
Перевод поста Джона Маклуна (Jon Mcloone, директор департамента международного бизнеса и стратегического развития Wolfram Research). Оригинал поста: How to Win at Rock-Paper-Scissors
Скачать пост в виде документа Mathematica
С точки зрения математики игра камень-ножницы-бумага (см. Дополнение 1 в конце) не является особо интересной. Стратегия равновесия Нэша очень проста: случайно и с одинаковой вероятностью выбирайте из трех вариантов, и при условии проведения большого числа игр ни вы, ни ваш соперник не сможете одержать победу. Хотя, при обсчитывании стратегии при помощи компьютера всё ещё возможно выиграть у человека после большого числа игр.
Моя девятилетняя дочь показала мне программу, созданную ей при помощи Scratch, которая выигрывала абсолютно каждый раз просто отслеживая, какой выбор сделали вы, перед тем, как сделать свой! Но я познакомлю вас с простым решением, которое выигрывает у человека в камень-ножницы-бумагу без обмана.

Поскольку того, кто всегда совершает абсолютно случайный выбор победить невозможно, мы будем рассчитывать на то, что люди не очень-то и случайны. Если компьютер сможет заметить некий шаблон, по которому вы действуете в своих попытках быть случайным, он станет на шаг ближе к тому, чтобы предсказать ваши будущие действия.
Я думал о создании алгоритма в качестве одной из тем нашего курса статистики в рамках концепции Computer-Based Math. Но первая же статья, на которую я наткнулся в поисках предсказательных алгоритмов, рассматривала решение при помощи сложной конструкции на основе копула-распределений. Это решение было трудным для понимания школьника (а возможно, и для меня), поэтому я решил разработать более простое решение, которое я мог бы объяснить простыми словами. И пусть даже оно уже и было разработано ранее, намного веселее создавать вещи по-своему, чем находить их готовую реализацию.
Для начала нам необходимо просто иметь возможность начать игру. На тот момент уже была разработана и доступна демонстрация, позволяющая играть в камень-ножницы-бумагу, но это было не совсем то, что мне нужно, поэтому я написал свою версию. Этот пункт не требует особых пояснений:
In[1]:=

Out[1]=

По большей части этот код описывает пользовательский интерфейс и правила игры. Вся стратегия компьютерного игрока содержится в этой функции:
In[2]:=
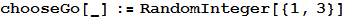
где 1 соответствует камню, 2 — бумаге и 3 — ножницам. Это оптимальное решение. Как бы вы ни играли, вы выиграете столько же игр, сколько и компьютер, и ваш показатель побед будет колебаться в районе нуля.
Итак, теперь было бы интересно переписать функцию chooseGo чтобы осуществлять предсказание касаемо вашего выбора, используя данные о последних играх, хранящиеся в переменной history. Первым шагом будет анализ совершённых в течение последних нескольких игр выборов и поиск всех случаев вхождения какой-либо последовательности. Наблюдая за тем, что человек делал в каждой следующей игре, мы можем обнаружить некий шаблон поведения.
In[3]:=

Первый аргумент функции представляет собой историю прошлых игр. Например, в наборе данных, представленных ниже, компьютер (вторая колонка — второй элемент каждого подсписка) только что сыграл бумагу (ей соответствует число 2) против камня, сыгранного человеком (число 1). Это видно по последнему элементу списка. Также видно, что такая ситуация уже возникала дважды, и оба раза следующим ходом человека был снова камень.
In[4]:=
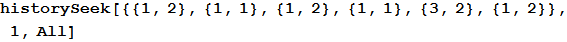
Out[4]=
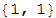
Второй аргумент это количество последних элементов истории, по которым и будет вестись поиск. В данном случае в качестве аргумента функции передано число 1, что осуществляет поиск в данных только случаев вхождения {1,2}. Если мы выберем 2, то функция будет искать вхождения последовательности {3,2}, {1,2} и вернёт пустой список, поскольку такая последовательность ранее не встречалась.
Третий аргумент, All, указывает на то, что в искомых последовательностях должны совпадать и ходы человека, и ходы компьютера. Аргумент можно изменить на 1, чтобы смотреть только на историю ходов человека (то есть предполагая, что человеческий выбор зависит только от его же предыдущих ходов), или 2, чтобы обращать внимания только на второй столбец, то есть на историю ходов компьютера (то есть предполагая, что человек отвечает на предыдущие ходы компьютера независимо от того, какие сам совершал ходы и, следовательно, независимо от того, выиграл он или проиграл).
Например, в данном случае мы находим, что человек выбирал после камня, вне зависимости от того, что в тех же играх выбирал компьютер.
In[5]:=
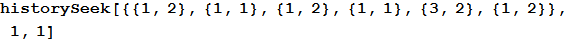
Out[5]=

Имея большое количество данных, мы можем обойтись только аргументом All, и программа сможет сама решить, чьи ходы, компьютера или человека, более важны. Например, если история ходов компьютера игнорируется человеком в ходе осуществления выбора, тогда набор данных, полученый для какой-либо истории ходов компьютера будет иметь то же распределение, что и для любой другой истории ходов компьютера, при условии, что данных о предыдущих играх достаточно. Осуществляя поиск по всем парам игр, получим тот же результат, как и если бы мы сначала выбирали данные по истории ходов компьютера, а потом использовали это подмножество для показанной выше функции. То же произойдёт в случае, если имеет значение только история ходов компьютера. Но при этом, производя поиск при учёте обоих этих предположений по отдельности можно получить более верные совпадения в истории, и больше всего это проявляется в случаях, когда набор данных об играх поначалу мал.
Таким образом из этих двух проверок мы можем обнаружить, что первый даёт оценку в 100%, что следующим выбором человека будет камень, а второй показывает, что с 75% вероятностью человек выберет камень и с 25% вероятностью — ножницы.
И здесь я несколько застопорился в решении задачи.
В данном случае два предсказания по крайне мере более менее близки по результату, хотя и расходятся в численных значениях вероятностей. Но если вы проводите поиск по трём «срезам» данных c рядом различных длин истории, и результаты предсказаний противоречивы — как их объединить?
Я поместил заметку об этой проблеме в папку «Написать про это в блог» и забыл о ней до тех пор, пока несколько недель назад не произошёл спор о том, как осветить концепцию "статистической значимости" в курсе Computer-Based Math.
Я понял, что вопрос состоит не в том, как скомбинировать полученные предсказания, а в том, как определить, какое из предсказаний наиболее значимое. Одно из предсказаний могло бы быть более значимым, чем остальные, поскольку оно отражает более выраженную тенденцию или, может быть, основано на большем наборе данных. Это было неважно для меня, и поэтому я просто использовал p-значение теста на значимость (с нулевой гипотезой о том, что оба игрока играют случайно), чтобы упорядочить полученные предсказания.
Думаю, мне следовало бы прислушаться к нашему же первому принципу о том, что первым шагом в решении любой математической проблемы является “верная постановка вопроса”.
In[6]:=

Теперь, если мы возьмём последний полученный нами результат, обнаруживается, что лучшее предсказание — камень, имеющее p-значение 0.17. Это значит, что лишь с вероятностью 0.17, данные, используемые для данного предсказания, отклоняются от дискретного равномерного распределения (DiscreteUniformDistribution[{1,3}]), причём скорее случайно, чем из-за систематической ошибки, производимой человеческом или по какой-либо другой причине, которая могла изменить распределение.
In[7]:=
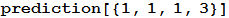
Out[7]=
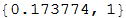
Чем меньше это p-значение, тем более уверенными мы можем быть в том, что нашли настоящий шаблон поведения. Так что мы просто осуществляем предсказания для различных длин истории и срезов данных и выбираем предсказание с наименьшим p-значением.
In[8]:=

И делаем такой выбор, который побьёт выбор человека.
In[10]:=

Здесь вы видите результат. Вы можете скачать и самостоятельно опробовать его с сайта Wolfram Demonstrations.
In[11]:=

Out[11]=

Когда программа имеет слишком мало данных, она играет случайно, так что начинаете вы на равных. Поначалу, когда она только начинает обучаться, она принимает несколько глупые решения, поэтому вы можете вырваться вперёд. Но после 30-40 игр она начинает получать действительно значимые предсказания, и вы увидите, как ваш показатель побед опустится в отрицательную область и так там и останется.
Конечно, такое решение хорошо только против примитивных попыток казаться случайным. Его предсказуемость делает его подверженным возможному проигрышу против хорошо просчитанной и намеченной стратегии. Крайне интересно попробовать победить эту программу при помощи интуиции. Это возможно, но если вы перестанете думать либо будете думать слишком усердно, вы скоро отстанете. Конечно, программа могла бы с лёгкостью это сделать, применяя тот же алгоритм с целью предсказать следующий ход этой программы.
Такой подход ведёт к началу некой «гонки вооружений», соревнований по написанию алгоритмов, которые будут выигрывать в камень-ножницы-бумагу у алгоритма соперника, и единственный способ прекратить это — вернуться к стратегии равновесия Нэша, осуществляя выбор через RandomInteger[{1,3}].
Дополнение 1
В том случае, если вы не знаете, как играть в эту игру, правила таковы: вы выбираете камень, ножницы или бумагу, используя один из трёх жестов, показанных одновременно вами и вашим соперником. Камень побеждает ножницы (делает их тупыми), ножницы побеждают бумагу (они её режут), а бумага побеждает камень (она его заворачивает). Победивший получает одно очко, в случае ничьей оба игрока не получают очков.
Благодарю Сергея Шевчука за помощь, оказанную в переводе данного поста.
