
Внимание! Реклама! Пост оплачен Капитаном Очевидность!
Ниже под катом вы найдёте 15 пунктов, описывающих правильную организацию ресурсов, доступных по протоколу HTTP — веб-сайтов, «ручек» бэкенда, API и прочая. «Правильный» здесь означает «соответствующий рекомендациям и спецификациям». Большая часть ниженаписанного почти дословно переведена из официальных стандартов, рекомендаций и best practices от IETF и W3C.

Вы не найдёте здесь абсолютно ничего неочевидного. Нет, серьёзно, каждый веб-разработчик теоретически эти 15 пунктов должен освоить где-то в районе junior developer-а и/или второго-третьего курса университета.
Однако на практике оказывается, что великое множество веб-разработчиков эти азы таки не усвоило. Читаешь документацию к иным API и рыдаешь. Уверен, что каждый читатель таки найдёт в этом списке что-то новое для себя.
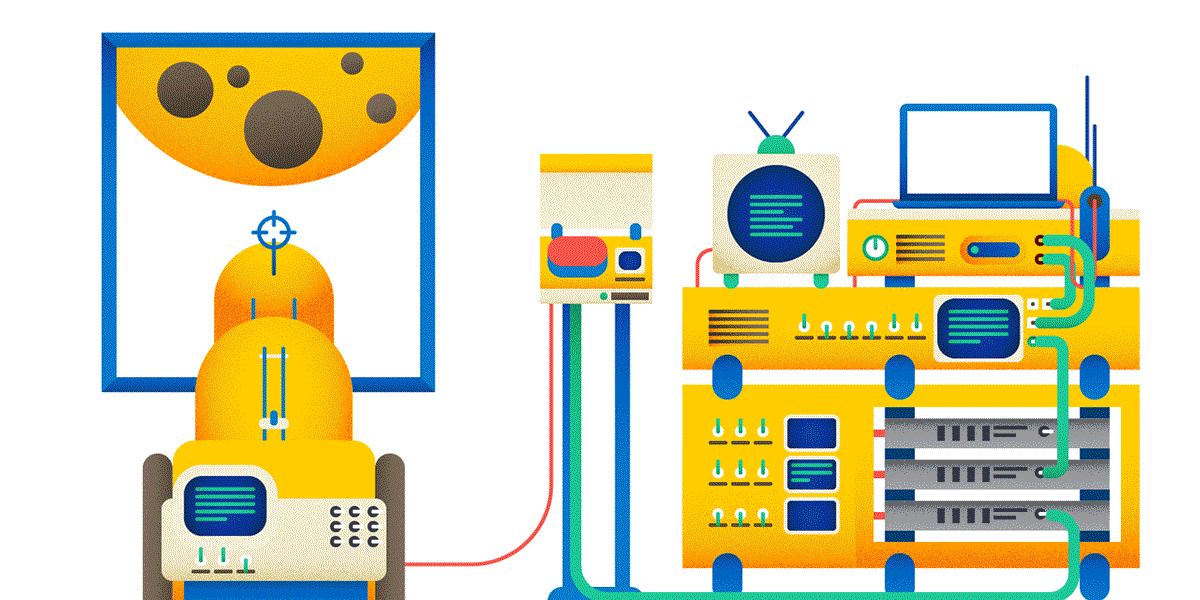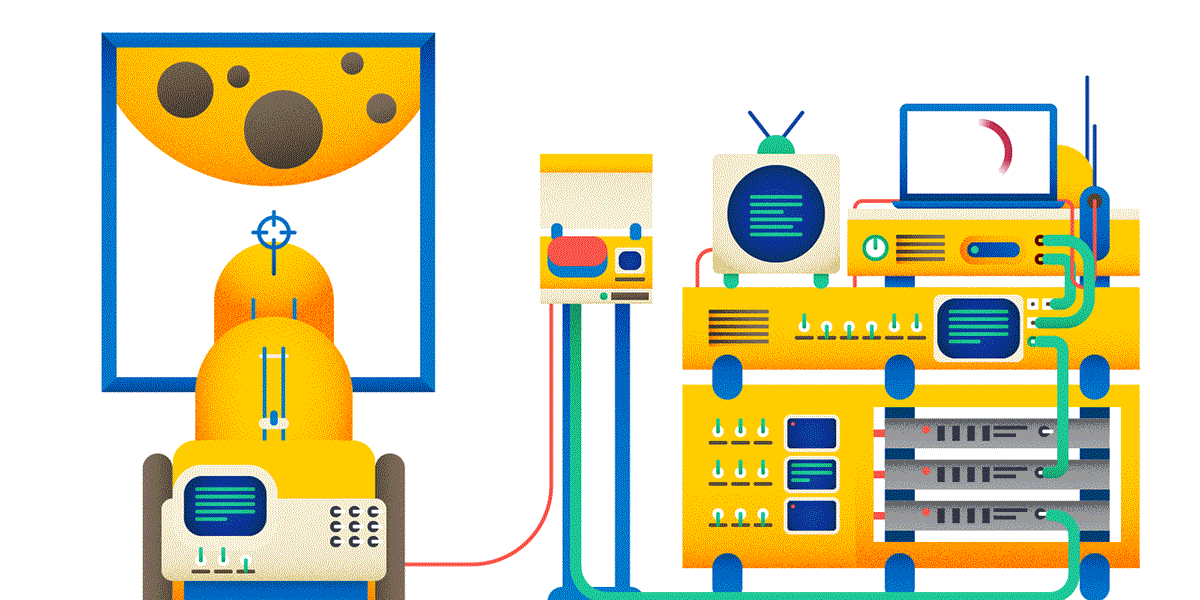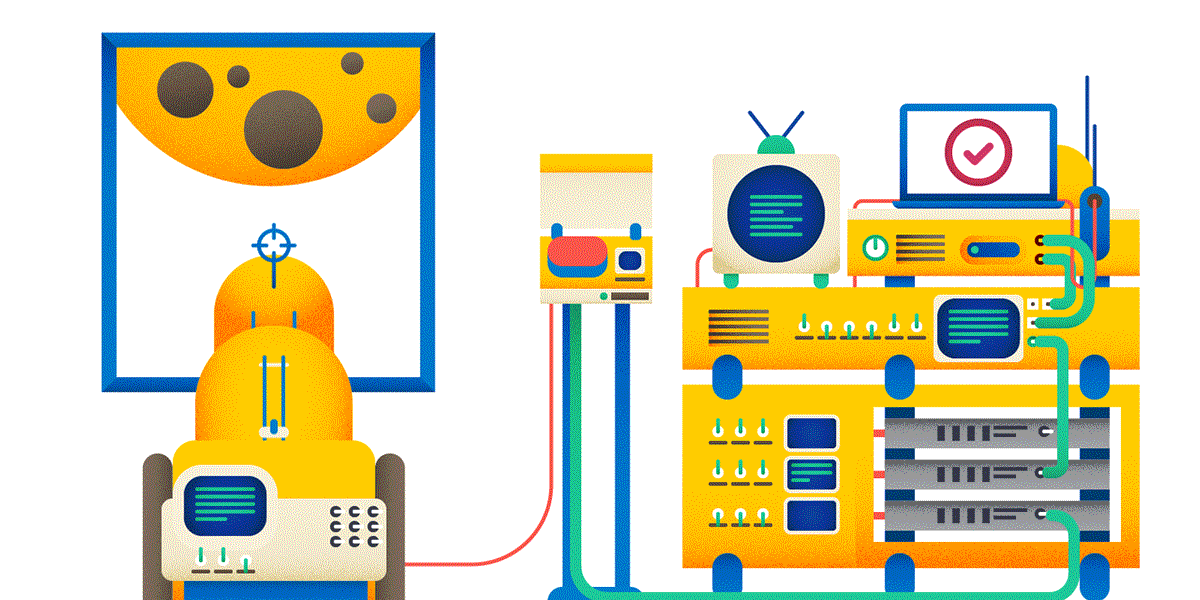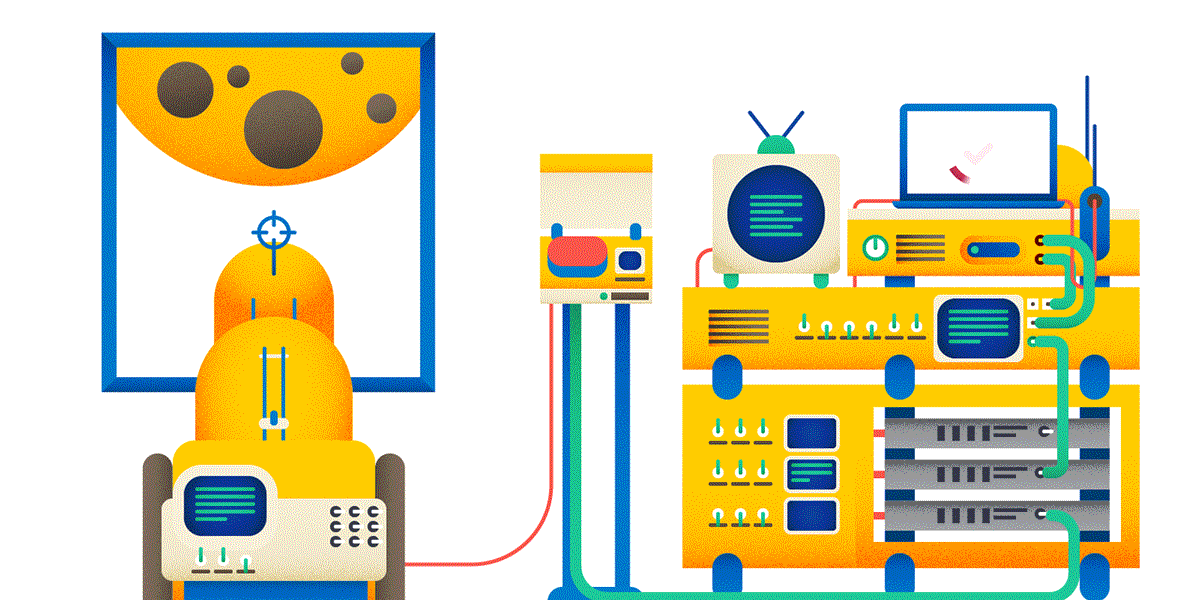
1. URL идентифицирует ресурс — некоторую разделяемую сущность. Файл — ресурс. Ручка, которая что-то ищет — ресурс. Вызов метода — не ресурс. Если вы хотите шарахнуть из пушки по Луне, то вот так делать не надо:
Заведите ресурс «шарахалка», и тогда у вас всё будет логично:
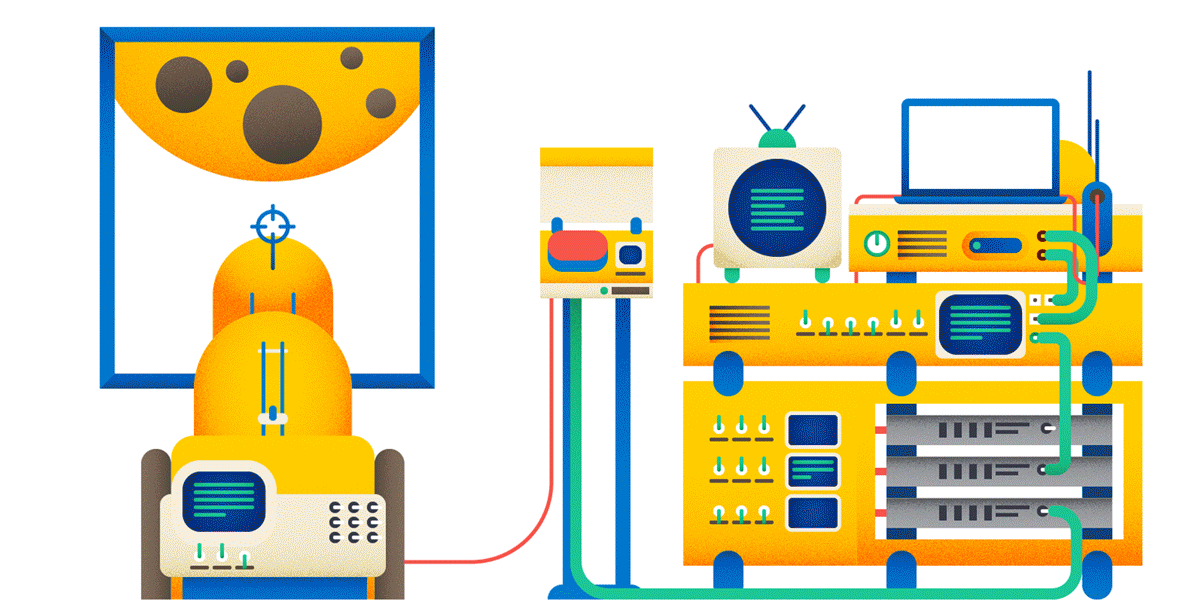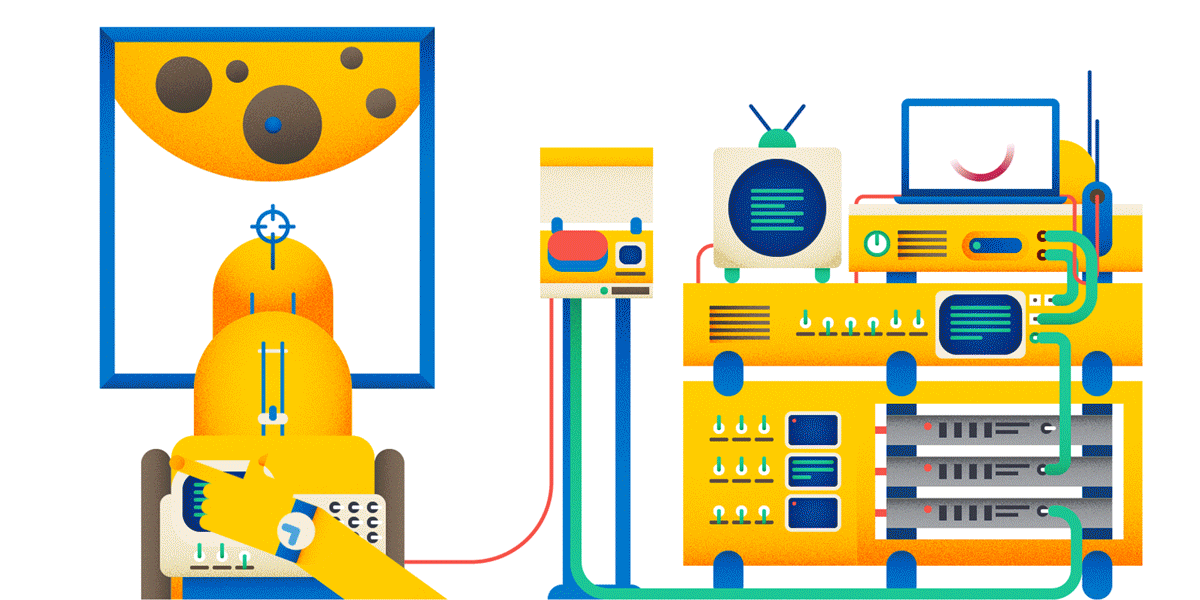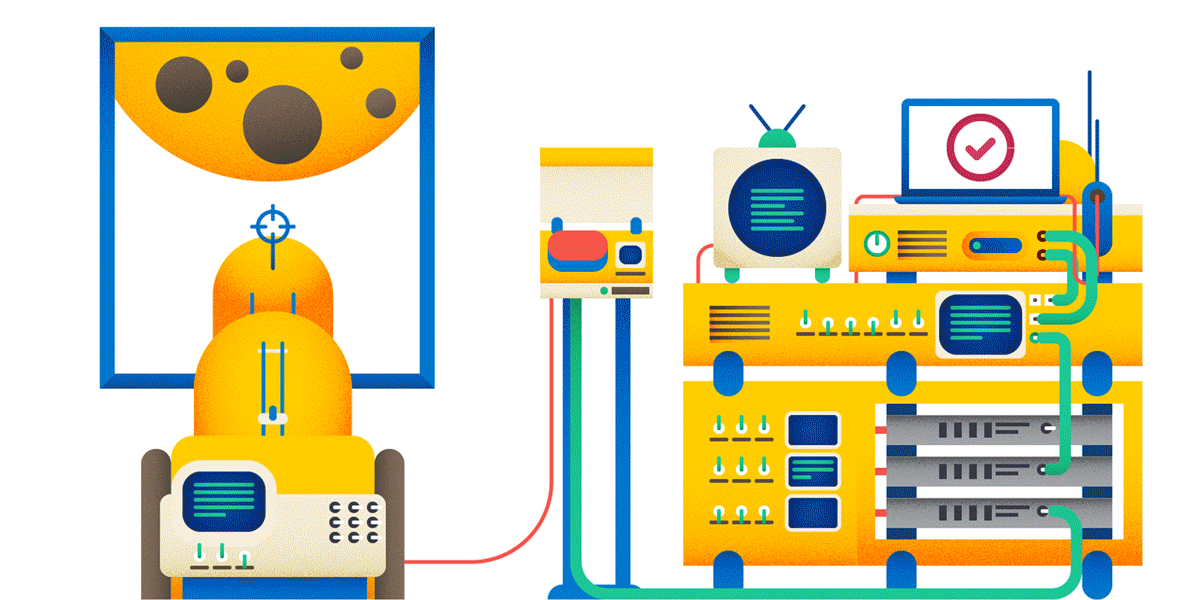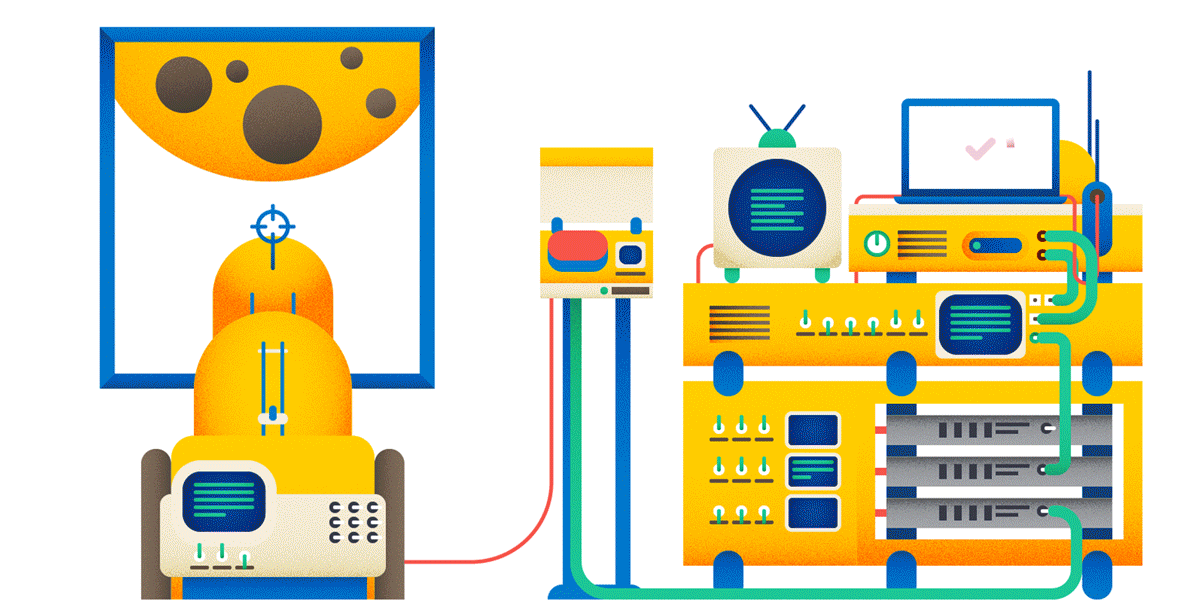
Почему POST, а не GET? Читай ниже.
2. URL состоит из схемы (протокола), хоста, пути (path), запроса (query) и фрагмента. Путь используется для организации иерархических ресурсов, запрос — для неиерархических ресурсов и для параметров операции. Фрагмент идентифицирует подчинённый ресурс, не имеющий прямого URL.
Если на вашем сайте «Няшные котики» есть каталог по породам, то его вполне логично организовать в виде частей path, поскольку каждый котик принадлежит ровно к одной породе. А вот доставлять одного котика можно в несколько городов, поэтому фильтр «с доставкой в город N» следует организовать через query.
3. Обращение по HTTP состоит из применения метода (глагола) к URL. Результатом такого применения должно быть — сюрприз-сюрприз! — то, что в глаголе написано. То есть GET возвращает представление ресурса, DELETE удаляет и т.п.
4. Методы GET, HEAD, OPTIONS — безопасные. Предполагается, что вызов этих методов состояния ресурса не изменяет. Поэтому многие сетевые агенты — такие, например, как префетчер ссылок в браузере или мессенджере — считают себя вправе по таким ссылкам ходить без явного волеизъявления пользователя. ИЧСХ, никаких стандартов не нарушают.
5. По умолчанию методы GET и HEAD кэшируются, OPTIONS, POST, PUT, PATCH, DELETE — нет. Поэтому если вы шарахнули по Луне методом POST, вы можете быть (почти) уверены, что этот запрос выполнится. Если вы шарахаете методом GET, какой-нибудь промежуточный прокси может ВНЕЗАПНО отдать вам ответ из кэша, и шарах в реальности не произойдёт.
6. Операции GET, PUT, DELETE симметричны. PUT кладёт нечто по URL-у (создавая новый ресурс или перезаписывая старый), GET по этому URL-у возвращает представление того, что положил PUT, DELETE удаляет ресурс.
Метод HEAD синонимичен по семантике методу GET, но не возвращает тело ответа, а только его заголовки (метаинформацию о ресурсе).
7. POST используется в том случае, если у вас нет URL, к которому вы хотите применить операцию. Например, если пользователь пишет новое сообщение в тредик на форуме, он может сам вычислить его id и сделать:
Если клиенту генерировать id не разрешено, ему придётся делать POST на ресурс уровнем выше по иерархии:
И этот ресурс сам создаст новое сообщение.
Обратите внимание, если вы по ошибке или вследствие сетевых проблем повторите POST запрос — создастся второе сообщение в треде, идентичное первому. PUT вы можете делать хоть 100500 раз, результат не изменится. Это свойство называется идемпотентностью.
Ладно создание постов на форуме. Вот если вы делаете тяжёлую и дорогую операцию по пользовательскому запросу — очень рекомендуется выполнять для этого идемпотентный запрос. А то может получиться как на картинке:

Разумеется, использование идемпотентного PUT порождает свои проблемы — в частности, как разрешать конфликты. Придётся больше программировать, зато результат будет более надёжным и безопасным.
8. PUT может использоваться как для создания новых ресурсов, так и для обновления старых. Однако в случае использования PUT для перезаписи предполагается, что в теле запроса передаётся закодированный ресурс целиком. Если же вы хотите модифицировать ресурс, т.е. изменить его внутреннее представление без полной перезаписи, то для этого был придуман метод PATCH. Этот метод некэшируемый, небезопасный и неидемпотентный.
9. Коды ответа нужны в первую очередь для того, чтобы клиент мог понять, что ему делать дальше. 3хх говорит, что для успешного выполнения запроса нужно выполнить дополнительное действие. 4хх говорит, что клиент, составляя запрос, сделал что-то неправильно и, обычно, о том, что умолять бесполезно — повторное выполнение запроса всё равно выкинет ошибку. В 4хх крайне рекомендуется включать информацию о том, что конкретно клиент сделал не так. 5хх говорит о том, что клиент всё сделал правильно — проблема на стороне сервера.
Обычно при успешном выполнении операции сервер отвечает на GET — 200, на PUT — 201 Created (если ресурс создан) или 200 (ресурс обновлён), на DELETE — 204 (операция успешна, возвращать нечего), на POST — 200 или 201 (во втором случае в заголовке, обычно Location, указывается URL созданного ресурса).
10. Работая с HTTP-статусами, не наступите на популярные грабли:
11. Существует особый подкласс URL-ов, которые кодируют в себе и ресурс, и действие над ним. В англоязычной литературе их принято называть Capability URLs. Классический пример такого URL — ссылки на восстановление паролей, а также всевозможные «секретные» прямые ссылки на всяческие ресурсы.
12. Поскольку основная опасность при работе с Capability URL — возможность их утечки, следует максимально закрыть возможности случайно такой URL найти или перехватить:
13. Должны быть предусмотрены меры минимизации возможного ущерба:
пользователь, создавший Capability URL (например, расшаривший документ), должен иметь возможность сделать обратную операцию, т.е. отозвать URL;
Capability URLs должны протухать со временем; чем опаснее предоставляемый доступ, тем короче должен быть срок жизни URL.
14. Наконец, сами «секретные» страницы должны быть защищены от сливания данных сторонним агентам:
15. Всё описанное выше существует в стандартах исключительно в форме рекомендации, и принудить кого-либо к строгому исполнению этих рекомендаций нельзя. Я уже не первый раз рассказываю про всю эту тривию, и часто слышу в ответ «да плевать я на всё это хотел, придумали какой-то ненужной ерунды; как у меня работали все сервисы только на GET, так и дальше будут, мучайтесь со своими PUT-ами и DELETE-ми сами».
Разумеется, вы вольны писать свой сервис сами. Но имейте, пожалуйста, в виду, что между вашим сервером и вашим клиентом, даже если они стоят физически рядышком в одном ДЦ, есть огромное множество других сетевых агентов — браузеров, прокси, роутеров, имплементаций HTTP-протокола в разных языках программирования и разных ОС, DPI-оборудование провайдеров и так далее. Все эти агенты плюс-минус имплементируют протокол HTTP с оглядкой на RFC.
Если вдруг клиентский браузер запрефетчит GET-ссылку и шарахнет по Луне — это будет ваша вина, бесполезно писать производителю. Если у вас деньги переводятся GET-запросом, а имплементация HTTP протокола в вашем языке программирования, не дождавшись ответа от соседнего роутера, решит повторить запрос и проведёт транзакцию дважды — это будет опять ваша вина.
Но даже не это главное. Допустим, ваши HTTP-пакеты гуляют в строго контролируемой среде. Как вы собираетесь объяснять другим разработчикам, какие рекомендации вы нарушили и почему? Как ваш коллега должен понять, что вот этот GET-запрос повторять нельзя, а статус 400 вовсе не означает клиентскую ошибку? Отступая от рекомендаций, вы, фактически, каждый раз создаёте какой-то свой диалект HTTP с собственной семантикой. Не забудьте его хотя бы задокументировать ;)
Список литературы:
(В разработке последнего документа ваш покорный слуга принимал определённое участие.)
Ниже под катом вы найдёте 15 пунктов, описывающих правильную организацию ресурсов, доступных по протоколу HTTP — веб-сайтов, «ручек» бэкенда, API и прочая. «Правильный» здесь означает «соответствующий рекомендациям и спецификациям». Большая часть ниженаписанного почти дословно переведена из официальных стандартов, рекомендаций и best practices от IETF и W3C.

Вы не найдёте здесь абсолютно ничего неочевидного. Нет, серьёзно, каждый веб-разработчик теоретически эти 15 пунктов должен освоить где-то в районе junior developer-а и/или второго-третьего курса университета.
Однако на практике оказывается, что великое множество веб-разработчиков эти азы таки не усвоило. Читаешь документацию к иным API и рыдаешь. Уверен, что каждый читатель таки найдёт в этом списке что-то новое для себя.
1. URL идентифицирует ресурс — некоторую разделяемую сущность. Файл — ресурс. Ручка, которая что-то ищет — ресурс. Вызов метода — не ресурс. Если вы хотите шарахнуть из пушки по Луне, то вот так делать не надо:
GET /?method=шарахнуть&to=ЛунаЗаведите ресурс «шарахалка», и тогда у вас всё будет логично:
POST /шарахалка/?to=ЛунаПочему POST, а не GET? Читай ниже.
2. URL состоит из схемы (протокола), хоста, пути (path), запроса (query) и фрагмента. Путь используется для организации иерархических ресурсов, запрос — для неиерархических ресурсов и для параметров операции. Фрагмент идентифицирует подчинённый ресурс, не имеющий прямого URL.
Scheme Host Path Query Fragment ↓ ↓ ↓ ↓ ↓ http://nyashnye-kotiki.xxx/breeds/maine-coon/?deliver_to=Moscow#photo
Если на вашем сайте «Няшные котики» есть каталог по породам, то его вполне логично организовать в виде частей path, поскольку каждый котик принадлежит ровно к одной породе. А вот доставлять одного котика можно в несколько городов, поэтому фильтр «с доставкой в город N» следует организовать через query.
3. Обращение по HTTP состоит из применения метода (глагола) к URL. Результатом такого применения должно быть — сюрприз-сюрприз! — то, что в глаголе написано. То есть GET возвращает представление ресурса, DELETE удаляет и т.п.
4. Методы GET, HEAD, OPTIONS — безопасные. Предполагается, что вызов этих методов состояния ресурса не изменяет. Поэтому многие сетевые агенты — такие, например, как префетчер ссылок в браузере или мессенджере — считают себя вправе по таким ссылкам ходить без явного волеизъявления пользователя. ИЧСХ, никаких стандартов не нарушают.
5. По умолчанию методы GET и HEAD кэшируются, OPTIONS, POST, PUT, PATCH, DELETE — нет. Поэтому если вы шарахнули по Луне методом POST, вы можете быть (почти) уверены, что этот запрос выполнится. Если вы шарахаете методом GET, какой-нибудь промежуточный прокси может ВНЕЗАПНО отдать вам ответ из кэша, и шарах в реальности не произойдёт.
6. Операции GET, PUT, DELETE симметричны. PUT кладёт нечто по URL-у (создавая новый ресурс или перезаписывая старый), GET по этому URL-у возвращает представление того, что положил PUT, DELETE удаляет ресурс.
Метод HEAD синонимичен по семантике методу GET, но не возвращает тело ответа, а только его заголовки (метаинформацию о ресурсе).
7. POST используется в том случае, если у вас нет URL, к которому вы хотите применить операцию. Например, если пользователь пишет новое сообщение в тредик на форуме, он может сам вычислить его id и сделать:
PUT /threads/php-rulezz/messages/100500Если клиенту генерировать id не разрешено, ему придётся делать POST на ресурс уровнем выше по иерархии:
POST /threads/php-rulezz/messagesИ этот ресурс сам создаст новое сообщение.
Обратите внимание, если вы по ошибке или вследствие сетевых проблем повторите POST запрос — создастся второе сообщение в треде, идентичное первому. PUT вы можете делать хоть 100500 раз, результат не изменится. Это свойство называется идемпотентностью.
Ладно создание постов на форуме. Вот если вы делаете тяжёлую и дорогую операцию по пользовательскому запросу — очень рекомендуется выполнять для этого идемпотентный запрос. А то может получиться как на картинке:
Разумеется, использование идемпотентного PUT порождает свои проблемы — в частности, как разрешать конфликты. Придётся больше программировать, зато результат будет более надёжным и безопасным.
8. PUT может использоваться как для создания новых ресурсов, так и для обновления старых. Однако в случае использования PUT для перезаписи предполагается, что в теле запроса передаётся закодированный ресурс целиком. Если же вы хотите модифицировать ресурс, т.е. изменить его внутреннее представление без полной перезаписи, то для этого был придуман метод PATCH. Этот метод некэшируемый, небезопасный и неидемпотентный.
9. Коды ответа нужны в первую очередь для того, чтобы клиент мог понять, что ему делать дальше. 3хх говорит, что для успешного выполнения запроса нужно выполнить дополнительное действие. 4хх говорит, что клиент, составляя запрос, сделал что-то неправильно и, обычно, о том, что умолять бесполезно — повторное выполнение запроса всё равно выкинет ошибку. В 4хх крайне рекомендуется включать информацию о том, что конкретно клиент сделал не так. 5хх говорит о том, что клиент всё сделал правильно — проблема на стороне сервера.
Обычно при успешном выполнении операции сервер отвечает на GET — 200, на PUT — 201 Created (если ресурс создан) или 200 (ресурс обновлён), на DELETE — 204 (операция успешна, возвращать нечего), на POST — 200 или 201 (во втором случае в заголовке, обычно Location, указывается URL созданного ресурса).
10. Работая с HTTP-статусами, не наступите на популярные грабли:
- статус 401 Unauthorized обязан сопровождаться заголовком WWW-Authenticate и, таким образом, применим только тогда, когда клиент аутентифицируется посредством HTTP-аутентификации; во всех остальных случаях следует использовать 403 Forbidden;
- статусы 3xx — это не только редиректы; они показывают, что клиент должен выполнить дополнительное действие, иначе запрос не может считаться успешным; например, по статусу 304 Not Modified клиент должен взять актуальную версию ресурса из кэша;
- статус 404, как ни странно, один из немногих 4xx статусов, которые клиент имеет право повторять — он означает, что ресурса сейчас нет, но вполне возможно, что он появится; вообще 404 — статус неопределённости, который используется, если сервер не хочет раскрывать механику ошибки; для того, чтобы индицировать клиенту, что без дополнительных действий с его стороны ресурс не появится, следует использовать 410 Gone (ресурс был удалён) либо общий статус 400.
11. Существует особый подкласс URL-ов, которые кодируют в себе и ресурс, и действие над ним. В англоязычной литературе их принято называть Capability URLs. Классический пример такого URL — ссылки на восстановление паролей, а также всевозможные «секретные» прямые ссылки на всяческие ресурсы.
12. Поскольку основная опасность при работе с Capability URL — возможность их утечки, следует максимально закрыть возможности случайно такой URL найти или перехватить:
- для генерации секретных частей URL должен использоваться сильный генератор случайных строк (например, UUID 4), исключающий возможности найти Capability URL перебором; разумеется, URL не должен генерироваться детерминированным способом типа md5(username) и такие URL нельзя пропускать через сокращатели ссылок;
- Capability URLs должны работать только по HTTPS;
- страницы, доступные через Capability URL, должны быть закрыты wildcard-ом от индексации роботами.
13. Должны быть предусмотрены меры минимизации возможного ущерба:
пользователь, создавший Capability URL (например, расшаривший документ), должен иметь возможность сделать обратную операцию, т.е. отозвать URL;
Capability URLs должны протухать со временем; чем опаснее предоставляемый доступ, тем короче должен быть срок жизни URL.
14. Наконец, сами «секретные» страницы должны быть защищены от сливания данных сторонним агентам:
- на них не должно быть никаких third-party скриптов и картинок, желательно — на уровне CSP;
- на них не должно быть ссылок на third-party сайты; если они необходимы, то нужно скрывать referrer, например, через rel=«noreferrer»;
- вообще желательно через Referrer Policy настроить скрытие referrer-а;
- желательно сразу после захода пользователя через History API менять URL в адресной строке браузера, чтобы его нельзя было подсмотреть через плечо;
- если ссылка предполагает какое-то действие (например, смену пароля), то на секретной странице должна быть форма (кнопка, скрипт), которую требуется отослать, чтобы действие осуществить, причём эта форма должно быть подписана CSRF-токеном (иначе префетчер браузера / почтового клиента / мессенджера сможет восстановить пароль за юзера).
15. Всё описанное выше существует в стандартах исключительно в форме рекомендации, и принудить кого-либо к строгому исполнению этих рекомендаций нельзя. Я уже не первый раз рассказываю про всю эту тривию, и часто слышу в ответ «да плевать я на всё это хотел, придумали какой-то ненужной ерунды; как у меня работали все сервисы только на GET, так и дальше будут, мучайтесь со своими PUT-ами и DELETE-ми сами».
Разумеется, вы вольны писать свой сервис сами. Но имейте, пожалуйста, в виду, что между вашим сервером и вашим клиентом, даже если они стоят физически рядышком в одном ДЦ, есть огромное множество других сетевых агентов — браузеров, прокси, роутеров, имплементаций HTTP-протокола в разных языках программирования и разных ОС, DPI-оборудование провайдеров и так далее. Все эти агенты плюс-минус имплементируют протокол HTTP с оглядкой на RFC.
Если вдруг клиентский браузер запрефетчит GET-ссылку и шарахнет по Луне — это будет ваша вина, бесполезно писать производителю. Если у вас деньги переводятся GET-запросом, а имплементация HTTP протокола в вашем языке программирования, не дождавшись ответа от соседнего роутера, решит повторить запрос и проведёт транзакцию дважды — это будет опять ваша вина.
Но даже не это главное. Допустим, ваши HTTP-пакеты гуляют в строго контролируемой среде. Как вы собираетесь объяснять другим разработчикам, какие рекомендации вы нарушили и почему? Как ваш коллега должен понять, что вот этот GET-запрос повторять нельзя, а статус 400 вовсе не означает клиентскую ошибку? Отступая от рекомендаций, вы, фактически, каждый раз создаёте какой-то свой диалект HTTP с собственной семантикой. Не забудьте его хотя бы задокументировать ;)
Список литературы:
- www.rfc-editor.org/rfc/rfc2616.txt
- tools.ietf.org/html/rfc5789
- www.w3.org/TR/webarch
- w3ctag.github.io/capability-urls
(В разработке последнего документа ваш покорный слуга принимал определённое участие.)
