Сегодня я расскажу вам о небольшой части большого проекта — World of Tanks. Многие из вас, наверное, знают World of Tanks со стороны пользователя, я же предлагаю взглянуть на него с точки зрения разработчика. В этой статье речь пойдет об эволюции одного из технических решений проекта, а именно — передаче и обработке результатов боя.

Для понимания сути рассматриваемой проблемы сначала опишу, как устроены «Танки». Проект представляет собой распределенное клиент-серверное приложение, которое на стороне сервера представлено несколькими разнотипными узлами. Вся физика и внутриигровая логика обсчитываются на сервере, а клиент отвечает за взаимодействие с пользователем — обработку пользовательского ввода и отображение результатов. Упрощенная схема кластера выглядит так:

За взаимодействие с клиентом отвечают BaseApp-узлы. Они принимают информацию от пользователя по сети и передают её внутрь кластера, а также отсылают пользователю информацию о событиях, произошедших внутри кластера. Все физические взаимодействия, происходящие на арене, просчитываются на CellApp-узлах. Там же собирается информация о событиях, произошедших с танком за время боя: количество выстрелов, попаданий, пробитий и т. д. Один бой может обслуживаться несколькими CellApp-ами, на каждом из которых могут обсчитываться несколько пользователей из разных боев. По окончании боя пакеты статистики по всем танкам отсылаются из CellApp-ов на BaseApp. Он агрегирует пакеты и обрабатывает результаты боя: высчитывает штрафы и награды, проверяет выполнение квестов и выдает медальки, т. е. формирует другие пакеты данных, которые отправляет пользователям. Важно отметить, что CellApp-ы и BaseApp-ы представляют собой изолированные процессы. Некоторые из них могут располагаться на других машинах, но в пределах одного кластера. Так что передача данных между ними происходит через сетевые интерфейсы, а между клиентом и кластером — через интернет.
Для передачи пакетов данных используется протокол с гарантированной доставкой, реализованный поверх UDP. Под капотом, за весь I\O и гарантированную доставку поверх UDP, отвечает библиотека Mercury, которая является частью платформы BigWorld Technology. Фактически мы можем повлиять на данные только перед отправкой – подготовить их таким образом, чтобы оптимизировать затраты на отправку/получение.
По понятным причинам, мы хотим сократить объем передаваемых между узлами данных до минимума: это уменьшит всплески трафика, задержку на прием-передачу и значительно сократит объем данных, передаваемых клиенту с информацией о результатах боя. На предварительную обработку данных отводится один тик равный 100 мс, в течение которого также могут обрабатываться и другие события. Поэтому предварительная обработка должна занимать как можно меньше времени. В идеале, она не должна отнимать время вообще.
Давайте взглянем на процесс подготовки данных.
Большая часть внутриигровой логики World of Tanks написана на Python. Данные, пересылаемые между CellApp и BaseApp, а также данные, отправляемые пользователю по окончании боя, представляют собой dict с разнообразными значениями от простых (вроде целого/дробного числа или значения True/False), до составных — словарей и последовательностей. Ни code-object, ни классы, ни экземпляры пользовательских классов никогда не передаются от одного узла другому. Это связано с требованиями безопасности и производительности.
Для того чтобы было удобнее рассматривать дальнейший материал, приведем пример данных, с которыми мы будем работать далее:
Для непосредственной передачи данных между узлами, экземпляр dict необходимо преобразовать в бинарный пакет данных минимального размера. При совершении удаленного вызова движок BigWorld предоставляет возможность прозрачной для программиста конвертации Python-объектов в бинарные данные и обратно с помощью модуля cPikcle.
Пока объем передаваемых данных был небольшим, они перед отправкой просто конвертировались в бинарный формат при помощи модуля cPickle (назовем этот протокол обмена версией 0). Именно в таком виде вышла первая закрытая бета-версия танков 0.1 в далеком 2010 году.
К достоинствам этого метода стоит отнести простоту и достаточную эффективность как в плане быстродействия, так и компактности итогового бинарного представления.
Недостатки следуют из достоинств, в частности, простоты этого метода: строковые ключи из словаря тоже передаются между узлами кластера и от кластера пользователю. В некоторых случаях эти строковые ключи могут занимать значительную часть передаваемого бинарного пакета.
Шло время, значительно выросли объемы данных и одновременный онлайн, а, следовательно, выросло и количество одновременно завершаемых боев и объем информации передаваемой по окончании боя. Для сокращения трафика мы выкинули строковые ключи из пересылаемых данных и заменили индексами в list. Такая операция не привела к потере данных: зная порядок ключей, восстановить исходный dict легко.
Для проведения операций удаления и восстановления ключей был необходим шаблон, в котором хранились бы все возможные ключи и соответствующие функции:
Как видно из примера, бинарное представление стало более компактным по сравнению с версией 0. Но за компактность мы расплатились временем, затраченым на предварительную обработку данных и добавлением нового кода, который нужно поддерживать.
Это решение вышло в версии 0.9.5, в самом начале 2015 года. Протокол с преобразованием dict в list, последующим pickle.dumps(data, -1) назовем версией 1.
С выходом нового режима «Превосходство», объем данных вырос значительно, так как они собираются для каждого танка отдельно, а в этом режиме пользователь может выйти в бой и генерировать данные аж на трех машинах. Поэтому достаточно остро встала необходимость утрамбовать данные еще плотнее.
Для того чтобы передавать еще меньше избыточной информации, мы применили следующие приемы:
1. Для каждого вложенного словаря мы применили такой же подход, как и к главному словарю, — выкинули ключи и преобразовали dict в list. Таким образом, «шаблон», по которому данные преобразуются из dict в list и обратно, стал рекурсивным.
2. Внимательно присмотревшись к данным перед отправкой, мы заметили, что в некоторых случаях последовательность заключена в контейнер типа set или frozenset. Бинарное представление этих контейнеров в протоколе cPickle версии 2 занимает гораздо больше места:
Мы сэкономили еще несколько байтов, преобразовав set и frozenset в list перед отправкой. Так как приемной стороне обычно неинтересен конкретный тип последовательности, а важны только данные, такая замена не привела к ошибкам.
3. Довольно часто не для всех ключей в словаре заданы значения. Некоторые из них могут отсутствовать, а другие — не отличаться от значений по умолчанию, которые известны заранее и на передающей, и на принимающей стороне. Также нужно помнить, что значения «по умолчанию» для данных разных типов имеют разное бинарное представление. Достаточно редко, но все же встречаются значения по умолчанию, чуть более сложные, чем просто пустое значение определенного типа. В нашем случае это несколько счетчиков объединенных в одно поле, представленное в виде последовательностей из нулей. В этих случаях значения по умолчанию могут занимать много места в бинарных данных, пересылаемых между узлами. Для того чтобы добиться еще большей экономии, перед отправкой мы заменяем значения по умолчанию на None. В результате во всех случаях бинарное представление станет более компактным или не изменится в длине.
Рассматривая примеры, стоит учесть, что cPickle добавляет в бинарный пакет заголовок и терминатор, общий объем которых составляет 3 байта, а реальный объем сериализированных данных равен
Более того, замена значений по умолчанию приносит выгоду и при сжатии бинарных данных zlib-ом. В бинарном представлении list-элементы идут друг за другом без всяких разделителей. Несколько значений по умолчанию подряд, замененных на None, будут представлены в виде последовательности из одинаковых байтов, которые могут быть хорошо заархивированы.
4. Данные архивируются zlib-ом с уровнем компрессии равным 1, т. к. этот уровень позволяет достичь оптимального соотношения степени архивации ко времени работы.
Если свести воедино шаги 1–3, то получится примерно так:
В итоге все эти приемы были применены в протоколе версии 2, который вышел в версии 0.9.8, в мае 2015 года.
Да, мы еще больше увеличили время, затрачиваемое на предварительную подготовку, но зато и объем бинарного пакета сократился значительно.
Для того чтобы можно было посмотреть, к чему привело применение вышеописанных приемов на реальных данных, приведем график зависимости размера пакета данных об одном танке, передаваемых с CellApp на BaseApp по окончании боя, в различных версиях от версии.

Напомним, что в режиме «Превосходство» версии 0.9.8, игрок может выйти в бой на трех танках и соответственно суммарный объем данных возрастет троекратно.
И время, затрачиваемое на обработку тех же данных перед отправкой.
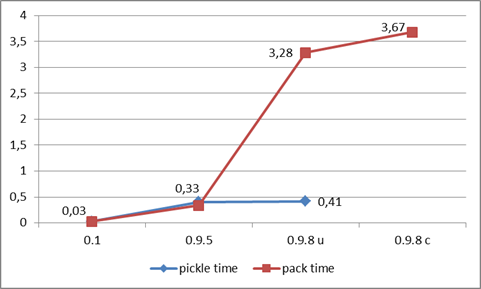
Где 0.9.8u — обработка без сжатия zlib-ом (uncomressed), а 0.9.8c — с применением сжатия (compressed). Время указано в секундах на 10000 итераций.
Замечу, что данные были собраны для версии 0.9.8 и потом аппроксимированы для 0.9.5 и 0.1 с учетом используемых ключей. Более того, для каждого пользователя и танка данные будут значительно разниться, так как объем данных напрямую зависит от поведения игрока (сколько противников было обнаружено, повреждено и т. д.). Так что к приведенным графикам стоит относиться скорее как к иллюстрации тенденции.
В нашем случае критически важным было уменьшить объем передаваемых данных между узлами. Также желательно было сократить время предварительной обработки. Поэтому протокол второй версии стал для нас оптимальным решением. Следующим логичным шагом является вынесение функциональности сериализации в отдельный бинарный модуль, который будет производить все манипуляции самостоятельно, и не будет хранить информацию, описывающую данные в бинарном потоке, как pickle. Это позволит ужать объем данных еще больше, и, возможно, уменьшит время на обработку. Но пока мы работаем с решением, описанным выше.

Под капотом
Для понимания сути рассматриваемой проблемы сначала опишу, как устроены «Танки». Проект представляет собой распределенное клиент-серверное приложение, которое на стороне сервера представлено несколькими разнотипными узлами. Вся физика и внутриигровая логика обсчитываются на сервере, а клиент отвечает за взаимодействие с пользователем — обработку пользовательского ввода и отображение результатов. Упрощенная схема кластера выглядит так:

За взаимодействие с клиентом отвечают BaseApp-узлы. Они принимают информацию от пользователя по сети и передают её внутрь кластера, а также отсылают пользователю информацию о событиях, произошедших внутри кластера. Все физические взаимодействия, происходящие на арене, просчитываются на CellApp-узлах. Там же собирается информация о событиях, произошедших с танком за время боя: количество выстрелов, попаданий, пробитий и т. д. Один бой может обслуживаться несколькими CellApp-ами, на каждом из которых могут обсчитываться несколько пользователей из разных боев. По окончании боя пакеты статистики по всем танкам отсылаются из CellApp-ов на BaseApp. Он агрегирует пакеты и обрабатывает результаты боя: высчитывает штрафы и награды, проверяет выполнение квестов и выдает медальки, т. е. формирует другие пакеты данных, которые отправляет пользователям. Важно отметить, что CellApp-ы и BaseApp-ы представляют собой изолированные процессы. Некоторые из них могут располагаться на других машинах, но в пределах одного кластера. Так что передача данных между ними происходит через сетевые интерфейсы, а между клиентом и кластером — через интернет.
Для передачи пакетов данных используется протокол с гарантированной доставкой, реализованный поверх UDP. Под капотом, за весь I\O и гарантированную доставку поверх UDP, отвечает библиотека Mercury, которая является частью платформы BigWorld Technology. Фактически мы можем повлиять на данные только перед отправкой – подготовить их таким образом, чтобы оптимизировать затраты на отправку/получение.
По понятным причинам, мы хотим сократить объем передаваемых между узлами данных до минимума: это уменьшит всплески трафика, задержку на прием-передачу и значительно сократит объем данных, передаваемых клиенту с информацией о результатах боя. На предварительную обработку данных отводится один тик равный 100 мс, в течение которого также могут обрабатываться и другие события. Поэтому предварительная обработка должна занимать как можно меньше времени. В идеале, она не должна отнимать время вообще.
Начало
Давайте взглянем на процесс подготовки данных.
Большая часть внутриигровой логики World of Tanks написана на Python. Данные, пересылаемые между CellApp и BaseApp, а также данные, отправляемые пользователю по окончании боя, представляют собой dict с разнообразными значениями от простых (вроде целого/дробного числа или значения True/False), до составных — словарей и последовательностей. Ни code-object, ни классы, ни экземпляры пользовательских классов никогда не передаются от одного узла другому. Это связано с требованиями безопасности и производительности.
Для того чтобы было удобнее рассматривать дальнейший материал, приведем пример данных, с которыми мы будем работать далее:
data = {
"someIntegerValue" : 1,
"someBoolValue" : True,
"someListOfIntsValue" : [1, 2, 3],
"someFloatValue" : 0.5,
"someDictionaryValue" : {
"innerVal" : 1,
"innerVal2" : 2,
"listOfVals" : [1, 2, 3, 4],
},
"2dArray" : [
[1, 2, 3, 4, 5, 6],
[7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24]
]
}
Для непосредственной передачи данных между узлами, экземпляр dict необходимо преобразовать в бинарный пакет данных минимального размера. При совершении удаленного вызова движок BigWorld предоставляет возможность прозрачной для программиста конвертации Python-объектов в бинарные данные и обратно с помощью модуля cPikcle.
Пока объем передаваемых данных был небольшим, они перед отправкой просто конвертировались в бинарный формат при помощи модуля cPickle (назовем этот протокол обмена версией 0). Именно в таком виде вышла первая закрытая бета-версия танков 0.1 в далеком 2010 году.
К достоинствам этого метода стоит отнести простоту и достаточную эффективность как в плане быстродействия, так и компактности итогового бинарного представления.
>>> p = cPickle.dumps(data, -1)
>>> len(p)
277
Недостатки следуют из достоинств, в частности, простоты этого метода: строковые ключи из словаря тоже передаются между узлами кластера и от кластера пользователю. В некоторых случаях эти строковые ключи могут занимать значительную часть передаваемого бинарного пакета.
Оптимизируем
Шло время, значительно выросли объемы данных и одновременный онлайн, а, следовательно, выросло и количество одновременно завершаемых боев и объем информации передаваемой по окончании боя. Для сокращения трафика мы выкинули строковые ключи из пересылаемых данных и заменили индексами в list. Такая операция не привела к потере данных: зная порядок ключей, восстановить исходный dict легко.
Для проведения операций удаления и восстановления ключей был необходим шаблон, в котором хранились бы все возможные ключи и соответствующие функции:
NAMES = (
"2dArray",
"someListOfIntsValue",
"someDictionaryValue",
"someFloatValue",
"someIntegerValue",
"someBoolValue",
)
INDICES = {x[1] : x[0] for x in enumerate(NAMES)}
def dictToList(indices, d):
l = [None, ] * len(indices)
for name, index in indices.iteritems():
l[index] = d[name]
return l
def listToDict(names, l):
d = {}
for x in enumerate(names):
d[x[1]] = l[x[0]]
return d
>>> dictToList(INDICES, data)
[[[1, 2, 3, 4, 5, 6], [7, 8, 9, 10, 11, 12], [13, 14, 15, 16, 17, 18], [19, 20, 21, 22, 23, 24]], [1, 2, 3], {'listOfVals': [1, 2, 3, 4], 'innerVal2': 2, 'innerVal': 1}, 0.5, 1, True]
>>>
>>> len(cPickle.dumps(dictToList(INDICES, data), -1)
165
Как видно из примера, бинарное представление стало более компактным по сравнению с версией 0. Но за компактность мы расплатились временем, затраченым на предварительную обработку данных и добавлением нового кода, который нужно поддерживать.
Это решение вышло в версии 0.9.5, в самом начале 2015 года. Протокол с преобразованием dict в list, последующим pickle.dumps(data, -1) назовем версией 1.
Оптимизируем дальше
С выходом нового режима «Превосходство», объем данных вырос значительно, так как они собираются для каждого танка отдельно, а в этом режиме пользователь может выйти в бой и генерировать данные аж на трех машинах. Поэтому достаточно остро встала необходимость утрамбовать данные еще плотнее.
Для того чтобы передавать еще меньше избыточной информации, мы применили следующие приемы:
1. Для каждого вложенного словаря мы применили такой же подход, как и к главному словарю, — выкинули ключи и преобразовали dict в list. Таким образом, «шаблон», по которому данные преобразуются из dict в list и обратно, стал рекурсивным.
2. Внимательно присмотревшись к данным перед отправкой, мы заметили, что в некоторых случаях последовательность заключена в контейнер типа set или frozenset. Бинарное представление этих контейнеров в протоколе cPickle версии 2 занимает гораздо больше места:
>>> l = list(xrange(3))
>>> cPickle.dumps(set(l), -1)
'\x80\x02c__builtin__\nset\nq\x01]q\x02(K\x00K\x01K\x02e\x85Rq\x03.'
>>>
>>> cPickle.dumps(frozenset(l), -1)
'\x80\x02c__builtin__\nfrozenset\nq\x01]q\x02(K\x00K\x01K\x02e\x85Rq\x03.'
>>>
>>> cPickle.dumps(l, -1)
'\x80\x02]q\x01(K\x00K\x01K\x02e.'
Мы сэкономили еще несколько байтов, преобразовав set и frozenset в list перед отправкой. Так как приемной стороне обычно неинтересен конкретный тип последовательности, а важны только данные, такая замена не привела к ошибкам.
3. Довольно часто не для всех ключей в словаре заданы значения. Некоторые из них могут отсутствовать, а другие — не отличаться от значений по умолчанию, которые известны заранее и на передающей, и на принимающей стороне. Также нужно помнить, что значения «по умолчанию» для данных разных типов имеют разное бинарное представление. Достаточно редко, но все же встречаются значения по умолчанию, чуть более сложные, чем просто пустое значение определенного типа. В нашем случае это несколько счетчиков объединенных в одно поле, представленное в виде последовательностей из нулей. В этих случаях значения по умолчанию могут занимать много места в бинарных данных, пересылаемых между узлами. Для того чтобы добиться еще большей экономии, перед отправкой мы заменяем значения по умолчанию на None. В результате во всех случаях бинарное представление станет более компактным или не изменится в длине.
>>> len(cPickle.dumps(None, -1))
4
>>> len(cPickle.dumps((), -1))
4
>>> len(cPickle.dumps([], -1))
4
>>> len(cPickle.dumps({}, -1))
4
>>> len(cPickle.dumps(False, -1))
4
>>> len(cPickle.dumps(0, -1))
5
>>> len(cPickle.dumps(0.0, -1))
12
>>> len(cPickle.dumps([0, 0, 0], -1))
14
Рассматривая примеры, стоит учесть, что cPickle добавляет в бинарный пакет заголовок и терминатор, общий объем которых составляет 3 байта, а реальный объем сериализированных данных равен
(X - 3), где X — значение из примера.Более того, замена значений по умолчанию приносит выгоду и при сжатии бинарных данных zlib-ом. В бинарном представлении list-элементы идут друг за другом без всяких разделителей. Несколько значений по умолчанию подряд, замененных на None, будут представлены в виде последовательности из одинаковых байтов, которые могут быть хорошо заархивированы.
4. Данные архивируются zlib-ом с уровнем компрессии равным 1, т. к. этот уровень позволяет достичь оптимального соотношения степени архивации ко времени работы.
Если свести воедино шаги 1–3, то получится примерно так:
class DictPacker(object):
def __init__(self, *metaData):
self._metaData = tuple(metaData)
# Packs input dataDict into a list.
def pack(self, dataDict):
metaData = self._metaData
l = [None] * len(metaData)
for index, metaEntry in enumerate(metaData):
try:
name, transportType, default, packer = metaEntry
default = copy.deepcopy(default) # prevents modification of default.
v = dataDict.get(name, default)
if v is None:
pass
elif v == default:
v = None
elif packer is not None:
v = packer.pack(v)
elif transportType is not None and type(v) is not transportType:
v = transportType(v)
if v == default:
v = None
l[index] = v
except Exception as e:
LOG_DEBUG_DEV("error while packing:", index, metaEntry, str(e))
return l
# Unpacks input dataList into a dict.
def unpack(self, dataList):
ret = {}
for index, meta in enumerate(self._metaData):
val = dataList[index]
name, _, default, packer = meta
default = copy.deepcopy(default) # prevents modification of default.
if val is None:
val = default
elif packer is not None:
val = packer.unpack(val)
ret[name] = val
return ret
PACKER = DictPacker(
("2dArray", list, 0, None),
("someListOfIntsValue", list, [], None),
("someDictionaryValue", dict, {},
DictPacker(
("innerVal", int, 0, None),
("innerVal2", int, 0, None),
("listOfVals", list, [], None),
)
),
("someFloatValue", float, 0.0, None),
("someIntegerValue", int, 0, None),
("someBoolValue", bool, False, None),
)
>>> PACKER.pack(data)
[[[1, 2, 3, 4, 5, 6], [7, 8, 9, 10, 11, 12], [13, 14, 15, 16, 17, 18], [19, 20, 21, 22, 23, 24]], [1, 2, 3], [1, 2, [1, 2, 3, 4]], 0.5, 1, True]
>>> len(cPickle.dumps(PACKER.pack(data), -1))
126
В итоге все эти приемы были применены в протоколе версии 2, который вышел в версии 0.9.8, в мае 2015 года.
Да, мы еще больше увеличили время, затрачиваемое на предварительную подготовку, но зато и объем бинарного пакета сократился значительно.
Сравнение результатов
Для того чтобы можно было посмотреть, к чему привело применение вышеописанных приемов на реальных данных, приведем график зависимости размера пакета данных об одном танке, передаваемых с CellApp на BaseApp по окончании боя, в различных версиях от версии.

Напомним, что в режиме «Превосходство» версии 0.9.8, игрок может выйти в бой на трех танках и соответственно суммарный объем данных возрастет троекратно.
И время, затрачиваемое на обработку тех же данных перед отправкой.

Где 0.9.8u — обработка без сжатия zlib-ом (uncomressed), а 0.9.8c — с применением сжатия (compressed). Время указано в секундах на 10000 итераций.
Замечу, что данные были собраны для версии 0.9.8 и потом аппроксимированы для 0.9.5 и 0.1 с учетом используемых ключей. Более того, для каждого пользователя и танка данные будут значительно разниться, так как объем данных напрямую зависит от поведения игрока (сколько противников было обнаружено, повреждено и т. д.). Так что к приведенным графикам стоит относиться скорее как к иллюстрации тенденции.
Заключение
В нашем случае критически важным было уменьшить объем передаваемых данных между узлами. Также желательно было сократить время предварительной обработки. Поэтому протокол второй версии стал для нас оптимальным решением. Следующим логичным шагом является вынесение функциональности сериализации в отдельный бинарный модуль, который будет производить все манипуляции самостоятельно, и не будет хранить информацию, описывающую данные в бинарном потоке, как pickle. Это позволит ужать объем данных еще больше, и, возможно, уменьшит время на обработку. Но пока мы работаем с решением, описанным выше.
