
Перед разработчикам, которые используют API Яндекс.Карт, довольно часто встаёт задача отобразить много объектов на карте. Действительно много — порядка 10 000. Причем эта задача актуальна и для нас самих — попробуйте поискать аптеки на Яндексе. На первый взгляд кажется: «А в чем собственно проблема? Бери да показывай». Но пока не начнешь этим заниматься, не поймешь, что проблем на самом деле целый вагон.
Вопросы по большому количеству меток с завидной регулярностью поступают в наш клуб и техподдержку. Кто все эти люди? Кому может быть интересно показать на карте больше 10 меток? В этом посте я подробно рассмотрю весь вагон проблем и расскажу, как в API появились инструменты, помогающие разработчикам оптимально показать большое количество объектов на карте.
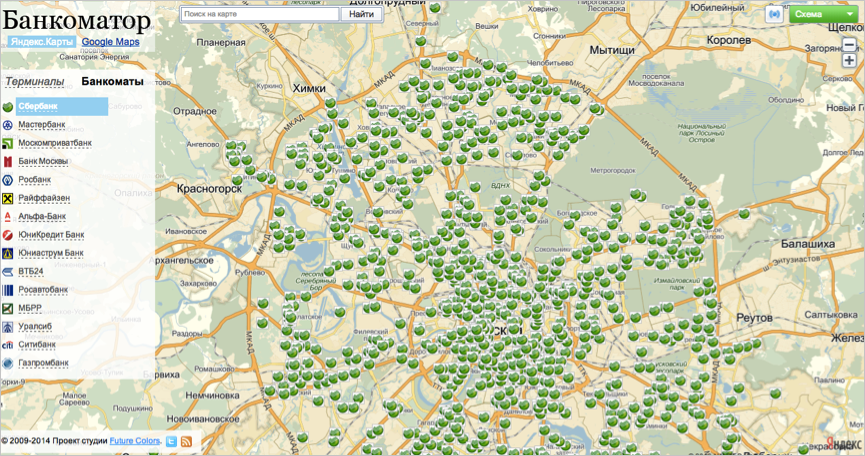
В основном с проблемой сталкиваются информационные сервисы, которые хотят привязать данные к карте. Например сайт bankomator.ru рассказывает пользователям, где найти банкомат нужного банка.
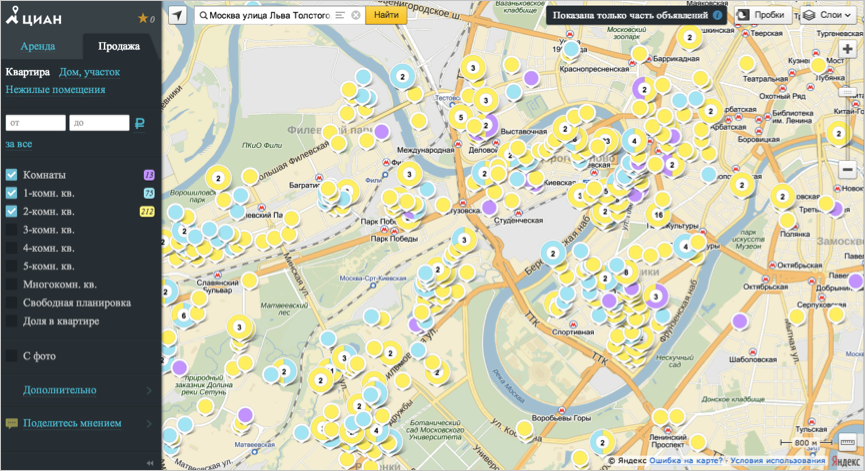
Также от большого количества данных страдают ресурсы, посвященные недвижимости. Яркий пример – Cian.ru.
Мы сами внутри Яндекса до недавнего времени советовали смежным командам различные «хаки» и приемы для показа множества точек через API. Яркие примеры – Яндекс.Недвижимость и Яндекс.Такси.
Чтобы прочувствовать на себе всю тяжесть поставленной задачи, нужно попробовать ее решить. Для начала давайте поймем, как показать карту на странице вашего сервиса. Рассмотрим простую схему:
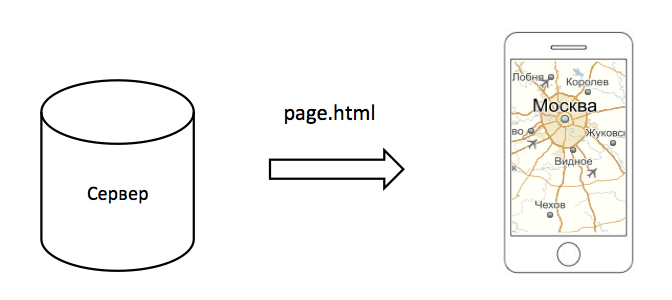
Клиент (например, Safari на iPhone) запрашивает с сервера страницу index.html. Страница представляет собой документ вот с таким кодом:
Теперь усложняем задачу. У нас есть база данных, в которой хранятся адреса болельщиков «Зенита». И мы хотим показать на карте адреса этих болельщиков.
Решение задачи «в лоб»:
Если вы менеджер проекта, и ваш разработчик демонстрирует такое решение, скорее всего, вы поседеете. Вы выскажете ему свое оценочное суждение. Если убрать нецензурную брань, можно будет выделить следующие тезисы:
Мысль получает два направления:
В API Яндекс.Карт сто лет назад был сделан инструмент для решения этих задач – технология активных областей. Кому интересно подробно, почитайте руководство разработчика.
Кратко – вы генерируете на сервере прозрачные картинки с метками плюс текстовое описание меток. Клиент может следить за видимой областью карты и запрашивать данные, которые нужны для текущей видимой области карты.
С помощью хотспотов, например, рисуются пробки на maps.yandex.ru. На этой же технологии сделан сайт bankomator.ru.
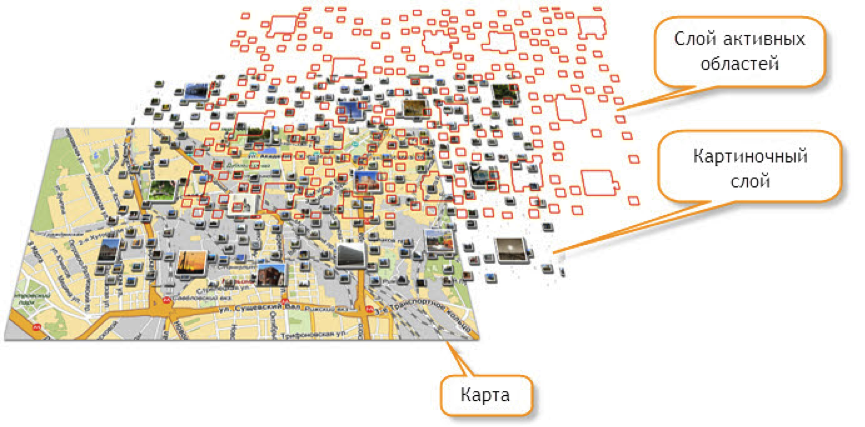
У этой технологии есть несколько существенных минусов
1. Очень сложная серверная часть. Попробуйте на досуге написать модуль, который генерирует вот такие картинки и их геометрические описания, и вы все поймете.

2. Абсолютная негибкость. Невозможно «приподнять» метку при наведении на нее курсора. Невозможно быстро поменять на клиенте внешний вид меток. Короче – на любой чих надо просить сервер перегенерировать картинку.
Поэтому пользователи крутились, как могли, без хотспотов – передавали наборы единичных объектов на клиент пачками, через таймаут. При этом на клиенте их снова ждали проблемы. Если вы передали на клиент 1000 точек, как их отрисовать?
Из каждой точки нужно было сгенерировать объект

Подытожив все эти дела, мы решили написать модуль, который бы позволил:
И мы это сделали.Мы котики.
Чтобы научиться рисовать метки быстро, надо было понять, какие проблемы кроются в текущем, уже существующем решении. Давайте посмотрим, что может делать объект
Кроме того, метка динамически реагирует на любое изменение внешней среды – изменение опций, данных, проекции карты, смена масштаба карты, смена центра карты и многое, многое другое. Такие вот у нас могучие плейсмарки.

А нужна ли вся эта программная мощь для случая, когда разработчику просто нужно показать много однотипных меток на карте? Правильно, не нужна.
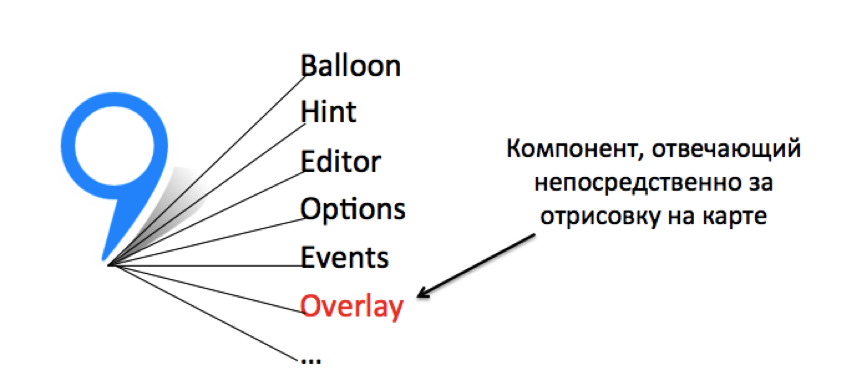
Поэтому первое озарение заключалось в следующем: а давайте вынесем все вспомогательные модули меток в один общий компонент и для каждого отдельного объекта будем создавать только программную сущность, которая непосредственно отвечает за отрисовку.
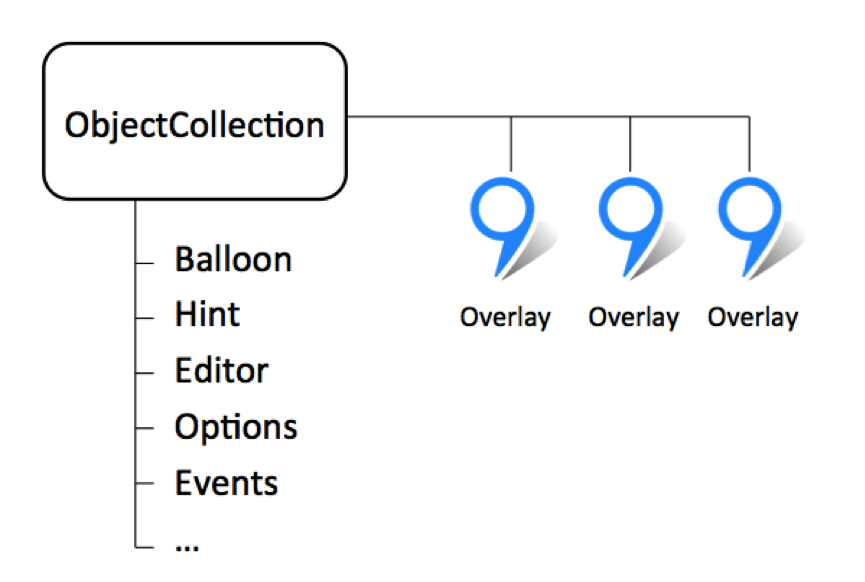
Второе озарение пришло, когда мы думали над проблемой лишних программных инициализаций. Вспоминаем рассказ выше, где-то в районе вот такой картинки.
Нам захотелось избавиться от лишних программных инициализаций, и мы придумали гениальное. Садитесь поудобнее, сейчас будет откровение: если вам мешают лишние программные инициализации – не делайте их.
Мы решили, что будем хранить пользовательские данные об объектах (по факту в JSON), а программные сущности для объектов будут создаваться только тогда, когда какой-либо объект нужно будет отрисовать на карте.

После комбинации этих идей и некоторой разработки родился новый модуль API для отображения большого количества точечных объектов – ymaps.ObjectManager.
На вход этого менеджера скармливается JSON-описание объектов.
Менеджер анализирует, какие метки попадают в видимую область карты и либо рисует метки, либо кластеризует эти метки и показывает результат на карте.
Для отрисовки меток и кластеров на карте мы взяли только часть объекта
Эти приемы позволили нам неплохо продвинуться в вопросе отрисовки большого числа меток на клиенте. Вот какие мы получили приросты по скорости:
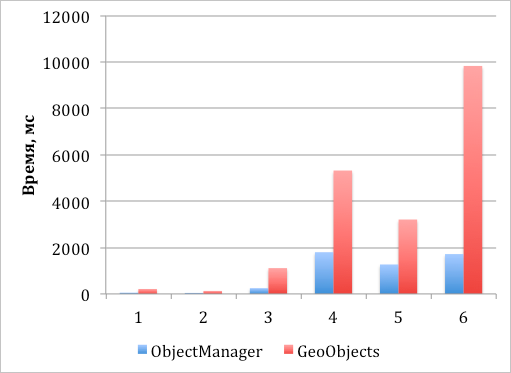
График 1. Скорость создания и добавления объектов на карту с последующей асинхронной отрисовкой их видимой части
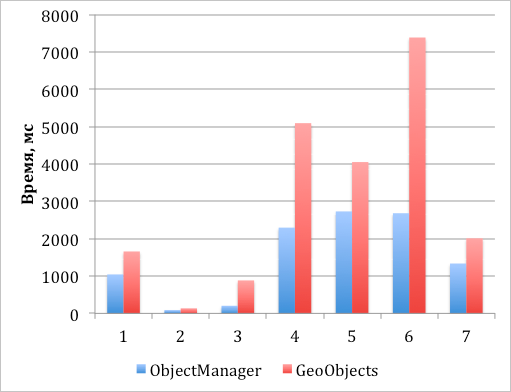
График 2. Скорость создания и добавления объектов на карту с последующей синхронной отрисовкой их видимой части
Важное замечание. Вся эта статистика справедлива для современных браузеров. IE8 к числу этих браузеров не относится. Поэтому для него цифры будут значительно хуже, но думаю для большинства это не имеет значения.
У нас получилось ускорить непосредственно создание и отрисовку объектов, вдобавок к этому мы максимально оптимизировали инициализацию программных сущностей. Теперь вы можете, например, откластеризовать на клиенте 50 000 точек, и работать с картой будет комфортно.
Почитать подробно про модуль можно в нашем руководстве разработчика, а посмотреть вживую примеры работы модуля — в песочнице.
Итак, мы научились быстро-быстро рисовать и кластеризовать точки на клиенте. Что дальше?
Помните пример про болельщиков «Зенита»? Мы решили проблему отрисовки данных на клиенте, но никак не решили проблему, связанную с оптимальной подгрузкой этих данных. Мы начали собирать типовые задачи пользователей API. По итогам исследований мы получили два типовых кейса:
Для решения этих кейсов были написаны модули LoadingObjectManager и RemoteObjectManager соответственно.Оба модуля основаны по сути на реализации ObjectManager, но имеют ряд различий в алгоритме загрузки и кеширования загруженных данных.
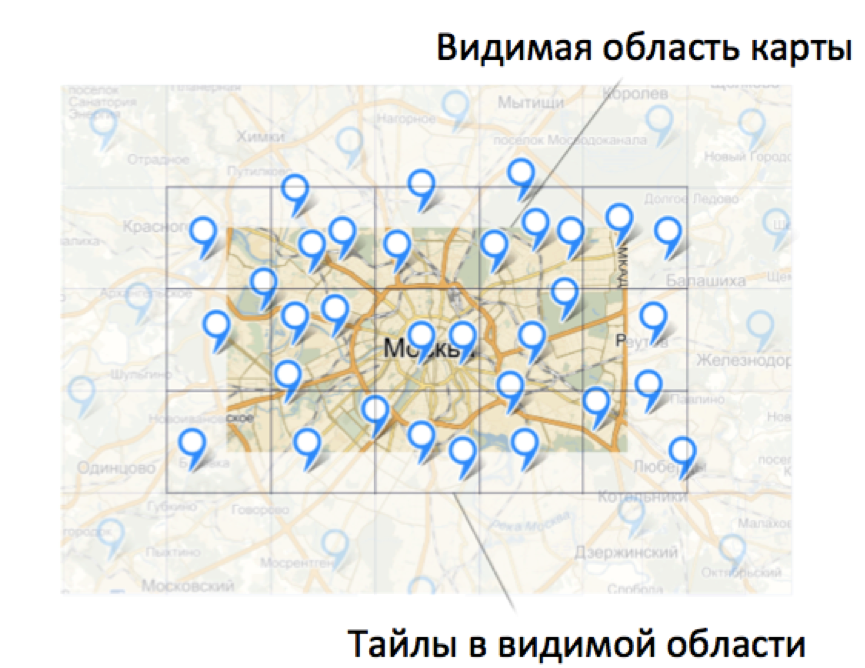
В итоге по мере работы пользователя с картой ему будут приходить данные из вашей базы. В какой-то момент все или необходимая часть данных будут подгружены и запросы на сервер вообще перестанут отправляться.
Данные хранятся на клиенте в pr-дереве, поэтому выборки даже для большого количества данных делаются довольно шустро.
Теперь обсудим вариант номер два – отображение на клиенте результатов серверной кластеризации. Допустим, вы написали серверную кластеризацию меток. Также вы написали скрипт, который по запросу от клиента умеет отдавать кластеры и единичные метки, не вошедшие в состав кластера.
Вам остается только создать инстанцию RemoteObjectManager и прописать в нем путь до этого чудо-скрипта. RemoteObjectManager будет работать почти так же, как и LoadingObjectManager. Разница будет только в том, что мы будем перезапрашивать данные с сервера при каждой смене зума.
Поскольку данные кластеризуются на сервере, то сервер и только сервер может знать, какие данные нужно, а какие не нужно показывать в данный момент на карте. Поэтому информация об объектах хранится на клиенте только до первой смены зума, а потом все запрашивается заново.
Если с сервера передается описание метки-кластера, то на клиенте эти метки подцепят всю инфраструктуру из API – для кластеров нарисуются специальные значки, для них будут работать все стандартные поведения и так далее и тому подобное.
В этом разделе мы хотим перечислить концепции хранения и обработки данных на сервере, которые мы предполагали при проектировании клиентской части. Пойдём от простого к сложному.
Клиентский код оперирует данными исключительно потайлово. Тайл – это некоторая нумерованная область на карте. Подробнее про нумерацию тайлов можно прочитать в нашей документации.
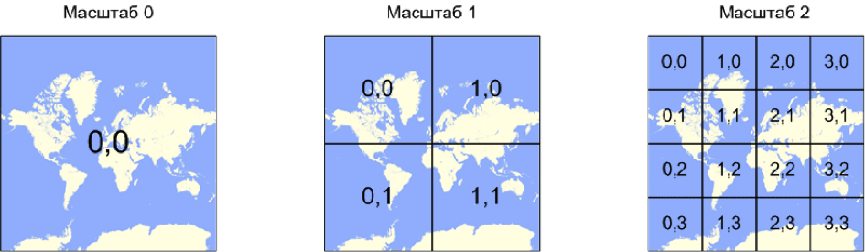
Когда на странице показывается некоторая область карты, клиентский модуль вычисляет, какие тайлы попали в эту видимую область, проверяет наличие нужных данных и отправляет запросы за данными по необходимости.
У клиентского модуля есть настройки, которые заставляют отправлять запросы за каждым новым тайлом по отдельности. Чем это ценно? Да тем, что мы получаем конечное число вариантов запроса клиента на сервер.
zoom=0, tile=[0, 0]
zoom=1, tile=[0, 0]
zoom=1, tile=[0, 1]
zoom=1, tile=[1, 0]
zoom=1, tile=[1, 1]
zoom=2, tile=[0, 0]
…
Поскольку запросы известны заранее, ответы на запросы тоже можно сгенерировать заранее. Организуем на сервере какую-то такую файловую структуру.
В файлах будет храниться примерно такой код:
При загрузке такого файла на клиенте будет вызван JSONP-callback, прописанный в файле. Данные попадут в недры LoadingObjectManager, закешируются и отрисуются в нужном виде.
В результате на сервере можно хранить просто статические файлы с наборами данных, а клиентская часть сама решит, что ей когда запросить и показать.
Существенным минусом вышеописанного решения является большое количество запросов за данными от клиента к серверу. Намного целесообразнее отправлять запрос сразу за несколькими тайлами, чем запрашивать данные для каждого тайла по отдельности.Но для обработки запросов за группами тайлов уже придется написать некоторый серверный код.
При этом данные можно продолжить хранить в отдельных файлах. Когда от клиента поступит запрос за данными в некоторой прямоугольной области, достаточно будет склеить содержимое нескольких файлов в один ответ и отправить его обратно на клиент.
Самый верный, на наш взгляд, путь – реализовать серверную часть с использованием какой-либо базы данных, умеющей индексировать геопривязанные данные. Для любой базы, не поддерживающей пространственные индексы, можно создать подобный индекс самостоятельно, используя концепцию пространственных ключей.
Вообще хранение геопривязанных данных на сервере и их кластеризация – тема отдельной беседы. Так что обсудим в другой раз.
В этом репозитории живет пример реализации серверной части с серверной grid-кластеризацией, написанный на node.js + mongo.db. может кому-то пригодится (Демо).
Сравнительная таблица новых модулей.
На данный момент мы поддерживаем работу только с точечными объектами. Поддержка полигонов, полилиний и прочих прекрасных фигур стоит у нас в планах и появится в будущих релизах.
Когда стоит задуматься об использовании этих модулей? Почти в любой ситуации, когда вам надо отрисовать на карте много точечных объектов.
Полезные ссылки:
Вопросы по большому количеству меток с завидной регулярностью поступают в наш клуб и техподдержку. Кто все эти люди? Кому может быть интересно показать на карте больше 10 меток? В этом посте я подробно рассмотрю весь вагон проблем и расскажу, как в API появились инструменты, помогающие разработчикам оптимально показать большое количество объектов на карте.
В основном с проблемой сталкиваются информационные сервисы, которые хотят привязать данные к карте. Например сайт bankomator.ru рассказывает пользователям, где найти банкомат нужного банка.
Также от большого количества данных страдают ресурсы, посвященные недвижимости. Яркий пример – Cian.ru.
Мы сами внутри Яндекса до недавнего времени советовали смежным командам различные «хаки» и приемы для показа множества точек через API. Яркие примеры – Яндекс.Недвижимость и Яндекс.Такси.
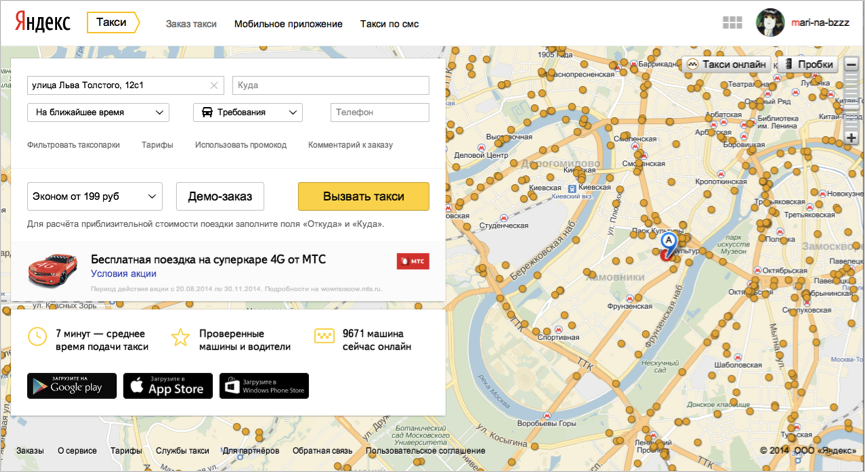
Пункт 1. В чем собственно проблема?
Чтобы прочувствовать на себе всю тяжесть поставленной задачи, нужно попробовать ее решить. Для начала давайте поймем, как показать карту на странице вашего сервиса. Рассмотрим простую схему:

Клиент (например, Safari на iPhone) запрашивает с сервера страницу index.html. Страница представляет собой документ вот с таким кодом:
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<script src="//api-maps.yandex.ru/2.1/?lang=ru_RU" type="text/javascript"></script>
<script type="text/javascript">
ymaps.ready(init);
function init () {
var myMap = new ymaps.Map('map', {
center: [55.76, 37.64],
zoom: 10
});
}
</script>
</head>
<body>
<div id="map"></div>
</body>
Теперь усложняем задачу. У нас есть база данных, в которой хранятся адреса болельщиков «Зенита». И мы хотим показать на карте адреса этих болельщиков.
Решение задачи «в лоб»:
- Делаем выборку из базы данных, получаем 1 млрд адресов.
- Дописываем в файл index.html массив, содержащий весь миллиард адресов.
- Передаем этот файл на клиент.
- На клиенте перебираем данные массива и рисуем для каждого элемента метку на карте.
Если вы менеджер проекта, и ваш разработчик демонстрирует такое решение, скорее всего, вы поседеете. Вы выскажете ему свое оценочное суждение. Если убрать нецензурную брань, можно будет выделить следующие тезисы:
- Вес файла index.html увеличится до нескольких Мб и у пользователя страница будет открываться по несколько секунд.
- Зачем передавать на клиент ВСЮ базу, если нужно показать только метки для Москвы?
- Зачем рисовать на карте ВСЕ метки, если человек увидит только десятую их часть?
- Если на карте нарисовать около 100-200 меток обычным способом, карта будет тормозить.
- Можно загружать метки постепенно, пачками, чтобы канал не забивался и браузер успевал эти метки отрисовывать?
Мысль получает два направления:
- Нужно уметь определять, какие данные видит пользователь и запрашивать только нужное.
- Когда это нужное пришло, его надо оптимально отрисовать.
В API Яндекс.Карт сто лет назад был сделан инструмент для решения этих задач – технология активных областей. Кому интересно подробно, почитайте руководство разработчика.
Кратко – вы генерируете на сервере прозрачные картинки с метками плюс текстовое описание меток. Клиент может следить за видимой областью карты и запрашивать данные, которые нужны для текущей видимой области карты.
С помощью хотспотов, например, рисуются пробки на maps.yandex.ru. На этой же технологии сделан сайт bankomator.ru.
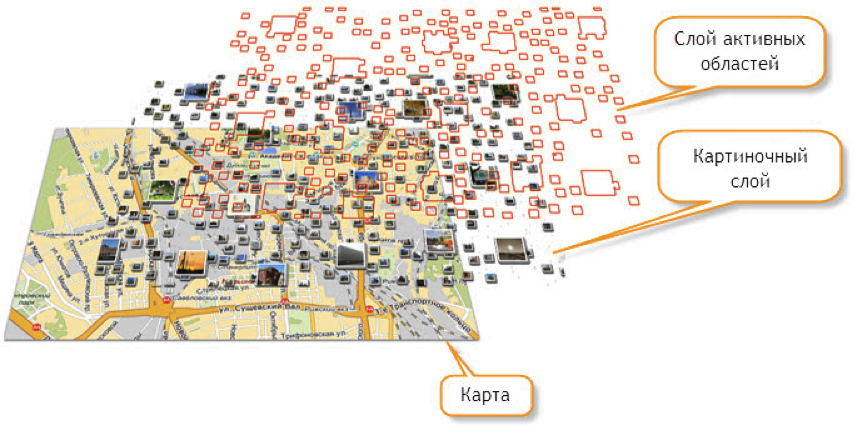
У этой технологии есть несколько существенных минусов
1. Очень сложная серверная часть. Попробуйте на досуге написать модуль, который генерирует вот такие картинки и их геометрические описания, и вы все поймете.

2. Абсолютная негибкость. Невозможно «приподнять» метку при наведении на нее курсора. Невозможно быстро поменять на клиенте внешний вид меток. Короче – на любой чих надо просить сервер перегенерировать картинку.
Поэтому пользователи крутились, как могли, без хотспотов – передавали наборы единичных объектов на клиент пачками, через таймаут. При этом на клиенте их снова ждали проблемы. Если вы передали на клиент 1000 точек, как их отрисовать?
Из каждой точки нужно было сгенерировать объект
ymaps.Placemark и добавить его на карту. Можно было добавить метки в кластеризатор (ymaps.Clusterer) и добавить откластеризованные метки на карту. Тут надо обратить внимание, что при кластеризации 10 000 точек нужно сначала эти 10 000 точек инстанцировать, а потом передать в кластеризатор. То есть метка может не показаться на карте, так как войдет в кластер, но мы все равно потратим время на ее инициализацию.
Подытожив все эти дела, мы решили написать модуль, который бы позволил:
- Быстро и легко отрисовать на клиенте большое количество точек.
- Избежать лишних инициализаций при работе с точками на клиенте.
- Загружать данные на клиент строго по требованию.
И мы это сделали.
Пункт 2. Рисуем метки быстро
Чтобы научиться рисовать метки быстро, надо было понять, какие проблемы кроются в текущем, уже существующем решении. Давайте посмотрим, что может делать объект
ymaps.Placemark:- Он умеет рисоваться на карте.
- У него есть свой менеджер балуна
placemark.balloon. - У него есть свой менеджер хинта
placemark.hint. - У него есть редактор, который позволяет перетаскивать метку и фиксировать ее координаты
placemark.editor.
Кроме того, метка динамически реагирует на любое изменение внешней среды – изменение опций, данных, проекции карты, смена масштаба карты, смена центра карты и многое, многое другое. Такие вот у нас могучие плейсмарки.

А нужна ли вся эта программная мощь для случая, когда разработчику просто нужно показать много однотипных меток на карте? Правильно, не нужна.
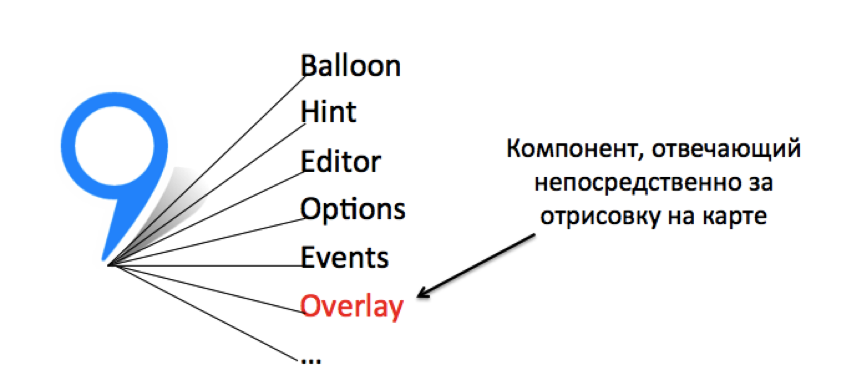
Поэтому первое озарение заключалось в следующем: а давайте вынесем все вспомогательные модули меток в один общий компонент и для каждого отдельного объекта будем создавать только программную сущность, которая непосредственно отвечает за отрисовку.

Второе озарение пришло, когда мы думали над проблемой лишних программных инициализаций. Вспоминаем рассказ выше, где-то в районе вот такой картинки.
Нам захотелось избавиться от лишних программных инициализаций, и мы придумали гениальное. Садитесь поудобнее, сейчас будет откровение: если вам мешают лишние программные инициализации – не делайте их.
Мы решили, что будем хранить пользовательские данные об объектах (по факту в JSON), а программные сущности для объектов будут создаваться только тогда, когда какой-либо объект нужно будет отрисовать на карте.

После комбинации этих идей и некоторой разработки родился новый модуль API для отображения большого количества точечных объектов – ymaps.ObjectManager.
На вход этого менеджера скармливается JSON-описание объектов.
Менеджер анализирует, какие метки попадают в видимую область карты и либо рисует метки, либо кластеризует эти метки и показывает результат на карте.
Для отрисовки меток и кластеров на карте мы взяли только часть объекта
ymaps.Placemark (а именно ymaps.overlay.*), которая отвечала только за отображение метки на карте. Всю инфраструктуру типа балунов и хинтов мы вынесли в единый общий компонент.Эти приемы позволили нам неплохо продвинуться в вопросе отрисовки большого числа меток на клиенте. Вот какие мы получили приросты по скорости:
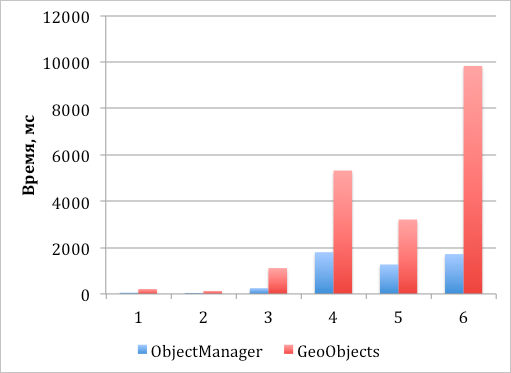
График 1. Скорость создания и добавления объектов на карту с последующей асинхронной отрисовкой их видимой части
- Создание 1000 меток и добавление их на карту, все метки видны.
- Создание 1000 меток и добавление их на карту с кластеризацией, все метки видны.
- Создание 10000 меток и добавление их на карту с кластеризацией, все метки видны.
- Создание 50 000 меток и добавление их на карту с кластеризацией, все метки видны.
- Создание 50 000 меток и добавление их на карту с кластеризацией, видны 500 объектов.
- Создание 50 000 меток и добавление их на карту без кластеризации, видны 10 000.

График 2. Скорость создания и добавления объектов на карту с последующей синхронной отрисовкой их видимой части
- Создание 1000 меток и добавление их на карту, все метки видны.
- Создание 1000 меток и добавление их на карту с кластеризацией, все метки видны.
- Создание 10000 меток и добавление их на карту с кластеризацией, все метки видны.
- Создание 50 000 меток и добавление их на карту с кластеризацией, все метки видны.
- Создание 50 000 меток и добавление их на карту с кластеризацией, видны 500 объектов.
- Создание 10 000 меток и добавление их на карту без кластеризации, видны 2000.
- Создание 5000 меток и добавление их на карту без кластеризации, видны 1000.
Важное замечание. Вся эта статистика справедлива для современных браузеров. IE8 к числу этих браузеров не относится. Поэтому для него цифры будут значительно хуже, но думаю для большинства это не имеет значения.
У нас получилось ускорить непосредственно создание и отрисовку объектов, вдобавок к этому мы максимально оптимизировали инициализацию программных сущностей. Теперь вы можете, например, откластеризовать на клиенте 50 000 точек, и работать с картой будет комфортно.
Почитать подробно про модуль можно в нашем руководстве разработчика, а посмотреть вживую примеры работы модуля — в песочнице.
Итак, мы научились быстро-быстро рисовать и кластеризовать точки на клиенте. Что дальше?
Пункт 3. Оптимально подгружаем данные
Помните пример про болельщиков «Зенита»? Мы решили проблему отрисовки данных на клиенте, но никак не решили проблему, связанную с оптимальной подгрузкой этих данных. Мы начали собирать типовые задачи пользователей API. По итогам исследований мы получили два типовых кейса:
- У человека на сервере много данных, он хочет показывать их на клиенте, но подгружать данные по мере надобности.
- Разработчик подготавливает данные на сервере (например, реализует серверную кластеризацию) и хочет показывать на клиенте результаты этой обработки.
Для решения этих кейсов были написаны модули LoadingObjectManager и RemoteObjectManager соответственно.Оба модуля основаны по сути на реализации ObjectManager, но имеют ряд различий в алгоритме загрузки и кеширования загруженных данных.
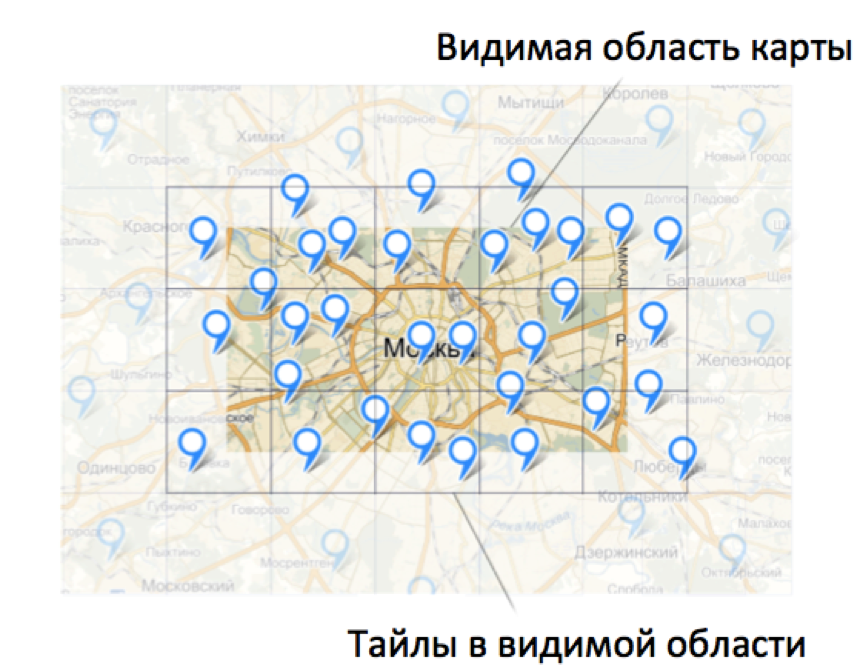
В итоге по мере работы пользователя с картой ему будут приходить данные из вашей базы. В какой-то момент все или необходимая часть данных будут подгружены и запросы на сервер вообще перестанут отправляться.
Данные хранятся на клиенте в pr-дереве, поэтому выборки даже для большого количества данных делаются довольно шустро.
Теперь обсудим вариант номер два – отображение на клиенте результатов серверной кластеризации. Допустим, вы написали серверную кластеризацию меток. Также вы написали скрипт, который по запросу от клиента умеет отдавать кластеры и единичные метки, не вошедшие в состав кластера.
Вам остается только создать инстанцию RemoteObjectManager и прописать в нем путь до этого чудо-скрипта. RemoteObjectManager будет работать почти так же, как и LoadingObjectManager. Разница будет только в том, что мы будем перезапрашивать данные с сервера при каждой смене зума.
Поскольку данные кластеризуются на сервере, то сервер и только сервер может знать, какие данные нужно, а какие не нужно показывать в данный момент на карте. Поэтому информация об объектах хранится на клиенте только до первой смены зума, а потом все запрашивается заново.
Если с сервера передается описание метки-кластера, то на клиенте эти метки подцепят всю инфраструктуру из API – для кластеров нарисуются специальные значки, для них будут работать все стандартные поведения и так далее и тому подобное.
Пункт 4. Размышления на тему серверной реализации
В этом разделе мы хотим перечислить концепции хранения и обработки данных на сервере, которые мы предполагали при проектировании клиентской части. Пойдём от простого к сложному.
1. Хранение информации об объектах на сервере в статических файлах
Клиентский код оперирует данными исключительно потайлово. Тайл – это некоторая нумерованная область на карте. Подробнее про нумерацию тайлов можно прочитать в нашей документации.
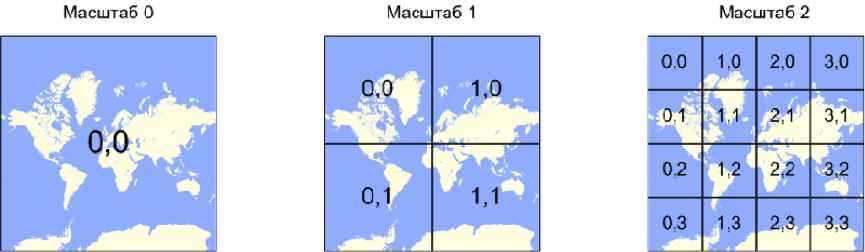
Когда на странице показывается некоторая область карты, клиентский модуль вычисляет, какие тайлы попали в эту видимую область, проверяет наличие нужных данных и отправляет запросы за данными по необходимости.
У клиентского модуля есть настройки, которые заставляют отправлять запросы за каждым новым тайлом по отдельности. Чем это ценно? Да тем, что мы получаем конечное число вариантов запроса клиента на сервер.
zoom=0, tile=[0, 0]
zoom=1, tile=[0, 0]
zoom=1, tile=[0, 1]
zoom=1, tile=[1, 0]
zoom=1, tile=[1, 1]
zoom=2, tile=[0, 0]
…
Поскольку запросы известны заранее, ответы на запросы тоже можно сгенерировать заранее. Организуем на сервере какую-то такую файловую структуру.
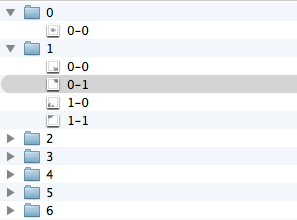
В файлах будет храниться примерно такой код:
myCallback_x_1_y_2_z_5({
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"id": 0,
"geometry": {
"type": "Point",
"coordinates": [55.831903, 37.411961]
},
"properties": {
"balloonContent": "Содержимое балуна",
"clusterCaption": "Метка 1",
"hintContent": "Текст подсказки"
}
},
...
]
}
При загрузке такого файла на клиенте будет вызван JSONP-callback, прописанный в файле. Данные попадут в недры LoadingObjectManager, закешируются и отрисуются в нужном виде.
В результате на сервере можно хранить просто статические файлы с наборами данных, а клиентская часть сама решит, что ей когда запросить и показать.
2. Динамическое формирование ответа из статических файлов
Существенным минусом вышеописанного решения является большое количество запросов за данными от клиента к серверу. Намного целесообразнее отправлять запрос сразу за несколькими тайлами, чем запрашивать данные для каждого тайла по отдельности.Но для обработки запросов за группами тайлов уже придется написать некоторый серверный код.
При этом данные можно продолжить хранить в отдельных файлах. Когда от клиента поступит запрос за данными в некоторой прямоугольной области, достаточно будет склеить содержимое нескольких файлов в один ответ и отправить его обратно на клиент.
3. Динамическое формирование ответа с использованием базы данных
Самый верный, на наш взгляд, путь – реализовать серверную часть с использованием какой-либо базы данных, умеющей индексировать геопривязанные данные. Для любой базы, не поддерживающей пространственные индексы, можно создать подобный индекс самостоятельно, используя концепцию пространственных ключей.
Вообще хранение геопривязанных данных на сервере и их кластеризация – тема отдельной беседы. Так что обсудим в другой раз.
В этом репозитории живет пример реализации серверной части с серверной grid-кластеризацией, написанный на node.js + mongo.db. может кому-то пригодится (Демо).
Заключение
Сравнительная таблица новых модулей.
| Модуль | Преимущества | Недостатки |
|---|---|---|
| ObjectManager | Позволяет кластеризовать объекты на клиенте. Отрисовка производится только тех объектов, которые попадают в видимую область карты. Позволяет фильтровать объекты при их отображении. Нет необходимости реализовывать серверную часть, поскольку вся обработка данных производится на стороне клиента. |
Поддерживает работу только с метками. Данные загружаются для всех объектов сразу (даже для тех, которые не попадают в видимую область карты). Кластеризация объектов производится на стороне клиента. |
| LoadingObjectManager | Позволяет кластеризовать объекты на клиенте. Загружает данные только для видимой области карты. Сохраняет загруженные данные. Для каждого объекта данные загружаются только один раз. Позволяет фильтровать объекты при их отображении. |
Поддерживает работу только с метками. Кластеризация объектов производится на стороне клиента. Необходимо реализовать серверную часть. |
| RemoteObjectManager | Использует серверную кластеризацию данных. Данные объектов хранятся на сервере. Каждый раз подгружаются данные только для тех объектов, которые попадают в видимую область карты. |
Поддерживает работу только с метками. При изменении коэффициента масштабирования данные загружаются заново (даже для тех объектов, для которых данные уже были загружены). Необходимо реализовывать собственную кластеризацию. Необходимо реализовать серверную часть. |
На данный момент мы поддерживаем работу только с точечными объектами. Поддержка полигонов, полилиний и прочих прекрасных фигур стоит у нас в планах и появится в будущих релизах.
Когда стоит задуматься об использовании этих модулей? Почти в любой ситуации, когда вам надо отрисовать на карте много точечных объектов.
Полезные ссылки:
- Подробнейшее руководство разработчика с картинками – tech.yandex.ru/maps/doc/jsapi/2.1/dg/concepts/many-objects-docpage.
- Примеры в песочнице – tech.yandex.ru/maps/jsbox/2.1/object_manager
- Проект на гитхабе с примером реализации серверной части для RemoteObjectManager – github.com/dimik/geohosting-server.
- Клуб разработчиков API Яндекс.Карт, куда нужно приходить с вопросами – clubs.ya.ru/mapsapi.
