
В докладе рассказывается о том, как мы извлекаем сущности (например, имена людей и географические названия) из текстов и запросов. А также об извлечении фактов, т.е. связей между объектами. Мы рассмотрим несколько подходов к решению этих задач: формулирование правил, составление словарей всевозможных объектов, машинное обучение.
Лекция рассчитана на старшеклассников — студентов Малого ШАДа, но и взрослые смогут с ее помощью восполнить некоторые пробелы.
http://video.yandex.ru/users/e1coyot/view/4/
Извлечение объектов и фактов из текстов – это часть NLP (Natural Language Processing – автоматическая обработка естественного языка). Конечная цель – научить машину полноценно понимать обычный человеческий текст. И движение к этой цели мы пока только начали.
Сегодня NLP успешно применяется для нескольких целей:
Извлечение структурированной информации из неструктурированного текста называется Text Mining. Основная часть этого процесса посвящена определению объектов, их отношениям и свойствам в тестах. Text Mining можно условно разделить на несколько крупных задач:
Итак, для начала разметим в тексте именованные сущности. В примере красным выделены названия компаний, а зеленым – имена людей. Это выделение соответсвует желаемому поведению алгоритма. После чего можно переходить к разрешению кореференции.

Кореференция – это попытка связать несколько разных отсылок в тексте к одному реальному объекту.

Одним из примеров кореференции является анафора – отсылка к объекту при помощи специальных указателей. В нашем случае – это местоимения.
Второй пример кореференции – это синонимия. Она может быть выражена по-разному:
Кореференцию нужно обязательно учитывать при анализе текста, чтобы избежать извлечения лишних фактов и сущностей, не имеющих привязки к реальным объектам.
Факты можно представить как строки в таблице, в столбцах которых находятся объекты и отношения между ними. Результат процесса извлечения фактов выглядит примерно следующим образом:

Мы обычно применяем IE для извлечения следующих типов объектов: даты, адреса, телефоны, ФИО, названия товаров, компаний и т.п. Полезными фактами чаще всего являются события, мнения и отзывы, контактные данные и объявления.
Итак, на входе у нас текст на естественном языке. Анализировать его необходимо сразу на всех лингвистических уровнях:
Текст делится на абзацы, предложения, слова. Затем слова нормализуются – выделяется их начальная форма. Далее проводится полный или частичный синтаксический разбор, определяются зависимости и связи между словами в предложениях.
На первый взгляд кажется, что разбить текст на предложения не составляет никакого труда. Нужно просто ориентироваться на знаки препинания, маркирующие конец предложения. Но работает этот метод далеко не всегда. Ведь, например, точка может обозначать и сокращение, использоваться в дробных числах или URL. Любой знак препинания может использоваться в названиях компаний или сервисов. Например, Yahoo! Или Яндекс.Маркет.
С выделением начальной формы тоже не все так просто. Конечно, в большинстве случаев ее можно получить при помощи морфологического словаря. Но применимо это далеко не всегда. Например, как определить словарную форму слова «стекло»? Это может быть как существительное, так и глагол. И прежде чем обращаться к морфологическому словарю, нужно снять омонимию. Решается эта при помощи корпуса языка, в котором все слова размечены по частям речи, и омонимия снята. Таким образом, основываясь на контексте, и статистике употребления слова в корпусе, можно принять решение, к какой же части речи относится то или иное слово.
Следующий этап — полный или частичный синтаксический разбор. Выстраивается граф зависимостей и отношений между словами внутри предложения. Вот пример синтаксического дерева, которое можно построить при помощи синтаксического парсера:
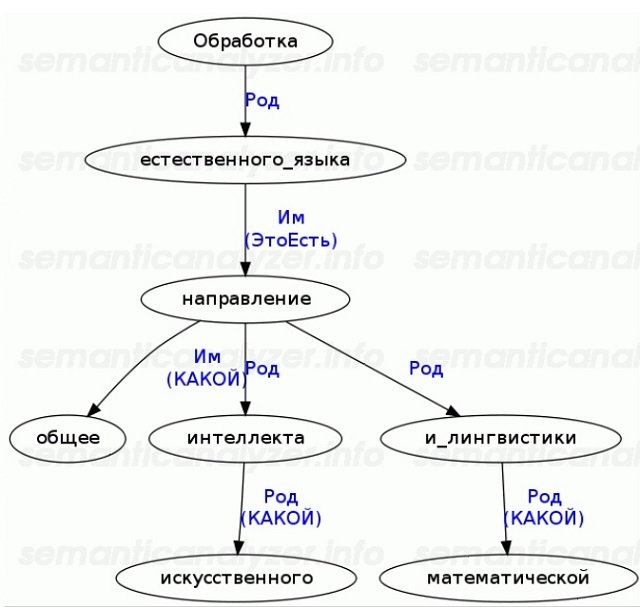
Алгоритмов, которые в любых условиях могут построить полный синтаксический граф без ошибок не существует. Однако для большинства прикладных задач Text Mining достаточно и частичного разбора.
Помимо морфологической омонимии, о которой мы говорили выше, бывает также синтаксическая и «объектная» омонимия. В качестве примера синтаксической омонимии приведем пример: «Он видел их семью своими глазами». Оба варианта прочтения будут синтаксически верны: кто-то видел чью-то семью своими глазами, либо некто семиглазый кого-то видел. Для решения такой проблемы нужно привлекать уже семантический анализ.
«Объектная» омонимия предполагает, что у двух различных реальных объектов могут быть одинаковые наименования. Например, в России есть сразу два известных человека по имени Михаил Задорнов: юморист и бывший министр финансов. Если не научить систему различать этих людей, при попытке извлечения фактов о них, могут возникать разнообразные казусы.
Когда все эти шаги пройдены, можно переходить непосредственно к извлечению фактов. При помощи специальных алгоритмов мы хотим получить из неструктурированного отрывка текст, в котором все нужные нам объекты и факты будут размечены и категорированы. Наглядно представить это можно следующим образом:

Условно можно выделить три основных подхода, применяющихся в извлечении фактов:
В нашем случае онтологии — это «концептуальные словари», представляющие собой структуры, в которых описываются некоторые понятия и/или объекты, отношения между ними, а также их характеристики.
Онтологии могут быть универсальными (в них предпринимается попытка описать максимально широкий набор объектов), отраслевые (с информацией по предметным областям) и узкоспециализированные (предназначенные для решения конкретной задачи). Также могут применяться онтологии объектов (базы знаний). Наиболее яркий пример базы знаний — это Википедия.
Итак, у нас есть некая онтология. Опираясь на контексты и уже имеющиеся списки объектов можно строить гипотезы по отношению к объектам и фактам в тексте, а далее верифицировать или отклонять эти гипотезы. Слева приведен текст, в котором цветом размечены объекты, о которых хотелось бы извлечь какую-нибудь информацию. В качестве онтологии применим Википедию. Отправляя туда запросы по всем ключевым словам из нашего текста, мы получим список статей, расположенный справа. Красным в нем помечены статьи, относящиеся сразу к нескольким объектам.

Теперь наша цель — отсечь неверные гипотезы. Сделать это можно разными способами. Чаще всего применяется машинное обучение, различные контекстные и синтаксические факторы.
Извлечение информации с помощью онтологий позволяет получить достаточно высокую точность NER и отсутствие случайных срабатываний. Снятие омонимии также происходит с высокой точностью. К недостаткам этого подхода можно отнести низкую полноту, ведь извлечь можно только то, что уже есть в онтологии. А в онтологию нужно либо добавлять объекты руками, либо выстраивать процедуру автоматического добавления.
Другой подход — машинное обучение — требует большого объема вводных данных. Нужно максимально покрыть лингвистической информацией обучающую выборку текстов: разметить всю морфологию, синтаксис, семантику, онтологические связи. Плюсы этого подхода в том он не требует ручного труда помимо создания размеченного корпуса. Не нужно составлять правила или онтологии. При необходимости такая система легко перенастраивается и переобучается. Правила получаются более абстрактными. Однако есть и минусы. Инструменты для автоматической разметки русскоязычных текстов пока не очень развиты, а существующие не всегда легко доступны. Корпуса должны быть достаточно объемными, размечены верно, единообразно и полностью. А это достаточно трудоемкий процесс. Кроме того, если что-то пошло не так, сложно отследить, где именно возникла ошибка, и точечно ее исправить.
Третий подход – подход, основанный на правилах, т.е. написание шаблонов вручную. Аналитик составляет описания типов информации, которые необходимо извлечь. Подход удобен тем, что если в результатах анализ обнаруживаются ошибки, очень просто найти их причину и внести необходимые изменения в правила. Проще всего составляются правила для относительно стандартизированных объектов: имен, дат, наименований компаний и т.п.
Выбор оптимального подхода определяется конкретной задачей. Сейчас чаще всего применяются онтологии и машинное обучение, однако, будущее за гибридными системами.
В Яндексе NER используется для извлечения фактов в почте, названий географических объектов и имен из запросов, фактов в вакансиях, а также для кластеризации и классификации новостей.
Лекция рассчитана на старшеклассников — студентов Малого ШАДа, но и взрослые смогут с ее помощью восполнить некоторые пробелы.
http://video.yandex.ru/users/e1coyot/view/4/
Извлечение объектов и фактов из текстов – это часть NLP (Natural Language Processing – автоматическая обработка естественного языка). Конечная цель – научить машину полноценно понимать обычный человеческий текст. И движение к этой цели мы пока только начали.
Сегодня NLP успешно применяется для нескольких целей:
- Текстовый поиск
- Извлечение фактов
- Диалоговые системы и Question Answering
- Синтез и распознавание речи
- Оценка тональности отзывов
- Кластеризация и классификация текстов.
Извлечение структурированной информации из неструктурированного текста называется Text Mining. Основная часть этого процесса посвящена определению объектов, их отношениям и свойствам в тестах. Text Mining можно условно разделить на несколько крупных задач:
- Named Entity Recognition (NER) – извлечение именованных сущностей/объектов;
- Co-reference resolution – разрешение кореференции;
- Information Extraction (IE) – извлечение фактов.
Итак, для начала разметим в тексте именованные сущности. В примере красным выделены названия компаний, а зеленым – имена людей. Это выделение соответсвует желаемому поведению алгоритма. После чего можно переходить к разрешению кореференции.

Кореференция – это попытка связать несколько разных отсылок в тексте к одному реальному объекту.

Одним из примеров кореференции является анафора – отсылка к объекту при помощи специальных указателей. В нашем случае – это местоимения.
Второй пример кореференции – это синонимия. Она может быть выражена по-разному:
- Транслитерация: Yandex – Яндекс.
- Аббревиация: ВТБ – Внешторгбанк – Банк Внешней Торговли.
- Синонимы: больница – госпиталь.
- Словообразование: Москва – московский.
- Графические: авто кредит – автокредит.
Кореференцию нужно обязательно учитывать при анализе текста, чтобы избежать извлечения лишних фактов и сущностей, не имеющих привязки к реальным объектам.
Факты можно представить как строки в таблице, в столбцах которых находятся объекты и отношения между ними. Результат процесса извлечения фактов выглядит примерно следующим образом:

Мы обычно применяем IE для извлечения следующих типов объектов: даты, адреса, телефоны, ФИО, названия товаров, компаний и т.п. Полезными фактами чаще всего являются события, мнения и отзывы, контактные данные и объявления.
Первичная обработка текста
Итак, на входе у нас текст на естественном языке. Анализировать его необходимо сразу на всех лингвистических уровнях:
- графематическом.
- лексическом
- морфологическом
- синтаксическом
- семантическом
Текст делится на абзацы, предложения, слова. Затем слова нормализуются – выделяется их начальная форма. Далее проводится полный или частичный синтаксический разбор, определяются зависимости и связи между словами в предложениях.
На первый взгляд кажется, что разбить текст на предложения не составляет никакого труда. Нужно просто ориентироваться на знаки препинания, маркирующие конец предложения. Но работает этот метод далеко не всегда. Ведь, например, точка может обозначать и сокращение, использоваться в дробных числах или URL. Любой знак препинания может использоваться в названиях компаний или сервисов. Например, Yahoo! Или Яндекс.Маркет.
С выделением начальной формы тоже не все так просто. Конечно, в большинстве случаев ее можно получить при помощи морфологического словаря. Но применимо это далеко не всегда. Например, как определить словарную форму слова «стекло»? Это может быть как существительное, так и глагол. И прежде чем обращаться к морфологическому словарю, нужно снять омонимию. Решается эта при помощи корпуса языка, в котором все слова размечены по частям речи, и омонимия снята. Таким образом, основываясь на контексте, и статистике употребления слова в корпусе, можно принять решение, к какой же части речи относится то или иное слово.
Следующий этап — полный или частичный синтаксический разбор. Выстраивается граф зависимостей и отношений между словами внутри предложения. Вот пример синтаксического дерева, которое можно построить при помощи синтаксического парсера:
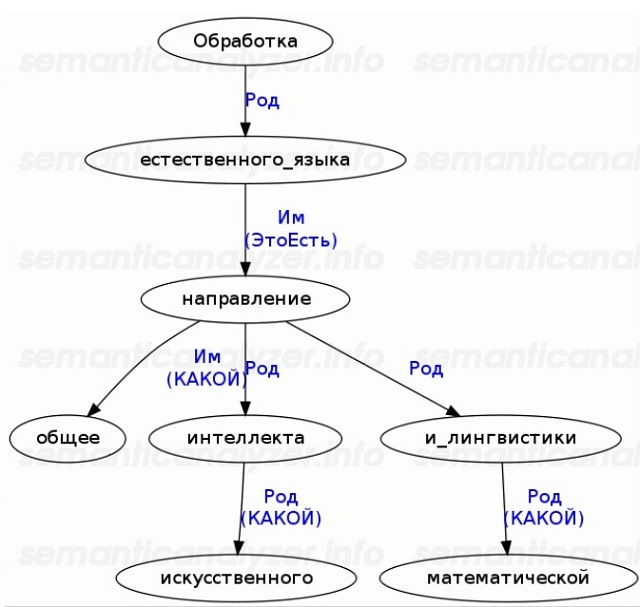
Алгоритмов, которые в любых условиях могут построить полный синтаксический граф без ошибок не существует. Однако для большинства прикладных задач Text Mining достаточно и частичного разбора.
Помимо морфологической омонимии, о которой мы говорили выше, бывает также синтаксическая и «объектная» омонимия. В качестве примера синтаксической омонимии приведем пример: «Он видел их семью своими глазами». Оба варианта прочтения будут синтаксически верны: кто-то видел чью-то семью своими глазами, либо некто семиглазый кого-то видел. Для решения такой проблемы нужно привлекать уже семантический анализ.
«Объектная» омонимия предполагает, что у двух различных реальных объектов могут быть одинаковые наименования. Например, в России есть сразу два известных человека по имени Михаил Задорнов: юморист и бывший министр финансов. Если не научить систему различать этих людей, при попытке извлечения фактов о них, могут возникать разнообразные казусы.
Извлечение фактов
Когда все эти шаги пройдены, можно переходить непосредственно к извлечению фактов. При помощи специальных алгоритмов мы хотим получить из неструктурированного отрывка текст, в котором все нужные нам объекты и факты будут размечены и категорированы. Наглядно представить это можно следующим образом:

Условно можно выделить три основных подхода, применяющихся в извлечении фактов:
- по онтологиям;
- опираясь на правила (Rule-based);
- опираясь на машинное обучение (ML).
В нашем случае онтологии — это «концептуальные словари», представляющие собой структуры, в которых описываются некоторые понятия и/или объекты, отношения между ними, а также их характеристики.
Онтологии могут быть универсальными (в них предпринимается попытка описать максимально широкий набор объектов), отраслевые (с информацией по предметным областям) и узкоспециализированные (предназначенные для решения конкретной задачи). Также могут применяться онтологии объектов (базы знаний). Наиболее яркий пример базы знаний — это Википедия.
Итак, у нас есть некая онтология. Опираясь на контексты и уже имеющиеся списки объектов можно строить гипотезы по отношению к объектам и фактам в тексте, а далее верифицировать или отклонять эти гипотезы. Слева приведен текст, в котором цветом размечены объекты, о которых хотелось бы извлечь какую-нибудь информацию. В качестве онтологии применим Википедию. Отправляя туда запросы по всем ключевым словам из нашего текста, мы получим список статей, расположенный справа. Красным в нем помечены статьи, относящиеся сразу к нескольким объектам.

Теперь наша цель — отсечь неверные гипотезы. Сделать это можно разными способами. Чаще всего применяется машинное обучение, различные контекстные и синтаксические факторы.
Извлечение информации с помощью онтологий позволяет получить достаточно высокую точность NER и отсутствие случайных срабатываний. Снятие омонимии также происходит с высокой точностью. К недостаткам этого подхода можно отнести низкую полноту, ведь извлечь можно только то, что уже есть в онтологии. А в онтологию нужно либо добавлять объекты руками, либо выстраивать процедуру автоматического добавления.
Другой подход — машинное обучение — требует большого объема вводных данных. Нужно максимально покрыть лингвистической информацией обучающую выборку текстов: разметить всю морфологию, синтаксис, семантику, онтологические связи. Плюсы этого подхода в том он не требует ручного труда помимо создания размеченного корпуса. Не нужно составлять правила или онтологии. При необходимости такая система легко перенастраивается и переобучается. Правила получаются более абстрактными. Однако есть и минусы. Инструменты для автоматической разметки русскоязычных текстов пока не очень развиты, а существующие не всегда легко доступны. Корпуса должны быть достаточно объемными, размечены верно, единообразно и полностью. А это достаточно трудоемкий процесс. Кроме того, если что-то пошло не так, сложно отследить, где именно возникла ошибка, и точечно ее исправить.
Третий подход – подход, основанный на правилах, т.е. написание шаблонов вручную. Аналитик составляет описания типов информации, которые необходимо извлечь. Подход удобен тем, что если в результатах анализ обнаруживаются ошибки, очень просто найти их причину и внести необходимые изменения в правила. Проще всего составляются правила для относительно стандартизированных объектов: имен, дат, наименований компаний и т.п.
Выбор оптимального подхода определяется конкретной задачей. Сейчас чаще всего применяются онтологии и машинное обучение, однако, будущее за гибридными системами.
В Яндексе NER используется для извлечения фактов в почте, названий географических объектов и имен из запросов, фактов в вакансиях, а также для кластеризации и классификации новостей.
