
Приветствуем, уважаемое хабрасообщество! Сегодня мы продолжаем начатый в первой части рассказ о создании модификации XVM (eXtended Visualization Mod) для игры World of Tanks. Во второй части вас ждет описание истории развития серверной части мода.
Древнее царство
Как я уже говорил в первой части, самый первый бэкэнд мода работал на VPS, написан был на PHP и хранил базу игроков в виде файлов в файловой системе. Чтобы избежать лимита inode-ов 64K (лимит файлов в одном каталоге обычно настраивается, но на той VPS, похоже, настройка была залочена), применялась трехуровневая структура.
Первые две буквы ника игрока становились именем первой директории от корня БД. Следующие две буквы — именем вложенной в нее директории. И уже в ней-то и лежали plain-файлы с данными игроков и именами, равными никам.
Запросы выглядели так:
http://domain.com/users/<nickname>.На каждого игрока отправлялся свой запрос. То есть, из одного боя могло прийти до 30 запросов. Правда, на клиентской части применялось кеширование уже увиденных игроков, что слегка снижало нагрузку. Затем от этого кеширования отказались из-за крайне низкого процента попаданий в рандоме.
Несмотря на примитивность, у этой реализации было весомое преимущество — она работала даже на VPS и «тянула» сотню-другую запросов в секунду.
Надежда
После переезда на полноценный сервер была не менее оперативно запилена еще одна реализация, на сей раз на PHP + MySQL. Нам тогда вообще казалось, что для нашей задачи (запрос по одной записи по индексу), да еще запущенной на таком «мощном» железе (EQ4: Intel Core i7-920, 8 GB DDR3, 2x 750 GB SATA II HDD), можно использовать все антипаттерны проектирования — и оно все равно заработает. Реальность, как обычно, не подвела.
Итак, что же мы там «наколхозили»:
- Шаблон запроса, естественно, оставили как есть.
- Запрос проверялся регуляркой на похожесть на ник.
- Искали в БД этот ник.
- Если находили и он был обновлен не слишком давно, то отдавали его в ответе.
- Если не находили, либо запись была слишком старая, то начиналось самое интересное.
Надо было как-то получить данные игрока. На тот момент никаких публичных API не существовало, поэтому первое, что приходило в голову — парсить страницу вида worldoftanks.ru/community/accounts/27030462-Alex. Но есть одна проблема: в URL страницы, помимо ника, есть еще и ID, который мы из запроса получить не можем. Из-за этого, следующим пунктом колхоза у нас идет страница worldoftanks.ru/community/accounts, а точнее — форма поиска на этой странице. Отправляем из нашего приложения как бы AJAX–запрос, ушедший со страницы поиска игроков. В ответе получаем:
request_data: {
echo: 0
filtered_count: 210846
items: [
abbreviation: "",
account_url: "/community/accounts/27030462-Alex/",
battles: 3737,
clan_url: "",
exp: 636853,
id: 27030462,
name: "Alex",
wins: 1686
],
….
}
Видим, что у нас теперь есть не только id, но и готовая ссылка. Все, можно парсить.
К счастью, примерно тогда же появилось мобильное приложение World of Tanks Assistant, от Wargaming. Приложение вполне себе отображало статистику любого игрока. Добрые люди провели исследование и выяснили протокол обмена.
Данные грузились по адресу:
http://worldoftanks.ru/uc/accounts//api//?source_token=Intellect_Soft-WoT_Mobile-unofficial_stats
ApiVersion за время его использования нами и до появления официального API успел вырасти с 1.3 до 1.7. Каких-либо отличий для нас в них не было. Правда, проблема получения playerID прежде, чем делать запрос к API, никуда не делась.
И да, если кто еще не понял: запрос данных игрока происходил прямо во время обработки клиентского запроса.
Данный шедевр инженерной мысли стабильно работал под нагрузкой 200-300 запросов/секунду, что было лишь немногим больше, чем самый первый вариант, работавший на статических файлах. При повышении нагрузки мы упирались в CPU.
Эпоха возрождения
Поначалу моменты, когда сервер не справлялся, случались только по вечерам пятницы и субботы. Со временем эти «моменты» все увеличивались и увеличивались. Стало очевидно: что-то тут не так. Нагрузка у нас не рекордная, сервер не самый слабый. Проблема усугублялась тем, что опытных PHP-шников у нас не было. Как и не было опытных *nix специалистов.
Сели думать. Надумали следующее:
- Самое главное — мы занялись улучшением клиентской части, и нашли способ получать не только ники игроков, но и ID.
- Оптимизировать клиентские запросы, чтобы запрашивать игроков не по одному, а сразу всех из одного боя.
- Попробовать модную связку NodeJS + Mongo.
Был запилен первый вариант node-сервера. В нем не использовались никакие фреймворки. Только стандартные модули, типа http и mongo. Сервер представлял собой хардкорный процедурный код.
Запросы стали выглядеть так:
http://domain.com/users/<playerId1>,<playerId2>......<playerId30>
Первый же вариант показал обнадеживающие результаты — он тянул до 100-150 запросов/секунду. Новых запросов, на 30 игроков, т.е. это эквивалентно ~4000 старых запросов по одному игроку. Прирост более чем в 10 раз на смене технологии нас очень впечатлил, и, поскольку на тот момент запас прочности был очень солидным, — мы стали развивать «статистические» возможности XVM.
В очередной раз сели думать и надумали сделать что-то типа REST-сервиса со следующими методами:
- /001
/test — клиент при старте определяет с помощью этого метода, что сервер вообще жив. Кроме этого есть еще китайцы, которых, как известно много. Много настолько, что уже на этом этапе они создали у себя несколько серверов, используя наш код, а клиент отправлял запрос /test на каждый известный ему сервер и выбирал среди них лучший по времени отклика. Вариант /001 появился первым, так как требовал минимальной переделки клиента. Потом был оставлен для совместимости.
Ответ: {
id: 1,
status: "ok"
}
- /:ids — основной метод для выдачи статистики в бою.
:ids — это разделенный запятыми список конструкций вида playerId[=tankId], где tankId — это, как не сложно догадаться, id техники, на которой вышел в бой этот игрок. При отсутствии этого уточнения никакая статистика по технике не отдавалась — только общая.
Вывод метода повторяет описанный ниже метод /INFO с той лишь разницей, что секция v отфильтрована по текущему танку.
- /WN/:playerId — в клиенте не использовался, но использовался особо любопытными пользователями, так как выдавал некоторые хранящиеся в нашей базе метрики, используемые для расчета рейтингов (подробнее о различных рейтингах будет в третьей части статьи).
Ответ:WN
ID: 1015634
Nick: iBat
LVL: 7.4173503602768065
EFF: 78 | 1508
WN6: NaN |
GWR: 56.90
battles: 14017
wins: 7976
hit percent: 70
damage: 20594320 (1469)
frags: 18182 (1.3)
spotted: 17163 (1.2)
defence: 12444 (0.9)
capture: 24638 (1.8)
created: Wed Jan 19 2011 20:29:04 GMT+0400 (Russian Standard Time)
updated: Wed Jul 30 2014 18:20:03 GMT+0400 (Russian Standard Time)
cached: Thu Jul 31 2014 22:30:05 GMT+0400 (Russian Standard Time)
- /INFO/ID/:playerId
/INFO/:region/:playerName
/INFO/:playerName — группа методов для “ангарной” статистики. Несколько методов были нужны из-за специфики разных песочниц в клиенте. Где-то можно было вытащить ID игрока, а где-то только имя. С переходом на Python проблема отпала — в последних версиях сервера остался только запрос по ID.
Ответ:[{
"_id": 1015634,
"__v": 2,
"st": "ok",
"dt": "2014-07-31T18:30:05.761Z",
"ts": 1406831405761,
"cr": 1295454544,
"up": 1406730003,
"nm": "iBat",
"wgr": 8697,
"v": {
"1": {
"b": 20,
"w": 13,
"dmg": 13556,
"def": 0,
"frg": 35,
"spo": 38
},
"257": {
"b": 66,
"w": 38,
"dmg": 22804,
"def": 30,
"frg": 46,
"spo": 44
},
...
},
"rnd": {
"e": 1509,
"wn6": 1631
},
"lvl": 7.4173503602768065,
"b": 14017,
"w": 7976,
"spo": 17163,
"hip": 70,
"cap": 24638,
"dmg": 20594320,
"frg": 18182,
"def": 12444,
"e": 1508,
"wn6": 1630,
"wn8": 2155,
"cmp": {
"b": 50,
"w": 36,
"spo": 21,
"hip": 0,
"cap": 147,
"dmg": 44154,
"frg": 53,
"def": 112,
"e": 1393,
"wn6": 1394
}
}]
- /STAT
/STAT/queueLength
/STAT/monthUsers — группа методов, выдававшая некоторые серверные метрики, по которым мы с помощью cacti строили графики и мониторили состояние сервера. Скриншотов cacti у нас не сохранилось, поэтому прикладываю очень похожий мониторинг, который работает в данный момент.
Мониторинг: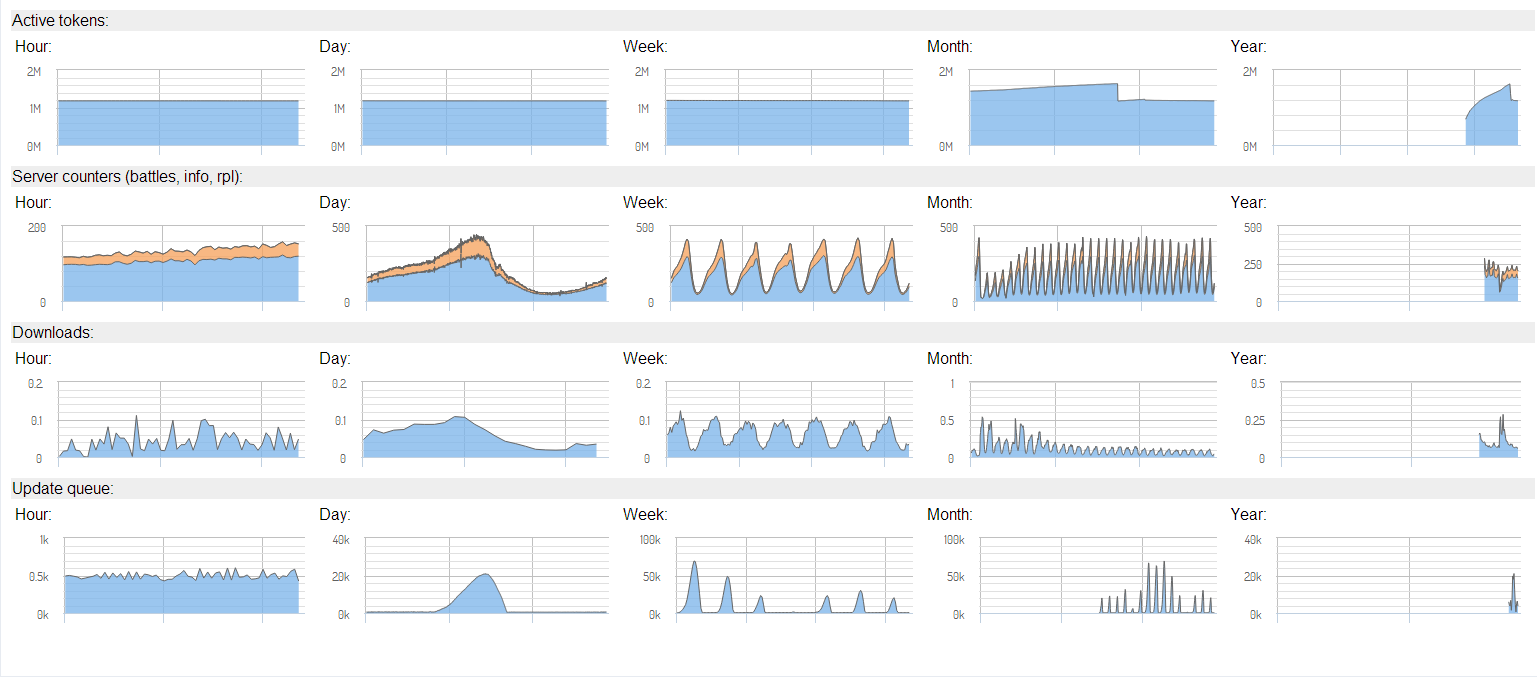
Вариант разработки серверной части под такое ТЗ в процедурном стиле вызывал нехорошие мысли, поэтому решили попробовать еще одну модную штуку: express.
Надо сказать, до этого у меня не было опыта работы с каким-либо MVC-фреймворком, но, несмотря на это, разобрался очень быстро, и буквально за два вечера сделал первый работающий вариант. В общем, в адрес разработчиков express говорю самые теплые слова за возможность быстрого старта.
Получившийся сервер, во-первых, неплохо работал, а во-вторых, его код радовал глаз в отличие от старого варианта.
На этой волне воодушевления я решил «гулять так гулять!» и добавил в проект ODM mongoose. Код стал еще красивее, пока гонял тесты на локальной машине, буквально нарадоваться не мог, что все красиво лежит на своем месте и как все просто и логично работает.
Пришла пора деплоить эту красоту на сервер. Задеплоил. Проверил — работает! Отошел минут на 20. Прихожу, проверяю — не работает. Смотрю в консоли — процесс node запущен. Перезапускаю. Несколько секунд работает, потом — глухо.
Не буду долго тянуть: проблема была в CPU. Под обычной на тот момент вечерней нагрузкой вариант кода без mongoose шутя эту нагрузку переваривал, а вариант с mongoose (несмотря на всю свою красоту) — нет. Пришлось с грустью откатывать почти все изменения нескольких дней.
Тучи сгущаются
В конце 2012 года случился очередной всплеск активности пользователей XVM, и наш замечательный сервер перестал справляться с нагрузкой. Если честно, проблемы были и раньше, но не такие серьезные. Теперь же вечерами мод скорее не работал, чем работал. В качестве крайней меры мы даже прикрутили к серверу модуль toobusy, который позволял обрабатывать столько запросов, сколько тянуло железо, и пропускать остальное. Мониторинг показывал острую нехватку памяти для процесса mongo. Решили переезжать на другой сервер: EX-4S (i7-2600, 32 GB DDR3, 2x3 TB SATA III HDD).
Переехали. Полегчало. Правда, ненадолго.

Как только случились зимние каникулы, проблема опять возникла. Ценой всякого шаманства над кодом удалось довести скорость запросов со 150 до 180-200 в секунду, но этого все равно было мало. В какой-то из вечеров, когда все почти лежало, я ради проверки закомментировал блок кода, отвечавший за обновление “просроченных” игроков с WG API и… оно заработало. И неплохо: получили стабильные 240 с пиками до 260 запросов/сек. Через несколько дней родился код, в котором апдейтер игроков был выделен в отдельный независимый процесс, а непосредственно код, взаимодействующий с клиентами, только складывал ID игроков, требующих обновления, в отдельную коллекцию.
Этого апгрейда нам хватило где-то на месяц. И в очередной раз увидели все те же проблемы: вечерами начинались пропуски клиентских запросов. На сей раз уперлись в IOPS. Не очень долго думая, в марте 2013-го заказали для нашего сервера дополнительное оборудование: SSD-диск на 240Гб. Линейки серверов с предустановленными SSD-дисками тогда еще не было.
Помогло! Сервер стал тянуть до 380-400 запросов/сек. Примерно полгода все работало довольно ровно и не вызывало особых нареканий у пользователей. В августе 2013-го мы переехали на свежепоявившийся EX40-SSD, поскольку для наших целей он подходил лучше, а стоил дешевле, чем EX-4S с дополнительным SSD.
А в конце 2013….. как вы уже догадались, нас постигла та же самая проблема. Причем на сей раз очевидных и простых путей решения было не видно. Последние колдунства над кодом сделаны. Сервер весьма неплох. q4x2, который *nix специалист, в свою очередь, “подкрутил” сервер "по самое немогу".
Содержимое /etc/sysctl.conf для интересующихся# Kernel sysctl configuration file for Red Hat Linux
#
# For binary values, 0 is disabled, 1 is enabled. See sysctl(8) and
# sysctl.conf(5) for more details.
# Controls IP packet forwarding
net.ipv4.ip_forward = 0
# Controls source route verification
net.ipv4.conf.default.rp_filter = 1
# Do not accept source routing
net.ipv4.conf.default.accept_source_route = 0
# Controls the System Request debugging functionality of the kernel
kernel.sysrq = 0
# Controls whether core dumps will append the PID to the core filename.
# Useful for debugging multi-threaded applications.
kernel.core_uses_pid = 1
# Controls the use of TCP syncookies
net.ipv4.tcp_syncookies = 1
# Controls the default maxmimum size of a mesage queue
kernel.msgmnb = 65536
# Controls the maximum size of a message, in bytes
kernel.msgmax = 65536
# Controls the maximum shared segment size, in bytes
kernel.shmmax = 68719476736
# Controls the maximum number of shared memory segments, in pages
kernel.shmall = 4294967296
net.core.somaxconn = 262144
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.core.netdev_max_backlog = 10000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_max_tw_buckets = 720000
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_keepalive_time = 1800
net.ipv4.tcp_keepalive_probes = 7
net.ipv4.tcp_keepalive_intvl = 30
net.core.wmem_max = 33554432
net.core.rmem_max = 33554432
net.core.rmem_default = 8388608
net.core.wmem_default = 4194394
net.ipv4.tcp_rmem = 4096 8388608 16777216
net.ipv4.tcp_wmem = 4096 4194394 16777216
net.ipv4.tcp_fin_timeout = 15
fs.epoll.max_user_watches = 1000000
fs.file-max = 5000000
net.core.netdev_max_backlog = 100000
net.core.optmem_max = 10000000
net.core.rmem_default = 10000000
net.core.rmem_max = 10000000
net.core.somaxconn = 1000000
net.core.wmem_default = 10000000
net.core.wmem_max = 10000000
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 12000
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_mem = 30000000 30000000 30000000
net.ipv4.tcp_rmem = 30000000 30000000 30000000
net.ipv4.tcp_wmem = 30000000 30000000 30000000
net.netfilter.nf_conntrack_max=1048576
В общем, все, что можно было сделать малой кровью, сделано. Уже начали подумывать о приобретении второго-третьего сервера и настраивать балансировку.
Но как-то вечером в разговоре с q4x2 у нас вышел спор о том, что не все платформы одинаково полезны. А если проще, то он меня убеждал, что все наши беды из-за NodeJS, и что он готов сделать свой вариант сервера на Java, который “порвет” Node на британский флаг. Я в этом сильно сомневался, но согласился поучаствовать в эксперименте, и, раз уж такое дело, решил попробовать чего-нибудь нативного.
Поскольку, по своему обыкновению, захотелось чего-то нового, то выбор пал на D и фреймворк vibed. Удивительно, но даже мне, последние года три занимавшемуся почти исключительно JS, удалось относительно быстро состряпать работающий вариант. Разрабатывал я его под Windows. А вот при разворачивании под Centos 6.5 у нас возникли очень большие сложности с удовлетворением зависимостей. Линкеру приходилось вручную прописывать очевидные вещи.
Сложности до конца побороть не удалось, поэтому эксперимент с D был досрочно свернут. Сам язык нам очень понравился, но пока что у него, увы, проблемы с инструментарием.
Пока мы все-это писали, сервер вечерами не справлялся: не хватало CPU. И мы решились на еще один переезд, на сей раз на PX90-SSD (Xeon E5-1650 v2, 64 GB ECC DDR3, 2 x 240 GB SSD).
Рассвет новой эры
Не успел Node-сервер обрадоваться двум новым ядрам, как q4x2 выкатил свой Java-сервер. Код мне напомнил самый первый вариант Node-сервера: все в одном файле в процедурном стиле. Код мы постепенно привели к божескому виду, но все равно было видно (после избавления от детских болячек), насколько этот вариант быстрее Node. В цифрах загрузки CPU — примерно в четыре раза. В часы пик, при ~500 запросах/сек основным java-процессом используется одно ядро. Для Node-версии на четырехядернике такая нагрузка была недостижимой, а на шестиядернике она была очень близка к предельной.
Как раз в это время мы решили вводить активацию статистики на нашем сайте. Это означало, что полученные клиентами токены доступа будут ходить по сети при каждом запросе. Чтобы немного их обезопасить, сервер был размещен за HTTPS. И тут нас ждал очередной сюрприз.
Чуть выше я упомянул про детские болячки java-кода. А пока мы их пару недель лечили, java-код работал не намного лучше старого, и было очень похоже на то, что шестиголовый сервер не потянет проксю + https.
Чтобы не ждать чуда, был немедленно приобретен еще один сервер: EX40 (i7-4770, 32 GB DDR3, 2 x 2 TB HDD) с целью быть фронтендом и тянуть https. Немцы сервер сделали, но с одной маленькой, как потом выяснилось, проблемкой: ему присвоили IP в диапазоне 5.x.x.x. Фронтенд мы на нем сделали, и все замечательно работало, но на форуме начали копиться жалобы от людей, у которых ничего не работало.
Немного исследовав этот вопрос, мы выяснили, что проблема с 5.x.x.x — известная штука, связана она с приложением под названием Hamachi. Причем новые версии Hamachi переехали на 25.x.x.x (интересно, эти ребята принципиально не хотят использовать приватные сети для своих целей?), но нам от этого было не легче. Пришлось переезжать обратно на основной сервер, благо к тому моменту он уже мог тянуть все наше хозяйство единолично, да еще с солидным запасом.
Итого на данный момент у нас весь бэкэнд: наш код + БД работает на одном сервере. Load averages редко превышают единицу. Но сейчас мы задумали еще одну реорганизацию серверного хозяйства с переносом БД на отдельный сервер. Одна из причин: у Mongo очень тяжело с холодным стартом — после перезагрузки она не тянет и половины той нагрузки, которую тянет после прогрева (из-за этого, кстати, были проблемы 3-4 августа). Перенос на отдельный сервер позволит не трогать его. Другая причина — у нас появились некоторые идеи по развитию мода, которые потребуют значительного увеличения размера БД. Текущих 2*240Гб может не хватить. В целом, можно сказать, что проблема бэкэнда на нашей стороне решена. Осталась другая.
Борьба с Wargaming API
Второй по остроте проблемой после работоспособности самого сервера у нас всегда были обновления статистики игроков. По понятной причине, все наши пользователи так или иначе обращают внимание на игровую статистику, и большинство из них хотят видеть обновления этой статистики настолько часто, насколько это вообще возможно (в идеале — в реальном времени). А на пути к решению этой задачи у нас всегда стоял WG API. Точнее — его ограничения.
Самая главная для нас проблема — лимит на число запросов с одного IP. Во времена, когда публичного API еще не было, лимит с одного IP составлял около 10 запросов/сек. Нам этого было, мягко говоря, маловато. Поэтому выкручивались как могли: у нас было несколько прокси-серверов, через которые слались запросы к API.
С появлением API стало немного легче в плане доступного лимита. Нашему приложению присвоили премиум-статус, что в теории дает нам право делать по 50 запросов/сек. А дальше начинаются НО:
- В старой версии (не публичный API, данные для мобильного приложения) все нужные нам данные по каждому игроку были собраны в одном методе. А с появлением публичного API данные были перераспределены по разным методам, и нам пришлось делать на каждого игрока по два запроса (/account/info/, /account/tanks/).
- Эти методы поддерживают запрос сразу по нескольким игрокам (до 100). То есть, в теории мы бы могли запрашивать до 5000 игроков/сек. Но в реальности запрос к /account/tanks/ на 100 игроков занимал ~45 секунд, а если их отправлять слишком часто, то они начинают массово отваливаться.
Методом проб и ошибок был найден рецепт относительно стабильной работы: запрос на 20 игроков раз в 2 секунды. Да, это нас отбросило обратно на 10 игроков/сек. В связи с недостаточностью этой величины периоды обновления были дифференцированы для пользователей нашего мода и для всех остальных.
Пользователей обновляем в 3-4 раза чаще. Например, сейчас пользователи попадают в очередь на обновление через 3, а остальные — через 11 суток после предыдущего обновления.
- Через некоторое время WG выкатил новый метод - /tanks/stats/. Метод выдавал гораздо более детальную статистику по танкам игрока по сравнению с /account/tanks/, и нам, естественно, захотелось ее получить. Но! Этот метод не поддерживает запрос по списку игроков. Только по одному. И это было еще не самое плохое: хуже, что этот метод для некоторых игроков выдавал несуществующие у него танки.
Вот пример, отправленный в техподдержку WG, в котором видно расхождение в показаниях двух методов почти в два раза. Немного поисследовав, выяснили, что показания по реально существующим у игрока танкам — правильные. Неправильны только показания по танкам, которых нет. Для нас это означает, что теперь приходится делать по три запроса на каждый аккаунт: /account/info/, /account/tanks/, /tanks/stats/. Причем /account/tanks/ нужен только для того, чтобы получить актуальный список танков, и откинуть из результатов /tanks/stats/ лишние.
Все это привело к тому, что сейчас скорость обновления снизилась до 8 аккаунтов/сек. Надеемся, что когда-нибудь мы сможем делать по сотне/сек, и сбудется мечта многих пользователей если не о реальном времени, то хотя бы о ежедневных обновлениях.
- Были и еще мелкие косячки: к примеру, после разделения немецкого танка PzIV на модификации Pz_IV_AusfD, Pz_IV_AusfH и Pz_IV_AusfA естественно изменились ID этих танков. Но еще долго API выдавал для некоторых аккаунтов старый ID=17, соответствующий неразделенному PzIV. А метод /encyclopedia/tanks/, из которого мы узнаем уровень и тип танка, этот ID уже не содержал, что иногда приводило к забавным результатам при подсчете рейтингов.
К счастью, сейчас появилась возможность отправлять багрепорты на такие чудеса. Раньше единственным ответом было: вам запрещено пользоваться чужим идентификатором приложения (?source_token=Intellect_Soft-WoT_Mobile-unofficial_stats). То есть, медленно, но верно начались изменения к лучшему. Нас стали воспринимать серьезно. Так что ждем, надеемся и верим!
На этом вторая часть повествования завершается. Впереди будет еще одна часть, которая расскажет о самом интересном - развитии клиентской части модификации.

