузки интернет пользователей. Мы не получаем на этапе загрузки в DDS единого интернет пользователя, а загружаем данные в разрезе систем источников. Таким образом загрузки в Data Vault из разных источников не зависят друг от друга.
Важно было сразу предусмотреть физическую структуру хранения данных в Hadoop, т.е. сразу хорошо продумать DDL таблиц в Hive. На этом этапе мы зафиксировали два соглашения:
- Использование партиционирования в HDFS;
- Эмуляция дистрибьюции по ключу в HDFS.
В результате каждый объект (таблица) Data Vault в своем DDL содержит:
PARTITIONED BY (ymd string, load_src string)и
CLUSTERED BY (l_visit_rk) INTO 64 BUCKETSРеки ETL в озере данных
Вот и подошли к самому интересному. Концепцию продумали, моделирование провели, создали структуры данных, теперь хорошо бы было бы это все наполнить данными.
Для того что бы обеспечить стабильный поток данных (файлов) в слой RAW мы используем Apache Flume. Для обеспечения отказоустойчивости и независимости от кластера Hadoop мы разместили Flume на отдельном сервере – получили такой как бы File Gate, перед кластером Hadoop. Ниже приведу пример настройки агента Flume для передачи портального syslog:
# *** Clickstream PROD syslog source ***
a3.sources = r1 r2
a3.channels = c1
a3.sinks = k1
a3.sources.r1.type = syslogtcp
a3.sources.r2.type = syslogudp
a3.sources.r1.port = 5141
a3.sources.r2.port = 5141
a3.sources.r1.host = 0.0.0.0
a3.sources.r2.host = 0.0.0.0
a3.sources.r1.channels = c1
a3.sources.r2.channels = c1
# channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
# sink
a3.sinks.k1.type = hdfs
a3.sinks.k1.channel = c1
a3.sinks.k1.hdfs.path = /prod_raw/portal/clickstream/ymd=%Y-%m-%d
a3.sinks.k1.hdfs.useLocalTimeStamp = true
a3.sinks.k1.hdfs.filePrefix = clickstream
a3.sinks.k1.hdfs.rollCount = 100000
a3.sinks.k1.hdfs.rollSize = 0
a3.sinks.k1.hdfs.rollInterval = 600
a3.sinks.k1.hdfs.idleTimeout = 0
a3.sinks.k1.hdfs.fileType = CompressedStream
a3.sinks.k1.hdfs.codeC = bzip2
# *** END ***
Таким образом, мы получили стабильный поток данных в слой RAW. Дальше нужно разложить эти данные в модель, наполнить Data Vault, ну короче нужен ETL на Hadoop.
Барабанная дробь, гаснет свет, на сцену выходит Informatica Big Data Edition. Не буду в красках и много рассказывать про этот ETL инструмент, постараюсь коротко и по делу.
Лирическое отступление. Хочется сразу отметить, что Informatica Platform (в которую входит BDE), это не та всем знакомая Informatica PowerCenter. Это принципиально новая платформа интеграции данных от корпорации Informatica, на которую сейчас постепенно переносят весь тот большой набор полезных функций из старого и всеми любимого PowerCenter.
Теперь по делу. Informatica BDE позволяет достаточно быстро разрабатывать ETL процедуры (маппинги), среда очень удобная и не требует длительного обучения. Маппинг транслируется в HiveQL и выполняется на кластере Hadoop, Informatica обеспечивает удобный мониторинг, последовательность запуска ETL процессов, обработку ветвлений и исключительных ситуаций.
Например, вот так выглядит маппинг, который наполняет хаб интернет юзеров нашего портала (см. Рис. 3).
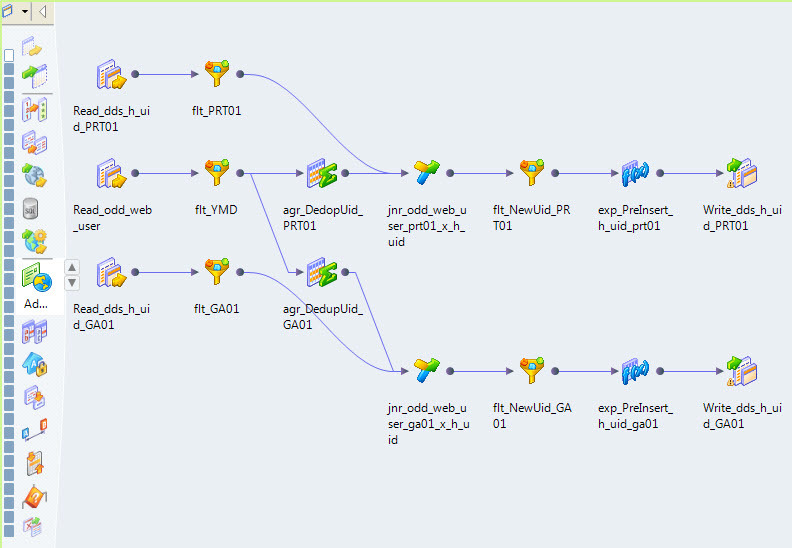
Рис.3 Маппинг
Оптимизатор Informatica BDE транслирует этот маппинг в HiveQL и сам определяет шаги исполнения (см. Рис. 4).

Рис.4 План выполнения
Informatica BDE позволяет гибко управлять параметрами среды выполнения. Например, мы у себя настроили следующие параметры:
mapreduce.input.fileinputformat.split.minsize = 256000000
mapred.java.child.opts = -Xmx1g
mapred.child.ulimit = 2
mapred.tasktracker.map.tasks.maximum = 100
mapred.tasktracker.reduce.tasks.maximum = 150
io.sort.mb = 100
hive.exec.dynamic.partition.mode = nonstrict
hive.optimize.ppd = true
hive.exec.max.dynamic.partitions = 100000
hive.exec.max.dynamic.partitions.pernode = 10000
Маппинги можно объединять в потоки. Например, у нас данные из отдельных систем источников загружаются в отдельных потоках (см. Рис. 5).
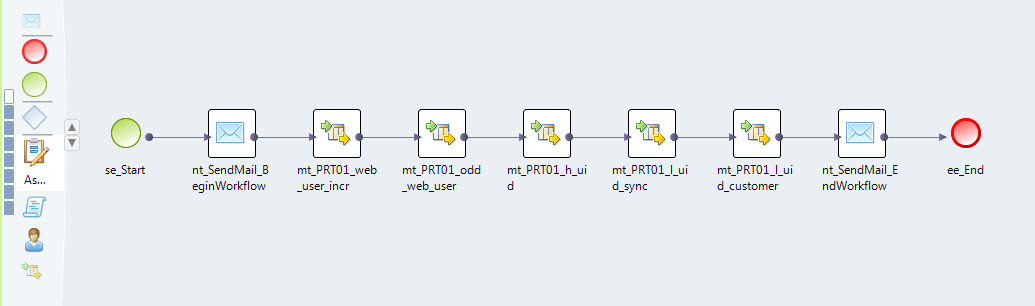
Рис.5 Поток загрузки данных
Informatica BDE обладает удобным инструментом администрирования и мониторинга (см. Рис. 6).
Рис.6 Мониторинг исполнения потока данных
Из преимуществ Informatica BDE можно выделить следующее:
- Поддержка множества дистрибутивов Hadoop: Cloudera, Hortonworks, MapR, PivotalHD, IBM Biginsights;
- Быстрая имплементация в продукт новых фич, разрабатываемых в Hadoop: поддержка новых версий дистрибутивов, поддержка новых версий Hive, поддержка новых типов данных в Hive, поддержка партиционированных таблиц в Hive, поддержка новых форматов хранения данных;
- Быстрая разработка маппингов;
- И ещё один очень важный аргумент в пользу Informatica — это очень тесное сотрудничество и партнерство с лидером рынка дистрибутивов Hadoop, компанией Cloudera. Этот аргумент позволяет определить стратегический выбор в пользу этих двух платформ, если вы решили строить Data Lake.
Из недостатков можно выделить следующее:
- Один большой, но не столь весомый, но все же недостаток – не хватает всего того множества полезных фич, которые есть в старом PowerCenter. Это гибкая работа с переменными и параметрами как внутри маппинга, так и на этапе взаимодействия workflow->mapping-> workflow. Но, новая платформа Informatica развивается и с каждой новой версией становиться более удобной.
В целом инструмент Informatica BDE весьма хорошо показал себя при работе с Hadoop и у нас на него дальше очень большие планы в части ETL на Hadoop. Думаю, в скором времени напишем ещё более предметные статьи о реализации ETL на Hadoop на Informatica BDE.
Результаты
Основной результат, который мы получили на данным этапе — это стабильно работающий ETL, наполняющий DDS. Результат был получен за два месяца, командой из двух ETL разработчиков и архитектора. Сейчас мы ежедневно прогоняем через ETL на Hadoop ~100Gb текстовых логов и получаем в Data Vault примерно на порядок меньше данных, на основе которых собираются витрины данных. Загрузка в модель происходит на ночном регламенте, загружается дневной инкремент данных. Длительность загрузки составляет ~2 часа. С этими данными, выполняя Ad-hoc запросы, работают аналитики через Hue и IPython.
Планы на будущее
- Переход на CDH 5.4 (сейчас работаем на 5.2) и пилотирование Hive 0.14 и технологию Hive on Spark;
- Обновление Informatica 9.6.1 Hotfix2 до Hotfix3. И конечно ждем Informatica 10;
- Разработка маппингов, собирающих витрины для работы машинного обучения и data scientist-ов;
- Развитие ILM в Hadoop/HDFS.
