
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Для проверки Вы можете использовать следующую команду:
В результате выполнения команды получите следующее:
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg {1,2,3,4}. Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
В результате получим что то похожее на:
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Где,
Другие простые команды для проверки базового состояния выглядят следующим образом:
Пример результата:
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
Где,
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
# /usr/Adaptec_Event_Monitor/arcconf getconfig 1
Или (более поздняя версия):
Примерный результат на фото:
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
# lspci | egrep -i 'raid|adaptec'
В результате выполнения команды получите следующее:
81:00.0 RAID bus controller: Adaptec AAC-RAID (rev 09)
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
# smartctl --scan
В результате у Вас должно получится следующее:
/dev/sda -d scsi # /dev/sda, SCSI device
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg {1,2,3,4}. Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
# smartctl -d sat --all /dev/sgX
# smartctl -d sat --all /dev/sg1
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
# smartctl -d sat --all /dev/sg1 -H
Для SAS диск используют следующий синтаксис:
# smartctl -d scsi --all /dev/sgX
# smartctl -d scsi --all /dev/sg1
### Ask the device to report its SMART health status or pending TapeAlert message ###
# smartctl -d scsi --all /dev/sg1 -H
В результате получим что то похожее на:
smartctl version 5.38 [x86_64-redhat-linux-gnu] Copyright (C) 2002-8 Bruce Allen
Home page is http://smartmontools.sourceforge.net/
Device: SEAGATE ST3146855SS Version: 0002
Serial number: xxxxxxxxxxxxxxx
Device type: disk
Transport protocol: SAS
Local Time is: Wed Jul 7 04:34:30 2010 CDT
Device supports SMART and is Enabled
Temperature Warning Enabled
SMART Health Status: OK
Current Drive Temperature: 24 C
Drive Trip Temperature: 68 C
Elements in grown defect list: 0
Vendor (Seagate) cache information
Blocks sent to initiator = 1857385803
Blocks received from initiator = 1967221471
Blocks read from cache and sent to initiator = 804439119
Number of read and write commands whose size <= segment size = 312098925
Number of read and write commands whose size > segment size = 45998
Vendor (Seagate/Hitachi) factory information
number of hours powered up = 13224.42
number of minutes until next internal SMART test = 42
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 58984049 1 0 58984050 58984050 3151.730 0
write: 0 0 0 0 0 9921230881.600 0
verify: 1308 0 0 1308 1308 0.000 0
Non-medium error count: 0
No self-tests have been logged
Long (extended) Self Test duration: 1367 seconds [22.8 minutes]
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
# smartctl -d scsi --all /dev/sg2 -H
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
/dev/sg0 - RAID 10 контроллер.
/dev/sg1 - Первый диск в массиве RAID 10.
/dev/sg2 - Второй диск в массиве RAID 10.
/dev/sg3 - Третий диск в массиве RAID 10.
/dev/sg4 - Четвертый диск в массиве RAID 10.
Проверить жесткий диск можно с помощью следующих команд:
# smartctl -t short -d scsi /dev/sg2
# smartctl -t long -d scsi /dev/sg2
Где,
-t short : Запуск быстрого теста.
-t long : Запуск полного теста.
-d scsi : Указывает scsi, как тип устройства.
--all : Отображает всю SMART информацию для устройства.
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
# /usr/StorMan/arcconf getconfig 1 | more
# /usr/StorMan/arcconf getconfig 1 | grep State
# /usr/StorMan/arcconf getconfig 1 | grep -B 3 State
Пример результата:
Device #0
Device is a Hard drive
State : Online
--
S.M.A.R.T. : No
Device #1
Device is a Hard drive
State : Online
--
S.M.A.R.T. : No
Device #2
Device is a Hard drive
State : Online
--
S.M.A.R.T. : No
Device #3
Device is a Hard drive
State : Online
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
# /usr/Adaptec_Event_Monitor/arcconf getconfig [AD | LD [LD#] | PD | MC | [AL]] [nologs]
Где,
Prints controller configuration information.
Option AD : Информация исключительно о контроллере Adapter
LD : Информация исключительно о логических устройствах
LD# : Дополнительная информация об указанном логическом устройстве
PD : Информация исключительно о физическом устройстве
MC : Информация исключительно о Maxcache 3.0
AL : Вся информация
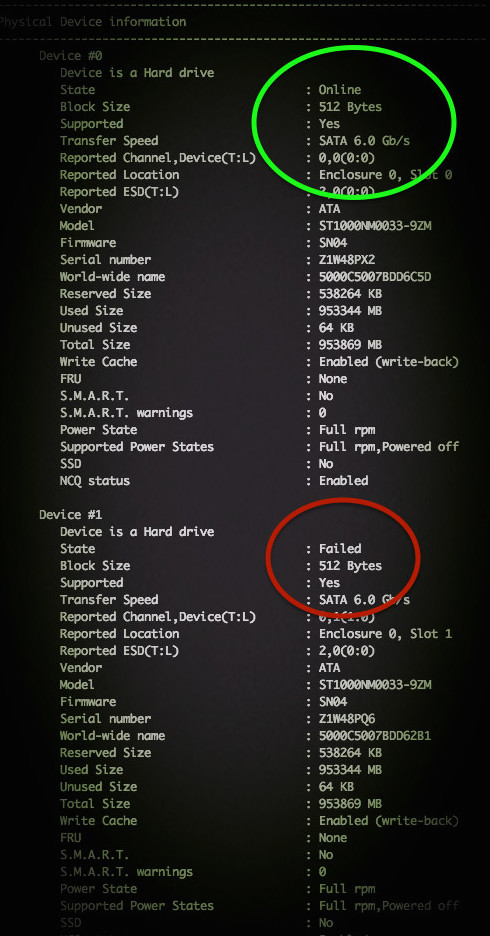
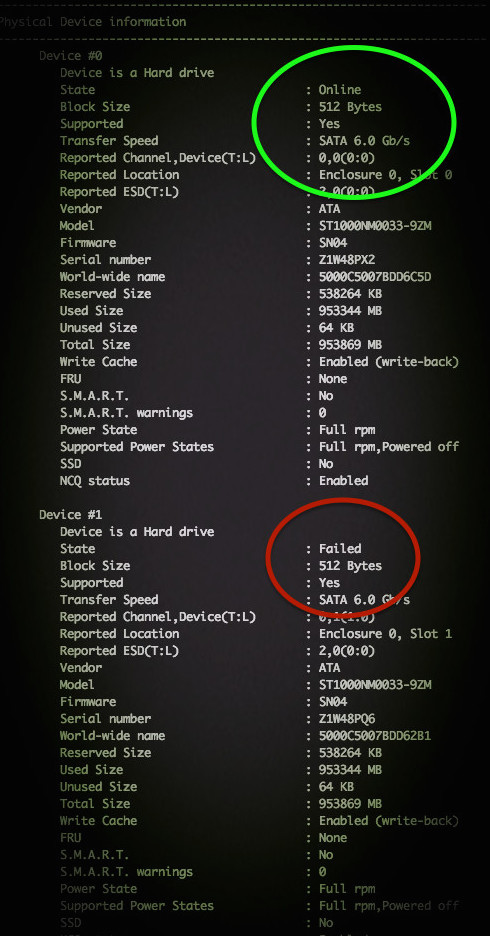
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
# /usr/Adaptec_Event_Monitor/arcconf getconfig 1
Или (более поздняя версия):
# /usr/StorMan/arcconf getconfig 1
Примерный результат на фото:
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
