
Только что в Париже на конференции LeWeb Яндекс объявил об открытии нового важного направления своей деятельности — по коммерческой обработке больших данных — Yandex Data Factory.
Мы верим, что обработка больших данных — это часть нового витка технической революции, который сделает всё человечество ещё более эффективным и приведёт нас к будущему, которое мы сейчас ещё даже не можем до конца представить. И в нём работа с большими объёмами данных будет не менее важной и распространённой, чем выработка электричества или железные дороги сегодня.

Перед публичным запуском Yandex Data Factory мы провели несколько пилотных проектов с компаниями-партнёрами. Для компании, обслуживающей линии электропередач, в Yandex Data Factory создали систему, которая анализирует сделанные беспилотниками снимки и автоматически выявляет угрозы: например, деревья, растущие слишком близко к проводам. А для автодорожного агентства проанализировали данные о загруженности дорог, качестве покрытия, средней скорости движения транспорта и аварийности. Это позволило в режиме реального времени составлять прогноз заторов на дорогах на ближайший час и выявлять участки с высокой вероятностью ДТП.
Кажется, каждый раз, когда человечество учится экономить где-нибудь 10%, происходит индустриальная революция. 200 лет назад стали использовать паровую машину. Сто лет назад благодаря развитию химии появились новые искусственные материалы. Электроника в XX веке изменила не только производство, но и быт. Когда люди поняли, что обрабатывать материалы дешевле в Китае и Юго-Восточной Азии, все промышленное производство мира переехало туда. На самом деле, 10% экономии — это мировые сдвиги. Анализ данных может помочь мировому производству и экономике стать более эффективными.
Интернет — не единственное место, где есть большие данные. Исторически еще в 60-70-х прошлого века их генерировали геологи. Они наблюдали за тем, как отражаются волны от взрывов на поверхности — это был их способ посмотреть под землю. В геологоразведке есть, что анализировать. И два года назад мы предоставили свои технологии параллельных вычислений и оборудование для обработки геолого-геофизических данных. Алгоритмы стали новым способом посмотреть под землю.
Многие из нас думают, что Wi-Fi в самолетах нужен для того, чтобы мы могли пользоваться своими устройствами во время полетов. Но изначально интернет в них появлялся, потому что современный самолёт — это тысячи датчиков, которые все время своего полёта измеряют огромное количество показателей и генерируют данные. Их часть передаётся на землю еще до посадки, а после неё из самолёта извлекают терабайтный диск и сохраняют его, не зная, что делать со всем, что на нём записано.
Но если посмотреть даже на те данные, которые передаются во время полёта, можно заранее предсказать, какие запчасти, например, нужно заменить в самолёте. Это сэкономит и время пассажиров, и ресурсы авиастроения, которое теряет 10% на простоях из-за запчастей. Сам Яндекс — это буквально улицы из серверов, которые потребляют 120 МВт мощности. И даже когда у вас сотни тысяч серверов, одновременно всегда в любую секунду не работает несколько сот дисков. Машина может предсказать, какой диск следующим выйдет из строя, и подскажет, что его надо поменять.
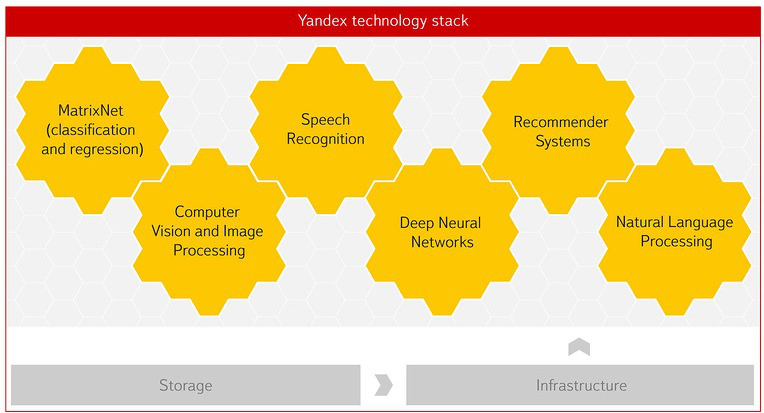
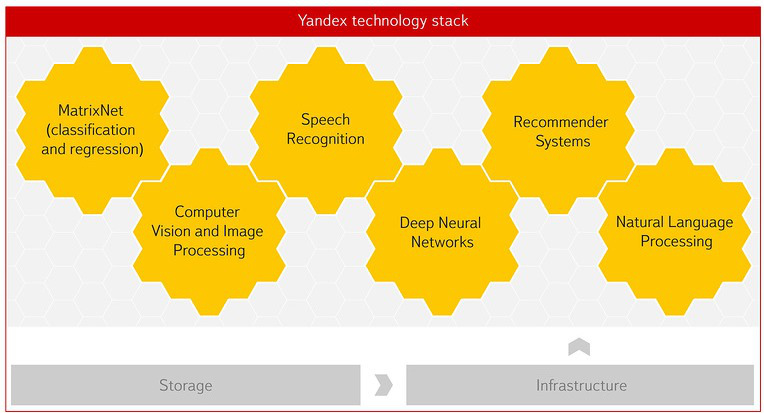
Яндекс — одна из немногих компаний мира, обладающих нужными для этого технологиями и экспертизой. Поиск в интернете невозможен без машинного обучения и умения анализировать данные. Сейчас они стоят практически за всем в Яндексе — прогнозом пробок, статистическим переводом, распознаванием речи и изображений. Большое влияние на становление этого оказала советская научная школа. Впоследствии мы создали Школу анализа данных, чтобы готовить специалистов, которые умеют работать с данными. В Высшей школе экономики при нашем участии появился факультет компьютерных наук, где в том числе есть департамент анализа данных и искусственного интеллекта.
Матрикснет — наша технология машинного обучения изначально создавалась, чтобы решать задачи ранжирования в поиске. Сейчас её используют ученые в ЦЕРНе. Один из проектов связан с построением системы отбора данных о столкновениях частиц в коллайдере в реальном времени. Это точный и гибкий фильтр, основанный на Матрикснете, который позволяет учёным очень быстро получать в распоряжение только интересные и важные данные о столкновениях частиц в БАК, чтобы использовать их в научных работах. Иногда это сверхредкие данные, встречающиеся, например, в 100 тысячах случаях на 100 миллиардов. Больше половины всех научных статей LHCb основаны как раз на данных, отфильтрованных нашим алгоритмом на базе Матрикснета.

Второй наш проект с ЦЕРНом — оптимизация хранилища данных. За два года работы БАК сгенерировал петабайты данных, которые хранятся на жестких дисках, чтобы у учёных был к ним оперативный доступ. Но место на HDD уже заканчивается, и какую-то часть данных нужно переносить на ленточные накопители. Это более дешевый способ хранения, но и менее гибкий — не так просто искать данные на ленте. Надо понять, какую именно часть файлов переносить, а какую — оставить на жестких дисках. Мы предложили ЦЕРНу помочь проранжировать тысячи накопленных файлов об экспериментах и выделить данные, которые необходимо оставить на HDD. Таким образом, мы поможем высвободить несколько петабайтов на HDD, а это десятки процентов.
Количество данных растет очень быстрыми темпами. Каждый из нас носит огромный источник данных в кармане — телефон. Датчики становятся всё дешевле, данных на сервера отправляется все больше, и встаёт вопрос, что с ними делать. Нам кажется, что если мы научимся их использовать и как-то с ними работать, то есть шансы сэкономить мировой экономике 10% ресурсов. И, если это случится, нас ждёт новая индустриальная революция.
Мы верим, что обработка больших данных — это часть нового витка технической революции, который сделает всё человечество ещё более эффективным и приведёт нас к будущему, которое мы сейчас ещё даже не можем до конца представить. И в нём работа с большими объёмами данных будет не менее важной и распространённой, чем выработка электричества или железные дороги сегодня.

Перед публичным запуском Yandex Data Factory мы провели несколько пилотных проектов с компаниями-партнёрами. Для компании, обслуживающей линии электропередач, в Yandex Data Factory создали систему, которая анализирует сделанные беспилотниками снимки и автоматически выявляет угрозы: например, деревья, растущие слишком близко к проводам. А для автодорожного агентства проанализировали данные о загруженности дорог, качестве покрытия, средней скорости движения транспорта и аварийности. Это позволило в режиме реального времени составлять прогноз заторов на дорогах на ближайший час и выявлять участки с высокой вероятностью ДТП.
Кажется, каждый раз, когда человечество учится экономить где-нибудь 10%, происходит индустриальная революция. 200 лет назад стали использовать паровую машину. Сто лет назад благодаря развитию химии появились новые искусственные материалы. Электроника в XX веке изменила не только производство, но и быт. Когда люди поняли, что обрабатывать материалы дешевле в Китае и Юго-Восточной Азии, все промышленное производство мира переехало туда. На самом деле, 10% экономии — это мировые сдвиги. Анализ данных может помочь мировому производству и экономике стать более эффективными.
Интернет — не единственное место, где есть большие данные. Исторически еще в 60-70-х прошлого века их генерировали геологи. Они наблюдали за тем, как отражаются волны от взрывов на поверхности — это был их способ посмотреть под землю. В геологоразведке есть, что анализировать. И два года назад мы предоставили свои технологии параллельных вычислений и оборудование для обработки геолого-геофизических данных. Алгоритмы стали новым способом посмотреть под землю.
Многие из нас думают, что Wi-Fi в самолетах нужен для того, чтобы мы могли пользоваться своими устройствами во время полетов. Но изначально интернет в них появлялся, потому что современный самолёт — это тысячи датчиков, которые все время своего полёта измеряют огромное количество показателей и генерируют данные. Их часть передаётся на землю еще до посадки, а после неё из самолёта извлекают терабайтный диск и сохраняют его, не зная, что делать со всем, что на нём записано.
Но если посмотреть даже на те данные, которые передаются во время полёта, можно заранее предсказать, какие запчасти, например, нужно заменить в самолёте. Это сэкономит и время пассажиров, и ресурсы авиастроения, которое теряет 10% на простоях из-за запчастей. Сам Яндекс — это буквально улицы из серверов, которые потребляют 120 МВт мощности. И даже когда у вас сотни тысяч серверов, одновременно всегда в любую секунду не работает несколько сот дисков. Машина может предсказать, какой диск следующим выйдет из строя, и подскажет, что его надо поменять.
Яндекс — одна из немногих компаний мира, обладающих нужными для этого технологиями и экспертизой. Поиск в интернете невозможен без машинного обучения и умения анализировать данные. Сейчас они стоят практически за всем в Яндексе — прогнозом пробок, статистическим переводом, распознаванием речи и изображений. Большое влияние на становление этого оказала советская научная школа. Впоследствии мы создали Школу анализа данных, чтобы готовить специалистов, которые умеют работать с данными. В Высшей школе экономики при нашем участии появился факультет компьютерных наук, где в том числе есть департамент анализа данных и искусственного интеллекта.
Матрикснет — наша технология машинного обучения изначально создавалась, чтобы решать задачи ранжирования в поиске. Сейчас её используют ученые в ЦЕРНе. Один из проектов связан с построением системы отбора данных о столкновениях частиц в коллайдере в реальном времени. Это точный и гибкий фильтр, основанный на Матрикснете, который позволяет учёным очень быстро получать в распоряжение только интересные и важные данные о столкновениях частиц в БАК, чтобы использовать их в научных работах. Иногда это сверхредкие данные, встречающиеся, например, в 100 тысячах случаях на 100 миллиардов. Больше половины всех научных статей LHCb основаны как раз на данных, отфильтрованных нашим алгоритмом на базе Матрикснета.

Второй наш проект с ЦЕРНом — оптимизация хранилища данных. За два года работы БАК сгенерировал петабайты данных, которые хранятся на жестких дисках, чтобы у учёных был к ним оперативный доступ. Но место на HDD уже заканчивается, и какую-то часть данных нужно переносить на ленточные накопители. Это более дешевый способ хранения, но и менее гибкий — не так просто искать данные на ленте. Надо понять, какую именно часть файлов переносить, а какую — оставить на жестких дисках. Мы предложили ЦЕРНу помочь проранжировать тысячи накопленных файлов об экспериментах и выделить данные, которые необходимо оставить на HDD. Таким образом, мы поможем высвободить несколько петабайтов на HDD, а это десятки процентов.
Количество данных растет очень быстрыми темпами. Каждый из нас носит огромный источник данных в кармане — телефон. Датчики становятся всё дешевле, данных на сервера отправляется все больше, и встаёт вопрос, что с ними делать. Нам кажется, что если мы научимся их использовать и как-то с ними работать, то есть шансы сэкономить мировой экономике 10% ресурсов. И, если это случится, нас ждёт новая индустриальная революция.
