
Сегодня мы расскажем вам о нашей технологии под названием Блендер. Она обеспечивает ранжирование и встраивание блоков с вертикальными поисками в страницу поисковой выдачи Яндекса.
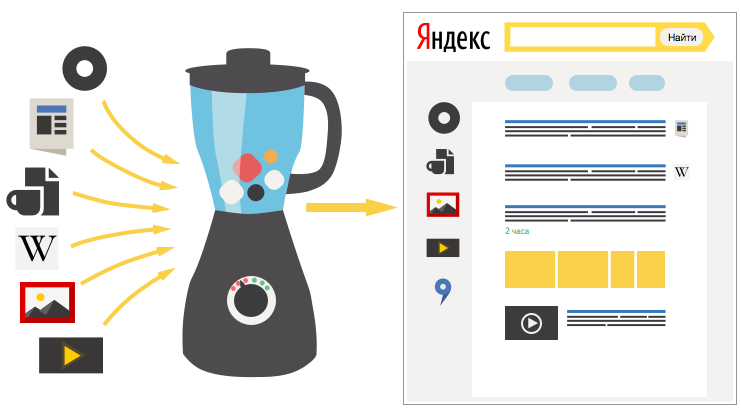
Начать, пожалуй, стоит с того, зачем вообще мы применяем вертикальные поиски. В некоторых случаях поиск по вертикалям бывает гораздо эффективнее стандартного веб-поиска. Например, когда пользователю требуется найти информацию определенного типа (картинки, видео). Некоторые запросы подразумевают другие критерии ранжирования: при поиске по товарам важно иметь возможность производить ранжирование по цене, а в поиске по людям необходимо учитывать дополнительные фильтры. Вертикальные поиски также могут предполагать совершенно иные способы взаимодействия с пользователем, как в случае с навигацией по результатам, отмеченным на карте, при поиске ближайшего магазина, кинотеатра или заправки.
Конечно, с таким запросами лучше всего обращаться в специализированные поисковые сервисы Яндекса: Картинки, Видео, Карты, Музыку. Однако это требует от пользователя дополнительных действий: нужно предварительно вбить адрес или выбрать определенный поисковый движок. Ввести запрос в омнибокс браузера и поискать дефолтным движком – наиболее простой и распространенный сценарий. Наша задача – предоставить релевантные результаты и встроить вертикали там, где это необходимо.
Но определить, насколько та или иная вертикаль соответствует конкретному запросу не так-то просто. Ведь запрос не всегда полностью отражает потребности пользователя. Проще говоря, мы не можем точно знать, что было у пользователя в голове, когда он этот запрос создавал. Например, если в качестве запроса выступает название банка, трудно сходу сказать, что хотел увидеть пользователь: ссылку на официальный сайт или расположение ближайшего к нему отделения. Бывает, что в запросе присутствует еще более многозначный объект. Допустим, пользователь вбил запрос [Гарри Поттер]. Он мог иметь в виду, как серию книг, так и серию фильмов. И допустим, что один из этих фильмов в данный момент идет в кинотеатрах, а все остальные уже выпущены на дисках. Сходу определить, хотел ли пользователь почитать книгу, заказать билет в кинотеатр, купить диск, посмотреть фильм онлайн или скачать файл с ним, невозможно. Наша задача заключается в том, чтобы определить, какие вертикали соответствуют возможным потребностям и встроить их на страницу выдачи.
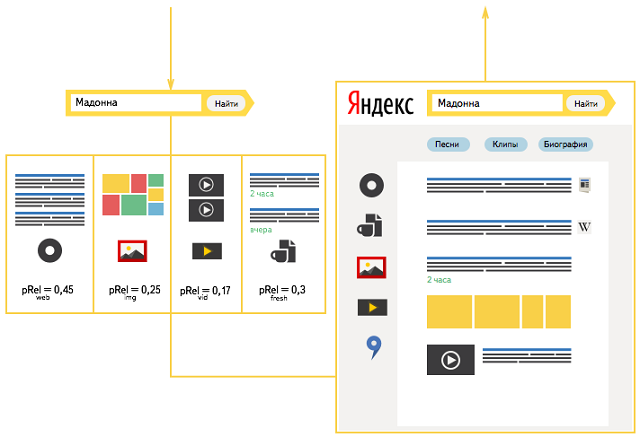
Для начала мы прогоняем запрос через все вертикали. Применяя эвристические алгоритмы, мы отсекаем потребности, которые имеют наименьшую вероятность для каждой конкретной вертикали.
Затем на основе машинного обучения определяем категорию запроса по критерию соответствия конкретным вертикалям. На основе этих категорий у нас появляется возможность предсказывать вероятность того, что вертикаль соответствует запросу.
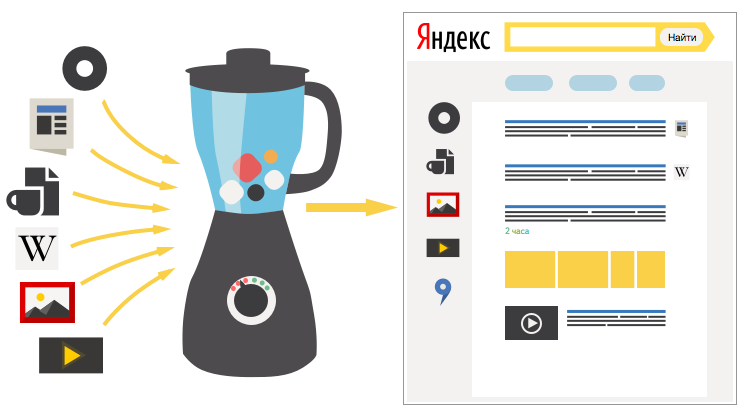
Теперь, когда мы можем определить вероятность потребности для каждой вертикали, нужно произвести ранжирование. У нас есть как достаточно обособленные вертикали с совершенно отдельными алгоритмами ранжирования (картинки, видео), так и небольшие надстройки над веб-поиском, добавляющие новые критерии. Если в качестве потребности выступает тип необходимого пользователю контента, на помощь приходят обособленные вертикали со своим ранжированием. Но бывают запросы, для которых наиболее релевантными оказываются вертикали второго типа: поиски по веб-документам с дополнительными критериями и учетом новых данных. Например, мы можем отранжировать документы по свежести, по цене товара и т.п. Мы можем строить такие вертикали непосредственно над основной веб-базой, предварительно собрав данные, на основе которых будет проводиться ранжирование. Для этого нам требуется следующее:
Если на сайте не используются микроформаты, мы можем применить собственную схему майнинга. Оператор может без труда определить схему майнинга для каждого отдельного сайта, пометить расположение различных характеристик товара: наименование, цену и описание. После разметки все эти характеристики могут быть намайнены. Таким образом, мы можем заметно улучшить качество поиска.
Чтобы определить, насколько качественная выдача получилась для одной потребности, можно использовать метрику pFound. Ее результат будет оценкой вероятности найти релевантный результат в отранжированном списке. Формула метрики выглядит следующим образом:
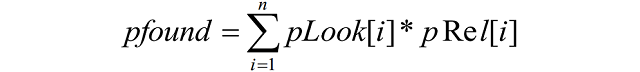
Где pLook[i] – вероятность просмотреть i-й документ из списка, pRel[i] – вероятность того, что i-й документ окажется релевантным. Значения pRel[i] в нашей модели вычисляются из оценок релевантности по запросу. Вероятность просмотра документа рассчитывается при помощи каскадных моделей. В нашем случае пользователь просматривает результаты сверху вниз один за другим. Он продолжает просмотр в случае, если предыдущий вариант оказался неподходящим, и прекращает поисковую сессию с вероятностью pBreak:
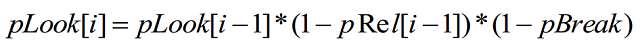
Представить все это в динамике можно следующей схемой:
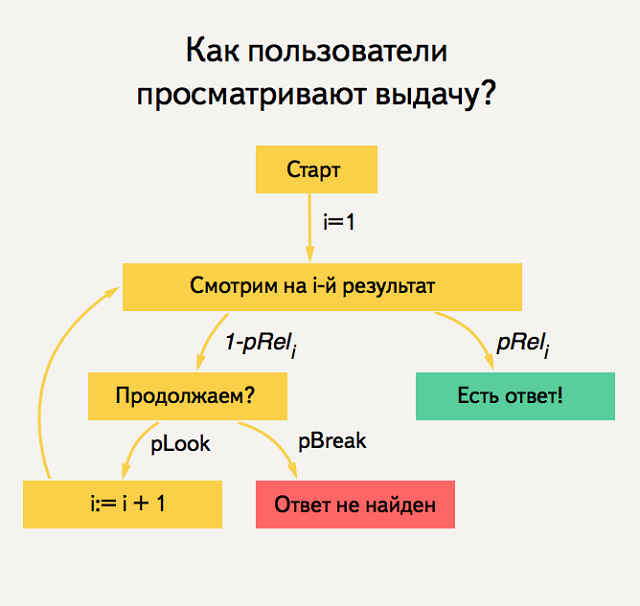
Пользователь просматривает страницу выдачи сверху вниз. С вероятностью pRel он найдет то, что искал и с вероятностью pBreak устанет и уйдет со страницы выдачи.
Блендер же встраивает в поисковую выборку результаты сразу по нескольким вертикалям и потребностям. Соответственно, тут лучше работает метрика wide pFound. Она определяет вероятность того, что пользователь будет удовлетворен ответом на неоднозначный запрос. Wide pFound – это сумма вероятностей потребностей, помноженная на pFound определенной потребности. Иначе говоря, сумма вероятностей того, что пользователь увидит определенный результат, помноженная на вероятность релевантности этого результата.
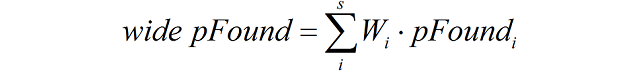
В нашем новом поисковом интерфейсе Острова предусмотрены более широкие возможности взаимодействия с вертикалями. Например, если запросу соответствуют определенные вертикальные поиски, переключаться между ними можно при помощи значков на левой панели. Так мы реализовали идею релевантного интерфейса, динамически отсекающего все ненужные в данный момент элементы.
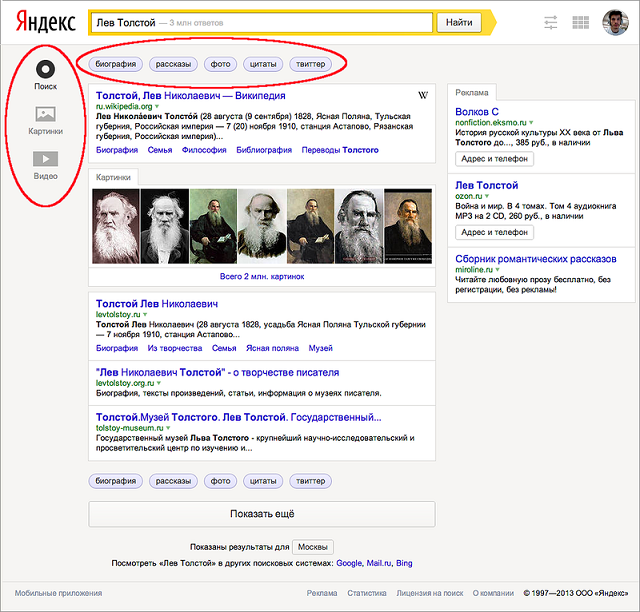
Помимо ссылок на левой панели, вертикальные поиски отображаются в виде блоков на странице основного поиска. Это еще один путь к конкретным вертикальным движкам.
Начать, пожалуй, стоит с того, зачем вообще мы применяем вертикальные поиски. В некоторых случаях поиск по вертикалям бывает гораздо эффективнее стандартного веб-поиска. Например, когда пользователю требуется найти информацию определенного типа (картинки, видео). Некоторые запросы подразумевают другие критерии ранжирования: при поиске по товарам важно иметь возможность производить ранжирование по цене, а в поиске по людям необходимо учитывать дополнительные фильтры. Вертикальные поиски также могут предполагать совершенно иные способы взаимодействия с пользователем, как в случае с навигацией по результатам, отмеченным на карте, при поиске ближайшего магазина, кинотеатра или заправки.
Конечно, с таким запросами лучше всего обращаться в специализированные поисковые сервисы Яндекса: Картинки, Видео, Карты, Музыку. Однако это требует от пользователя дополнительных действий: нужно предварительно вбить адрес или выбрать определенный поисковый движок. Ввести запрос в омнибокс браузера и поискать дефолтным движком – наиболее простой и распространенный сценарий. Наша задача – предоставить релевантные результаты и встроить вертикали там, где это необходимо.
Но определить, насколько та или иная вертикаль соответствует конкретному запросу не так-то просто. Ведь запрос не всегда полностью отражает потребности пользователя. Проще говоря, мы не можем точно знать, что было у пользователя в голове, когда он этот запрос создавал. Например, если в качестве запроса выступает название банка, трудно сходу сказать, что хотел увидеть пользователь: ссылку на официальный сайт или расположение ближайшего к нему отделения. Бывает, что в запросе присутствует еще более многозначный объект. Допустим, пользователь вбил запрос [Гарри Поттер]. Он мог иметь в виду, как серию книг, так и серию фильмов. И допустим, что один из этих фильмов в данный момент идет в кинотеатрах, а все остальные уже выпущены на дисках. Сходу определить, хотел ли пользователь почитать книгу, заказать билет в кинотеатр, купить диск, посмотреть фильм онлайн или скачать файл с ним, невозможно. Наша задача заключается в том, чтобы определить, какие вертикали соответствуют возможным потребностям и встроить их на страницу выдачи.
Определяем потребности

Для начала мы прогоняем запрос через все вертикали. Применяя эвристические алгоритмы, мы отсекаем потребности, которые имеют наименьшую вероятность для каждой конкретной вертикали.
Затем на основе машинного обучения определяем категорию запроса по критерию соответствия конкретным вертикалям. На основе этих категорий у нас появляется возможность предсказывать вероятность того, что вертикаль соответствует запросу.
Теперь, когда мы можем определить вероятность потребности для каждой вертикали, нужно произвести ранжирование. У нас есть как достаточно обособленные вертикали с совершенно отдельными алгоритмами ранжирования (картинки, видео), так и небольшие надстройки над веб-поиском, добавляющие новые критерии. Если в качестве потребности выступает тип необходимого пользователю контента, на помощь приходят обособленные вертикали со своим ранжированием. Но бывают запросы, для которых наиболее релевантными оказываются вертикали второго типа: поиски по веб-документам с дополнительными критериями и учетом новых данных. Например, мы можем отранжировать документы по свежести, по цене товара и т.п. Мы можем строить такие вертикали непосредственно над основной веб-базой, предварительно собрав данные, на основе которых будет проводиться ранжирование. Для этого нам требуется следующее:
- определить тип контента;
- определить его признаки;
- намайнить их значения в документе при помощи микроформатов;
- составить под каждую вертикаль инструкции для асессоров по разметке и релевантности вертикальных позиций.
Если на сайте не используются микроформаты, мы можем применить собственную схему майнинга. Оператор может без труда определить схему майнинга для каждого отдельного сайта, пометить расположение различных характеристик товара: наименование, цену и описание. После разметки все эти характеристики могут быть намайнены. Таким образом, мы можем заметно улучшить качество поиска.
Качество
Чтобы определить, насколько качественная выдача получилась для одной потребности, можно использовать метрику pFound. Ее результат будет оценкой вероятности найти релевантный результат в отранжированном списке. Формула метрики выглядит следующим образом:

Где pLook[i] – вероятность просмотреть i-й документ из списка, pRel[i] – вероятность того, что i-й документ окажется релевантным. Значения pRel[i] в нашей модели вычисляются из оценок релевантности по запросу. Вероятность просмотра документа рассчитывается при помощи каскадных моделей. В нашем случае пользователь просматривает результаты сверху вниз один за другим. Он продолжает просмотр в случае, если предыдущий вариант оказался неподходящим, и прекращает поисковую сессию с вероятностью pBreak:

Представить все это в динамике можно следующей схемой:

Пользователь просматривает страницу выдачи сверху вниз. С вероятностью pRel он найдет то, что искал и с вероятностью pBreak устанет и уйдет со страницы выдачи.
Блендер же встраивает в поисковую выборку результаты сразу по нескольким вертикалям и потребностям. Соответственно, тут лучше работает метрика wide pFound. Она определяет вероятность того, что пользователь будет удовлетворен ответом на неоднозначный запрос. Wide pFound – это сумма вероятностей потребностей, помноженная на pFound определенной потребности. Иначе говоря, сумма вероятностей того, что пользователь увидит определенный результат, помноженная на вероятность релевантности этого результата.

Вертикали в Островах
В нашем новом поисковом интерфейсе Острова предусмотрены более широкие возможности взаимодействия с вертикалями. Например, если запросу соответствуют определенные вертикальные поиски, переключаться между ними можно при помощи значков на левой панели. Так мы реализовали идею релевантного интерфейса, динамически отсекающего все ненужные в данный момент элементы.

Помимо ссылок на левой панели, вертикальные поиски отображаются в виде блоков на странице основного поиска. Это еще один путь к конкретным вертикальным движкам.
