
Перед тестированием всегда стояли и стоят две задачи – помочь команде поддерживать высокий уровень качества разработки и делать это, не задерживая весь процесс. И это справедливо не только для наших проектов в Яндексе, где мы работаем над очень большим количеством сервисов. Часто основная задача и вовсе формулируется как увеличение скорости тестирования при сохранении должного уровня качества. Скорость процесса разработки, приверженность ценностям частых и быстрых релизов – это основополагающие факторы для успеха любого продукта. У команды больше возможностей маневра, команда быстрее находит и исправляет ошибки, быстрее получает фидбек. Как же ускоряться, не теряя качества, как достичь дзена непрерывной доставки изменений?

Сегодня мы покажем, что Continuous Delivery — это просто и весело! А пользу от него можно получить, встроив его даже частично. Мы в тестировании Яндекса уже несколько лет используем подобный подход для наших библиотек с открытым исходным кодом — Allure Framework или Yandex QATools. Процесс прост, значительно масштабируем и может применяться как для огромных команд из одного человека, так и для маленьких командочек из десятков человек. А самое главное — весь инструментарий доступен в Open Source!
Кстати, до 30 сентября можно подать заявку и поступить в нашу Школу автоматизации процессов разработки в Питере. Обучение в ней бесплатное и будет состоять не только из курса лекций — обязательным этапом станет командная работа над учебным проектом.
А теперь вернёмся к теме. Представьте картину: уютное рабочее место, вы пишете код, добавляете юнит-тесты и отправляете изменения в систему контроля версий, а через пару часов они «выезжают» на боевые сервера. И все при этом работает.
Кажется, что такой процесс характерен либо для метода разработки «хлобысь, хлобысь и в продакшен» (убрав часть про юнит-тесты), либо для рекламного ролика компании, специализирующейся на инновациях при разработке ПО. При этом под ним обязательно нужна бегущая строка, аналогичная подписи под каскадёрскими трюками: «Опасно, не пытайтесь повторить дома!».
История одного разработчика. Где-то слышал задачу о бэкапах: «Сколько грузовиков нужно, чтобы администратор начал делать резервные копии?». Юмор черный, поэтому решение жду в комментариях. Здесь речь идет о процессе разработки, но суть не меняется. Разработчик отправляет любое изменение в основную ветку и, посчитав, что пора собрать пакет для тестирования и выкладки, останавливается на стабильном, по его мнению, состоянии кода, обновляя ветку, из которой собираются пакеты. Теперь возникает вопрос: «Что содержится в новом пакете после очередной сборки?». Любой ответ на этот вопрос может быть неправильным. Ведь разработчик уверен, что меняет код только он, поэтому смотреть в историю изменений не нужно. Бывало, буквально чудом, находили при тестировании аномалии, которые могли серьёзно осложнить жизнь пользователям наших сервисов. Аномалиями оказывались несогласованные изменения, попавшие в ветку либо от разработчика из другого проекта, решившего исправить баг, либо собранные «за компанию» и просто забытые. Сложности ожидали и тех, кто решил бы влиться в процесс разработки. В какой ветке ведется разработка? В какой ветке стабильная версия? Как вообще собирать пакет?
А в случае, если в пакете находились ошибки, после их правок тестировщика мог ждать сюрприз — вместе с исправлениями могли «приехать» еще несколько новых возможностей. При особом везении после пары циклов пакет мог увеличить первоначальное количество задач в несколько раз и «распухнуть» до невообразимых размеров.
История нескольких разработчиков. Эта история отличается только тем, что в список ежедневной рутины каждому разработчику в команде добавляется слияние своих изменений с изменениями коллег. А еще ведь все друг другу доверяют и никто не смотрит на эти самые изменения коллег — они же знают, что пишут! Все бы и рады смотреть, что происходит с проектом, тем более когда коллега уходит в отпуск, все равно приходится разбираться, но где это делать? В среде разработки негде оставить комментарий. Лично сказать не всегда удобно, особенно если разработка ведется в разных офисах. Да и изменения уже в проекте — так просто не переделать в случае ошибок.
Что общего у этих историй? Отговорки. Все считают, что упростить себе жизнь, введя понятный процесс и автоматизировав рутину, слишком сложно. Кроме того, всем придется ломать себя об колено, чтобы привыкнуть к новым реалиям. Это не так. Мы уже разрушили в своих командах такой миф.
Бросаться разрушать вредные, но несущественные мифы, о которых никто не слышал и от которых никто не страдал, — непродуктивно. Поэтому, испытав первые трудности с доставкой изменений до конечных потребителей, текущую схему разработки пришлось менять.
Для полного веселья потребуется: GitHub Flow как непосредственный процесс, CI сервер. Немного, правда? Наши библиотеки живут на GitHub, поэтому я буду пользоваться его терминологией, давая комментарии по ходу. Весь этот процесс вполне возможен почти на любых комбинациях CI-серверов и популярных площадках для IT-проектов, вроде GitLab, Bitbucket. Ключевое только одно: потребуется клей, называемый семейством расширений Pull Request Builders.
Форк, коммит, пуш, реквест, билд, ревью, мерж, релиз.
Все эти смешные слова я дальше употреблять не буду. Хоть и очень тянет! Тот, кто их знает и регулярно использует, скорее всего, давно внедрил подобный процесс. Эти короткие непонятные словечки так же легко выучить, как и реализовать следующие основные этапы в рамках задачи на легкое построение процесса:
Точка входа — основной репозиторий, мастер-ветка. Один из главных бонусов подхода — всегда известно, где находится стабильный рабочий код, который видел не только разработчик. Прямое изменение этой ветки запрещено. Даже если очень хочется.
На этом этапе потребуется только GitHub или аналог. Первое, что нужно сделать, — продублировать текущую мастер-ветку основного репозитория в свой личный репозиторий. Тут разработчик волен строить процесс кодирования так, как ему нравится. Это его личный репозиторий, и здесь он полновластный хозяин. Конечная цель проста — набор изменений, базирующийся на мастер-ветке основного репозитория, в любой ветке личного.
На этом этапе появляестя и самая большая сложность — приучить себя писать unit-тесты на свои изменения. Самое интересное, что сложность не в том, чтобы написать эти тесты, а именно приучить себя их делать. Но если выработать такую привычку, она окупит почти любые трудозатраты на само написание тестов. Начните с малого: покрывайте позитивные сценарии. Их легко продумать, легко реализовать в тестах. Привыкнув не бояться за поломку заявленной функциональности, легко добавить негативные сценарии. Это избавит от страха непоправимо сломаться в неожиданных местах. Изменения готовы к демонстрации?
По набору возможных печенек и вариантов реализации это самый технологичный этап. Этап не просто так называется «смотрят другие» — без слова «разработчики». Автоматика!
Для начала разработчику нужно запустить процесс — предложить свои изменения к слиянию в основную ветку проекта. Думаю, не нужно говорить о том, что телепаты обычно в отъезде, поэтому сообщения к каждому изменению должны четко отражать их суть. Особенно сильно это ощущается, когда сам возвращаешься после перерыва к работе над проектом и обнаруживаешь чужие изменения. Хорошо, если понятно, что произошло по заголовкам в истории GIT. Ведь после отпуска не очень-то хочется, разглядывая разницу, переваривать тонны изменений, чтобы внести маленькое исправление. В проектах с открытым исходным кодом это более чем важно — здесь за вашей историей следят уже сотни человек!
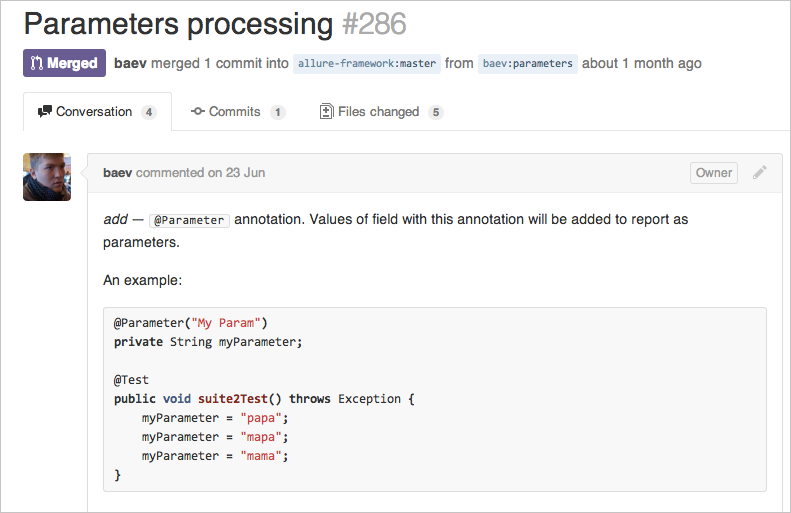
Тут в дело и вступает CI-сервер. Мы используем два: TeamCity & Jenkins. Какой точно использовать, мы так до конца и не определились. Зависит в основном от предпочтений настраивающего новую задачу на сборку. Для того чтобы сборка началась, как только в основной репозиторий приехало предложение на слияние, потребуется тот самый клей — одно из расширений семейства «Pull Request Builders».
Например, для Jenkins + GitHub это GitHub PRBP.
Для Jenkins + Bitbucket это Bitbucket PRBP.
Для Teamcity + Github это TeamCity.GitHub.
CI-сервер заботливо соберет предложенное изменение, прогонит тесты и обязательно сообщит о проблемах в самом предложении на слияние:

Прямо здесь же стоит настроить и статический анализ кода. Сейчас можно автоматически находить огромное количество ошибок в коде! Например, при помощи SonarQube. Он сможет измерить покрытие тестами и предупредить, если оно вдруг упадет. Получение обратной связи занимает минуты! Исправить ошибки можно в той же самой ветке, из которой было предложение:

Не стоит бояться совсем перезаписать историю в этой ветке. GitHub, например, быстро обновит предложение, а CI-сервер снова пересоберет его. Во многих проектах с открытым исходным кодом такое правило отдельно прописано.
После успешной сборки — время для осмотра кода живым человеком. Конечно, если вы единственный разработчик, вам может быть некого просить посмотреть ваш код. В этом случае представляется отличный шанс самому критично взглянуть на внесенные изменения. После пройденной сборки и осмотра кода остается нажать всего одну кнопку — залить изменения в основную ветку. Ответственный шаг. Во всех системах отражается, кто это сделал.
При небольших изменениях, чтение этого раздела отнимает гораздо больше времени, чем то, о чем он написан.
Как только изменения попали в основную ветку, наступает время интеграционного тестирования. Здесь удобнее всего поставить на караул задачу на сборку тестовых пакетов. Мы в наших библиотеках в этот момент обновляем SNAPSHOT версию в Maven репозитории. Тут уже гоняются тяжелые интеграционные тесты, проверяющие взаимодействие со сторонними компонентами, запускаются браузерные тесты, где это требуется. На этом этапе вполне реально отдать пакеты в ручное тестирование.
Как только в основной ветке накопилось достаточное количество изменений, которыми все участники довольны в нужной степени, приходит время релиза. Обычно это еще одна задача на сборку с ручным вызовом. В GitHub, например, для этого используют команду для HuBot. Очень удобно помечать в этот момент головное изменение тегом. Это позволит в любой момент при желании получить возможность собрать нужную версию, не вспоминая номер изменения.
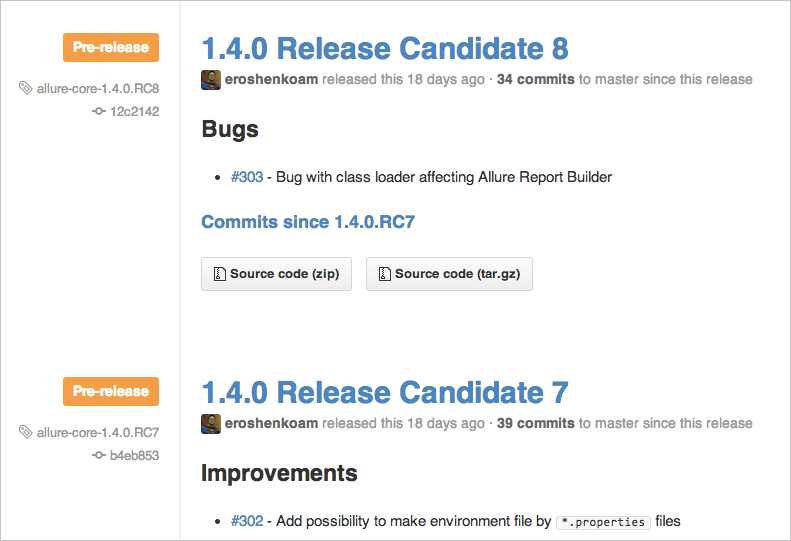
Выбор версии релиза — отдельный процесс, для которого существуют даже особые стандарты. Для маленьких библиотек мы пользуемся двухциферной нотацией: младшая растет каждый релиз, старшая при потере обратной совместимости обнуляет младшую. Для библиотек побольше — трехциферной с аналогичной логикой.
Для того чтобы организовать подобный процесс даже не нужно иметь собственный CI-сервер. Для маленьких проектов очень удобно использовать www.cloudbees.com/jenkins, который даст полноценный Jenkins-сервер с ограничением на количество сборок. Начать собирать предложения на слияние на GitHub вполне реально используя buildhive.cloudbees.com — у него нет лимитов. Либо travis-ci.org, для которого нужно в корень проекта положить небольшой конфигурационный файлик.
Если же у вас под рукой свой сервер, настроить на нем Jenkins или TeamCity — дело получаса. Настройки по умолчанию в этих серверах перекрывают 80% базовых потребностей, и нужно просто добавить нужные расширения.
А настроив полную цепочку на маленьком проекте однажды — масштабировать решение на соседние проекты даже больших размеров возможно за пару часов с абсолютного нуля.
Если вам интересно заниматься подобными вещами, интересно строить автоматически масштабируемые системы, облегчающие разработку, сборку, а главное, тестирование, если интересно повышать качество продуктов, которыми пользуются от мала до велика, добро пожаловать к нам в Школу автоматизации процессов разработки!

Сегодня мы покажем, что Continuous Delivery — это просто и весело! А пользу от него можно получить, встроив его даже частично. Мы в тестировании Яндекса уже несколько лет используем подобный подход для наших библиотек с открытым исходным кодом — Allure Framework или Yandex QATools. Процесс прост, значительно масштабируем и может применяться как для огромных команд из одного человека, так и для маленьких командочек из десятков человек. А самое главное — весь инструментарий доступен в Open Source!
Кстати, до 30 сентября можно подать заявку и поступить в нашу Школу автоматизации процессов разработки в Питере. Обучение в ней бесплатное и будет состоять не только из курса лекций — обязательным этапом станет командная работа над учебным проектом.
А теперь вернёмся к теме. Представьте картину: уютное рабочее место, вы пишете код, добавляете юнит-тесты и отправляете изменения в систему контроля версий, а через пару часов они «выезжают» на боевые сервера. И все при этом работает.
Кажется, что такой процесс характерен либо для метода разработки «хлобысь, хлобысь и в продакшен» (убрав часть про юнит-тесты), либо для рекламного ролика компании, специализирующейся на инновациях при разработке ПО. При этом под ним обязательно нужна бегущая строка, аналогичная подписи под каскадёрскими трюками: «Опасно, не пытайтесь повторить дома!».
Как это было раньше
История одного разработчика. Где-то слышал задачу о бэкапах: «Сколько грузовиков нужно, чтобы администратор начал делать резервные копии?». Юмор черный, поэтому решение жду в комментариях. Здесь речь идет о процессе разработки, но суть не меняется. Разработчик отправляет любое изменение в основную ветку и, посчитав, что пора собрать пакет для тестирования и выкладки, останавливается на стабильном, по его мнению, состоянии кода, обновляя ветку, из которой собираются пакеты. Теперь возникает вопрос: «Что содержится в новом пакете после очередной сборки?». Любой ответ на этот вопрос может быть неправильным. Ведь разработчик уверен, что меняет код только он, поэтому смотреть в историю изменений не нужно. Бывало, буквально чудом, находили при тестировании аномалии, которые могли серьёзно осложнить жизнь пользователям наших сервисов. Аномалиями оказывались несогласованные изменения, попавшие в ветку либо от разработчика из другого проекта, решившего исправить баг, либо собранные «за компанию» и просто забытые. Сложности ожидали и тех, кто решил бы влиться в процесс разработки. В какой ветке ведется разработка? В какой ветке стабильная версия? Как вообще собирать пакет?
А в случае, если в пакете находились ошибки, после их правок тестировщика мог ждать сюрприз — вместе с исправлениями могли «приехать» еще несколько новых возможностей. При особом везении после пары циклов пакет мог увеличить первоначальное количество задач в несколько раз и «распухнуть» до невообразимых размеров.
История нескольких разработчиков. Эта история отличается только тем, что в список ежедневной рутины каждому разработчику в команде добавляется слияние своих изменений с изменениями коллег. А еще ведь все друг другу доверяют и никто не смотрит на эти самые изменения коллег — они же знают, что пишут! Все бы и рады смотреть, что происходит с проектом, тем более когда коллега уходит в отпуск, все равно приходится разбираться, но где это делать? В среде разработки негде оставить комментарий. Лично сказать не всегда удобно, особенно если разработка ведется в разных офисах. Да и изменения уже в проекте — так просто не переделать в случае ошибок.
Что общего у этих историй? Отговорки. Все считают, что упростить себе жизнь, введя понятный процесс и автоматизировав рутину, слишком сложно. Кроме того, всем придется ломать себя об колено, чтобы привыкнуть к новым реалиям. Это не так. Мы уже разрушили в своих командах такой миф.
Бросаться разрушать вредные, но несущественные мифы, о которых никто не слышал и от которых никто не страдал, — непродуктивно. Поэтому, испытав первые трудности с доставкой изменений до конечных потребителей, текущую схему разработки пришлось менять.
Инструментарий
Для полного веселья потребуется: GitHub Flow как непосредственный процесс, CI сервер. Немного, правда? Наши библиотеки живут на GitHub, поэтому я буду пользоваться его терминологией, давая комментарии по ходу. Весь этот процесс вполне возможен почти на любых комбинациях CI-серверов и популярных площадках для IT-проектов, вроде GitLab, Bitbucket. Ключевое только одно: потребуется клей, называемый семейством расширений Pull Request Builders.
Соль за 5 секунд
Форк, коммит, пуш, реквест, билд, ревью, мерж, релиз.
Соль в три этапа
Все эти смешные слова я дальше употреблять не буду. Хоть и очень тянет! Тот, кто их знает и регулярно использует, скорее всего, давно внедрил подобный процесс. Эти короткие непонятные словечки так же легко выучить, как и реализовать следующие основные этапы в рамках задачи на легкое построение процесса:
- разработчик делает изменение;
- изменение смотрят другие;
- изменение попадает в основную ветку системы контроля версий.
Разработчик делает изменение
Точка входа — основной репозиторий, мастер-ветка. Один из главных бонусов подхода — всегда известно, где находится стабильный рабочий код, который видел не только разработчик. Прямое изменение этой ветки запрещено. Даже если очень хочется.
На этом этапе потребуется только GitHub или аналог. Первое, что нужно сделать, — продублировать текущую мастер-ветку основного репозитория в свой личный репозиторий. Тут разработчик волен строить процесс кодирования так, как ему нравится. Это его личный репозиторий, и здесь он полновластный хозяин. Конечная цель проста — набор изменений, базирующийся на мастер-ветке основного репозитория, в любой ветке личного.
На этом этапе появляестя и самая большая сложность — приучить себя писать unit-тесты на свои изменения. Самое интересное, что сложность не в том, чтобы написать эти тесты, а именно приучить себя их делать. Но если выработать такую привычку, она окупит почти любые трудозатраты на само написание тестов. Начните с малого: покрывайте позитивные сценарии. Их легко продумать, легко реализовать в тестах. Привыкнув не бояться за поломку заявленной функциональности, легко добавить негативные сценарии. Это избавит от страха непоправимо сломаться в неожиданных местах. Изменения готовы к демонстрации?
Изменения смотрят другие
По набору возможных печенек и вариантов реализации это самый технологичный этап. Этап не просто так называется «смотрят другие» — без слова «разработчики». Автоматика!
Для начала разработчику нужно запустить процесс — предложить свои изменения к слиянию в основную ветку проекта. Думаю, не нужно говорить о том, что телепаты обычно в отъезде, поэтому сообщения к каждому изменению должны четко отражать их суть. Особенно сильно это ощущается, когда сам возвращаешься после перерыва к работе над проектом и обнаруживаешь чужие изменения. Хорошо, если понятно, что произошло по заголовкам в истории GIT. Ведь после отпуска не очень-то хочется, разглядывая разницу, переваривать тонны изменений, чтобы внести маленькое исправление. В проектах с открытым исходным кодом это более чем важно — здесь за вашей историей следят уже сотни человек!

Тут в дело и вступает CI-сервер. Мы используем два: TeamCity & Jenkins. Какой точно использовать, мы так до конца и не определились. Зависит в основном от предпочтений настраивающего новую задачу на сборку. Для того чтобы сборка началась, как только в основной репозиторий приехало предложение на слияние, потребуется тот самый клей — одно из расширений семейства «Pull Request Builders».
Например, для Jenkins + GitHub это GitHub PRBP.
Для Jenkins + Bitbucket это Bitbucket PRBP.
Для Teamcity + Github это TeamCity.GitHub.
CI-сервер заботливо соберет предложенное изменение, прогонит тесты и обязательно сообщит о проблемах в самом предложении на слияние:

Прямо здесь же стоит настроить и статический анализ кода. Сейчас можно автоматически находить огромное количество ошибок в коде! Например, при помощи SonarQube. Он сможет измерить покрытие тестами и предупредить, если оно вдруг упадет. Получение обратной связи занимает минуты! Исправить ошибки можно в той же самой ветке, из которой было предложение:

Не стоит бояться совсем перезаписать историю в этой ветке. GitHub, например, быстро обновит предложение, а CI-сервер снова пересоберет его. Во многих проектах с открытым исходным кодом такое правило отдельно прописано.
После успешной сборки — время для осмотра кода живым человеком. Конечно, если вы единственный разработчик, вам может быть некого просить посмотреть ваш код. В этом случае представляется отличный шанс самому критично взглянуть на внесенные изменения. После пройденной сборки и осмотра кода остается нажать всего одну кнопку — залить изменения в основную ветку. Ответственный шаг. Во всех системах отражается, кто это сделал.
При небольших изменениях, чтение этого раздела отнимает гораздо больше времени, чем то, о чем он написан.
Изменения попадают в основную ветку системы контроля версий
Как только изменения попали в основную ветку, наступает время интеграционного тестирования. Здесь удобнее всего поставить на караул задачу на сборку тестовых пакетов. Мы в наших библиотеках в этот момент обновляем SNAPSHOT версию в Maven репозитории. Тут уже гоняются тяжелые интеграционные тесты, проверяющие взаимодействие со сторонними компонентами, запускаются браузерные тесты, где это требуется. На этом этапе вполне реально отдать пакеты в ручное тестирование.
Чем приятен и удобен весь этот процесс? Он очень гибок. Все эти действия легко разнести на несколько каскадов. Например, делать сначала запрос на слияние в нестабильную ветку, в ней проводить все тяжелые действия по тестированию, а после них — отправлять запрос на слияние в основную ветку, в рамках которого собирать пакет на отправку на боевые сервера. И принимать запрос на слияние только после успешной выкладки. Либо наоборот — всё-всё тестирование проводить в рамках одного запроса, работая и пересобирая пакеты прямо на ходу, отправляя в основную ветку уже готовые к выкладке изменения. Это зависит от конкретной ситуации и укоренившихся привычек команды.
Как только в основной ветке накопилось достаточное количество изменений, которыми все участники довольны в нужной степени, приходит время релиза. Обычно это еще одна задача на сборку с ручным вызовом. В GitHub, например, для этого используют команду для HuBot. Очень удобно помечать в этот момент головное изменение тегом. Это позволит в любой момент при желании получить возможность собрать нужную версию, не вспоминая номер изменения.

Выбор версии релиза — отдельный процесс, для которого существуют даже особые стандарты. Для маленьких библиотек мы пользуемся двухциферной нотацией: младшая растет каждый релиз, старшая при потере обратной совместимости обнуляет младшую. Для библиотек побольше — трехциферной с аналогичной логикой.
Я тоже так хочу!
Для того чтобы организовать подобный процесс даже не нужно иметь собственный CI-сервер. Для маленьких проектов очень удобно использовать www.cloudbees.com/jenkins, который даст полноценный Jenkins-сервер с ограничением на количество сборок. Начать собирать предложения на слияние на GitHub вполне реально используя buildhive.cloudbees.com — у него нет лимитов. Либо travis-ci.org, для которого нужно в корень проекта положить небольшой конфигурационный файлик.
Если же у вас под рукой свой сервер, настроить на нем Jenkins или TeamCity — дело получаса. Настройки по умолчанию в этих серверах перекрывают 80% базовых потребностей, и нужно просто добавить нужные расширения.
А настроив полную цепочку на маленьком проекте однажды — масштабировать решение на соседние проекты даже больших размеров возможно за пару часов с абсолютного нуля.
Мы научим!
Если вам интересно заниматься подобными вещами, интересно строить автоматически масштабируемые системы, облегчающие разработку, сборку, а главное, тестирование, если интересно повышать качество продуктов, которыми пользуются от мала до велика, добро пожаловать к нам в Школу автоматизации процессов разработки!
