При работе над облачными сервисами Webzilla мы уделяем очень большое внимание системе мониторинга. Мы уверены, что только имея корректно работающий и надежный мониторинг, мы можем оказывать сервис на требуемом клиентами уровне качества. Во время работы над первым из облачных продуктов компании – облачным хранилищем Webzilla Instant Files – мы приступили к построению системы мониторинга еще до того, как начали строить сам продукт, продумали мониторинг для каждой функции еще на этапе её планирования.
Наша система мониторинга преследует несколько целей:
Мы работали над системой мониторинга не меньше времени, чем над функциональной частью сервиса — и мы делимся наработанным опытом.
В целом, наша система мониторинга состоит из трех основных подсистем:
Обычно, когда говорят «мониторинг», под этим словом понимают событийный мониторинг (
В простейшем случае — если выключился сервер (скажем, из-за отключения питания) — эти данные имеют простую форму: доступно на 1 сервер меньше, чем мы ожидали. Если же ситуация более сложная: например, по каким-то причинам приложение постепенно деградировало и стало медленнее отвечать на запросы, измерения могут показать, например, что «95-й перцентиль времени ответа удвоился за последнюю неделю». При этом, какого-то конкретного момента времени, когда система «сломалась» не существует. Лягушка не может назвать точный момент времени, когда вокруг нее образовался кипяток.
Иными словами, привычные события переформулировать на языке данных чаще всего нетрудно, но данные имеют и самостоятельную дополнительную ценность. Мы решили строить мониторинг с ориентацией на данные.
Сначала мы собираем данные. Потом — принимаем решения.
Для сбора эксплуатационных данных мы выбрали Ganglia. Нам оказались полезными несколько ее возможностей:
Ganglia состоит из трех типов компонент:
Ganglia нетрудно сконфигурировать так, чтобы данные были доступны и не терялись при авариях. Система поддерживает multicast-конфигурацию демонов мониторинга. Это означает, что все собранные эксплуатационные данные доставляются каждому узлу в кластере и сохраняются на нем. После этого, мета-демон выбирает, какой из демонов мониторинга опросить, и опрашивает его. Если при опросе происходит сбой, опрашивается следующая нода из кластера. Процесс продолжается до тех пор, пока либо не будет достигнут успех, либо не будет обойден весь кластер.
Конфигурирование такой системы осуществляется довольно просто.
Членство в кластере определяется в конфигурационном файле демона мониторинга gmond.conf
Все узлы кластера должны в конфигурации демона мониторинга иметь строчки, разрешающее рассылать мультикастом данные:
и принимать данные от других узлов
Кроме того, нужно разрешить мета-демону совершать опрос:
Сам мета-демон посредством его конфигурационного файла gmetad.conf должен быть настроен так, чтобы он обходил по очереди все узлы:
Описанная выше конфигурация изображается следующей схемой:
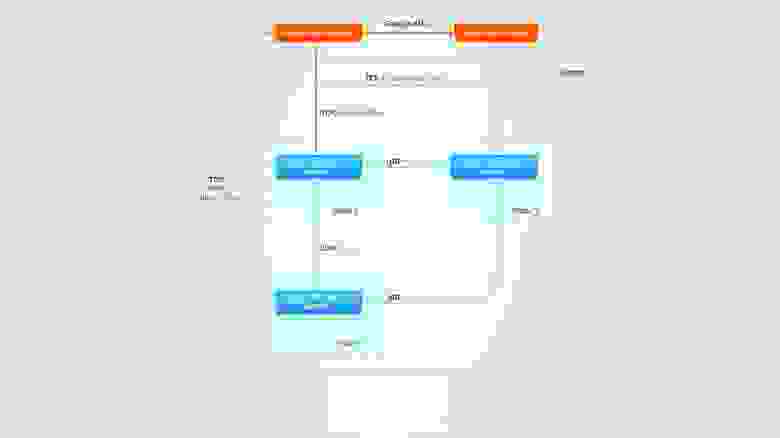
Демоны мониторинга Ganglia обмениваются данными друг с другом. Мета-демон опрашивает один демон мониторинга из кластера. При его недоступности, он обращается к следующему — и так далее. Веб-фронтенд получает XML от демона мониторинга и отображает его в понимаемой человеком форме.
Описанный подход позволяет собирать эксплуатационные данные со всех кластеров. У каждого кластера есть свои особенности, связанные с природой собираемых данных. У нас есть множество подсистем, отличающихся друг от друга — но при этом мы имеем один метод контролировать их все. Упомяну лишь два примера:
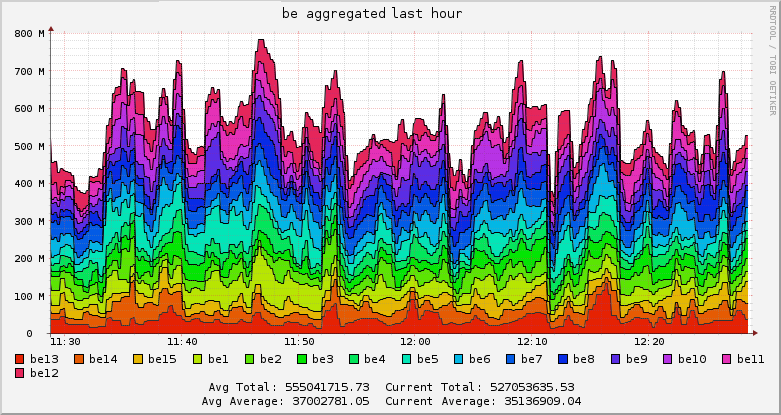
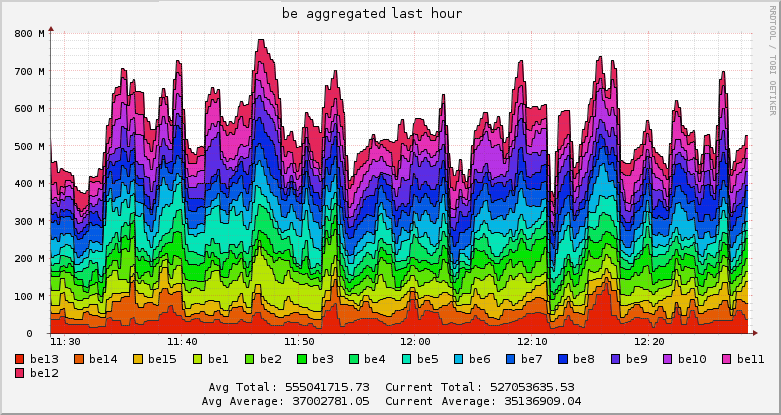
Если вам интересно увидеть, как выглядит веб-фронтенд Ganglia, это можно сделать на открытом фронтенде Wikipedia. Мы используем тот же интерфейс, устанавливаемый по умолчанию. Он выглядит недружественным, но подружиться с ним недолго. Кроме того, он имеет весьма приличную мобильную версию, которая радует менеджера. Возможность компульсивно следить за работой системы, находясь где угодно и в любое время — бесценна.
Логи важны по трем причинам:
Для организации системы сбора логов мы выбрали Logstash

Нельзя пройти мимо проекта с таким милым логотипом
Мы настроили Logstash как rsyslog-сервер. Благодаря этому Logstash может собирать логи с любого софта, способного писать в syslog.
Иметь просто систему сбора логов мало. Мы хотим получать от этого выгоду. Централизованое хранилище логов несет сразу несколько плюсов.
Когда количество серверов измеряется десятками, не говоря уже про сотни, удобство работы с логами имеет значение. У этого удобства есть два аспекта: гибкость и простота использования.
Logstash может использоваться совместно с ПО, которое обеспечивает эти возможности — Elasticsearch и Kibana.
Elasticsearch — это система поиска, снабженная REST API, построенная на основе Apache Lucene. Наличие API делает систему гибкой.
Kibana — это веб-фронтенд, способный работать поверх Elasticsearch. Он отвечает за простоту использования. Работу Kibana можно оценить по демонстрационной странице
Когда кто-то строит систему мониторинга, она может не иметь системы сбора логов или эксплуатационных данных (хотя это и неправильно). Но она точно имеет событийный мониторинг — собственно говоря, поиск по «Хабрахабру» говорит нам о том, что обсуждая мониторинг, люди имеют в виду прежде всего именно его событийную составляющую.
Событийный мониторинг важен потому, что он предоставляет главные интерфейсы для взаимодействия операторов поддержки с системой. Он служит для них приборной панелью и отсылает уведомления.
В качестве системы событийного мониторинга мы выбрали Shinken. Это Nagios-подобная система мониторинга, но не форк Nagios. Shinken был переписан полностью с нуля, сохранив при этом совместимость с плагинами для Nagios.
На сайте системы ее рекламируют как обладающую следующими возможностями:
В «концентрации на воздействии на бизнес» и «обнаружении корневых проблем» мы не нашли для себя большой ценности: фактически, логики, которую обеспечивает Nagios для этого достаточно.
С точки зрения же масштабируемости и надежности Shinken дает интересные возможности.
Shinken — по-настоящему модульная система. Одна из главных инноваций, представленные в Shinken — это четкое разделение на различные демоны:
Каждый из этих демонов может запускаться совершенно независимо от остальных. Кроме того, можно запускать столько демонов, сколько нужно (за исключением арбитра).
Обеспечение резервирования арбитров довольно несложно. Каждый демон может иметь запасной (spare) экземпляр. За это отвечает параметр конфигурации 'spare'. При определении основного арбитра он устанавливается равным нулю,
а при конфигурировании запасного — единице
Когда главный арбитр отказывает, запасной принимает на себя управление. Если арбитры сконфигурированы идентично (а это — единственный правильный способ их настраивать), потеря связности между ними ничем не угрожает. Запасной сделает все то же, что и основной, и не нанесет вреда.
Описание событийного мониторинга было бы неполным, не упомяни мы о событиях, которые мы отслеживаем. Многие из них довольно специфичны (и поэтому малоинтересны большинству читателей), другие — очень общие (и поэтому хорошо описаны в десятке других мест). Однако, пара из них тесно связаны со всей описанной выше системой и потому представляют интерес.
Можно придумать много определений «живого» хоста. Некоторые полагают, что живым можно считать хост, отвечающий на ICMP. В реальности, выбор правильного определения не имеет большого значения. Важен сервис, запущенный на хосте, а не сам хост. Главная причина, по которой нам нужно знать жив хост или нет в каком-то формальном смысле — это правильное определение зависимостей. Построив описанную систему, проверку живости хоста мы получили «бесплатно». Каждый хост должен отправлять в Ganglia свои данные. Пока он их действительно отсылает — он в некотором смысле «жив». Если не отсылает — с ним точно не все в порядке. Мы проверяем наличие этих данных при помощи Ganglia-плагина для Nagios, слегка модифицированного для наших целей.
Имея систему сбора эксплуатационных данных, было бы неразумно не использовать ее в событийном мониторинге. Самый простой способ сделать это — сравнивать получаемые значения с некоторыми пороговыми. Упомянутый в предыдущем пункте Ganglia-плагина для Nagios делает это из коробки.
Высокоуровневая схема взаимодействия компонент мониторинга

Понять ее проще, чем нарисовать.
Кластер приложения отсылает эксплуатационные данные в Ganglia, логи в Logstash и событийные проверки в Shinken.
Ganglia отсылает данные о «живости» хостов и проверки эксплуатационных данных в Shinken.
Shinken обрабатывает получаемое двумя способами. Он отсылает уведомления операторам и запускает обработчики событий, исправляющие некоторые неисправности.
Логи, эксплуатационные данные и информация о событиях отправляются в «приборные панели» — Kibana, Ganglia web frontend и Shinken web соответственно, где за ними наблюдают операторы.
Система мониторинга, которую мы строили не задумывалась как соответствующая каким-то «правильным» практикам панацея. Тем не менее, в жизни она показала себя надежным помощником, на которого можно положиться.
Основным элементом нашей системы предотвращения и обработки нештатных ситуаций является наша команда поддержки, работающая беспрерывно. Мы не пытались придумать автономную систему, способную работать без человеческого вмешательства.
То, что она работает в нашем окружении не означает, что она будет работать в другом без внесения в нее изменений. Мониторинг является частью нашей общей экосистемы, включающей как технические меры (такие как наличие и грамотное использование системы управления конфигурациями), так и бизнес-процессы в работе нашей команды поддержки.
Тем не менее, мы уверены, что наш подход достаточно гибок и может быть в том или ином виде применен в достаточно широком круге ситуаций, с которыми сталкиваются в своей работе команды, поддерживающие IT-сервисы.
Наша система мониторинга преследует несколько целей:
- В случае сбоя, мы не должны тратить время на то, чтобы определить, что произошло. Мы должны сразу и твердо это знать.
- Чтобы предотвратить максимальное количество сбоев до момента когда они затронут клиентов мы должны контролировать метрики и события, предвещающие проблемы.
- После любого инцидента мы должны иметь полный доступ ко всем данным, необходимым для расследования его причин, даже если на момент устранения его причина не была понятна.
- Наша команда поддержки должна реагировать на сбои оперативно и верно. Единственный способ достичь этого – обеспечить сотрудников инструментом, не загружающим их ненужной информацией.
Мы работали над системой мониторинга не меньше времени, чем над функциональной частью сервиса — и мы делимся наработанным опытом.
В целом, наша система мониторинга состоит из трех основных подсистем:
- сбора и анализа эксплуатационных данных;
- сбора и анализа логов;
- событийного мониторинга и оповещения.
Система сбора и анализа эксплуатационных данных
Обычно, когда говорят «мониторинг», под этим словом понимают событийный мониторинг (
** PROBLEM Host Alert: server01 is DOWN **). Краеугольный же камень нашего мониторинга — непрерывная работа с операционными данными. Состояние всех находящихся под наблюдением систем описывается показателями, меняющимися в течение всего наблюдения.В простейшем случае — если выключился сервер (скажем, из-за отключения питания) — эти данные имеют простую форму: доступно на 1 сервер меньше, чем мы ожидали. Если же ситуация более сложная: например, по каким-то причинам приложение постепенно деградировало и стало медленнее отвечать на запросы, измерения могут показать, например, что «95-й перцентиль времени ответа удвоился за последнюю неделю». При этом, какого-то конкретного момента времени, когда система «сломалась» не существует. Лягушка не может назвать точный момент времени, когда вокруг нее образовался кипяток.
Иными словами, привычные события переформулировать на языке данных чаще всего нетрудно, но данные имеют и самостоятельную дополнительную ценность. Мы решили строить мониторинг с ориентацией на данные.
Сначала мы собираем данные. Потом — принимаем решения.
Для сбора эксплуатационных данных мы выбрали Ganglia. Нам оказались полезными несколько ее возможностей:
- «Из коробки» работает с кластерами;
- Естественно масштабируется;
- Создает низкую нагрузку на узлы, с которых собирает данные;
- Поддерживает отказоустойчивую конфигурацию;
- Хорошо сопрягается с системами событийного мониторинга;
- Панель инструментов не требует доработки напильником.
Ganglia состоит из трех типов компонент:
- Ganglia monitoring daemon (gmond) — демон мониторинга Ganglia, запускающийся на каждом узле. Gmond собирает данные со своего сервера и отсылает их на другие узлы.
- Ganglia meta daemon (gmetad) — мета-демон Ganglia, опрашивающий демоны мониторинга и собирающий метрики. Результаты измерений, собранные мета-демоном, записываются в структурированном виде и могут быть опубликованы произвольному набору доверенных хостов. Формат данных документирован. Мы используем эти данные для графиков в веб-интерфейсе и информирования событийного мониторинга об аномалиях.
- Веб-интерфейс Ganglia. В идеальном мире, где все процессы полностью автоматизированы, иметь веб-интерфейс к системе сбора данных необязательно. Мы же довольно активно смотрим на графики и выявляем закономерности самостоятельно. Можно использовать любой веб-интерфейс или написать свой собственный. Мы используем стандартный. Каждый сотрудник может сформировать собственный набор графиков для одновременного отображения и таким образом отслеживать именно те параметры, которые интересуют его. Также есть возможность строить агрегированные графики по нескольким хостам.
Ganglia нетрудно сконфигурировать так, чтобы данные были доступны и не терялись при авариях. Система поддерживает multicast-конфигурацию демонов мониторинга. Это означает, что все собранные эксплуатационные данные доставляются каждому узлу в кластере и сохраняются на нем. После этого, мета-демон выбирает, какой из демонов мониторинга опросить, и опрашивает его. Если при опросе происходит сбой, опрашивается следующая нода из кластера. Процесс продолжается до тех пор, пока либо не будет достигнут успех, либо не будет обойден весь кластер.
Конфигурирование такой системы осуществляется довольно просто.
Конфигурирование Ganglia
Членство в кластере определяется в конфигурационном файле демона мониторинга gmond.conf
cluster {
name = "databases"
...
}
Все узлы кластера должны в конфигурации демона мониторинга иметь строчки, разрешающее рассылать мультикастом данные:
udp_send_channel {
mcast_if = eth0
mcast_join = 239.2.11.71
port = 8651
ttl = 1
}
и принимать данные от других узлов
udp_recv_channel {
mcast_if = eth0
mcast_join = 239.2.11.71
port = 8651
bind = 239.2.11.71
}
Кроме того, нужно разрешить мета-демону совершать опрос:
tcp_accept_channel {
port = 8649
}
Сам мета-демон посредством его конфигурационного файла gmetad.conf должен быть настроен так, чтобы он обходил по очереди все узлы:
data_source “databases” node_1_ip_address node_2_ip_address … node_N_ip_address
Описанная выше конфигурация изображается следующей схемой:

Демоны мониторинга Ganglia обмениваются данными друг с другом. Мета-демон опрашивает один демон мониторинга из кластера. При его недоступности, он обращается к следующему — и так далее. Веб-фронтенд получает XML от демона мониторинга и отображает его в понимаемой человеком форме.
Практическое применение
Описанный подход позволяет собирать эксплуатационные данные со всех кластеров. У каждого кластера есть свои особенности, связанные с природой собираемых данных. У нас есть множество подсистем, отличающихся друг от друга — но при этом мы имеем один метод контролировать их все. Упомяну лишь два примера:
- Наши системы управления, сбора информации о потреблении ресурсов и биллинга написаны на ruby. Для ruby есть гем gmetric, разработанный Ильей Григориком. С его помощью на этапе разработки мы включили биллинг в систему мониторинга за пару дней. Сразу после этого мы нашли несколько бутылочных горлышек и исключили их.
- Важнейшее ПО, которое мы используем — Openstack Swift. Сбор данных с него организуется при помощи StatsD. StatsD в свою очередь имеет бэкенд для Ganglia — и с его помощью мы отсылаем данные в нашу систему сбора.
Если вам интересно увидеть, как выглядит веб-фронтенд Ganglia, это можно сделать на открытом фронтенде Wikipedia. Мы используем тот же интерфейс, устанавливаемый по умолчанию. Он выглядит недружественным, но подружиться с ним недолго. Кроме того, он имеет весьма приличную мобильную версию, которая радует менеджера. Возможность компульсивно следить за работой системы, находясь где угодно и в любое время — бесценна.
Система сбора и анализа логов
Логи важны по трем причинам:
- Логи — это важнейший элемент post-mortem-ов и анализа происшествий. Если что-то сломалось, нужно изучить логи, чтобы понять причины произошедшего.
- Логи помогают определять наличие проблем. Мы точно знаем, что то или иное поведение программ доставляет проблемы нашим пользователям и это поведение можно отслеживать при помощи логов.
- Логи также предоставляют некоторые метрики. Можно считать частоту тех или иных событий при помощи логов и отправлять ее в систему сбора эксплуатационных данных.
Для организации системы сбора логов мы выбрали Logstash

Нельзя пройти мимо проекта с таким милым логотипом
Мы настроили Logstash как rsyslog-сервер. Благодаря этому Logstash может собирать логи с любого софта, способного писать в syslog.
Иметь просто систему сбора логов мало. Мы хотим получать от этого выгоду. Централизованое хранилище логов несет сразу несколько плюсов.
Индексирование и поиск
Когда количество серверов измеряется десятками, не говоря уже про сотни, удобство работы с логами имеет значение. У этого удобства есть два аспекта: гибкость и простота использования.
Logstash может использоваться совместно с ПО, которое обеспечивает эти возможности — Elasticsearch и Kibana.
Elasticsearch — это система поиска, снабженная REST API, построенная на основе Apache Lucene. Наличие API делает систему гибкой.
Kibana — это веб-фронтенд, способный работать поверх Elasticsearch. Он отвечает за простоту использования. Работу Kibana можно оценить по демонстрационной странице
Событийный мониторинг
Когда кто-то строит систему мониторинга, она может не иметь системы сбора логов или эксплуатационных данных (хотя это и неправильно). Но она точно имеет событийный мониторинг — собственно говоря, поиск по «Хабрахабру» говорит нам о том, что обсуждая мониторинг, люди имеют в виду прежде всего именно его событийную составляющую.
Событийный мониторинг важен потому, что он предоставляет главные интерфейсы для взаимодействия операторов поддержки с системой. Он служит для них приборной панелью и отсылает уведомления.
В качестве системы событийного мониторинга мы выбрали Shinken. Это Nagios-подобная система мониторинга, но не форк Nagios. Shinken был переписан полностью с нуля, сохранив при этом совместимость с плагинами для Nagios.
На сайте системы ее рекламируют как обладающую следующими возможностями:
- умная фильтрация и обнаружение корневых проблем, ведущая к уменьшению количества ненужных оповещений;
- концентрация на «воздействии на бизнес»;
- масштабируемость;
- надежность.
В «концентрации на воздействии на бизнес» и «обнаружении корневых проблем» мы не нашли для себя большой ценности: фактически, логики, которую обеспечивает Nagios для этого достаточно.
С точки зрения же масштабируемости и надежности Shinken дает интересные возможности.
Масштабирование и обеспечение отказоустойчивости
Shinken — по-настоящему модульная система. Одна из главных инноваций, представленные в Shinken — это четкое разделение на различные демоны:
- Pollers — запускают проверки и возвращают результаты;
- Reactionners — реагируют на результаты, отсылая уведомления или запуская обработчики событий;
- Schedulers — распределяют задачи между поллерами и результаты между реакционерами. Schedulers имеют некоторый внутренний интеллект, который позволяет им, например, если одна из проверок возвращает ошибку, поднять наверх очереди проверки от которых она зависит.
- Brokers — получают данные от scheduler-ов и сохраняют их в заданные при помощи плагинов хранилища.
- Arbiter — арбитр знает всю конфигурацию системы и распределяет части конфигурации и задачи между scheduler-ами. Он проверяет работоспособность других демонов, и если, например, один из scheduler-ов не отвечает, он делит его задачи между другими. В одном кластере нельзя иметь более одного активного арбитра.
Каждый из этих демонов может запускаться совершенно независимо от остальных. Кроме того, можно запускать столько демонов, сколько нужно (за исключением арбитра).
Обеспечение резервирования арбитров довольно несложно. Каждый демон может иметь запасной (spare) экземпляр. За это отвечает параметр конфигурации 'spare'. При определении основного арбитра он устанавливается равным нулю,
define arbiter{
arbiter_name arbiter-master
address master_ip
host_name master_hostname
port 7770
spare 0
}
а при конфигурировании запасного — единице
define arbiter{
arbiter_name arbiter-slave
address spare_ip
host_name slave_hostname
port 7770
spare 1
}
Когда главный арбитр отказывает, запасной принимает на себя управление. Если арбитры сконфигурированы идентично (а это — единственный правильный способ их настраивать), потеря связности между ними ничем не угрожает. Запасной сделает все то же, что и основной, и не нанесет вреда.
Описание событийного мониторинга было бы неполным, не упомяни мы о событиях, которые мы отслеживаем. Многие из них довольно специфичны (и поэтому малоинтересны большинству читателей), другие — очень общие (и поэтому хорошо описаны в десятке других мест). Однако, пара из них тесно связаны со всей описанной выше системой и потому представляют интерес.
Немного о проверках
«Живость» хоста
Можно придумать много определений «живого» хоста. Некоторые полагают, что живым можно считать хост, отвечающий на ICMP. В реальности, выбор правильного определения не имеет большого значения. Важен сервис, запущенный на хосте, а не сам хост. Главная причина, по которой нам нужно знать жив хост или нет в каком-то формальном смысле — это правильное определение зависимостей. Построив описанную систему, проверку живости хоста мы получили «бесплатно». Каждый хост должен отправлять в Ganglia свои данные. Пока он их действительно отсылает — он в некотором смысле «жив». Если не отсылает — с ним точно не все в порядке. Мы проверяем наличие этих данных при помощи Ganglia-плагина для Nagios, слегка модифицированного для наших целей.
Проверка эксплуатационных данных
Имея систему сбора эксплуатационных данных, было бы неразумно не использовать ее в событийном мониторинге. Самый простой способ сделать это — сравнивать получаемые значения с некоторыми пороговыми. Упомянутый в предыдущем пункте Ganglia-плагина для Nagios делает это из коробки.
TL;DR
Высокоуровневая схема взаимодействия компонент мониторинга
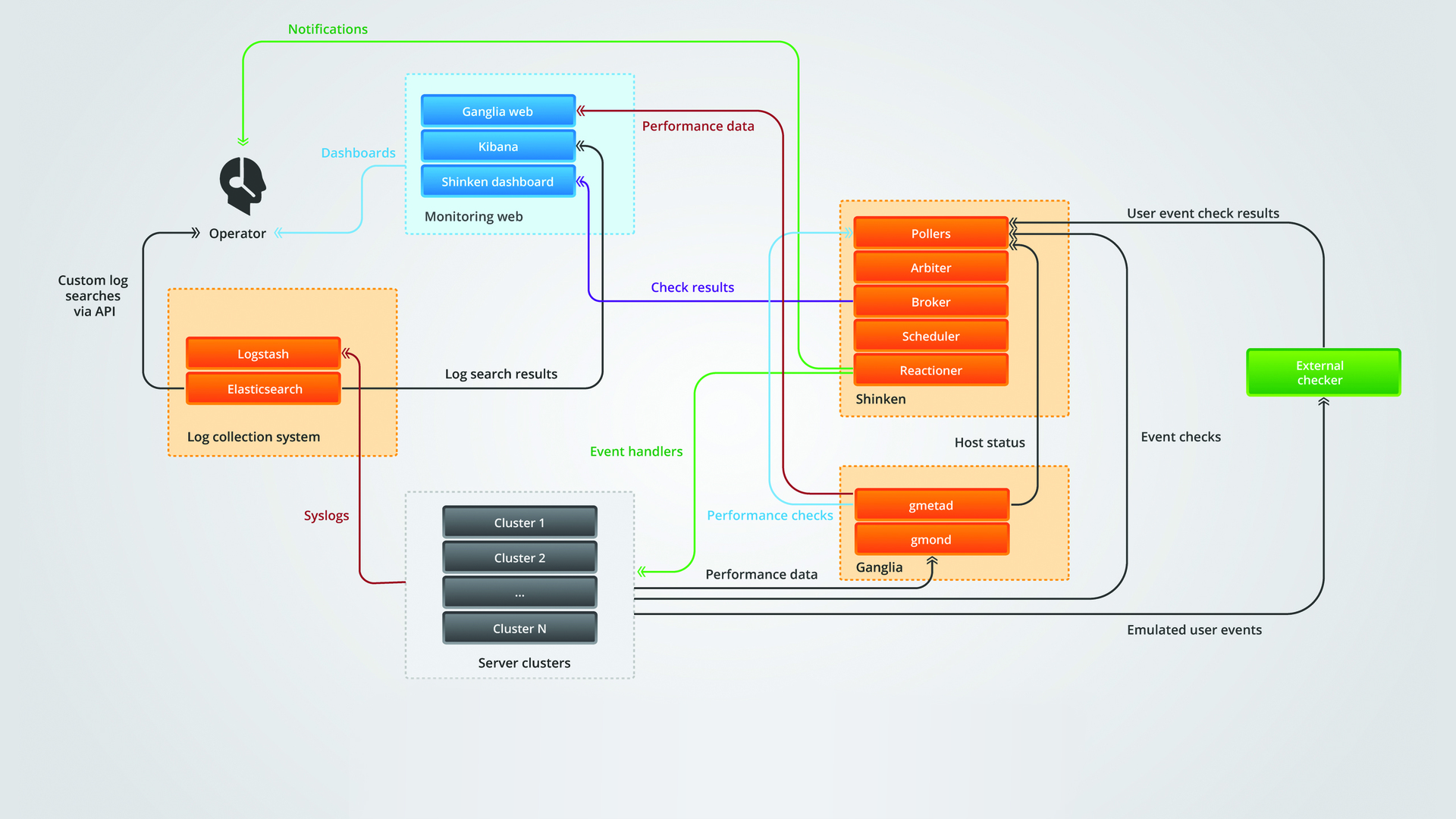
Понять ее проще, чем нарисовать.
Кластер приложения отсылает эксплуатационные данные в Ganglia, логи в Logstash и событийные проверки в Shinken.
Ganglia отсылает данные о «живости» хостов и проверки эксплуатационных данных в Shinken.
Shinken обрабатывает получаемое двумя способами. Он отсылает уведомления операторам и запускает обработчики событий, исправляющие некоторые неисправности.
Логи, эксплуатационные данные и информация о событиях отправляются в «приборные панели» — Kibana, Ganglia web frontend и Shinken web соответственно, где за ними наблюдают операторы.
Почему мы решили про это написать?
Система мониторинга, которую мы строили не задумывалась как соответствующая каким-то «правильным» практикам панацея. Тем не менее, в жизни она показала себя надежным помощником, на которого можно положиться.
Основным элементом нашей системы предотвращения и обработки нештатных ситуаций является наша команда поддержки, работающая беспрерывно. Мы не пытались придумать автономную систему, способную работать без человеческого вмешательства.
То, что она работает в нашем окружении не означает, что она будет работать в другом без внесения в нее изменений. Мониторинг является частью нашей общей экосистемы, включающей как технические меры (такие как наличие и грамотное использование системы управления конфигурациями), так и бизнес-процессы в работе нашей команды поддержки.
Тем не менее, мы уверены, что наш подход достаточно гибок и может быть в том или ином виде применен в достаточно широком круге ситуаций, с которыми сталкиваются в своей работе команды, поддерживающие IT-сервисы.
