
Сегодня Яндекс запустил поиск картинки по загруженному изображению. В этом посте мы хотим рассказать о технологии, которая стоит за этим сервисом, и о том, как её делали.
Технология внутри Яндекса получила название «Сибирь». От CBIR — Content-Based Image Retrieval.
Конечно, сама по себе задача не нова, и ей посвящено множество исследований. Но сделать прототип, работающий на академической коллекции, и построить промышленную систему, которая работает с миллиардами изображений и большим потоком запросов — очень разные истории.

Есть три сценария, при которых нужен поиск по загруженной картинке и которые нам и нужно было научиться обрабатывать.
Есть разные подходы, с помощью которых можно находить аналогичные изображения. Самый распространенный основан на представлении изображения в виде визуальных слов — квантованных локальных дескрипторов, вычисленных в особенных точках. Особенными называют точки, которые наиболее стабильны при изменениях изображения. Чтобы их найти, изображение обрабатывается специальными фильтрами. Описание областей вокруг этих точек в цифровом виде и является дескриптором. Чтобы превратить дескрипторы в визуальные слова, используется словарь визуальных слов. Его получают в результате кластеризации всех дескрипторов, посчитанных для репрезентативного множества изображений. В дальнейшем каждый вновь вычисленный дескриптор относят к соответствующему кластеру — так получаются квантованные дескрипторы (визуальные слова).
Процесс поиска изображения по загруженной картинке в больших коллекциях, как правило, строится в таком порядке:
Используемый нами способ поиска изображений по картинке-запросу схож с вышеизложенным традиционным подходом. Однако проверка взаимного расположения локальных особенностей требует значительных вычислительных ресурсов. И для того чтобы искать по огромной коллекции изображений, хранящейся в поисковом индексе Яндекса, нам пришлось найти более эффективные способы решения задачи. Наш метод индексирования позволяет существенно сократить количество изображений, которые могут считаться релевантными образцу (запросу).
Ключевое в нашей реализации поиска кандидатов — это переход от индексирования визуальных слов к индексированию более дискриминативных признаков, специальная структура индекса.
Для отбора кандидатов одинаково хорошо показали себя два метода:
При валидации мы используем собственную реализацию кластеризации преобразований между изображениями.
Теперь поднимемся на уровень выше и посмотрим на схему продукта в целом.
Каждый базовый поиск работает со своей частью индекса. Этим обеспечивается масштабируемость системы: при росте индекса добавляются новые фрагменты и новые реплики базового поиска. А отказоустойчивость обеспечивается дублированием базовых поисков и фрагментов индекса.
И еще один важный нюанс. Когда мы строили наш поисковый индекс изображений, то для того чтобы повысить эффективность поиска, использовали уже имеющиеся у нас знания о дубликатах изображений. Использовали это таким образом, что из каждой группы дубликатов мы брали только по одному представителю и включали его в индекс поиска по картинке. Логика проста: если картинка релевантна запросу, то все её копии будут так же релевантным ответом.
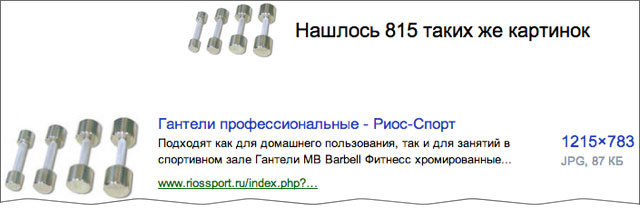
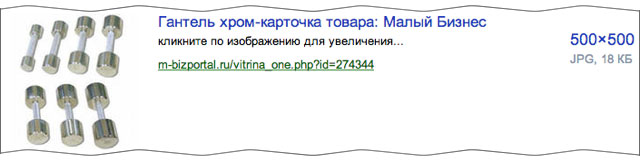

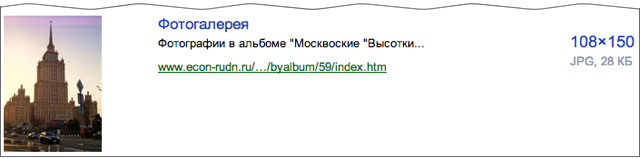
В этой версии мы рассчитывали находить только копии изображения, либо целиком совпадающие с загруженной картинкой, либо содержащие совпадающие фрагменты. Но уже сейчас наше решение показывает способности к обобщению: порой находится не просто такая же картинка, а другая картинка, но содержащая такой же объект. Например, это часто проявляется на архитектуре.




Это наш первый шаг в поиске изображений по контенту. Конечно, мы будем развивать подобные технологии и делать на их основе новые продукты. И уж чего-чего, а идей и желания у нас для этого хватает.
Технология внутри Яндекса получила название «Сибирь». От CBIR — Content-Based Image Retrieval.
Конечно, сама по себе задача не нова, и ей посвящено множество исследований. Но сделать прототип, работающий на академической коллекции, и построить промышленную систему, которая работает с миллиардами изображений и большим потоком запросов — очень разные истории.

Для чего всё это нужно?
Есть три сценария, при которых нужен поиск по загруженной картинке и которые нам и нужно было научиться обрабатывать.
- Человеку нужна такая же или похожая картинка, но в другом разрешении (как правило, самая большая), а может, другого цвета, лучшего качества или не обрезанная.
- Нужно понять, что на картинке. В этом случае достаточно короткого описания рядом с изображением, чтобы стало понятно, кто или что на нем.
- Нужно найти сайт, на котором есть такая же картинка. Например, когда захотелось почитать о том, что на картинке. Или посмотреть на такие же картинки. Или купить то, что на картинке изображено, – в этом случае нужны магазины.
Как это работает?
Есть разные подходы, с помощью которых можно находить аналогичные изображения. Самый распространенный основан на представлении изображения в виде визуальных слов — квантованных локальных дескрипторов, вычисленных в особенных точках. Особенными называют точки, которые наиболее стабильны при изменениях изображения. Чтобы их найти, изображение обрабатывается специальными фильтрами. Описание областей вокруг этих точек в цифровом виде и является дескриптором. Чтобы превратить дескрипторы в визуальные слова, используется словарь визуальных слов. Его получают в результате кластеризации всех дескрипторов, посчитанных для репрезентативного множества изображений. В дальнейшем каждый вновь вычисленный дескриптор относят к соответствующему кластеру — так получаются квантованные дескрипторы (визуальные слова).
Процесс поиска изображения по загруженной картинке в больших коллекциях, как правило, строится в таком порядке:
- Получение набора визуальных слов для загруженной картинки.
- Поиск кандидатов по инвертированному индексу, определяющему по заданному набору визуальных слов список содержащих его изображений.
- Проверка взаимного расположения совпавших дескрипторов для картинки-образца и исследуемого изображения. Это этап валидации и ранжирования кандидатов. Традиционно используется кластеризация преобразований Хафа или RANSAC.
Идеи подхода изложены в статьях:
- J. Philbin, O. Chum, M. Isard, J. Sivic, and A. Zisserman. Object retrieval with large vocabularies and fast spatial matching. In CVPR, 2007
- J. Sivic and A. Zisserman. Video google: a text retrieval approach to object matching in videos. In ICCV, 2003.
- James Philbin Josef Sivic Andrew Zisserman Geometric Latent Dirichlet Allocation on a Matching Graph for Large-scale Image Datasets (Items 3.1, 3.2)
Используемый нами способ поиска изображений по картинке-запросу схож с вышеизложенным традиционным подходом. Однако проверка взаимного расположения локальных особенностей требует значительных вычислительных ресурсов. И для того чтобы искать по огромной коллекции изображений, хранящейся в поисковом индексе Яндекса, нам пришлось найти более эффективные способы решения задачи. Наш метод индексирования позволяет существенно сократить количество изображений, которые могут считаться релевантными образцу (запросу).
Ключевое в нашей реализации поиска кандидатов — это переход от индексирования визуальных слов к индексированию более дискриминативных признаков, специальная структура индекса.
Для отбора кандидатов одинаково хорошо показали себя два метода:
- Индексирование высокоуровневых особенностей или визуальных фраз (словосочетаний). Они представляют собой комбинацию визуальных слов и параметров, характеризующих взаимное расположение и другие относительные характеристики соответствующих локальных особенностей изображения.
- Мульти-индекс, где ключ составляется из квантованных частей дескрипторов (product quantization). Метод был опубликован: download.yandex.ru/company/cvpr2012.pdf
При валидации мы используем собственную реализацию кластеризации преобразований между изображениями.
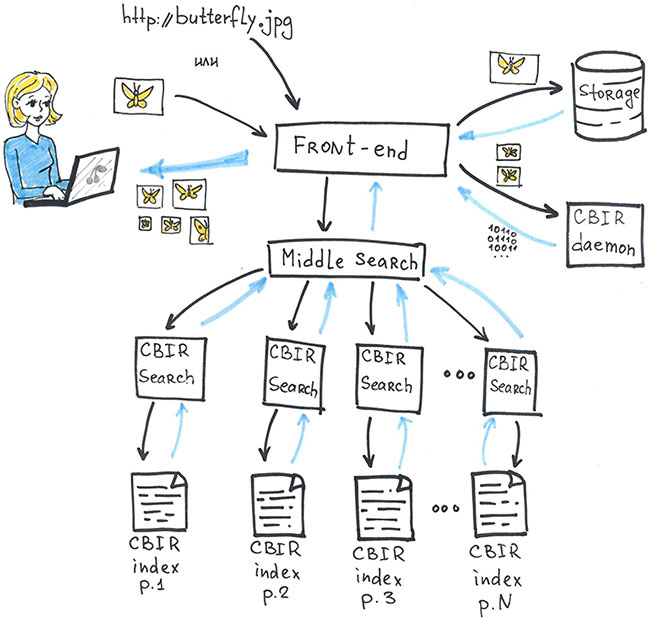
Теперь поднимемся на уровень выше и посмотрим на схему продукта в целом.
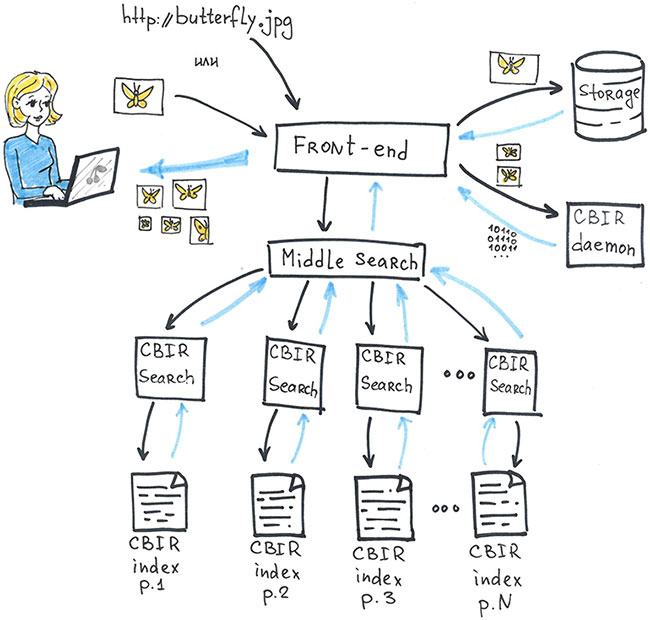
- Картинка пользователя попадает во временное хранилище.
- Оттуда уменьшенная копия изображения попадает в демон, где для картинки вычисляются дескрипторы и визуальные слова и из них формируется поисковый запрос.
- Запрос отправляется сначала на средний метапоиск и оттуда распределяется по базовым поискам. На каждом базовом поиске может найтись множество изображений.
- Найденные изображения отправляются обратно на средний метапоиск. Там происходит слияние результатов, и полученный отранжированный список показывается пользователю.
Каждый базовый поиск работает со своей частью индекса. Этим обеспечивается масштабируемость системы: при росте индекса добавляются новые фрагменты и новые реплики базового поиска. А отказоустойчивость обеспечивается дублированием базовых поисков и фрагментов индекса.
И еще один важный нюанс. Когда мы строили наш поисковый индекс изображений, то для того чтобы повысить эффективность поиска, использовали уже имеющиеся у нас знания о дубликатах изображений. Использовали это таким образом, что из каждой группы дубликатов мы брали только по одному представителю и включали его в индекс поиска по картинке. Логика проста: если картинка релевантна запросу, то все её копии будут так же релевантным ответом.

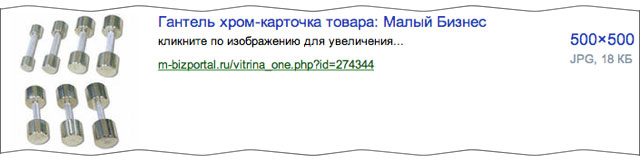

В этой версии мы рассчитывали находить только копии изображения, либо целиком совпадающие с загруженной картинкой, либо содержащие совпадающие фрагменты. Но уже сейчас наше решение показывает способности к обобщению: порой находится не просто такая же картинка, а другая картинка, но содержащая такой же объект. Например, это часто проявляется на архитектуре.
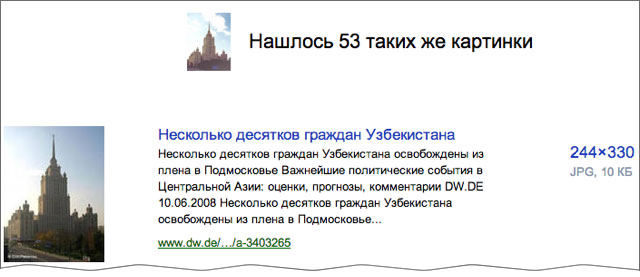




Это наш первый шаг в поиске изображений по контенту. Конечно, мы будем развивать подобные технологии и делать на их основе новые продукты. И уж чего-чего, а идей и желания у нас для этого хватает.
