
За последние несколько лет в мире IT появилась модная тенденция – использование всего «облачного» для разработки новых продуктов. Публичных облачных провайдеров не так много, самый популярных среди них – Amazon. Однако многие компании не готовы доверять приватные данные кому-либо, при этом хотят хранить их надежно, и поэтому поднимают частные небольшие облачка.
Любое облако состоит из двух основных компонентов: Единой Точки Входа (ЕТВ) и Облачной Магии (ОМ). Рассмотрим облачное хранилище Amazon S3: в роли ЕТВ используется довольно удобный REST API, а Облачную Магию обеспечивают эльфы, работающие на долларах. Компании, желающие разместить в S3 небольшие видеофайлы или базу данных, предварительно считают на калькуляторе сумму, которую они будут платить в месяц при планируемой нагрузке.
Эта статья про другое облачное хранилище, в котором эльфы питаются Духом Свободы, электричеством и еще им нужно немножечко «кокаина».
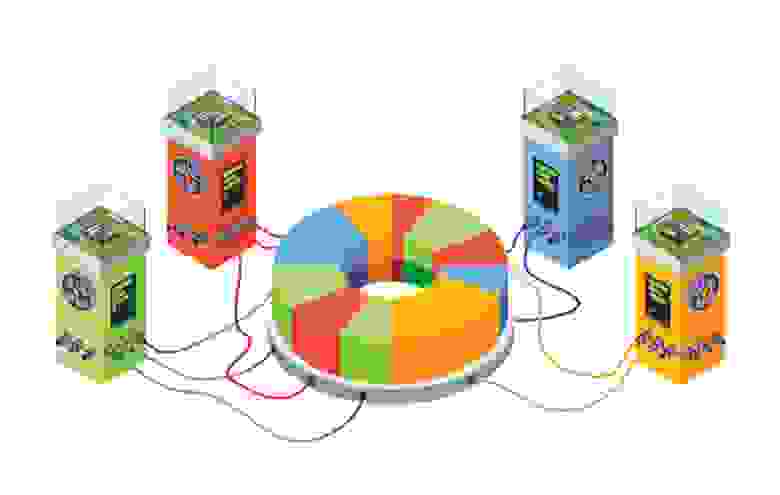
Называется это хранилище Elliptics.
История его создания берет свое начало в далеком 2007 году как части POHMELFS. В следующем году Elliptics был вынесен в отдельный проект, и в нем было перепробовано множество различных подходов к распределенному хранению данных, многие из них не подошли из-за сложности, из-за слишком малой практичности в реальной жизни. В конце концов его автор, Евгений Поляков, пришёл к созданию Elliptics в современном виде.
Это первая из Пяти Стихий, на сохранение которых направлен Elliptics. Машины постоянно ломаются, жесткие диски выходят из строя, а эльфы время от времени устраивают забастовки и кидаются корой. Дата-центр тоже может в любое время выпасть из нашего мира, в силу Черной Магии и Колдовства. Наиболее очевидные из них – это Обрыв Кабеля и Потеря Электричества.

Все уже давно знают, что делать в случае, если отключился диск или сервер. Но никто не задумывается, что будет с их системой, если откажет дата-центр, регион Amazon'а или произойдет иное крупное событие. Elliptics же изначально планировался для решения такого класса проблем.
В Elliptics’е все документы хранятся по 512-битовым ключам, которые получаются как результат sha512-функции от названия документа. Все ключи можно представить в виде Distributed Hash Table (DHT), кольца с диапазоном значений от 0 до 2512. Кольцо случайным образом делится между всеми машинами одной группы, причем каждый ключ может одновременно храниться в нескольких различных группах. Можно приближенно считать, что одна группа – один дата-центр. Как правило, компания Яндекс хранит 3 копии всех документов, и в случае выхода из строя какой-то машины мы теряем лишь одну копию части кольца. Даже при выходе из строя всего дата-центра информация не теряется, у нас все документы остаются еще как минимум в двух копиях, и поэтому эльфы до сих пор могут нести радость людям.
Эльфам-администраторам всегда хотелось иметь возможность подключать дополнительные машины, и Elliptics может это делать! При подключении нового компьютера к группе, он забирает себе случайные интервалы из тех 2512 ключей, и все последующие запросы по этим ключам будут приходить на данную машину.
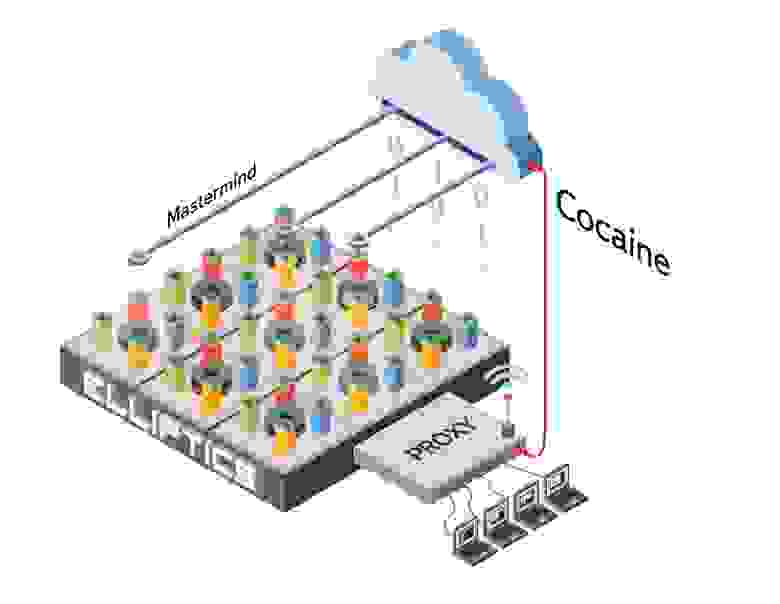
Если у нас есть три группы, состоящие из сотни машин каждая, то добавление новых повлечет за собой ребалансировку и, как следствие, придется большие объемы данных переливать по сети для их восстановления. Для тех, кому это не подходит, мы разработали систему балансировки нагрузки – Mastermind, которая работает на облачной платформе Cocaine. Mastermind – это набор равноправных супер-узлов, которые определяют в каких группах будет храниться тот или иной файл исходя из нагрузки на каждый из серверов. Тут тоже есть непростая Математическая Магия – в расчет принимается свободное место, загруженность дисков, нагрузка на центральный процессор, загрузка свичей, drop rate и многое другое. В случае выхода из строя любого из узлов Mastermind все продолжает работать, как и прежде. Если размер групп поддерживается небольшим, тогда при добавлении новых машин достаточно им выдать новую группу и дать знать об этом Mastermind’у. В этом случае к идентификатору файла добавляется информация о том, в каких группах его следует искать. Этот механизм позволяет обеспечивать поистине бесконечное и очень простое расширение хранилища.
Давайте рассмотрим, что делает система со старыми данными, которые оказались не на тех машинах после балансировки или вообще потерялись.
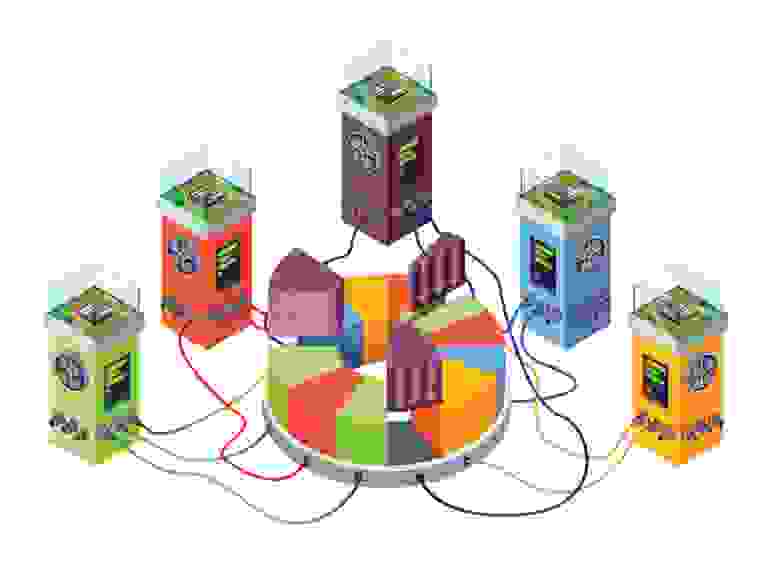
На этот случай в Elliptics предусмотрена система восстановления. Схема ее работы выглядит следующим образом: она проходится по всем машинам и, в случае если данные лежат на не своей машине, перемещает их на нужную. Если окажется, что какой-то документ лежит не в трех копиях, то во время этой процедуры документ будет размножен на нужные машины. При этом если система работает с Mastermind’ом, то номер группы расположения файла берется из мета-информации. Скорость восстановления зависит от многих факторов и нельзя назвать точную скорость восстановления ключей, но, как показывает нагрузочное тестирование, наиболее узким местом является сетевой канал между машинами, который используется для передачи данных.
Elliptics обладает небольшими накладными расходами и способен на одной машине при работе к кэшем выполнять до 240 тысяч операций чтения в секунду. При работе с диском скорость, естественно, падает и упирается в скорость чтения данных с диска.
На основе Elliptics реализован проект HistoryDB. С его помощью мы храним логи, поступающие от различных внешних событий. Во время тестирования, группа из трех машин спокойно и ровно справлялась с нагрузкой в 10 тысяч запросов в секунду, когда писались логи от 30 млн пользователей. При этом 10% из них генерировала 80% всех данных. В сумме на 30 млн пользователей пришлось около 500 млн обновлений каждый день. Однако просто хранить эти данные было бы слишком просто. Поэтому система была протестирована таким образом, что работая под нагрузкой, она позволила получить список всех пользователей, которые были активны в определенный период (день/месяц), посмотреть логи любого пользователя за любой день и имелась возможность добавить любые другие вторичные индексы к пользовательским данным.
Также на основе Elliptics в компании Яндекс построена работа таких сервисов как Яндекс.Музыка, Фотки, Карты, Маркет, вертикальные поиски, поиск по людям, бэкап почты. Готовится к переезду и Яндекс.Диск.
В Elliptics’е клиенты подключаются напрямую к серверам, и это позволяет:
Для пользователей сервиса хранения данных существуют следующие API, с помощью которых можно легко записывать, удалять, читать и обрабатывать данные:
Однако серебряной пули не существует, и у Elliptics существуют свои ограничения и проблемы:
В следующих статьях мы приведем пример использования Elliptics и расскажем больше технических подробностей: внутреннее строение кэша, работа нашего backend’а eblob, стриминг данных, вторичные индексы и многое другое.
Любое облако состоит из двух основных компонентов: Единой Точки Входа (ЕТВ) и Облачной Магии (ОМ). Рассмотрим облачное хранилище Amazon S3: в роли ЕТВ используется довольно удобный REST API, а Облачную Магию обеспечивают эльфы, работающие на долларах. Компании, желающие разместить в S3 небольшие видеофайлы или базу данных, предварительно считают на калькуляторе сумму, которую они будут платить в месяц при планируемой нагрузке.
Эта статья про другое облачное хранилище, в котором эльфы питаются Духом Свободы, электричеством и еще им нужно немножечко «кокаина».
Называется это хранилище Elliptics.
История его создания берет свое начало в далеком 2007 году как части POHMELFS. В следующем году Elliptics был вынесен в отдельный проект, и в нем было перепробовано множество различных подходов к распределенному хранению данных, многие из них не подошли из-за сложности, из-за слишком малой практичности в реальной жизни. В конце концов его автор, Евгений Поляков, пришёл к созданию Elliptics в современном виде.
Отказоустойчивость
Это первая из Пяти Стихий, на сохранение которых направлен Elliptics. Машины постоянно ломаются, жесткие диски выходят из строя, а эльфы время от времени устраивают забастовки и кидаются корой. Дата-центр тоже может в любое время выпасть из нашего мира, в силу Черной Магии и Колдовства. Наиболее очевидные из них – это Обрыв Кабеля и Потеря Электричества.

Одна грустная история
Однажды, во время дождя, одному маленькому котенку стало холодно, и он решил погреться. Поблизости не оказалось ни одного помещения, кроме трансформаторной будки, которая была сделана строго по ГОСТ’у – с проемом снизу сантиметров в 10. Трансформатор закоротило, и одним котенком стало меньше, а дата-центр оказался без электричества. Случилось это в выходной, в субботу, и поэтому штатные электрики не были на рабочем месте и не могли восстановить электроснабжение. Конечно, дизель-генератор имелся и работал, но топлива хватило всего на несколько часов. Служба безопасности отказалась пускать на территорию дата-центра оперативно вызванный бензовоз. В конце концов, все решилось благополучно, но никто не застрахован от подобных ситуаций.
Все уже давно знают, что делать в случае, если отключился диск или сервер. Но никто не задумывается, что будет с их системой, если откажет дата-центр, регион Amazon'а или произойдет иное крупное событие. Elliptics же изначально планировался для решения такого класса проблем.
В Elliptics’е все документы хранятся по 512-битовым ключам, которые получаются как результат sha512-функции от названия документа. Все ключи можно представить в виде Distributed Hash Table (DHT), кольца с диапазоном значений от 0 до 2512. Кольцо случайным образом делится между всеми машинами одной группы, причем каждый ключ может одновременно храниться в нескольких различных группах. Можно приближенно считать, что одна группа – один дата-центр. Как правило, компания Яндекс хранит 3 копии всех документов, и в случае выхода из строя какой-то машины мы теряем лишь одну копию части кольца. Даже при выходе из строя всего дата-центра информация не теряется, у нас все документы остаются еще как минимум в двух копиях, и поэтому эльфы до сих пор могут нести радость людям.
Расширяемость
Эльфам-администраторам всегда хотелось иметь возможность подключать дополнительные машины, и Elliptics может это делать! При подключении нового компьютера к группе, он забирает себе случайные интервалы из тех 2512 ключей, и все последующие запросы по этим ключам будут приходить на данную машину.
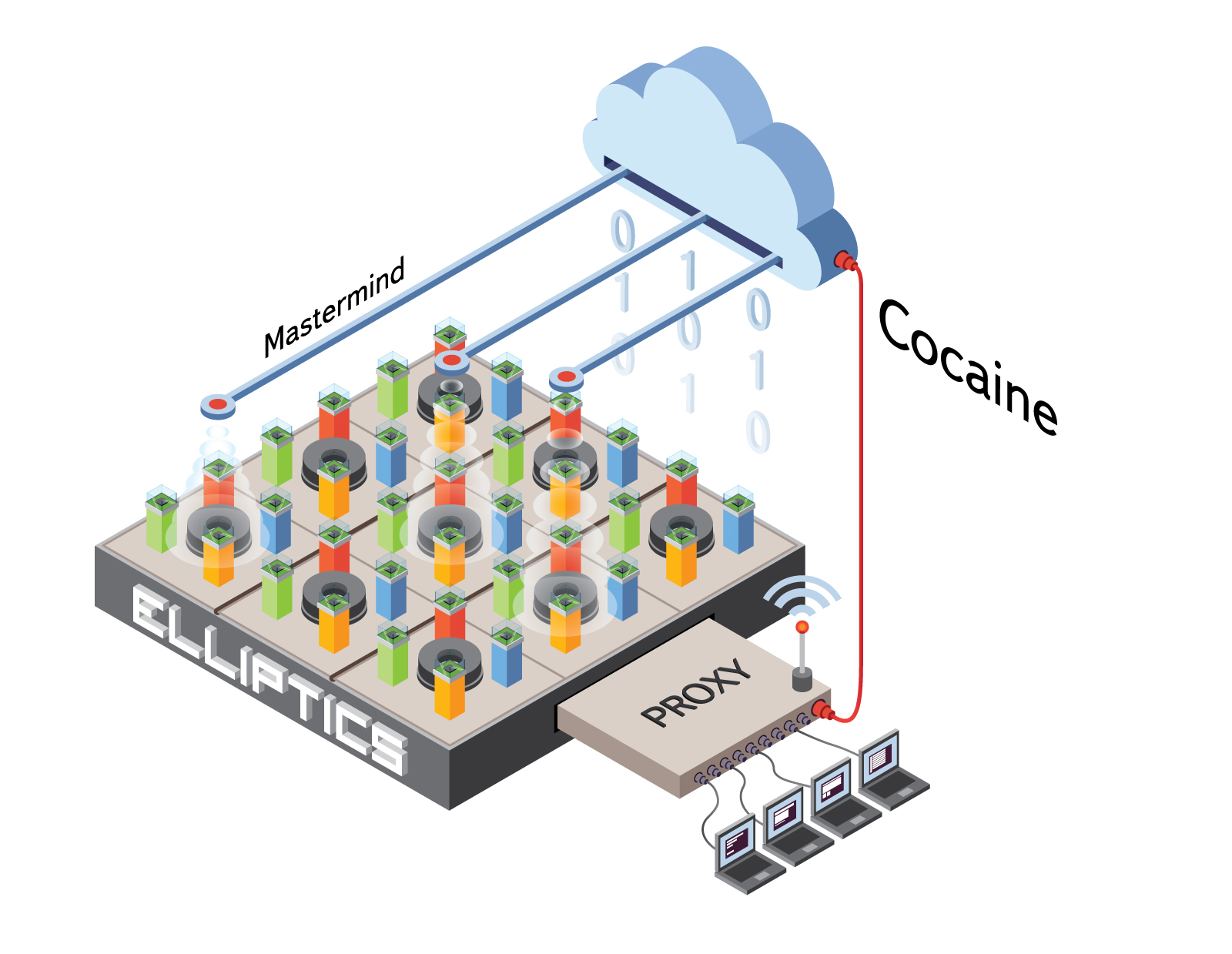
Если у нас есть три группы, состоящие из сотни машин каждая, то добавление новых повлечет за собой ребалансировку и, как следствие, придется большие объемы данных переливать по сети для их восстановления. Для тех, кому это не подходит, мы разработали систему балансировки нагрузки – Mastermind, которая работает на облачной платформе Cocaine. Mastermind – это набор равноправных супер-узлов, которые определяют в каких группах будет храниться тот или иной файл исходя из нагрузки на каждый из серверов. Тут тоже есть непростая Математическая Магия – в расчет принимается свободное место, загруженность дисков, нагрузка на центральный процессор, загрузка свичей, drop rate и многое другое. В случае выхода из строя любого из узлов Mastermind все продолжает работать, как и прежде. Если размер групп поддерживается небольшим, тогда при добавлении новых машин достаточно им выдать новую группу и дать знать об этом Mastermind’у. В этом случае к идентификатору файла добавляется информация о том, в каких группах его следует искать. Этот механизм позволяет обеспечивать поистине бесконечное и очень простое расширение хранилища.
Сохранность данных
Давайте рассмотрим, что делает система со старыми данными, которые оказались не на тех машинах после балансировки или вообще потерялись.

На этот случай в Elliptics предусмотрена система восстановления. Схема ее работы выглядит следующим образом: она проходится по всем машинам и, в случае если данные лежат на не своей машине, перемещает их на нужную. Если окажется, что какой-то документ лежит не в трех копиях, то во время этой процедуры документ будет размножен на нужные машины. При этом если система работает с Mastermind’ом, то номер группы расположения файла берется из мета-информации. Скорость восстановления зависит от многих факторов и нельзя назвать точную скорость восстановления ключей, но, как показывает нагрузочное тестирование, наиболее узким местом является сетевой канал между машинами, который используется для передачи данных.
Скорость
Elliptics обладает небольшими накладными расходами и способен на одной машине при работе к кэшем выполнять до 240 тысяч операций чтения в секунду. При работе с диском скорость, естественно, падает и упирается в скорость чтения данных с диска.
На основе Elliptics реализован проект HistoryDB. С его помощью мы храним логи, поступающие от различных внешних событий. Во время тестирования, группа из трех машин спокойно и ровно справлялась с нагрузкой в 10 тысяч запросов в секунду, когда писались логи от 30 млн пользователей. При этом 10% из них генерировала 80% всех данных. В сумме на 30 млн пользователей пришлось около 500 млн обновлений каждый день. Однако просто хранить эти данные было бы слишком просто. Поэтому система была протестирована таким образом, что работая под нагрузкой, она позволила получить список всех пользователей, которые были активны в определенный период (день/месяц), посмотреть логи любого пользователя за любой день и имелась возможность добавить любые другие вторичные индексы к пользовательским данным.

Также на основе Elliptics в компании Яндекс построена работа таких сервисов как Яндекс.Музыка, Фотки, Карты, Маркет, вертикальные поиски, поиск по людям, бэкап почты. Готовится к переезду и Яндекс.Диск.
Простота архитектуры
В Elliptics’е клиенты подключаются напрямую к серверам, и это позволяет:
- иметь простую архитектуру;
- гарантировать, что транзакции выполняются корректно;
- всегда знать, какая машина в группе отвечает за тот или иной ключ.
Для пользователей сервиса хранения данных существуют следующие API, с помощью которых можно легко записывать, удалять, читать и обрабатывать данные:
- асинхронная библиотека на C++ 11
- биндинг на Python
- HTTP-фронтенды на основе FastCGI и TheVoid (используя boost::asio)
Однако серебряной пули не существует, и у Elliptics существуют свои ограничения и проблемы:
- Eventual consistency. Так как Elliptics полностью распределен, то при различных неполадках сервер может отдать версию файла старее, чем актуальная. В некоторых случаях это может быть неприменимо, тогда за счет проседания времени ответа можно использовать более надежные способы запроса данных.
- Из-за того, что данные клиентом пишутся параллельно на несколько серверов, сеть между клиентом и серверами может стать узким местом.
- API может быть недостаточно удобен для высокоуровневых запросов. На данный момент мы не предоставляем удобных SQL-like запросов к данным.
- Так же в Elliptics нет высокоуровневой поддержки транзакций, поэтому невозможно гарантировать, что группа команд либо выполнится вся, либо не выполнится вообще.
В следующих статьях мы приведем пример использования Elliptics и расскажем больше технических подробностей: внутреннее строение кэша, работа нашего backend’а eblob, стриминг данных, вторичные индексы и многое другое.
