
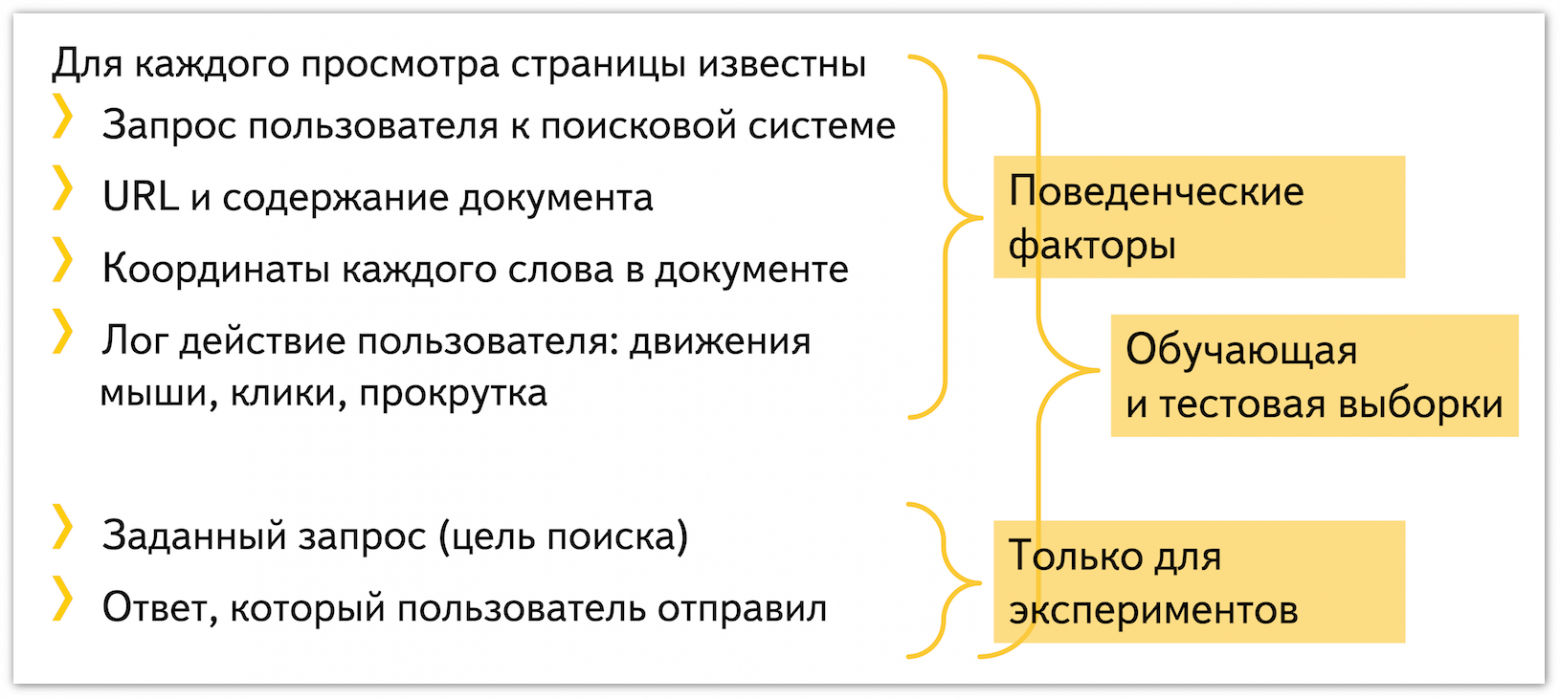
Анализ неявных предпочтений пользователей, выраженных в переходах по ссылкам и длительности просмотра страниц, — важнейший фактор в ранжировании документов в результатах поиска или, например, показе рекламы и рекомендации новостей. Алгоритмы анализа кликов хорошо изучены. Но можно ли узнать что-то ещё об индивидуальных предпочтениях человека, используя больше информации о его поведении на сайте? Оказывается, траектория движения мыши позволяет узнать, какие фрагменты просматриваемого документа заинтересовали пользователя.
Этому вопросу и было посвящено исследование, проведенное мной, Михаилом Агеевым, совместно с Дмитрием Лагуном и Евгением Агиштейном в Emory Intelligent Information Access Lab Университета Эмори.
Мы изучали методы сбора данных и алгоритмы анализа поведения пользователя по движениям мыши, а также возможности применения этих методов на практике. Они позволяют существенно улучшить формирование сниппетов (аннотаций) документов в результатах поиска. Работа с описанием этих алгоритмов была отмечена дипломом «Best Paper Shortlisted Nominee» на международной конференции ACM SIGIR в 2013 году. Позже я представил доклад о результатах проделанной работы в рамках научно-технических семинаров в Яндексе. Его конспект вы найдете под катом.
Сниппеты являются важнейшей частью любой поисковой системы. Они помогают пользователям искать информацию, и от их качества зависит удобство использования поисковой системы. Хороший сниппет должен быть удобочитаемым, должен показывать части документа, которые соответствуют запросу пользователя. В идеале сниппет должен содержать прямой ответ на вопрос пользователя или указание на то, что ответ есть в документе.

Общий принцип состоит в том, что текст запроса сопоставляется с текстом документа, в котором выделяются наиболее релевантные предложения, содержащие слова запроса или расширения запроса. Формула вычисления наиболее релевантных фрагментов учитывает совпадения с запросом. Учитывается плотность текста, местоположение текста, структура документа. Однако для высокорелевантных документов, которые всплывают в верхней части поисковой выдачи, текстовых факторов зачастую недостаточно. В тексте могут многократно встречаться слова из запроса, и определить, какие фрагменты текста отвечают на вопрос пользователя на основе только текстовой информации невозможно. Поэтому требуется привлечение дополнительных факторов.
При просмотре страницы внимание пользователя распространяется неравномерно. Основное внимание уделяется тем фрагментам, которые содержат искомую информацию.
Мы провели эксперименты с применением оборудования, отслеживающего движения глазного зрачка с точностью до нескольких десятков пикселей. Вот пример распределения тепловой карты траектории зрачка пользователя, искавшего ответ на вопрос, сколько битых пикселей должно быть на iPad 3, чтобы его можно было заменить по гарантии. Он вводит запрос [how many dead pixels ipad 3 replace], который приводит его на страницу Apple Community Forums с подобным вопросом. На странице слова из запроса встречаются многократно, однако пользователь заостряет внимание на том фрагменте, который действительно содержит ответ, что и видно на тепловой карте.

Если бы мы могли отслеживать и анализировать движения зрачков большего количества пользователей, мы могли бы только на основании этих данных выделять идеальные сниппеты для различных запросов. Проблема заключается в том, что у пользователей не установлены средства для айтрекинга, поэтому нужно искать другие пути получения необходимой информации.
При просмотре веб-документов пользователи обычно совершают движения мышью, скроллят страницы. В своей статье 2010 года К. Гуо и Е. Агиштейн отмечают, что по траектории можно предсказывать движения глазного зрачка с точностью 150 пикселей и полнотой 70%.

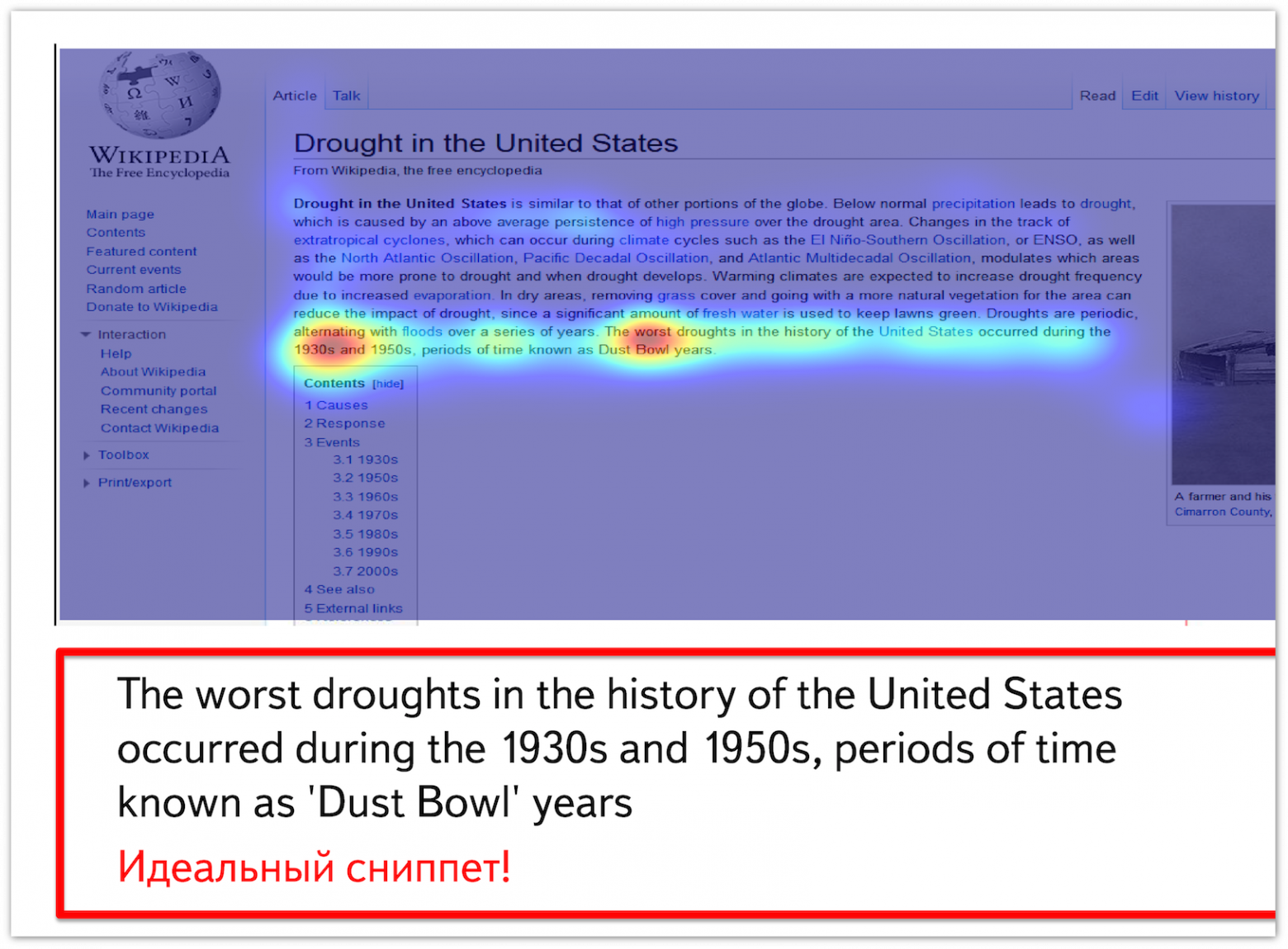
Ниже представлена тепловая карта движений мыши при просмотре документа, найденного по запросу [worst drought in US]. Видно, что наибольшая активность прослеживается именно на фрагменте, содержащем информацию о самых сильных засухах в США, именно из него можно сформировать идеальный сниппет.
Идея нашего исследования состоит в том, что данные о движениях мыши можно собирать при помощи JavaScript API, работающего в большинстве браузеров. По поведению пользователей мы можем предсказывать, какие фрагменты содержат релевантную запросу информацию, и затем использовать эти данные для улучшения качества сниппетов. Для того, чтобы реализовать и проверить эту идею, нужно решить несколько задач. Во-первых, нужно понять, как собрать реалистичные и достаточно масштабные данные о поведении пользователей за страницей результатов поиска. Во-вторых, нужно научиться по движениям мыши определять наиболее заинтересовавшие пользователя фрагменты. У пользователей есть разные привычки: некоторые любят выделять читаемый текст или просто наводят на него мышь, другие же открывают документ и читают его сверху вниз, изредка пролистывая его вниз. При этом у пользователей могут быть разные браузеры и устройства ввода. Кроме того, объем данных о движениях мыши на два порядка выше объема данных о кликах. Также стоит задача объединения поведенческих факторов с традиционными текстовыми.
Для сбора данных мы использовали инфраструктуру, разработанную нами в 2011. Основная идея – создать игру, подобную кубку Яндекса по поиску. Игроку ставится цель за ограниченное время при помощи поисковой системы найти в интернете ответ на поставленный вопрос. Игрок находит ответ и отправляет его нам вместе с URL страницы, где он был обнаружен. Отбор участников происходит через Amazon Mechanical Turk. Каждая игра состоит из 12 вопросов. За участие в игре длиной примерно сорок минут предполагается гарантированная оплата в $1. Еще по одному доллару получают 25% лучших игроков. Это достаточно дешевый способ сбора данных, который при этом дает большое разнообразие пользователей с разных концов мира. Вопросы брались на сайтах Wiki.answers.com, Yahoo! Answers и им подобных. Главным условием было отсутствие готовых ответов на самих этих сайтах. При этом вопросы должны были быть не слишком простыми, но иметь четкий короткий ответ, который можно найти в интернете. Чтобы отсечь роботов и недобросовестных участников, потребовалось реализовать несколько этапов проверки качества результатов. Во-первых, на входе в систему стоит капча, во-вторых, пользователю необходимо ответить на 1-2 тривиальных вопроса, а в-третьих, пользователь должен выполнять задание, используя наш прокси-сервер, благодаря чему мы можем удостоверить, что он действительно задавал вопросы поисковой системе и посещал страницу с ответом.
При помощи стандартных модулей для HTTP-сервера Apache mod_proxy_html и mod_sed мы реализовали проксирование всех обращений к поисковым сервисам. Пользователь заходил на нашу страницу, видел привычный интерфейс поисковика, но все ссылки там были заменены на наши. Переходя по такой ссылке, пользователь попадал на нужную страницу, но в нее уже был встроен наш JavaScript-код, отслеживающий поведение.
При протоколировании возникает небольшая проблема: позиция мыши представлена координатами в окне браузера, а координаты текста в нем зависят от разрешения экрана, версии и настроек. Нам же нужна точная привязка именно к тексту. Соответственно, нам нужно вычислять координаты каждого слова на клиенте и хранить эту информацию на сервере.
Результатом проведенных экспериментов стали следующие данные:
С точки зрения статистики данные выглядят следующим образом:

Код и собранные данные свободно доступны по этой ссылке.
Чтобы выделить сниппеты, текст разбивается на фрагменты по пять слов. Для каждого фрагмента выделяется по шесть поведенческих факторов:
При помощи машинного обучения все эти шесть факторов сворачиваются в одно число – вероятность интересности фрагмента. Но для начала нам нужно сформировать обучающее множество. При этом, мы не знаем доподлинно, что действительно заинтересовало читателя, что он читал, и где нашел ответ. Но мы можем в качестве положительных примеров взять фрагменты, которые пересекаются с ответом пользователя, а в качестве отрицательных – все остальные фрагменты. Это обучающее множество неточно и неполно, но его вполне достаточно для обучения алгоритма и улучшения качества сниппетов.
Первый эксперимент состоит в проверке адекватности нашей модели. Мы обучили алгоритм предсказания интересности фрагмента на одном множестве страниц и применяем к другому множеству. На графике по оси x показана предсказанная вероятность интересности фрагмента, а по оси y – среднее значение меры пересечения фрагмента с ответом пользователя:

Мы видим, что если алгоритм в большой степени уверен, что фрагмент хороший, то этот фрагмент имеет большое пересечение с ответом пользователя.
При построении метода машинного обучения наиболее важными факторами оказались DispMiddleTime (время, в течение которого фрагмент текста был виден на экране) и MouseOverTime (время, в течение которого курсор мыши был над фрагментом текста).
Итак, мы можем определить, какие фрагменты заинтересовали пользователя. Как мы можем использовать это для улучшения сниппетов? В качестве отправной точки мы реализовали современный алгоритм генерации сниппетов, опубликованный исследователями из Yahoo! в 2008 году. Для каждого предложения вычисляется набор текстовых факторов и строится метод машинного обучения для предсказания качества фрагмента с точки зрения выделения сниппета при помощи асессорских оценок по шкале {0,1}. Затем сравниваются несколько методов машинного обучения: SVM, ranking SVM и GBDT. Мы добавили больше факторов и расширили шкалу оценок до {0,1,2,3,4,5}. Для формирования сниппета отбирается от одного до четырех предложений из набора лучших. Фрагменты отбираются при помощи жадного алгоритма, который собирает фрагменты с суммарным наилучшим весом.
Мы используем следующий набор текстовых факторов:
Теперь, когда у нас есть вес фрагмента с точки зрения текстовой релевантности, нам нужно объединить его с фактором интересности фрагмента, вычисленным по поведению пользователя. Мы используем простую линейную комбинацию факторов, и вес λ в формуле вычисления качества фрагмента – это вес поведения.
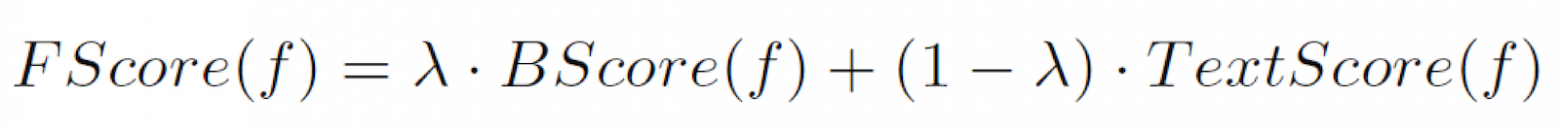
Нам нужно выбрать правильный вес λ. Тут есть две крайности: если значение λ слишком маленькое, то поведение не учитывается и сниппеты отличаются от baseline, если же значение λ слишком большое, есть риск, что мы потеряем в качестве сниппетов. Для выбора λ проводим эксперимент с выбором из пяти значений от нуля до единицы {0.1,0.3,0.5,0.7,0.9}. Для сравнения экспериментов мы набрали асессоров, которые попарно сопоставляли сниппеты по трем критериям:
На графиках ниже представлены доли пар сниппетов, в которых поведенческий алгоритм показал улучшение качества для трех критериев и пяти значений λ. Для каждого из значений λ асессоры давали разное количество оценок, и разное количество сниппетов отличаются по качеству. Поэтому доверительные интервалы для каждого из λ несколько различаются. Мы видим, что для λ=0.7 мы получаем статистически значимое улучшение качества сниппета по каждому из критериев. Coverage для этих сниппетов также достаточно большой: 40% сниппетов с учетом поведения отличаются от baseline.
Во-первых эксперименты проводились на информационных вопросах, когда пользователь ищет текст ответа в документах. Однако существуют и другие типы пользовательского интента: например, коммерческие, навигационные. Для таких запросов поведенческие факторы могут вызывать помехи, либо требовать другого способа учета. Во-вторых, по постановке эксперимента мы предполагаем, что просмотры страниц сгруппированы по информационной потребности. В наших экспериментах все пользователи для каждой пары документ-запрос искали одно и то же. Поэтому мы агрегируем данные для всех пользователей, вычисляя среднее значение веса фрагмента по всем пользователям. В реальном мире пользователи могут задавать один и тот же запрос и смотреть тот же самый документ с разными целями. И нам нужно для каждого запроса группировать пользователей по интенту, чтобы иметь возможность применить эти методы и агрегировать данные поведения. Ну и в-третьих, чтобы внедрить эту технологию в реальную систему, нужно найти способ сбора данных о поведении пользователей. Сейчас уже есть плагины для браузеров, рекламные сети и счетчики посещений, которые собирают данные о пользовательских кликах. Их функциональность можно расширить, добавив возможность сбора данных о движениях мыши.
Среди других применений метода можно отметить следующее:
После доклада состоялась сессия вопросов и ответов, посмотреть которую можно на видеозаписи.
Этому вопросу и было посвящено исследование, проведенное мной, Михаилом Агеевым, совместно с Дмитрием Лагуном и Евгением Агиштейном в Emory Intelligent Information Access Lab Университета Эмори.
Мы изучали методы сбора данных и алгоритмы анализа поведения пользователя по движениям мыши, а также возможности применения этих методов на практике. Они позволяют существенно улучшить формирование сниппетов (аннотаций) документов в результатах поиска. Работа с описанием этих алгоритмов была отмечена дипломом «Best Paper Shortlisted Nominee» на международной конференции ACM SIGIR в 2013 году. Позже я представил доклад о результатах проделанной работы в рамках научно-технических семинаров в Яндексе. Его конспект вы найдете под катом.
Сниппеты являются важнейшей частью любой поисковой системы. Они помогают пользователям искать информацию, и от их качества зависит удобство использования поисковой системы. Хороший сниппет должен быть удобочитаемым, должен показывать части документа, которые соответствуют запросу пользователя. В идеале сниппет должен содержать прямой ответ на вопрос пользователя или указание на то, что ответ есть в документе.
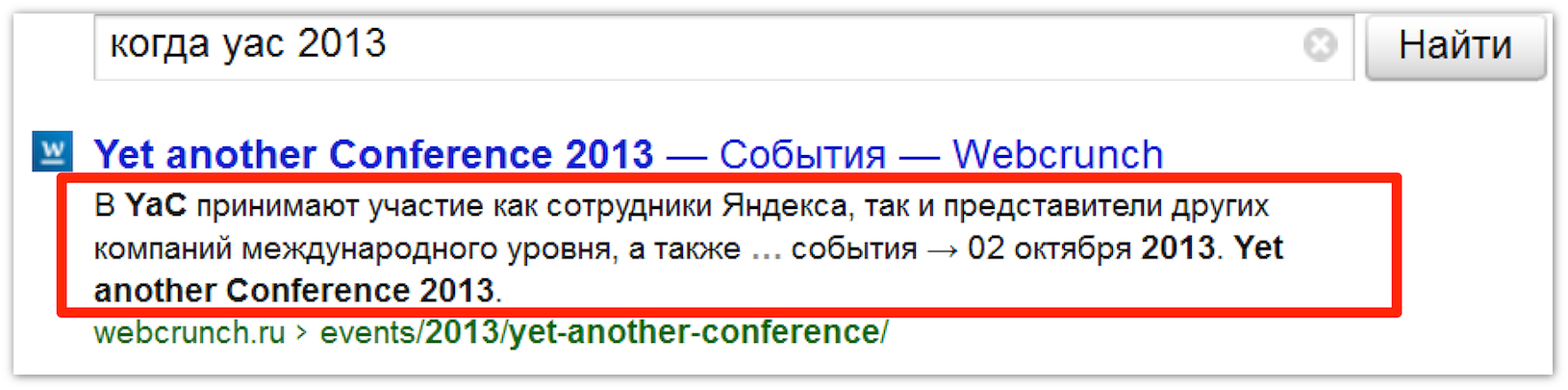
Общий принцип состоит в том, что текст запроса сопоставляется с текстом документа, в котором выделяются наиболее релевантные предложения, содержащие слова запроса или расширения запроса. Формула вычисления наиболее релевантных фрагментов учитывает совпадения с запросом. Учитывается плотность текста, местоположение текста, структура документа. Однако для высокорелевантных документов, которые всплывают в верхней части поисковой выдачи, текстовых факторов зачастую недостаточно. В тексте могут многократно встречаться слова из запроса, и определить, какие фрагменты текста отвечают на вопрос пользователя на основе только текстовой информации невозможно. Поэтому требуется привлечение дополнительных факторов.
При просмотре страницы внимание пользователя распространяется неравномерно. Основное внимание уделяется тем фрагментам, которые содержат искомую информацию.
Мы провели эксперименты с применением оборудования, отслеживающего движения глазного зрачка с точностью до нескольких десятков пикселей. Вот пример распределения тепловой карты траектории зрачка пользователя, искавшего ответ на вопрос, сколько битых пикселей должно быть на iPad 3, чтобы его можно было заменить по гарантии. Он вводит запрос [how many dead pixels ipad 3 replace], который приводит его на страницу Apple Community Forums с подобным вопросом. На странице слова из запроса встречаются многократно, однако пользователь заостряет внимание на том фрагменте, который действительно содержит ответ, что и видно на тепловой карте.
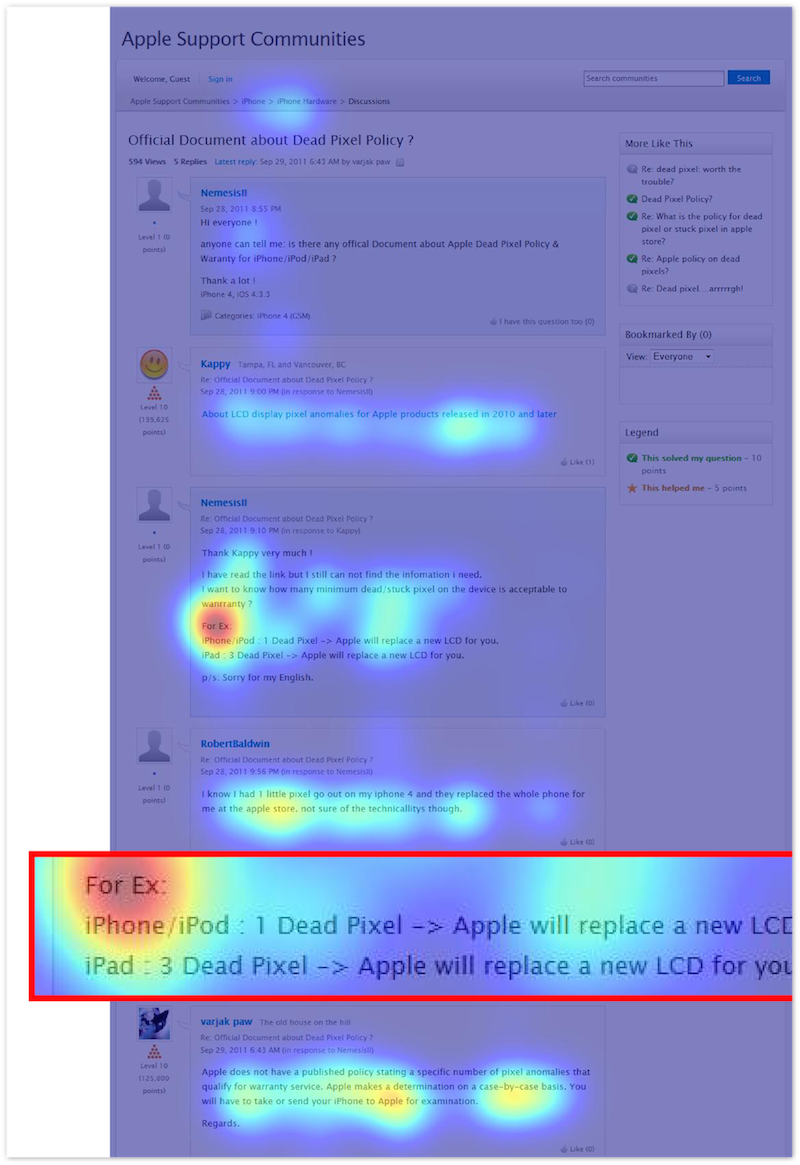
Если бы мы могли отслеживать и анализировать движения зрачков большего количества пользователей, мы могли бы только на основании этих данных выделять идеальные сниппеты для различных запросов. Проблема заключается в том, что у пользователей не установлены средства для айтрекинга, поэтому нужно искать другие пути получения необходимой информации.
При просмотре веб-документов пользователи обычно совершают движения мышью, скроллят страницы. В своей статье 2010 года К. Гуо и Е. Агиштейн отмечают, что по траектории можно предсказывать движения глазного зрачка с точностью 150 пикселей и полнотой 70%.
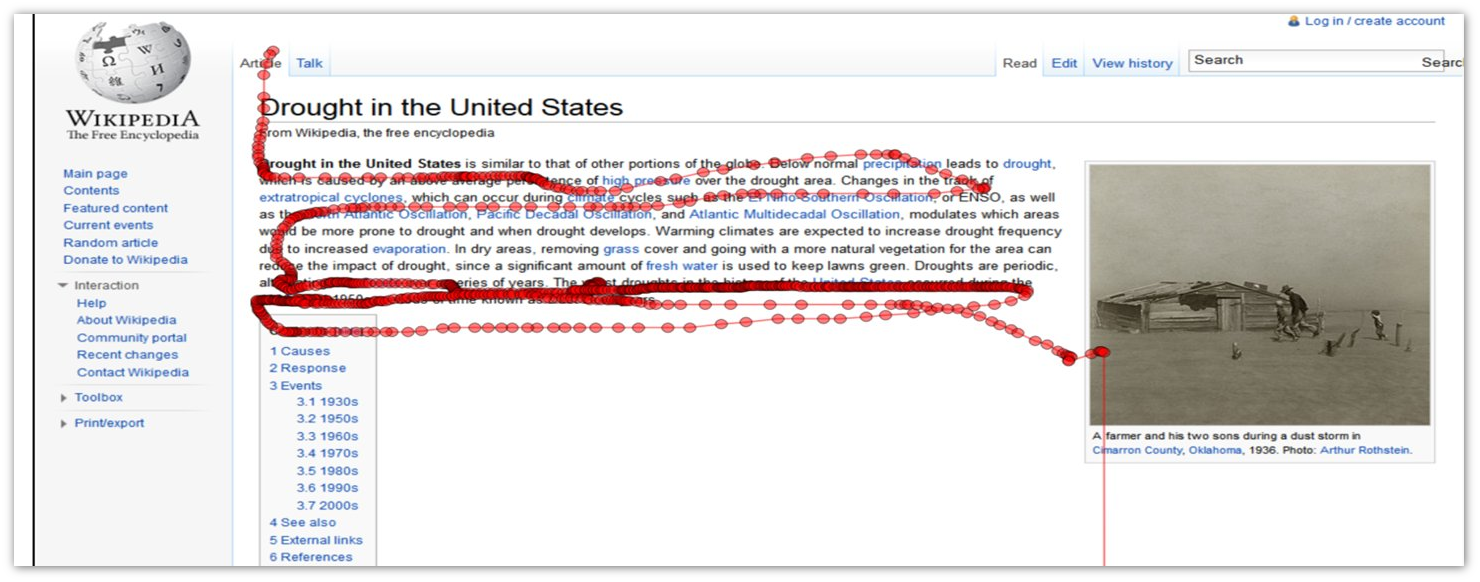
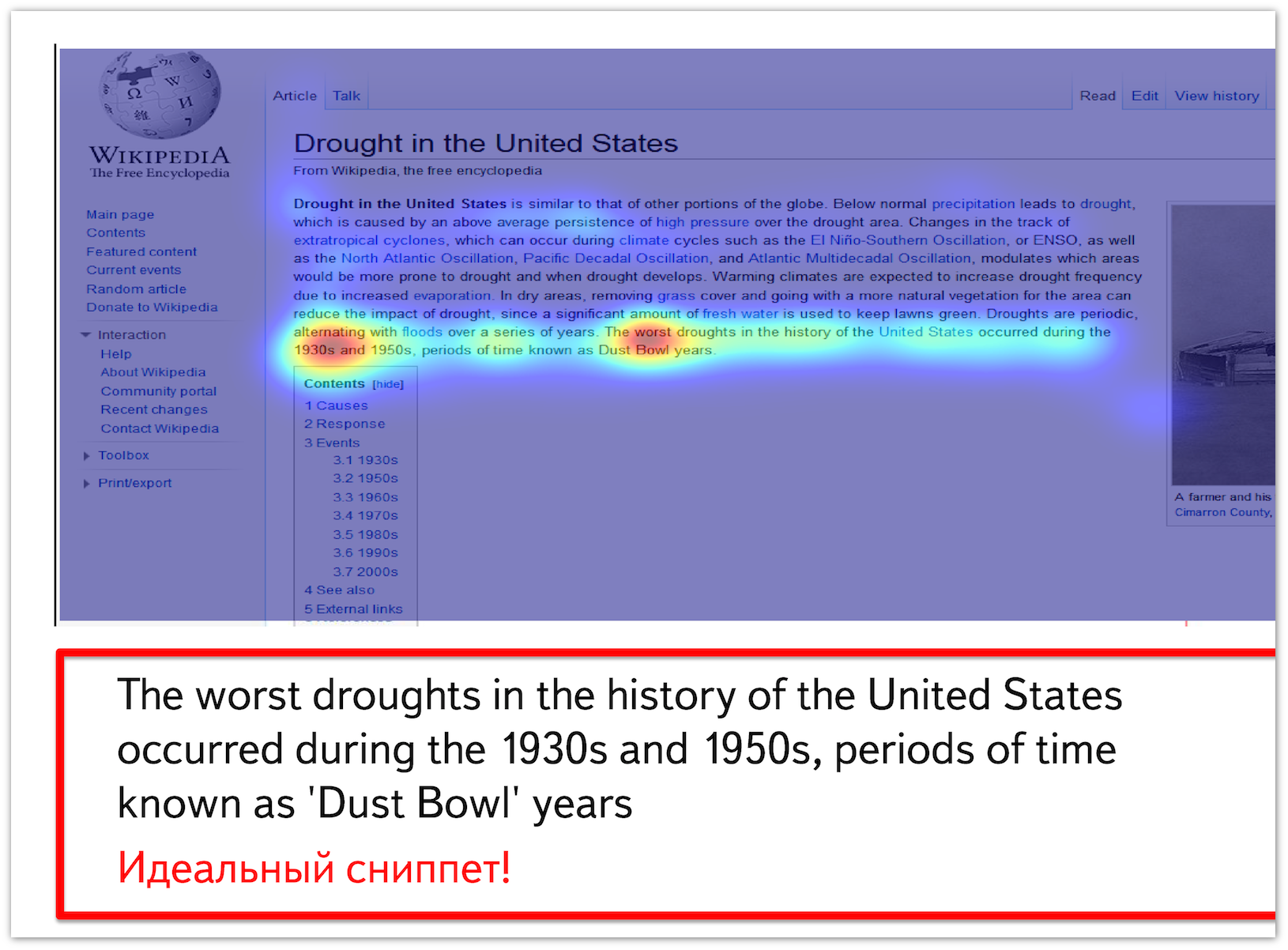
Ниже представлена тепловая карта движений мыши при просмотре документа, найденного по запросу [worst drought in US]. Видно, что наибольшая активность прослеживается именно на фрагменте, содержащем информацию о самых сильных засухах в США, именно из него можно сформировать идеальный сниппет.
Идея нашего исследования состоит в том, что данные о движениях мыши можно собирать при помощи JavaScript API, работающего в большинстве браузеров. По поведению пользователей мы можем предсказывать, какие фрагменты содержат релевантную запросу информацию, и затем использовать эти данные для улучшения качества сниппетов. Для того, чтобы реализовать и проверить эту идею, нужно решить несколько задач. Во-первых, нужно понять, как собрать реалистичные и достаточно масштабные данные о поведении пользователей за страницей результатов поиска. Во-вторых, нужно научиться по движениям мыши определять наиболее заинтересовавшие пользователя фрагменты. У пользователей есть разные привычки: некоторые любят выделять читаемый текст или просто наводят на него мышь, другие же открывают документ и читают его сверху вниз, изредка пролистывая его вниз. При этом у пользователей могут быть разные браузеры и устройства ввода. Кроме того, объем данных о движениях мыши на два порядка выше объема данных о кликах. Также стоит задача объединения поведенческих факторов с традиционными текстовыми.
Как собирать данные
Для сбора данных мы использовали инфраструктуру, разработанную нами в 2011. Основная идея – создать игру, подобную кубку Яндекса по поиску. Игроку ставится цель за ограниченное время при помощи поисковой системы найти в интернете ответ на поставленный вопрос. Игрок находит ответ и отправляет его нам вместе с URL страницы, где он был обнаружен. Отбор участников происходит через Amazon Mechanical Turk. Каждая игра состоит из 12 вопросов. За участие в игре длиной примерно сорок минут предполагается гарантированная оплата в $1. Еще по одному доллару получают 25% лучших игроков. Это достаточно дешевый способ сбора данных, который при этом дает большое разнообразие пользователей с разных концов мира. Вопросы брались на сайтах Wiki.answers.com, Yahoo! Answers и им подобных. Главным условием было отсутствие готовых ответов на самих этих сайтах. При этом вопросы должны были быть не слишком простыми, но иметь четкий короткий ответ, который можно найти в интернете. Чтобы отсечь роботов и недобросовестных участников, потребовалось реализовать несколько этапов проверки качества результатов. Во-первых, на входе в систему стоит капча, во-вторых, пользователю необходимо ответить на 1-2 тривиальных вопроса, а в-третьих, пользователь должен выполнять задание, используя наш прокси-сервер, благодаря чему мы можем удостоверить, что он действительно задавал вопросы поисковой системе и посещал страницу с ответом.
При помощи стандартных модулей для HTTP-сервера Apache mod_proxy_html и mod_sed мы реализовали проксирование всех обращений к поисковым сервисам. Пользователь заходил на нашу страницу, видел привычный интерфейс поисковика, но все ссылки там были заменены на наши. Переходя по такой ссылке, пользователь попадал на нужную страницу, но в нее уже был встроен наш JavaScript-код, отслеживающий поведение.
При протоколировании возникает небольшая проблема: позиция мыши представлена координатами в окне браузера, а координаты текста в нем зависят от разрешения экрана, версии и настроек. Нам же нужна точная привязка именно к тексту. Соответственно, нам нужно вычислять координаты каждого слова на клиенте и хранить эту информацию на сервере.
Результатом проведенных экспериментов стали следующие данные:
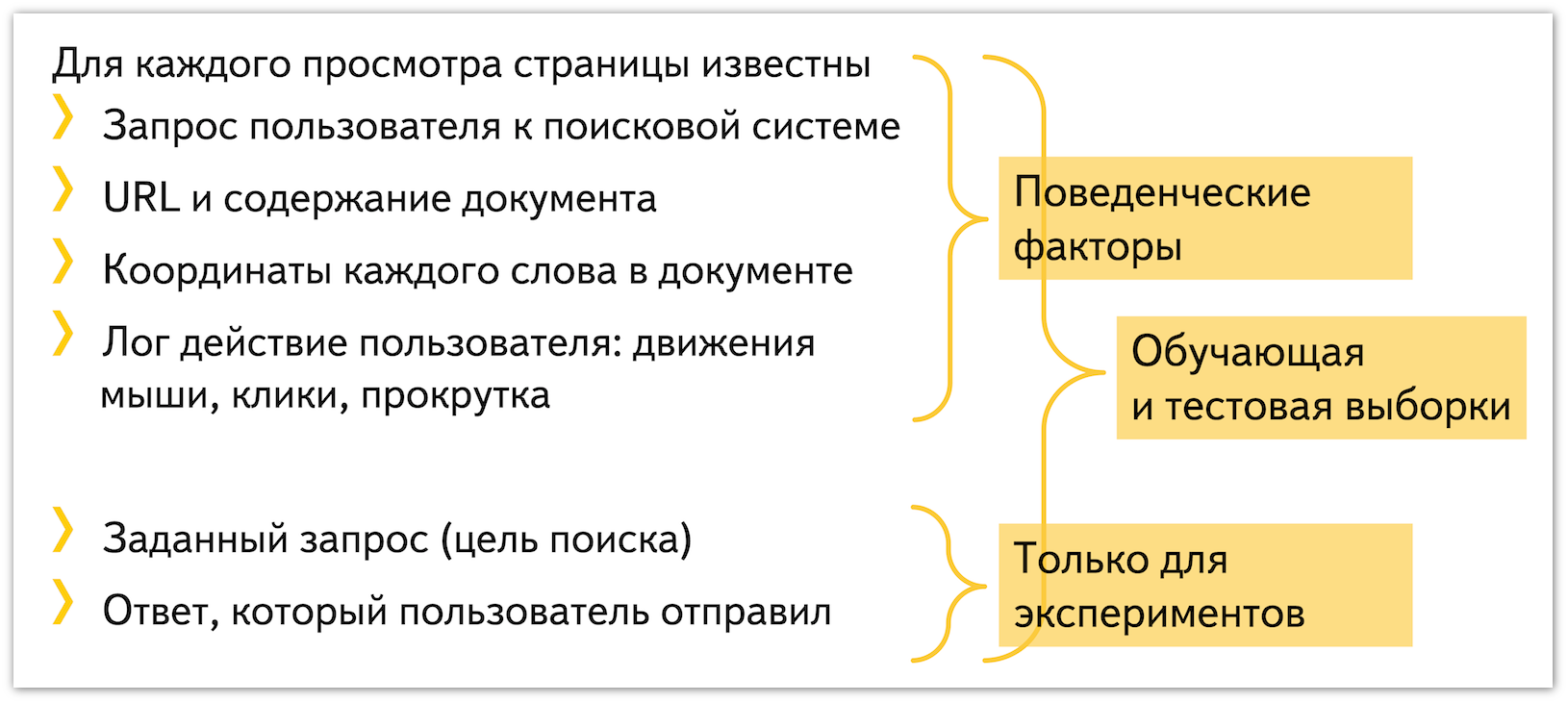
С точки зрения статистики данные выглядят следующим образом:

Код и собранные данные свободно доступны по этой ссылке.
Предсказание фрагментов, заинтересовавших пользователей
Чтобы выделить сниппеты, текст разбивается на фрагменты по пять слов. Для каждого фрагмента выделяется по шесть поведенческих факторов:
- Длительность нахождения курсора над фрагментом;
- Длительность нахождения курсора рядом с фрагментом (±100px);
- Средняя скорость мыши над фрагментом;
- Средняя скорость мыши рядом с фрагментом;
- Время показа фрагмента в видимой части окна просмотра (scrollabar);
- Время показа фрагмента в середине окна просмотра.
При помощи машинного обучения все эти шесть факторов сворачиваются в одно число – вероятность интересности фрагмента. Но для начала нам нужно сформировать обучающее множество. При этом, мы не знаем доподлинно, что действительно заинтересовало читателя, что он читал, и где нашел ответ. Но мы можем в качестве положительных примеров взять фрагменты, которые пересекаются с ответом пользователя, а в качестве отрицательных – все остальные фрагменты. Это обучающее множество неточно и неполно, но его вполне достаточно для обучения алгоритма и улучшения качества сниппетов.
Первый эксперимент состоит в проверке адекватности нашей модели. Мы обучили алгоритм предсказания интересности фрагмента на одном множестве страниц и применяем к другому множеству. На графике по оси x показана предсказанная вероятность интересности фрагмента, а по оси y – среднее значение меры пересечения фрагмента с ответом пользователя:
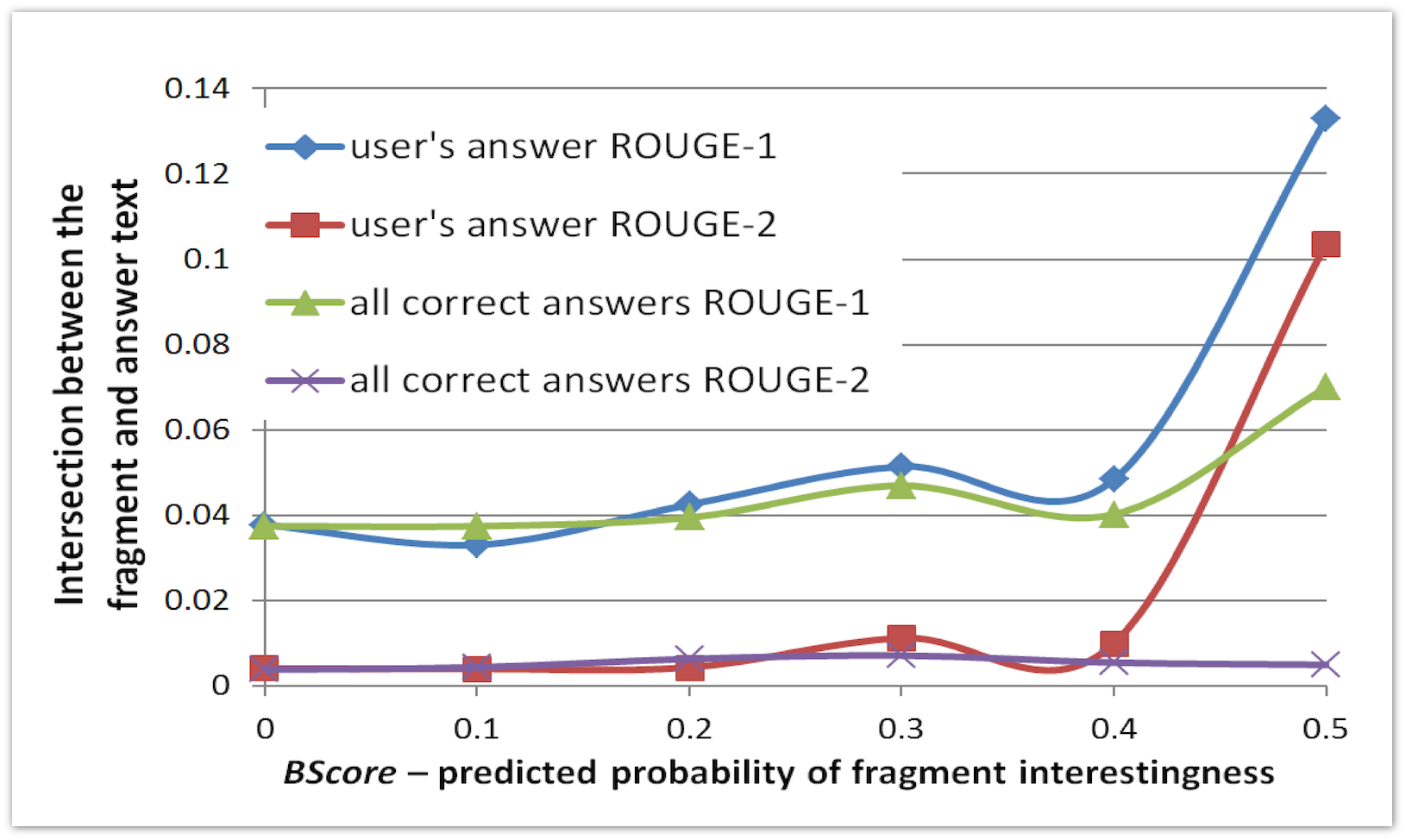
Мы видим, что если алгоритм в большой степени уверен, что фрагмент хороший, то этот фрагмент имеет большое пересечение с ответом пользователя.
При построении метода машинного обучения наиболее важными факторами оказались DispMiddleTime (время, в течение которого фрагмент текста был виден на экране) и MouseOverTime (время, в течение которого курсор мыши был над фрагментом текста).
Улучшение сниппетов на основе анализа поведения
Итак, мы можем определить, какие фрагменты заинтересовали пользователя. Как мы можем использовать это для улучшения сниппетов? В качестве отправной точки мы реализовали современный алгоритм генерации сниппетов, опубликованный исследователями из Yahoo! в 2008 году. Для каждого предложения вычисляется набор текстовых факторов и строится метод машинного обучения для предсказания качества фрагмента с точки зрения выделения сниппета при помощи асессорских оценок по шкале {0,1}. Затем сравниваются несколько методов машинного обучения: SVM, ranking SVM и GBDT. Мы добавили больше факторов и расширили шкалу оценок до {0,1,2,3,4,5}. Для формирования сниппета отбирается от одного до четырех предложений из набора лучших. Фрагменты отбираются при помощи жадного алгоритма, который собирает фрагменты с суммарным наилучшим весом.
Мы используем следующий набор текстовых факторов:
- Точное соответствие;
- Количество найденных слов запроса и синонимов (3 фактора);
- BM25-like (4 фактора);
- Расстояние между словами запроса (3 фактора);
- Длина предложения;
- Позиция в документе;
- Удобочитаемость: количество знаков пунктуации, заглавных слов, различных слов (9 факторов).
Теперь, когда у нас есть вес фрагмента с точки зрения текстовой релевантности, нам нужно объединить его с фактором интересности фрагмента, вычисленным по поведению пользователя. Мы используем простую линейную комбинацию факторов, и вес λ в формуле вычисления качества фрагмента – это вес поведения.

Нам нужно выбрать правильный вес λ. Тут есть две крайности: если значение λ слишком маленькое, то поведение не учитывается и сниппеты отличаются от baseline, если же значение λ слишком большое, есть риск, что мы потеряем в качестве сниппетов. Для выбора λ проводим эксперимент с выбором из пяти значений от нуля до единицы {0.1,0.3,0.5,0.7,0.9}. Для сравнения экспериментов мы набрали асессоров, которые попарно сопоставляли сниппеты по трем критериям:
- Representativeness: какой из сниппетов лучше отражает соответствие документа запросу? Необходимо прочитать документ до ответа на вопрос.
- Readability: какой из сниппетов лучше написан, легче читается?
- Judjeability: какой из сниппетов лучше помогает найти релевантный ответ и решить, нужно ли кликать на ссылку?
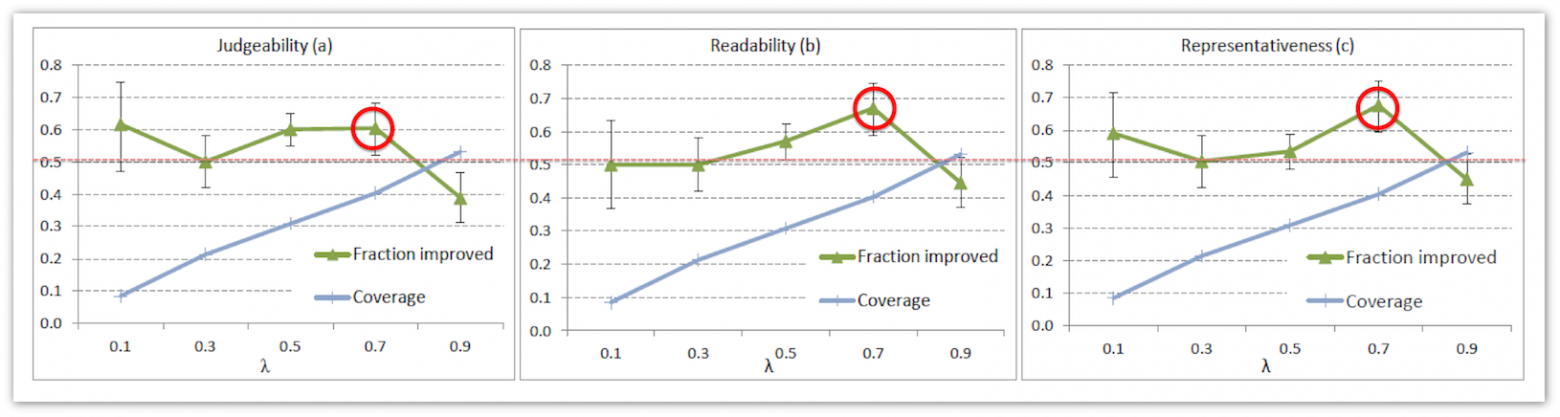
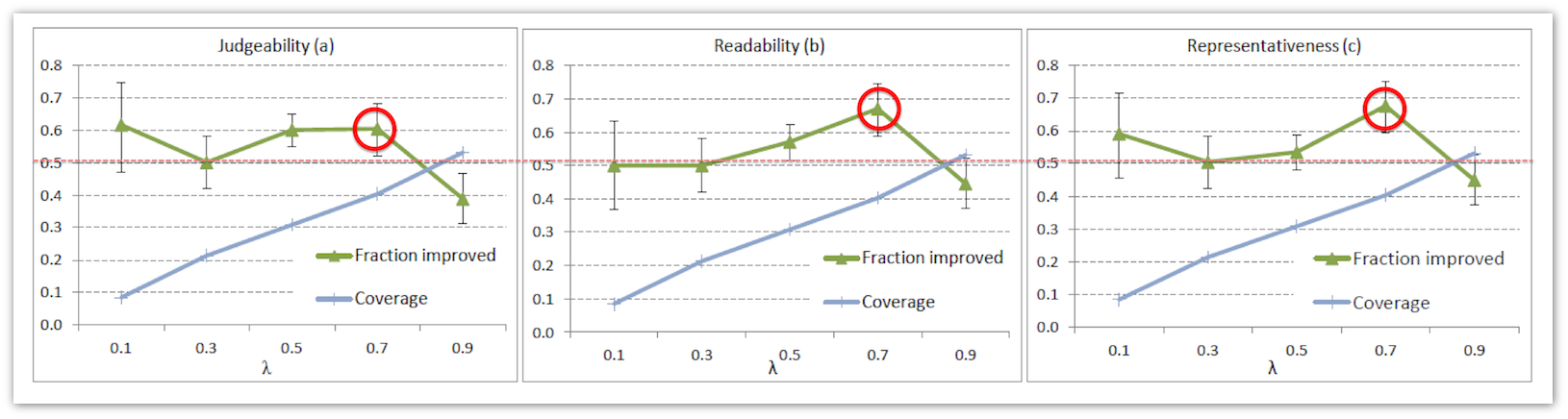
На графиках ниже представлены доли пар сниппетов, в которых поведенческий алгоритм показал улучшение качества для трех критериев и пяти значений λ. Для каждого из значений λ асессоры давали разное количество оценок, и разное количество сниппетов отличаются по качеству. Поэтому доверительные интервалы для каждого из λ несколько различаются. Мы видим, что для λ=0.7 мы получаем статистически значимое улучшение качества сниппета по каждому из критериев. Coverage для этих сниппетов также достаточно большой: 40% сниппетов с учетом поведения отличаются от baseline.
Основные предположения и ограничения рассмотренного подхода
Во-первых эксперименты проводились на информационных вопросах, когда пользователь ищет текст ответа в документах. Однако существуют и другие типы пользовательского интента: например, коммерческие, навигационные. Для таких запросов поведенческие факторы могут вызывать помехи, либо требовать другого способа учета. Во-вторых, по постановке эксперимента мы предполагаем, что просмотры страниц сгруппированы по информационной потребности. В наших экспериментах все пользователи для каждой пары документ-запрос искали одно и то же. Поэтому мы агрегируем данные для всех пользователей, вычисляя среднее значение веса фрагмента по всем пользователям. В реальном мире пользователи могут задавать один и тот же запрос и смотреть тот же самый документ с разными целями. И нам нужно для каждого запроса группировать пользователей по интенту, чтобы иметь возможность применить эти методы и агрегировать данные поведения. Ну и в-третьих, чтобы внедрить эту технологию в реальную систему, нужно найти способ сбора данных о поведении пользователей. Сейчас уже есть плагины для браузеров, рекламные сети и счетчики посещений, которые собирают данные о пользовательских кликах. Их функциональность можно расширить, добавив возможность сбора данных о движениях мыши.
Среди других применений метода можно отметить следующее:
- Улучшение Click Model за счет предсказания P(Examine | Click=0). Если мы отслеживаем только клики, то сказать с уверенностью, по какой причине пользователь не кликнул по ссылке в поисковой выдаче, мы не можем. Он мог прочитать сниппет, и решить, что документ нерелевантен, либо он просто не видел документа. С применением отслеживания движений мыши эта проблема отпадает, и мы можем заметно улучшить предсказание релевантности документа.
- Поведение пользователей на мобильных устройствах.
- Классификация движений мыши по интенту. Если усложнить модель, можно научиться отличать случайные движения мыши от намеренных, когда пользователь действительно помогает себе читать при помощи курсора. Кроме того, можно учитывать моменты бездействия как один из дополнительных признаков интересности фрагмента.
После доклада состоялась сессия вопросов и ответов, посмотреть которую можно на видеозаписи.
