
Мы в Яндекс.Почте совместно с командой Nginx провели исследование, чтобы на живом примере с подробностями расставить точки над «ё» в вопросе о том, насколько и за счет чего SPDY ускоряет интернет.
Про сам SPDY вы, конечно, знаете. В 2011 году несколько разработчиков компании Google опубликовали черновик нового протокола, призванного стать заменой привычному HTTP. Его основные отличия заключались в мультиплексировании ответов, сжатии заголовков и приоритизации трафика. Первые несколько версий были не вполне удачными, но к 2012 году спецификация устоялась, появились первые альтернативные (не из Google) реализации, доля поддержки в браузерах достигла 80%, вышла стабильная версия nginx с поддержкий SPDY.

Мы поняли, что, судя по всему, протокол из многообещающей перспективы превращается в хорошее отлаженное решение и начали полноценный цикл работ по внедрению. Начали, естественно, с тестирования. Очень хотелось без него поверить в дифирамбы, опубликованные в блогосфере, но этого в проектах с миллионами пользователей делать нельзя. Мы должны были получить подтверждение, что SPDY действительно даёт ускоряющий эффект.
Есть много интересных исследований вокруг SPDY, в том числе самого Google. Компания-автор протокола показывала, что в их случае SPDY ускоряет загрузку на 40%. Исследование протокола SPDY проводила и компания Opera. Но ни методик подсчета, ни примеров страниц, на которых были достигнуты столь впечатляющие результаты, в этих исследованиях не было.
Протокол SPDY довольно сложный и рассказать о нём непросто. Попробуем наглядно описать, как он работает.
Представим себе веб-страницу, на которой подключены несколько JavaScript- и CSS-файлов. Браузер открывает несколько соединений с сервером и начинает параллельно эти файлы с сервера загружать. Если на сервере включен HTTPS, — а как известно, Яндекс.Почта работает по HTTPS, — для каждого соединения необходимо сделать SSL-handshake, то есть браузеру и серверу нужно обменяться ключами, которыми они будут шифровать передаваемые данные. На это как серверу, так и браузеру необходимо потратить определенное время и ресурсы процессора.
Протокол SPDY призван сократить время — за счет того, что в нем необходимо установить всего одно соединение с сервером, а значит, и handshake необходим всего один. В итоге для загрузки статики браузер устанавливает соединение с сервером и сразу последовательно, не ожидая ответа, отправляет запросы за всеми необходимыми скриптами.
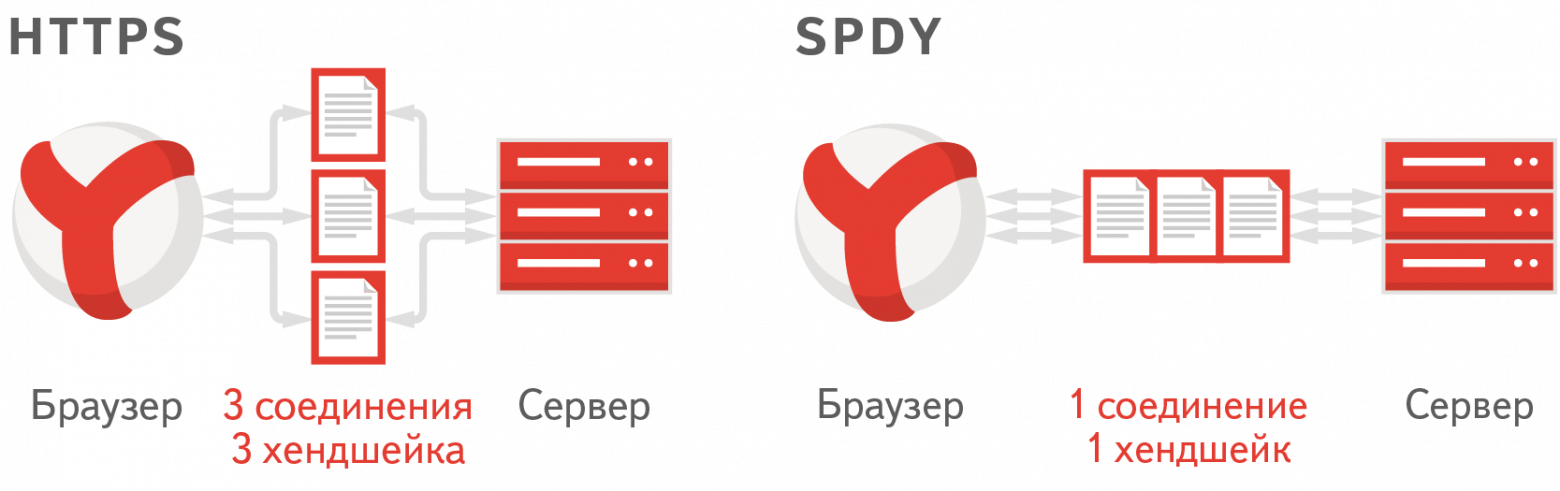
После этого сервер начинает последовательно эти файлы отдавать.
В нашей почте используется очень много статики. В минимизированном виде в сумме это около 500 мегабайт ресурсов для всех тем оформлений и всех страниц. Это и css и js файлы, и картинки. Из-за большого объема необходимой статики время первой загрузки не молниеносное.
Эту статику мы раздаем пользователям с почти 200 серверов, расположенных в Москве и CDN по всей России и за ее пределами. В качестве сервера мы используем Nginx, так как считаем, что это самый быстрый и надежный из существующих веб-серверов, способных раздавать статику. В прошлом году команда Nginx анонсировала свою реализацию протокола SPDY версии 2 в виде модуля. И мы начали пробовать раздавать статику с помощью Nginx и этого модуля в начале 2013 года.
Мы давно беспокоимся о скорости загрузки статики. У нас уже много сделано для того, чтобы пользователю нужно было грузить как можно меньше статики. Во-первых, само собой все js-скрипты и css у нас минимизируются при сборке. Мы контролируем размеры картинок и стараемся не выходить за пределы объема статики, необходимой для работы почты.
Во-вторых, у нас применяется технология так называемого фриза статики. Заключается она в следующем: если содержимое файла не поменялось, то у пользователей нет необходимости его перевыкачивать. Поэтому мы делаем так, что его путь от версии к версии остается неизменным. При сборке верстки этот путь получается вычислением хеш-суммы содержимого файла. Например. Для формирования таких путей мы пользуемся Борщиком.
Сперва мы решили замерить на своих тестовых машинках, насколько мы ускоримся, просто включив SPDY в конфиге. Мы выложили статику на одну физическую машинку, недоступную для пользователей, которая работала под управлением Ubuntu 12.04. На машинке было 12 ядер и 20GB оперативной памяти. Вся статика помещалась в RAM-диске в оперативной памяти.
Судя по этим замерам, мы ускорили почту очень заметно. Примерно так же, как Google ускорился по их замерам. Но мы у себя внутри не могли полностью сэмулировать все особенности загрузки почты, все проблемы сети, packet loss и прочие TTL. Поэтому, для того чтобы понять, не замедлим ли мы кому-нибудь загрузку, мы решили провести эксперимент на наших пользователях.
Среди них всех случайным образом выбрали 10% и разделили их на две группы: первой группе начали отдавать статику через SPDY, а вторая группа была контрольной.
Для первой группы статика грузилась с домена experiment.yandex.st, а для второй — с meth.yandex.st. Необходимость контрольной группы обуславливалась тем, что у всех пользователей Почты статика могла быть закешированной. Поэтому при их переезде на другой домен им пришлось бы статику перевыкачать, а тем, кто не попал в эксперимент, — нет. Сравнение было бы некорректным.
Во всех современных браузерах есть поддержка Navigation Timing API. Это JavaScript-API браузера, который позволяет получать разные данные о времени загрузки. Через него можно с точностью до миллисекунды узнать, когда пользователь перешел на страницу Почты и началась магия с загрузкой статики. Наш клиент-сайд работает таким образом, что он знает момент, когда загружаются все необходимые статические файлы. В наших скриптах мы вычитаем из второго момента первый и получаем время полной загрузки всей статики и отправляем эту цифру на сервер.
Помимо скорости загрузки важным аспектом для нас является количество незагрузок статики. Мы на клиентах проверяем две вещи:
1. Удалось ли вообще получить статический файл. Например, сервер ответил, что такого файла нет. Факт каждой такой незагрузки мы тоже отправляем на сервер и строим график их количества.
2. Пришел ли файл того размера, которого должен был быть. Расскажем об этом типе ошибок подробнее. Мы проверили поведение браузеров в случаях, когда во время передачи файла между сервером и клиентом обрывается соединение. Оказалось, что Firefox, IE и старая Opera передают нам статус 200 и весь недополученный контент. Браузеры не проверяют, что им пришло ровно столько данных, сколько указано в заголовке Content-Length. Но, что еще хуже, IE и Opera при этом кешируют этот недополученный контент, поэтому, пока кеш жив, правильно перевыкачать файл не получится. Firefox, к счастью, при следующем запросе перевыкачивает данные с сервера. Баг, сообщающий об этом неправильном поведении, есть в трекере Mozilla.
По полученным цифрам мы посчитали среднее время загрузки статики, медиану, а так же процентиль 80%. Ускорение по нашим приборам, к сожалению, не преодолело статистической погрешности.
Среднее время загрузки уменьшилось на 0.6%. То есть, несмотря на все заверения Гугла, SPDY как таковой не способен взять и ускорить любой сайт на те безумные 40-50%.
Мы попробовали включить SPDY/2 на mail.yandex.ru. После включения у нас появилось много ошибок в логах и нам пришлось его выключить. В Opera есть неприятный баг, который ввиду того, что ее поддержка уже прекращена, вряд ли починится. Заключается он в том, что Opera при отправке POST-запросов отправляет невалидный заголовок Content-Length. Проблема описана здесь: trac.nginx.org/nginx/ticket/337
Если у вас много посетителей со старыми Операми (12.*) и используются POST-запросы, мы не рекомендуем вам включать SPDY.
UPD: Разработчик SPDY подсказывает в комментариях, что в nginx, начиная с версии 1.5.10, уже реализована третья версия протокола, а поэтому старые Оперы уже не будут использовать SPDY при работе с ним. Поэтому и баг Оперы будет неактуален.
После наших исследований мы пришли к выводу, что SPDY нам ничего не ускорит, а оптимизация загрузки статики, уменьшение ее размера, оптимальное кеширование оказывают гораздо более — на порядки — заметные эффекты в скорости работы интерфейса.
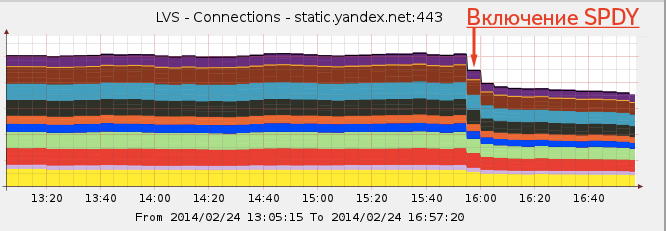
Однако в SPDY мы нашли для себя неожиданный профит. За счет того, что многие клиенты перестали создавать на каждый файл по соединению, этих соединений стало заметно меньше, а значит, наши процессоры стали меньше нагружаться. То есть какая-никакая, а экономия есть.
Вот как включение SPDY выглядело на графике открытых коннектов на наших серверах.
Разницы в количестве ошибок загрузки статики мы не нашли. Это значит, что включение SPDY в Nginx не создает никаких проблем в браузерах, даже в тех, где он не поддерживается.
Мы провели реверс-инжениринг реализации протокола SPDY в nginx и убедились, что он работает ровно так, как задумано. Еще мы попробовали в тестинге раздавать статику через Apache с подключенным модулем SPDY и померить аналогичным образом на синтетических запросах. Мы убедились, что в этом случае ускорение так же составляло совсем незначительную величину.
В итоге мы включили SPDY на всём yandex.st. Пусть оно нам не принесло ускорения в 100500%, но зато сэкономило некоторое количество электроэнергии за счет меньшей нагрузки на процессор :)
Еще одна причина отсутствия ускорения — Nginx сам по себе является невероятно быстрым сервером. Изначально SPDY было реализовано в виде модуля для сервера Apache, а как известно, ему требуется очень много ресурсов для поддержания соединения. Поэтому экономия коннектов в Apache дает заметный профит в его производительности. В Nginx же на поддержание 10 000 неактивных HTTP keep-alive соединений расходуется около 2.5M памяти (источник — nginx.org/ru).
К сожалению, нам не удалось выяснить, каким образом проводил исследование Google в своих измерениях по ускорению SPDY. Поэтому не следует воспринимать результаты нашего исследования как посыл о том, что этот протокол ничего не ускоряет. Наши выводы — это результат исследования частного случая применения SPDY для раздачи статики.
Про сам SPDY вы, конечно, знаете. В 2011 году несколько разработчиков компании Google опубликовали черновик нового протокола, призванного стать заменой привычному HTTP. Его основные отличия заключались в мультиплексировании ответов, сжатии заголовков и приоритизации трафика. Первые несколько версий были не вполне удачными, но к 2012 году спецификация устоялась, появились первые альтернативные (не из Google) реализации, доля поддержки в браузерах достигла 80%, вышла стабильная версия nginx с поддержкий SPDY.

Мы поняли, что, судя по всему, протокол из многообещающей перспективы превращается в хорошее отлаженное решение и начали полноценный цикл работ по внедрению. Начали, естественно, с тестирования. Очень хотелось без него поверить в дифирамбы, опубликованные в блогосфере, но этого в проектах с миллионами пользователей делать нельзя. Мы должны были получить подтверждение, что SPDY действительно даёт ускоряющий эффект.
Есть много интересных исследований вокруг SPDY, в том числе самого Google. Компания-автор протокола показывала, что в их случае SPDY ускоряет загрузку на 40%. Исследование протокола SPDY проводила и компания Opera. Но ни методик подсчета, ни примеров страниц, на которых были достигнуты столь впечатляющие результаты, в этих исследованиях не было.
SPDY. Взгляд изнутри
Протокол SPDY довольно сложный и рассказать о нём непросто. Попробуем наглядно описать, как он работает.
Представим себе веб-страницу, на которой подключены несколько JavaScript- и CSS-файлов. Браузер открывает несколько соединений с сервером и начинает параллельно эти файлы с сервера загружать. Если на сервере включен HTTPS, — а как известно, Яндекс.Почта работает по HTTPS, — для каждого соединения необходимо сделать SSL-handshake, то есть браузеру и серверу нужно обменяться ключами, которыми они будут шифровать передаваемые данные. На это как серверу, так и браузеру необходимо потратить определенное время и ресурсы процессора.
Протокол SPDY призван сократить время — за счет того, что в нем необходимо установить всего одно соединение с сервером, а значит, и handshake необходим всего один. В итоге для загрузки статики браузер устанавливает соединение с сервером и сразу последовательно, не ожидая ответа, отправляет запросы за всеми необходимыми скриптами.
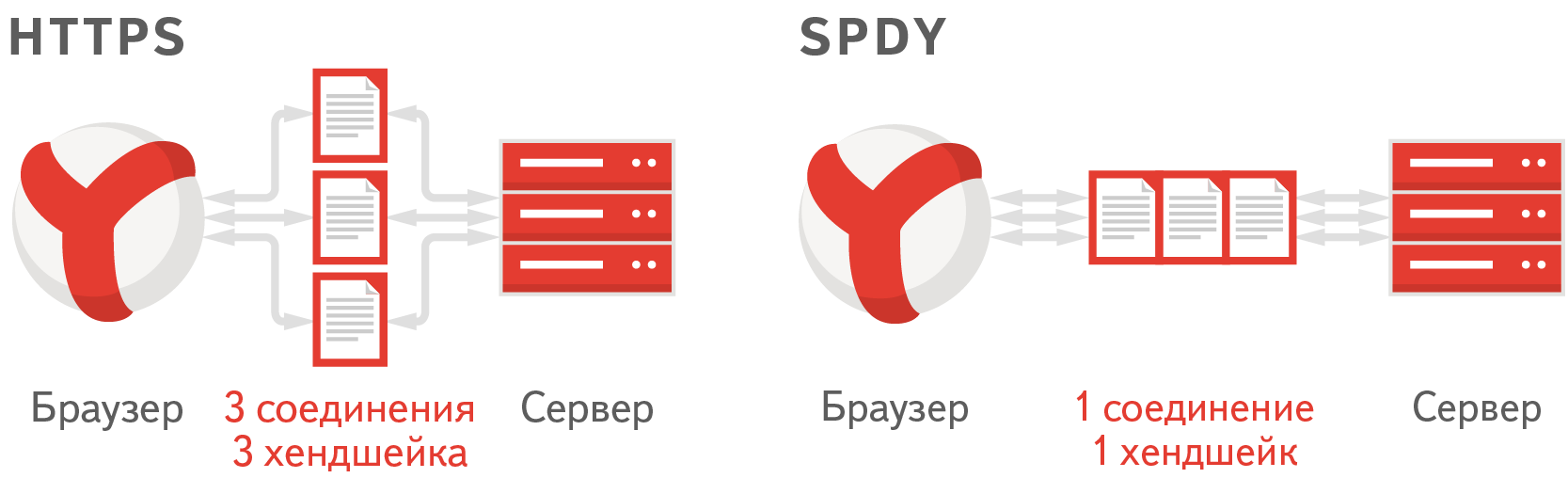
После этого сервер начинает последовательно эти файлы отдавать.
HTTPS
| Connect + TLS-handshake | Connect + TLS-handshake | Connect + TLS-handshake |
|---|---|---|
| > GET /bootstrap.css >… < HTTP/1.1 200 OK <… < body { margin: 0;} |
> GET /jquery.min.js >… < HTTP/1.1 200 OK <… < (function (window, undefined) { <… |
> GET/logo.png >… < HTTP/1.1 200 OK <… < [data] <… |
HTTPS + SPDY
| Connect + TLS-handshake |
|---|
| > GET /bootstrap.css > GET /jquery.js > GET /logo.png < [bootstrap.css content] <… < [jquery.js content] <… < [logo.png content] |
Ускоряем первую загрузку
В нашей почте используется очень много статики. В минимизированном виде в сумме это около 500 мегабайт ресурсов для всех тем оформлений и всех страниц. Это и css и js файлы, и картинки. Из-за большого объема необходимой статики время первой загрузки не молниеносное.
Эту статику мы раздаем пользователям с почти 200 серверов, расположенных в Москве и CDN по всей России и за ее пределами. В качестве сервера мы используем Nginx, так как считаем, что это самый быстрый и надежный из существующих веб-серверов, способных раздавать статику. В прошлом году команда Nginx анонсировала свою реализацию протокола SPDY версии 2 в виде модуля. И мы начали пробовать раздавать статику с помощью Nginx и этого модуля в начале 2013 года.
Текущие оптимизации
Мы давно беспокоимся о скорости загрузки статики. У нас уже много сделано для того, чтобы пользователю нужно было грузить как можно меньше статики. Во-первых, само собой все js-скрипты и css у нас минимизируются при сборке. Мы контролируем размеры картинок и стараемся не выходить за пределы объема статики, необходимой для работы почты.
Во-вторых, у нас применяется технология так называемого фриза статики. Заключается она в следующем: если содержимое файла не поменялось, то у пользователей нет необходимости его перевыкачивать. Поэтому мы делаем так, что его путь от версии к версии остается неизменным. При сборке верстки этот путь получается вычислением хеш-суммы содержимого файла. Например. Для формирования таких путей мы пользуемся Борщиком.
Как мы измеряли время загрузки
Сперва мы решили замерить на своих тестовых машинках, насколько мы ускоримся, просто включив SPDY в конфиге. Мы выложили статику на одну физическую машинку, недоступную для пользователей, которая работала под управлением Ubuntu 12.04. На машинке было 12 ядер и 20GB оперативной памяти. Вся статика помещалась в RAM-диске в оперативной памяти.
Судя по этим замерам, мы ускорили почту очень заметно. Примерно так же, как Google ускорился по их замерам. Но мы у себя внутри не могли полностью сэмулировать все особенности загрузки почты, все проблемы сети, packet loss и прочие TTL. Поэтому, для того чтобы понять, не замедлим ли мы кому-нибудь загрузку, мы решили провести эксперимент на наших пользователях.
Среди них всех случайным образом выбрали 10% и разделили их на две группы: первой группе начали отдавать статику через SPDY, а вторая группа была контрольной.
Для первой группы статика грузилась с домена experiment.yandex.st, а для второй — с meth.yandex.st. Необходимость контрольной группы обуславливалась тем, что у всех пользователей Почты статика могла быть закешированной. Поэтому при их переезде на другой домен им пришлось бы статику перевыкачать, а тем, кто не попал в эксперимент, — нет. Сравнение было бы некорректным.
Метрики
Во всех современных браузерах есть поддержка Navigation Timing API. Это JavaScript-API браузера, который позволяет получать разные данные о времени загрузки. Через него можно с точностью до миллисекунды узнать, когда пользователь перешел на страницу Почты и началась магия с загрузкой статики. Наш клиент-сайд работает таким образом, что он знает момент, когда загружаются все необходимые статические файлы. В наших скриптах мы вычитаем из второго момента первый и получаем время полной загрузки всей статики и отправляем эту цифру на сервер.
Помимо скорости загрузки важным аспектом для нас является количество незагрузок статики. Мы на клиентах проверяем две вещи:
1. Удалось ли вообще получить статический файл. Например, сервер ответил, что такого файла нет. Факт каждой такой незагрузки мы тоже отправляем на сервер и строим график их количества.
2. Пришел ли файл того размера, которого должен был быть. Расскажем об этом типе ошибок подробнее. Мы проверили поведение браузеров в случаях, когда во время передачи файла между сервером и клиентом обрывается соединение. Оказалось, что Firefox, IE и старая Opera передают нам статус 200 и весь недополученный контент. Браузеры не проверяют, что им пришло ровно столько данных, сколько указано в заголовке Content-Length. Но, что еще хуже, IE и Opera при этом кешируют этот недополученный контент, поэтому, пока кеш жив, правильно перевыкачать файл не получится. Firefox, к счастью, при следующем запросе перевыкачивает данные с сервера. Баг, сообщающий об этом неправильном поведении, есть в трекере Mozilla.
Результаты замеров
По полученным цифрам мы посчитали среднее время загрузки статики, медиану, а так же процентиль 80%. Ускорение по нашим приборам, к сожалению, не преодолело статистической погрешности.
Среднее время загрузки уменьшилось на 0.6%. То есть, несмотря на все заверения Гугла, SPDY как таковой не способен взять и ускорить любой сайт на те безумные 40-50%.
Opera 12.16 и Content-Length
Мы попробовали включить SPDY/2 на mail.yandex.ru. После включения у нас появилось много ошибок в логах и нам пришлось его выключить. В Opera есть неприятный баг, который ввиду того, что ее поддержка уже прекращена, вряд ли починится. Заключается он в том, что Opera при отправке POST-запросов отправляет невалидный заголовок Content-Length. Проблема описана здесь: trac.nginx.org/nginx/ticket/337
Если у вас много посетителей со старыми Операми (12.*) и используются POST-запросы, мы не рекомендуем вам включать SPDY.
UPD: Разработчик SPDY подсказывает в комментариях, что в nginx, начиная с версии 1.5.10, уже реализована третья версия протокола, а поэтому старые Оперы уже не будут использовать SPDY при работе с ним. Поэтому и баг Оперы будет неактуален.
Выводы
После наших исследований мы пришли к выводу, что SPDY нам ничего не ускорит, а оптимизация загрузки статики, уменьшение ее размера, оптимальное кеширование оказывают гораздо более — на порядки — заметные эффекты в скорости работы интерфейса.
Однако в SPDY мы нашли для себя неожиданный профит. За счет того, что многие клиенты перестали создавать на каждый файл по соединению, этих соединений стало заметно меньше, а значит, наши процессоры стали меньше нагружаться. То есть какая-никакая, а экономия есть.
Вот как включение SPDY выглядело на графике открытых коннектов на наших серверах.

Разницы в количестве ошибок загрузки статики мы не нашли. Это значит, что включение SPDY в Nginx не создает никаких проблем в браузерах, даже в тех, где он не поддерживается.
Мы провели реверс-инжениринг реализации протокола SPDY в nginx и убедились, что он работает ровно так, как задумано. Еще мы попробовали в тестинге раздавать статику через Apache с подключенным модулем SPDY и померить аналогичным образом на синтетических запросах. Мы убедились, что в этом случае ускорение так же составляло совсем незначительную величину.
В итоге мы включили SPDY на всём yandex.st. Пусть оно нам не принесло ускорения в 100500%, но зато сэкономило некоторое количество электроэнергии за счет меньшей нагрузки на процессор :)
Еще одна причина отсутствия ускорения — Nginx сам по себе является невероятно быстрым сервером. Изначально SPDY было реализовано в виде модуля для сервера Apache, а как известно, ему требуется очень много ресурсов для поддержания соединения. Поэтому экономия коннектов в Apache дает заметный профит в его производительности. В Nginx же на поддержание 10 000 неактивных HTTP keep-alive соединений расходуется около 2.5M памяти (источник — nginx.org/ru).
К сожалению, нам не удалось выяснить, каким образом проводил исследование Google в своих измерениях по ускорению SPDY. Поэтому не следует воспринимать результаты нашего исследования как посыл о том, что этот протокол ничего не ускоряет. Наши выводы — это результат исследования частного случая применения SPDY для раздачи статики.
