
Хороший виртуальный ассистент должен не только решать задачи пользователя, но и разумно отвечать на вопрос «Как дела?». Реплик без явной цели очень много, и заготовить ответ на каждую проблематично. Neural Conversational Models — сравнительно новый способ создания диалоговых систем для свободного общения. Его основа — сети, обученные на больших корпусах диалогов из интернета. Борис hr0nix Янгель рассказывает, чем хороши такие модели и как их нужно строить.
Под катом — расшифровка и основная часть слайдов.
Спасибо, что пришли. Меня зовут Боря Янгель, я в Яндексе занимаюсь применением deep learning к текстам на естественном языке и диалоговыми системами. Я сегодня вам хочу рассказать про Neural Conversational Models. Это сравнительно новая область исследований в deep learning, задача которой — научиться разрабатывать нейронные сети, которые с собеседником разговаривают на некоторые общие темы, то есть ведут то, что можно условно назвать светской беседой. Говорят «Привет», обсуждают, как у тебя дела, ужасную погоду или фильм, который ты недавно посмотрел. И сегодня я хочу рассказать, что в этой области уже было сделано, что можно делать на практике, пользуясь результатами, и какие остались проблемы, которые только предстоит решить.

Мой доклад будет устроен примерно следующим образом. Сперва мы немножко поговорим о том, зачем может понадобиться учить нейронные сети светской беседе, какие данные и нейросетевые архитектуры нам для этого будут нужны, и как мы будем обучать, чтобы решить эту задачу. В конце немного поговорим о том, как оценить, что у нас в результате получилось, то есть о метриках.

Зачем учить сети разговаривать? Кто-то может подумать, что мы учим, чтобы сделать искусственный интеллект, который кого-нибудь когда-нибудь поработит.
Но таких амбициозных задач мы перед собой не ставим. Более того, я сильно сомневаюсь, что методы, о которых я сегодня буду рассказывать, нам помогут сильно приблизиться к созданию настоящего искусственного интеллекта.
Вместо этого мы ставим перед собой цель делать более интересные голосовые и диалоговые продукты. Есть такой класс продуктов, который называется, например, голосовые ассистенты. Это такие приложения, которые в формате диалога вам помогают решить какие-то насущные задачи. Например, узнать, какая погода сейчас, или вызвать такси или узнать, где находится ближайшая аптека. Про то, как делаются такие продукты, вы узнаете на втором докладе моего коллеги Жени Волкова, а меня сейчас интересует вот какой момент. Хочется, чтобы в этих продуктах, если пользователю ничего сейчас не нужно, он мог с системой о чем-нибудь поболтать. И продуктовая гипотеза состоит в том, что если с нашей системой можно будет иногда поболтать, причем эти диалоги будут хорошими, интересными, уникальными, не повторяющимися — то к такому продукту пользователь будет возвращаться чаще. Такие продукты хочется делать.
Как их можно делать?
Есть путь, которым пошли, например, создатели Siri — можно взять и заготовить много реплик ответов, какие-то реплики, которые часто говорит пользователь. И когда вы произносите одну из этих реплик и получаете созданный редакторами ответ — все замечательно, это здорово выглядит, пользователям нравится. Проблема в том, что стоит вам сделать шажок в сторону от этого сценария, и вы тут же видите, что Siri — это не более чем глупая программа, которая может в одной реплике употребить какую-то фразу, а в следующей же реплике сказать, что ей неизвестен смысл этой фразы — что, по меньшей мере, странно.

Вот пример похожего по структуре диалога с ботом, который я сделал с помощью методов, о которых я вам сегодня буду рассказывать. Он, может быть, никогда не отвечает так же интересно и витиевато, как Siri, но зато ни в какой момент времени он не производит впечатление совсем уж глупой программы. И кажется, что это может быть лучше в каких-то продуктах. А если это совместить с подходом, который используется в Siri и отвечает редакторскими репликами, когда вы можете иначе делать fallback на такую модель, — кажется, что получится еще лучше. Наша цель — делать такие системы.

Какие данные нам понадобятся? Давайте я чуть забегу вперед и сперва скажу, с какой постановкой задачи мы будем работать, потому что это важно для обсуждения нашего вопроса. Мы хотим по репликам в диалоге до текущего момента, а также, возможно, какой-то другой контекстной информации о диалоге — например, где и когда этот диалог происходит — предсказать, какой должна быть следующая реплика. То есть — предсказать ответ.
Чтобы решать такую задачу с помощью deep learning, нам хорошо бы иметь корпус с диалогами. Этот корпус лучше бы был большим, потому что deep learning с маленькими текстовыми корпусами — сами, наверное, знаете, как он работает. Хорошо бы, чтобы диалоги были на нужные нам темы. То есть если мы хотим сделать бота, который будет обсуждать с вами ваши чувства или говорить о погоде, то такие диалоги должны быть в диалоговом корпусе. Поэтому корпус диалогов со службой поддержки интернет-провайдера нам в решении проблемы вряд ли подойдет.
Хорошо бы в корпусе знать автора каждой реплики хотя бы на уровне уникального идентификатора. Это поможет нам как-то моделировать тот факт, что, например, разные спикеры пользуются разной лексикой или вообще обладают разными свойствами: их по-разному зовут, они в разных местах живут и по-разному отвечают на одни вопросы. Соответственно, если у нас есть какие-то метаданные о спикерах — пол, возраст, место проживания и так далее — то это нам еще лучше поможет смоделировать их особенности.
Наконец, какие-то метаданные о диалогах — время или место, если это диалоги в реальном мире, — тоже полезны. Дело в том, что два человека могут вести совсем разные диалоги в зависимости от пространственно-временного контекста.
В литературе, то есть в статьях про Neural Conversational Models, очень любят два датасета.

Первый из них — Open Subtitles. Это просто субтитры из огромного числа американских фильмов и сериалов. Какие плюсы этого датасета? В нем очень много жизненных диалогов, прямо таких, которые нам нужны, потому что это фильмы, сериалы, там люди часто говорят друг другу: «Привет! Как дела?», обсуждают какие-то жизненные вопросы. Но поскольку это фильмы и сериалы, то здесь же кроется и минус датасета. Там много фантастики, много фэнтези, которое аккуратно нужно вычищать, и много довольно своеобразных диалогов. Я помню, первая модель, которую мы обучили на Open Subtitles, она к месту и не к месту очень много про вампиров почему-то говорила. На вопрос «Откуда ты?» иногда отвечала: «Я, мать твою, из ФБР». Кажется, что не каждый захочет, чтобы его диалоговый продукт вел себя таким образом.
Это не единственная проблема датасета с субтитрами. Он как сформирован? Надеюсь, многие из вас знают, что такое srt-файлы. Фактически авторы датасета просто взяли srt-файлы этих фильмов и сериалов, все реплики оттуда и записали в огромный текстовый файл. Вообще говоря, в srt-файлах ничего не понятно о том, кто какую реплику говорит и где заканчивается один диалог и начинается другой. Можно пользоваться разными эвристиками: например, предполагать, что две последовательные реплики всегда говорят разные спикеры, или, например, что если между репликами прошло больше 10 секунд, то это разные диалоги. Но подобные предположения выполняются в 70% случаев, и это создает много шума в датасете.
Есть работы, в которых авторы пытаются, например, опираясь на лексику спикеров, сегментировать все реплики в субтитрах на то, кто что говорит и где кончается один диалог и начинается другой. Но никаких прямо очень хороших результатов достигнуть пока не получилось. Кажется, что если использовать дополнительную информацию — например, видео или звуковую дорожку, — то можно сделать лучше. Но я пока ни одной такой работы не знаю.
Мораль какая? С субтитрами нужно быть осторожным. На них, наверное, можно предобучать модели, но учить до конца с учетом всех этих минусов я не советую.
Следующий датасет, который очень любят в научной литературе — это Твиттер. В Твиттере про каждый твит известно, корневой ли он или же является ответом на какой-то другой твит. Корневой в том смысле, что он не написан как ответ. Соответственно, это дает нам точную разбивку на диалоги. Каждый твит образует дерево, в котором путь от корня, то есть от корневого твита до листа, — какой-то диалог, часто довольно осмысленный. В Твиттере известен автор и время каждой реплики, можно получить дополнительную информацию о пользователях, то есть что-то там написано прямо в профиле пользователя Твиттера. Профиль можно поматчить с профилями в других социальных сетях и еще что-то узнать.
Какие минусы у Твиттера? В первую очередь он, очевидно, смещен в сторону размещения и обсуждения ссылок. Но оказывается, что если убрать все диалоги, в которых корневой твит содержит ссылку, то оставшееся — оно во многом, не всегда, но часто напоминает ту самую светскую беседу, которую мы пытаемся смоделировать. Однако также оказывается, что диалоги на светские темы, по крайней мере в русском Твиттере —за английский ручаться не буду — ведутся в основном школьниками.
Мы это выяснили следующим образом. Мы обучили какую-то модель на Твиттере в первый раз и задали ей несколько простых вопросов типа «Ты где?» и «Сколько тебе лет?».

В общем, на вопрос «Ты где?» единственный цензурный ответ был «В школе», а все остальные отличались разве что знаками препинания. Но ответ на вопрос «Сколько тебе лет?» окончательно расставил все на свои места. Поэтому тут мораль какая? Если хотите учить диалоговые системы на этом датасете, то проблему школьников как-то надо решить. Например, надо пофильтровать датасет. Ваша модель будет разговаривать как часть спикеров — нужно оставить только нужную часть или воспользоваться одним из методов кластеризации спикеров, про которую я чуть дальше поговорю.
Эти два датасета любят в научной литературе. А если вы собираетесь делать что-то на практике, то вы во многом ограничены разве что своей фантазией и названием компании, на которую вы работаете. Например, если вы Facebook, то вам повезло иметь свой мессенджер, где огромное количество диалогов как раз на те темы, которые нас интересуют. Если вы не Facebook, у вас все еще есть какие-то возможности. Например, можно достать данные из публичных чатов в Telegram, в Slack, в каких-то IRC-каналах, можно распарсить какие-то форумы, поскрепить какие-то комментарии в социальных сетях. Можно скачать сценарии фильмов, которые на самом деле следуют некоторому формату, который в принципе можно распарсить автоматически — и даже понять, где там кончается одна сцена, где кончается другая и кто автор конкретной реплики. Наконец, можно какие-то транскрипты телепередач найти в интернете, и я на самом деле уверен, что я перечислил только малую часть всевозможных источников для диалогового корпуса.

Мы поговорили про данные. Теперь давайте к самой главной части перейдем. Какие же нам нейронные сети надо на этих данных учить, чтобы у нас получилось что-то, что может разговаривать? Я напомню вам постановку задачи. Мы хотим по предыдущим репликам, которые были сказаны до текущего момента в диалоге, предсказать, какой же должна быть следующая реплика. И все подходы, которые решают эту задачу, можно условно разделить на два. Я их называю «порождающий» и «ранжирующий». В порождающем подходе мы моделируем условное распределение на ответ при фиксированном контексте. Если у нас такое распределение есть, то, чтобы отвечать, мы берем его моду, допустим, или просто сэмплируем из этого распределения. А ранжирующий подход — это когда мы обучаем некоторую функцию уместности ответа при условии контекста, который необязательно имеет вероятностную природу. Но, в принципе, это условное распределение из порождающего подхода тоже может быть с этой функцией уместности. А потом берем некоторый пул кандидатов ответов и выбираем из него лучший ответ для заданного контекста с помощью нашей функции уместности.
Сперва поговорим про первый подход — порождающий.
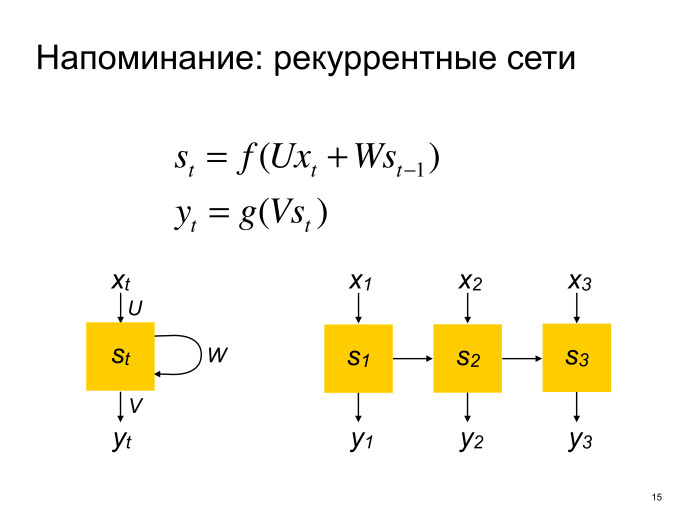
Здесь нам нужно знать, что такое рекуррентные сети. Я, честно говоря, надеюсь, что если вы пришли на доклад, где в названии есть нейросети, то вы знаете, что такое рекуррентные сети — потому что из моего сбивчивого минутного объяснения вы все равно вряд ли поймете, что это такое. Но правила такие, что я должен о них рассказать.
Итак, рекуррентные сети — это такая нейросетевая архитектура для работы с последовательностями произвольной длины. Работает она следующим образом.
У рекуррентной сети есть некоторое внутреннее состояние, которое она обновляет, проходясь по всем элементам последовательности. Условно можно считать, что проходит она слева направо. И так же опционально рекуррентная сеть на каждом шаге может сгенерировать какой-то выход, который идет куда-то дальше в вашей многослойной нейронной сети. И в классических нейронных сетях под названием vanilla RNN функция обновления внутреннего состояния — это просто некоторая нелинейность поверх линейного преобразования входа и предыдущего состояния, а выход — тоже нелинейность поверх линейного преобразования внутреннего состояния. Все любят рисовать вот так, или еще разворачивать по последовательностям. Мы в дальнейшем будем пользоваться второй нотацией.
На самом деле такими формулами обновления никто не пользуется, потому что если обучать такие нейронные сети, возникает очень много неприятных проблем. Пользуются более продвинутыми архитектурами. Например, LSTM (Long short-term memory) и GRU (Gated recurrent units). Дальше, когда мы будем говорить «рекуррентная сеть», мы будем предполагать что-то более продвинутое, чем простые рекуррентные сети.

Порождающий подход. О нашей задаче генерации реплики в диалоге по контексту можно думать как о задаче генерации строки по строке. То есть представим, что мы возьмем весь контекст, все предыдущие сказанные реплики, и просто сконкатенируем их, разделяя реплики разных спикеров некоторым специальным символом. Получается задача генерации строки по строке, а такие задачи неплохо изучены в машинном обучении, в частности — в машинном переводе. И стандартная архитектура в машинном переводе — так называемая sequence-to-sequence. И state of the art в машинном переводе — это все еще модификация подхода sequence-to-sequence. Он был предложен Суцкевером в 2014 году, а позже как раз адаптирован его соавторами для нашей задачи, Neural Conversational Models.
Что такое sequence-to-sequence? Это рекуррентная архитектура encoder-decoder, то есть это две рекуррентных сети: encoder и decoder. Encoder прочитывает исходную строку и генерирует некоторое ее конденсированное представление. Это конденсированное представление подается на вход декодеру, который уже должен сгенерировать выходную строку или для каждой выходной строки сказать, какая же у нее вероятность в этом условном распределении, которое мы пытаемся смоделировать.
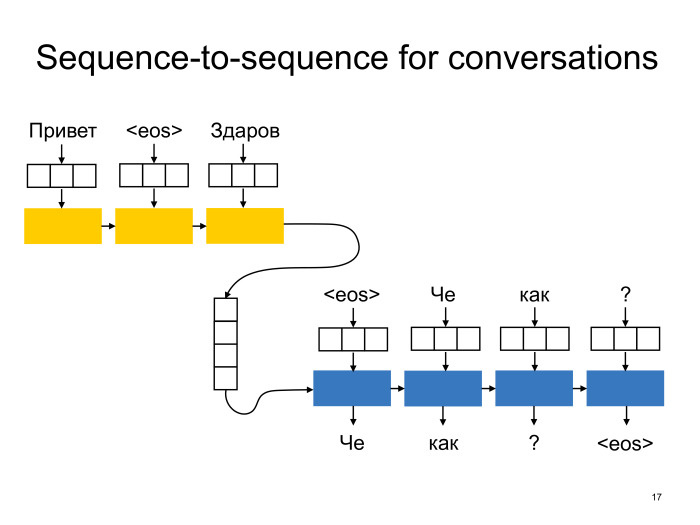
Выглядит это следующим образом. Желтенькое — сеть encoder. Допустим, у нас есть диалог двух спикеров из двух реплик «Привет» и «Здаров», для которого мы хотим сгенерировать ответ. Реплики спикеров мы разделим специальным символом end-of-sentense, eos. На самом деле не всегда разделяют предложение, но исторически его называют именно так. Каждое слово мы сперва погрузим в некоторое векторное пространство, сделаем то, что называется vector embedding. Затем этот вектор для каждого слова мы подадим на вход сети encoder, и последнее состояние сети encoder после того, как она обработает последнее слово, как раз и будет нашим конденсированным представлением контекста, которое мы подадим на вход в decoder. Мы можем, например, инициализировать первое скрытое состояние сети decoder этим вектором или, в качестве альтернативы, например, подать его на каждый timestamp вместе со словами. Сеть decoder на каждом шаге генерирует очередное слово реплики и на вход получает предыдущее слово, которое она сгенерировала. Это позволяет действительно лучше моделировать условное распределение. Почему? Я не хочу вдаваться сейчас в детали.
Генерирует decoder все до тех пор, пока не сгенерирует токен end-of-sentence. Это значит, что «Все, хватит». А на вход на первом шаге decoder, как правило, тоже получает токен end-of-sentence. И непонятно, что ему на вход нужно подать.

Обычно такие архитектуры обучаются с помощью обучения maximum likelihood. То есть мы берем условное распределение на ответы при известных нам контекстах в обучающей выборке и пытаемся сделать известные нам ответы как можно более вероятными. То есть максимизируем, допустим, логарифм такой вероятности по параметрам нейронной сети. А когда нам нужно сгенерировать реплику, у нас параметры нейронной сети уже известны, потому что мы их обучили и зафиксировали. И мы просто максимизируем условное распределение по ответу или сэмплируем из него. На самом деле точно его промаксимизировать нельзя, поэтому приходится пользоваться некоторыми приближенными методами. Например, есть метод стохастического поиска максимума в таких архитектурах encoder-decoder. Называется beam search. Что это такое, я тоже сейчас рассказать не успею, но ответ на данный вопрос легко найти в интернете.
Все модификации этой архитектуры, которые были придуманы для машинного перевода, можно попробовать применить и для Neural Conversational Models. Например, encoder и decoder, как правило, многослойные. Они работают лучше, чем однослойная архитектура. Как я уже сказал, это, скорее всего, LSTM- или GRU-сети, а не обычные RNN.
Encoder, как правило, двунаправленный. То есть на самом деле это две рекуррентные сети, которые проходятся по последовательности слева направо и справа налево. Практика показывает, что если идти только с одного направления, то пока вы дойдете до конца, сеть уже забудет, что там было сначала. А если идти с двух сторон, то у вас есть информация и слева, и справа в каждый момент. Это работает лучше.
Потом в машинном переводе есть такой трюк, прием, который называется attention. Его идея примерно в следующем. Каждый раз, когда ваш декодер генерирует очередное слово, вы можете еще дополнительно посмотреть на все слова или на скрытое представление на каждом timestamp в encoder и как-то их взвесить согласно тому, что вам сейчас нужно. Например, для генерации очередного слова вам нужно найти какой-нибудь следующий предлог во входной последовательности или понять, какая именованная сущность там определялась. Механизм attention помогает это сделать, и он немного помогает в Neural Conversational Models, но на самом деле намного меньше, чем в машинном переводе. Кажется, так происходит потому, что в машинном переводе в большинстве случаев для перевода очередного слова нужно посмотреть на одно слово в исходной последовательности. А при генерации реплики нужно посмотреть на много слов. И возможно, здесь будут работать лучше какие-то приемы, аналогичные тем, которые используются в memory networks. Типа multi-hole potential.
На самом деле того, что я вам сейчас рассказал, уже достаточно для создания некой Neural Conversational Model — при условии, что у вас есть данные. И она как-то будет разговаривать. Не могу сказать, что прямо очень плохо, но если вы будете с ней говорить, вы неизбежно столкнетесь с рядом проблем.
Первая проблема, которую вы увидите, — так называемая проблема слишком «общих» реплик. Это известная проблема модели encoder-decoder sequence-to-sequence, которая заключается в следующем. Такие модели склонны генерировать некие очень общие короткие по длине фразы, которые подходят к большому числу контекстов. Например, «Я не знаю», «Окей», «Я не могу сказать» и т. д. Почему так происходит? Можно, например, почитать статью, где авторы попытались формализовать некоторым образом это явление и показали, что в таких архитектурах оно будет происходить неизбежно.
В литературе про Neural Conversational Models предложен ряд решений или, я бы сказал, «костылей» для решения этой проблемы. Все они основаны на том, что мы по-прежнему обучаем модели в режиме максимизации правдоподобия, но когда генерируем реплику, то максимизируем не правдоподобие, а некоторый модифицированный функционал, который в себе это правдоподобие содержит.

Первая идея, которая появилась в литературе, — вместо правдоподобия максимизировать взаимную информацию между ответом и контекстом.
Что это значит на практике? Вот было такое выражение, которое мы максимизировали по ответу. А теперь давайте добавим к нему такой член. Это некий коэффициент, умноженный на априорную вероятность ответа. На самом деле это некое обобщение взаимной информации между ответом и контекстом. Такой коэффициент равен единице — получается как раз взаимная информация. Если он равен нулю, то получается исходный функционал. Но он может принимать этот параметр и промежуточные значения, чтобы вам можно было что-нибудь настроить в своем методе.
Какой у этого выражения смысл? Если мы его будем максимизировать, то теперь мы ищем не только уместный ответ при условии контекста, но и пенализируем ответы с большой априорной вероятностью. То есть, грубо говоря, пенализируем те ответы, которые часто встречаются в обучающем корпусе и которые можно сказать по поводу и без повода — как раз эти «Привет», «Как дела» и т. д.
Чтобы этим методом воспользоваться, вам теперь нужно не только обучить модель sequence-to-sequence, которая выдает указанную вероятность, но и обучить некоторую языковую модель на всевозможных ответах — чтобы получить эту вероятность. То есть возникает минус — нужно две модели.

Есть альтернативный способ переписать этот функционал, а точнее — записать другой функционал, который равен предыдущему с точностью до константы. Он факторизован немножко по-другому. Здесь все еще есть наша условная вероятность ответа при условии контекста, а еще есть вероятность контекста при условии ответа. Это можно проинтерпретировать следующим образом. Мы хотим не только ответы, уместные в данном контексте, но и такие ответы, по которым легко восстановить исходный контекст. То есть если ответ слишком общий, «Окей» или «Я не знаю», то совершенно непонятно, в каком контексте это было сказано. И такие ответы мы хотим штрафовать. Чтобы таким приемом воспользоваться, вам нужна и модель sequence-to-sequence, которая ответ генерирует по контексту, и модель sequence-to-sequence, которая контекст генерирует по ответу. То есть вам всё ещё нужны две модели.
Сравнительно недавно в статье, которую подали на ICLR, был предложен метод, в котором нужна всего одна модель. Тут идея такая. Мы при генерации реплики случайно выбираем сколько-то контекстов из нашего пула — допустим, из обучающей выборки. Затем наш функционал меняется следующим образом. Мы вычитаем из него такую пронормированную вероятность ответа при условии случайного контекста. Тут идея примерно такая же, как и на предыдущем слайде. Если наш ответ уместен для какого-то значительного числа случайных контекстов — это плохо, это значит, что он слишком общий. И на самом деле, если посмотреть на это формально, то перед нами всего лишь оценка Monte Carlo для MMI, который был записан на предыдущем слайде. Но ее прелесть в том, что дополнительная модель вам не нужна, и эмпирически почему-то это работает даже лучше, чем честный MMI.
Например, у честного MMI есть такое неприятное свойство, что этот член штрафует не только слишком общие ответы, но и грамматически корректные ответы, потому что грамматически корректные ответы более вероятны, чем грамматически некорректные. В результате, если неаккуратно подстроить коэффициент А, то сеть начинает разговаривать совершенно некогерентно. Это плохо.

Следующая проблема, с которой вы столкнетесь, — проблема консистентности ответов. Заключается она в следующем. Сеть на одни и те же вопросы, сформулированные по-разному или заданные в разных контекстах, будет давать разные ответы. Почему? Потому что сеть обучали на всем датасете в режиме максимизации правдоподобия, то есть она обучилась отвечать правильно в среднем по датасету. Если какой-то ответ часто встречается в датасете, значит, так можно отвечать. У сети нет никакого понятия о собственной личности и о том, что все ее ответы должны быть когерентными.
Если весь ваш датасет состоит из ответов одного и того же спикера, это никаких проблем не создаст, но вряд ли у вас есть датасет, в котором миллионы или десятки миллионов таких ответов. Поэтому проблему как-то надо решать.
Вот одно из решений, которое было предложено в литературе, в статье «A Persona-Based Neural Conversation Model»: давайте мы каждому спикеру дополнительно сопоставим вектор в некотором латентном пространстве спикеров. Так же, как мы слова погружаем в латентное пространство, мы и этот вектор будем подавать на вход декодеру в надежде, что при обучении мы туда запишем какую-то информацию, которая нужна, чтобы генерировать ответы от имени данного спикера. То есть, грубо говоря, запишем туда его пол, возраст, какие-то лексические особенности и т. д. И тут же у нас появится некий инструмент контроля поведения модели. Другими словами, мы компоненты этого вектора потом как-то сможем настраивать и, возможно, добиваться от сети желаемого поведения.
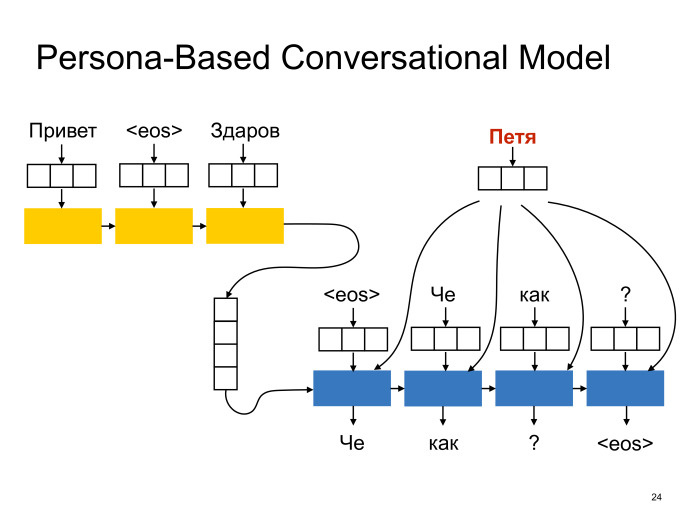
Но выглядит это в архитектуре sequence-to-sequence примерно следующим образом: все как раньше, только тут добавляется еще один вектор, который подается на каждый timestamp декодера. Например — конкатинируется с этим embedding-вектором слова.
В моделях с латентными переменными обычно есть проблема: тот факт, что мы хотим, чтобы в этот вектор записалась какая-то информация о спикере, еще не означает, что так действительно произойдет при обучении. В общем, нейронная сеть вправе распорядиться вектором как угодно. Ее представления необязательно совпадают с нашими. Но если обучить такую модель, а потом нарисовать, допустим, это пространство спикеров на плоскости с помощью алгоритма t-SNE или чего-нибудь подобного и поискать в нем какую-нибудь структуру, окажется, что она есть.
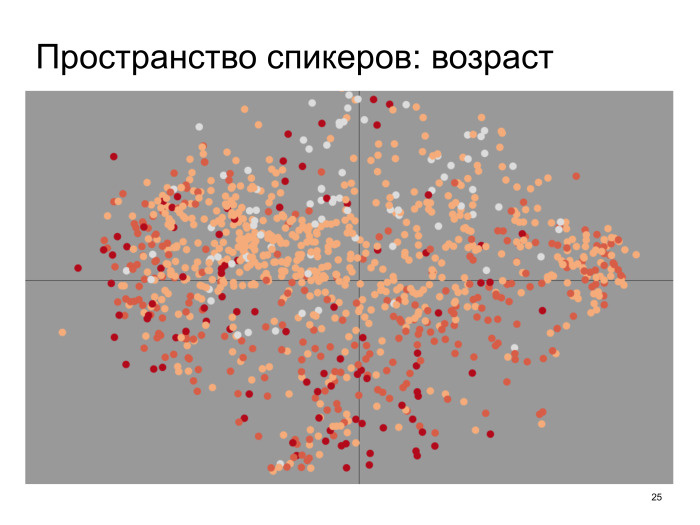
Например, можно нарисовать это пространство и отметить на нем возраст спикеров. Здесь светлые точки — это, грубо говоря, школьники, а красные точки — люди, которым больше 30 лет, если я не ошибаюсь. То есть видно, что это пространство слоистое, и сверху там находятся в основном школьники. Дальше идут студенты, потом молодые профессионалы и, наконец, люди, которым больше 30 или скольки-то лет. Другими словами, какая-то структура есть. Хорошо.
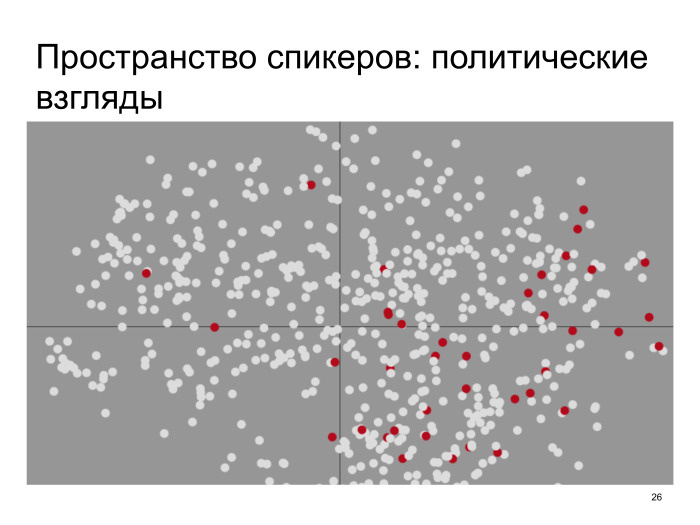
Можно сделать еще так. Я для некоторого числа пользователей Твиттера посмотрел, фолловят ли они некоторые аккаунты либеральных политиков или не фолловят, и это тоже нарисовал в указанном пространстве. Те, кто фоловят, оказались в основном в правом нижнем углу пространства. Это еще одно свидетельство, что там присутствует некоторая структура.

Сами авторы в статье приводят такую табличку, которая иллюстрирует, что их сеть научилась отвечать на вопросы консистентно. Тут ей задается ряд вопросов про ее домашний город, про то, откуда она, из какой страны, чем она занималась в колледже и т. д. И вроде как она консистентно отвечает. И вообще они там приводят, скажем, сравнение log-likelihood у моделей, в которых есть информация о спикере и в которых нет. Утверждается, что log-likelihood у моделей, которые знают про спикера, лучше.
Но они дальше говорят: «Наша цель не была полностью достигнута, потому что так же легко можно найти диалог, где это свойство не выполняется и где модель вроде как бы и уверенно, но периодически сбивается и отвечает в среднем по датасету». То есть проблема окончательно не решена, нужно работать. Это все, что я про порождающие модели хотел рассказать. Давайте теперь немного поговорим про ранжирующие.
Тут идея такая: вместо того, чтобы генерировать ответ с помощью какого-то вероятностного распределения, мы будем ранжировать ответы из некоторого пула согласно функции уместности ответа при условии контекста, которую мы обучим. Какие плюсы у такого подхода? Вы полностью контролируете пул ответов. Вы можете исключить грамматически некорректные ответы или ответы с обсценной лексикой, например. Тогда вы их никогда не сгенерируете, и вы меньше рискуете, чем при использовании порождающей модели, о которой я говорил раньше. Обучение таких архитектур происходит на порядки быстрее, и меньше проявляется проблема общих ответов — потому что она, скорее, свойственна архитектурам sequence-to-sequence encoder-decoder.
А минус, очевидно, такой: множество реплик, которые вы можете сказать, ограничено. И там, скорее всего, окажется реплика не на каждую ситуацию. Как только вам понадобится нечто не совсем тривиальное, скорее всего, его в вашем пуле не окажется.
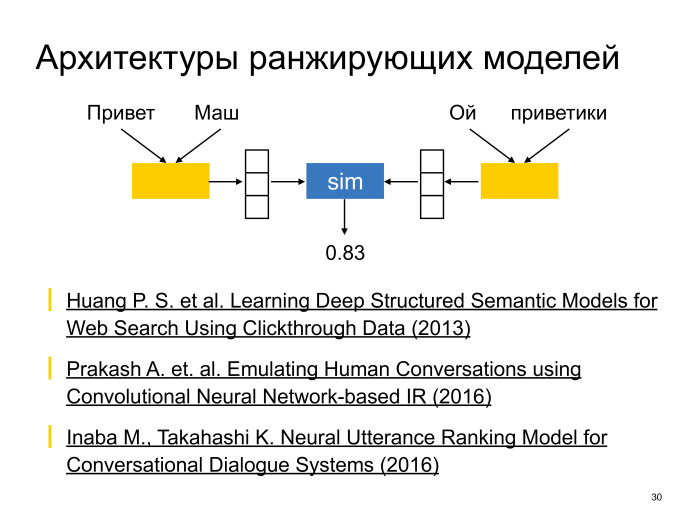
Как обычно устроены ранжирующие модели? Примерно следующим образом. Есть две сети, которые тут уже называются — и та сеть, и другая — encoder. Задача одной сети — получить некоторое конденсированное векторное представление контекста, другой — векторное представление ответа. Дальше уместность контекста при условии ответа считается с помощью некоторой функции сравнения двух векторов, но и получается в итоге некоторое число, которое говорит об уместности. Такая архитектура стала популярной после статьи Microsoft Research про DSSM, Deep Structure Semantic Models, в 2013 году. И впоследствии указанная архитектура тоже была не раз адаптирована во множестве разных статей для Neural Conversational Models.
Сети encoder, в принципе, могут быть любыми, если они по набору слов могут получить вектор. Например, это тоже могут быть рекуррентные сети — как и в архитектурах sequence-to-sequence. Или можно пойти более простым путем: это могут быть полносвязанные сети поверх усредненных эмбединговых слов. Тоже на удивление неплохо работает.
Как правило, функция уместности ответа в контексте — что-то простое, ведь нам нужно просто сравнить два вектора, скалярное произведение или косинусное расстояние, например.
Как обучаются такие модели? Поскольку они не порождающие, то тут уже положительных примеров недостаточно, нужны отрицательные. Если вы хотите, чтобы что-то отранжировалось высоко согласно вашей функции, вам нужно сказать, что должно отранжироваться низко.
Где брать отрицательные примеры? Классический подход — random sampling, когда вы просто берете случайные реплики в вашем датасете, говорите, что с большой вероятностью они неуместны и на это предположение опираетесь. Есть чуть более нетривиальный подход, который называется hard negative mining. Там идея такая: вы выбираете случайные реплики, но потом из случайных выбираете те, на которых сейчас модель сильнее всего ошибается.
С недавних пор в веб-ранжировании Яндекса существует алгоритм «Палех». Он во многом опирается на аналогичную архитектуру, и в статье на Хабрахабре написано, как этот hard negative mining может работать.
Теперь у вас есть положительные и отрицательные примеры. Что со всем этим делать? Нужна какая-то функция штрафа. Как правило, поступают очень просто: берут выходы этой функции Sim, которая является скалярным произведением или косинусным расстоянием, прогоняют через softmax и получают вероятностное распределение на ваш положительный пример и сколько-то отрицательных примеров, которые вы нагенерировали. А потом, как и в порождающих моделях, просто пользуются кроссэнтропийным лоссом, то есть хотят, чтобы вероятность правильного ответа была большой по сравнению с вероятностью неправильных. Есть всякие модификации на основе tripletloss. Это что-то типа подходов max margin, когда вы хотите, чтобы уместность вашего ответа при условии контакта была больше, чем уместность случайного ответа при условии контекста на некоторый margin, как в SVN. Про это тоже в интернете можно много всего интересного найти.
Как узнать, какая модель лучше? Как в машинном обучении обычно решают этот вопрос? У вас есть тестовая выборка, и вы по ней считаете какую-то метрику. Проблема в том, что здесь это не сработает, поскольку если ответ вашей модели не похож на ответ из тестовой выборки, это не говорит вообще ни о чем. Другими словами, даже на банальное «Привет» можно придумать десятки ответов, которые уместны, но у которых с ответом в тестовой выборке пара общих букв, не более того. Поэтому изначально все пытались использовать метрики из машинного перевода для решения этой задачи, которая сравнивает как-то ваш ответ с тем, что у вас было написано в тестовой выборке. Но все эти попытки провалились. Есть даже такая статья, где считается корреляция метрик, используемых в машинном переводе, с воспринимаемой людьми уместностью ответов. Корреляцию можно посчитать по тестовой выборке. И оказывается, что корреляции практически нет. Значит, этим способом лучше не пользоваться.
Каким же способом пользоваться тогда? Сейчас State of the art, если можно так сказать, подход — использовать краудсорсинг, то есть брать условный mechanical turk, и спрашивать у тёркеров: «Уместен ли данный ответ в данном контексте? Оцените по шкале от 0 до 5». Или: «Какой из данных ответов более уместен в этом контексте?». Если вы посмотрите литературу, в конечном итоге всем приходится сравнивать модели именно так.
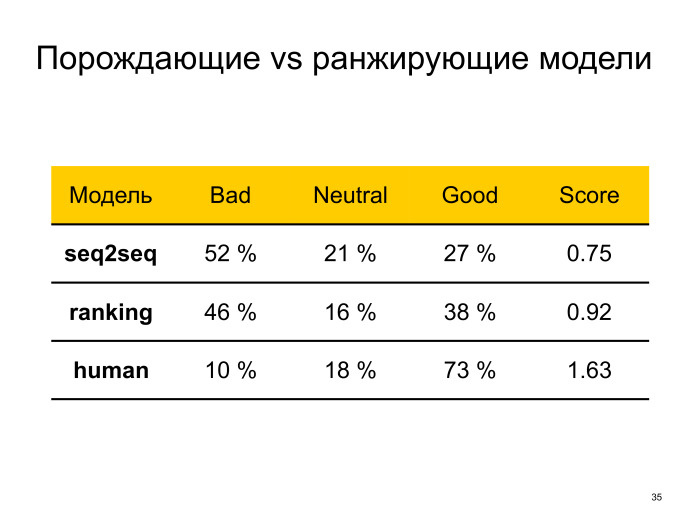
А что лучше: порождающие или ранжирующие модели? Вот мы взяли некоторую модель, которую обучили сами на Твиттере sequence-to-sequence, взяли ранжирующую DSSM-подобную модель и дальше на нашей краудсорсинговой платформе попросили работников оценить уместность каждого ответа при данном контексте, поставить одну из трех меток: bad, neutral или good. Bad значит, что ответ синтаксически некорректен, абсолютно неуместен или, например, содержит обсценную лексику. Neutral значит, что он уместен, но является общим и неинтересным. А good — что это синтаксически корректный и уместный ответ. И еще мы попросили людей сгенерировать сколько-то ответов, чтобы у нас был некий baseline, к которому можно стремиться. Вот какие получились цифры.
Что интересно, у людей есть 10% плохих ответов. Почему так происходит? Оказывается, в большинстве случаев люди пытались пошутить, но работники на краудсорсинговой платформе их шутку не поняли. Там, по-моему, в пуле был вопрос: «Какой главный ответ на все?». Ответ был «42», и видимо, никто не понял, что это значит. Там 9 из 10 — bad.
Что тут можно видеть? Очевидно, до людей еще далеко. Ранжирующие модели работают лучше — хотя бы потому, что в пуле много более интересных ответов и такой моделью проще ответ сгенерировать. А модели sequence-to-sequence работают хуже, но не то чтобы сильно хуже. Зато, как вы помните, они могут генерировать ответ в любой ситуации, так что, возможно, моделями sequence-to-sequence надо пользоваться. Или нужно комбинировать sequence-to-sequence и ранжирующие модели в виде какого-то ансамбля.
В заключение повторю основные поинты своего доклада. В последние пару лет Neural Conversational Models — по-настоящему горячая область исследований в deep learning, одна из таких областей. Ей очень много занимаются, в том числе крупные компании: Facebook, Google. Там происходит много интересного. В принципе, какими-то ее плодами можно пользоваться уже сейчас, но не следует ожидать, что у вас сразу получится искусственный интеллект. Осталось очень-очень много проблем, которые предстоит решать. И если у вас есть значительный опыт работы с текстами на естественном языке, опыт работы с диалоговыми системами или с deep learning в этой области — скорее всего, мы найдем что вам предложить.
Если вам интересно, вы можете, например, мне написать. У меня все. Спасибо.
Под катом — расшифровка и основная часть слайдов.
Спасибо, что пришли. Меня зовут Боря Янгель, я в Яндексе занимаюсь применением deep learning к текстам на естественном языке и диалоговыми системами. Я сегодня вам хочу рассказать про Neural Conversational Models. Это сравнительно новая область исследований в deep learning, задача которой — научиться разрабатывать нейронные сети, которые с собеседником разговаривают на некоторые общие темы, то есть ведут то, что можно условно назвать светской беседой. Говорят «Привет», обсуждают, как у тебя дела, ужасную погоду или фильм, который ты недавно посмотрел. И сегодня я хочу рассказать, что в этой области уже было сделано, что можно делать на практике, пользуясь результатами, и какие остались проблемы, которые только предстоит решить.

Мой доклад будет устроен примерно следующим образом. Сперва мы немножко поговорим о том, зачем может понадобиться учить нейронные сети светской беседе, какие данные и нейросетевые архитектуры нам для этого будут нужны, и как мы будем обучать, чтобы решить эту задачу. В конце немного поговорим о том, как оценить, что у нас в результате получилось, то есть о метриках.

Зачем учить сети разговаривать? Кто-то может подумать, что мы учим, чтобы сделать искусственный интеллект, который кого-нибудь когда-нибудь поработит.
Но таких амбициозных задач мы перед собой не ставим. Более того, я сильно сомневаюсь, что методы, о которых я сегодня буду рассказывать, нам помогут сильно приблизиться к созданию настоящего искусственного интеллекта.
Вместо этого мы ставим перед собой цель делать более интересные голосовые и диалоговые продукты. Есть такой класс продуктов, который называется, например, голосовые ассистенты. Это такие приложения, которые в формате диалога вам помогают решить какие-то насущные задачи. Например, узнать, какая погода сейчас, или вызвать такси или узнать, где находится ближайшая аптека. Про то, как делаются такие продукты, вы узнаете на втором докладе моего коллеги Жени Волкова, а меня сейчас интересует вот какой момент. Хочется, чтобы в этих продуктах, если пользователю ничего сейчас не нужно, он мог с системой о чем-нибудь поболтать. И продуктовая гипотеза состоит в том, что если с нашей системой можно будет иногда поболтать, причем эти диалоги будут хорошими, интересными, уникальными, не повторяющимися — то к такому продукту пользователь будет возвращаться чаще. Такие продукты хочется делать.
Как их можно делать?
Есть путь, которым пошли, например, создатели Siri — можно взять и заготовить много реплик ответов, какие-то реплики, которые часто говорит пользователь. И когда вы произносите одну из этих реплик и получаете созданный редакторами ответ — все замечательно, это здорово выглядит, пользователям нравится. Проблема в том, что стоит вам сделать шажок в сторону от этого сценария, и вы тут же видите, что Siri — это не более чем глупая программа, которая может в одной реплике употребить какую-то фразу, а в следующей же реплике сказать, что ей неизвестен смысл этой фразы — что, по меньшей мере, странно.

Вот пример похожего по структуре диалога с ботом, который я сделал с помощью методов, о которых я вам сегодня буду рассказывать. Он, может быть, никогда не отвечает так же интересно и витиевато, как Siri, но зато ни в какой момент времени он не производит впечатление совсем уж глупой программы. И кажется, что это может быть лучше в каких-то продуктах. А если это совместить с подходом, который используется в Siri и отвечает редакторскими репликами, когда вы можете иначе делать fallback на такую модель, — кажется, что получится еще лучше. Наша цель — делать такие системы.

Какие данные нам понадобятся? Давайте я чуть забегу вперед и сперва скажу, с какой постановкой задачи мы будем работать, потому что это важно для обсуждения нашего вопроса. Мы хотим по репликам в диалоге до текущего момента, а также, возможно, какой-то другой контекстной информации о диалоге — например, где и когда этот диалог происходит — предсказать, какой должна быть следующая реплика. То есть — предсказать ответ.
Чтобы решать такую задачу с помощью deep learning, нам хорошо бы иметь корпус с диалогами. Этот корпус лучше бы был большим, потому что deep learning с маленькими текстовыми корпусами — сами, наверное, знаете, как он работает. Хорошо бы, чтобы диалоги были на нужные нам темы. То есть если мы хотим сделать бота, который будет обсуждать с вами ваши чувства или говорить о погоде, то такие диалоги должны быть в диалоговом корпусе. Поэтому корпус диалогов со службой поддержки интернет-провайдера нам в решении проблемы вряд ли подойдет.
Хорошо бы в корпусе знать автора каждой реплики хотя бы на уровне уникального идентификатора. Это поможет нам как-то моделировать тот факт, что, например, разные спикеры пользуются разной лексикой или вообще обладают разными свойствами: их по-разному зовут, они в разных местах живут и по-разному отвечают на одни вопросы. Соответственно, если у нас есть какие-то метаданные о спикерах — пол, возраст, место проживания и так далее — то это нам еще лучше поможет смоделировать их особенности.
Наконец, какие-то метаданные о диалогах — время или место, если это диалоги в реальном мире, — тоже полезны. Дело в том, что два человека могут вести совсем разные диалоги в зависимости от пространственно-временного контекста.
В литературе, то есть в статьях про Neural Conversational Models, очень любят два датасета.

Первый из них — Open Subtitles. Это просто субтитры из огромного числа американских фильмов и сериалов. Какие плюсы этого датасета? В нем очень много жизненных диалогов, прямо таких, которые нам нужны, потому что это фильмы, сериалы, там люди часто говорят друг другу: «Привет! Как дела?», обсуждают какие-то жизненные вопросы. Но поскольку это фильмы и сериалы, то здесь же кроется и минус датасета. Там много фантастики, много фэнтези, которое аккуратно нужно вычищать, и много довольно своеобразных диалогов. Я помню, первая модель, которую мы обучили на Open Subtitles, она к месту и не к месту очень много про вампиров почему-то говорила. На вопрос «Откуда ты?» иногда отвечала: «Я, мать твою, из ФБР». Кажется, что не каждый захочет, чтобы его диалоговый продукт вел себя таким образом.
Это не единственная проблема датасета с субтитрами. Он как сформирован? Надеюсь, многие из вас знают, что такое srt-файлы. Фактически авторы датасета просто взяли srt-файлы этих фильмов и сериалов, все реплики оттуда и записали в огромный текстовый файл. Вообще говоря, в srt-файлах ничего не понятно о том, кто какую реплику говорит и где заканчивается один диалог и начинается другой. Можно пользоваться разными эвристиками: например, предполагать, что две последовательные реплики всегда говорят разные спикеры, или, например, что если между репликами прошло больше 10 секунд, то это разные диалоги. Но подобные предположения выполняются в 70% случаев, и это создает много шума в датасете.
Есть работы, в которых авторы пытаются, например, опираясь на лексику спикеров, сегментировать все реплики в субтитрах на то, кто что говорит и где кончается один диалог и начинается другой. Но никаких прямо очень хороших результатов достигнуть пока не получилось. Кажется, что если использовать дополнительную информацию — например, видео или звуковую дорожку, — то можно сделать лучше. Но я пока ни одной такой работы не знаю.
Мораль какая? С субтитрами нужно быть осторожным. На них, наверное, можно предобучать модели, но учить до конца с учетом всех этих минусов я не советую.
Следующий датасет, который очень любят в научной литературе — это Твиттер. В Твиттере про каждый твит известно, корневой ли он или же является ответом на какой-то другой твит. Корневой в том смысле, что он не написан как ответ. Соответственно, это дает нам точную разбивку на диалоги. Каждый твит образует дерево, в котором путь от корня, то есть от корневого твита до листа, — какой-то диалог, часто довольно осмысленный. В Твиттере известен автор и время каждой реплики, можно получить дополнительную информацию о пользователях, то есть что-то там написано прямо в профиле пользователя Твиттера. Профиль можно поматчить с профилями в других социальных сетях и еще что-то узнать.
Какие минусы у Твиттера? В первую очередь он, очевидно, смещен в сторону размещения и обсуждения ссылок. Но оказывается, что если убрать все диалоги, в которых корневой твит содержит ссылку, то оставшееся — оно во многом, не всегда, но часто напоминает ту самую светскую беседу, которую мы пытаемся смоделировать. Однако также оказывается, что диалоги на светские темы, по крайней мере в русском Твиттере —за английский ручаться не буду — ведутся в основном школьниками.
Мы это выяснили следующим образом. Мы обучили какую-то модель на Твиттере в первый раз и задали ей несколько простых вопросов типа «Ты где?» и «Сколько тебе лет?».

В общем, на вопрос «Ты где?» единственный цензурный ответ был «В школе», а все остальные отличались разве что знаками препинания. Но ответ на вопрос «Сколько тебе лет?» окончательно расставил все на свои места. Поэтому тут мораль какая? Если хотите учить диалоговые системы на этом датасете, то проблему школьников как-то надо решить. Например, надо пофильтровать датасет. Ваша модель будет разговаривать как часть спикеров — нужно оставить только нужную часть или воспользоваться одним из методов кластеризации спикеров, про которую я чуть дальше поговорю.
Эти два датасета любят в научной литературе. А если вы собираетесь делать что-то на практике, то вы во многом ограничены разве что своей фантазией и названием компании, на которую вы работаете. Например, если вы Facebook, то вам повезло иметь свой мессенджер, где огромное количество диалогов как раз на те темы, которые нас интересуют. Если вы не Facebook, у вас все еще есть какие-то возможности. Например, можно достать данные из публичных чатов в Telegram, в Slack, в каких-то IRC-каналах, можно распарсить какие-то форумы, поскрепить какие-то комментарии в социальных сетях. Можно скачать сценарии фильмов, которые на самом деле следуют некоторому формату, который в принципе можно распарсить автоматически — и даже понять, где там кончается одна сцена, где кончается другая и кто автор конкретной реплики. Наконец, можно какие-то транскрипты телепередач найти в интернете, и я на самом деле уверен, что я перечислил только малую часть всевозможных источников для диалогового корпуса.

Мы поговорили про данные. Теперь давайте к самой главной части перейдем. Какие же нам нейронные сети надо на этих данных учить, чтобы у нас получилось что-то, что может разговаривать? Я напомню вам постановку задачи. Мы хотим по предыдущим репликам, которые были сказаны до текущего момента в диалоге, предсказать, какой же должна быть следующая реплика. И все подходы, которые решают эту задачу, можно условно разделить на два. Я их называю «порождающий» и «ранжирующий». В порождающем подходе мы моделируем условное распределение на ответ при фиксированном контексте. Если у нас такое распределение есть, то, чтобы отвечать, мы берем его моду, допустим, или просто сэмплируем из этого распределения. А ранжирующий подход — это когда мы обучаем некоторую функцию уместности ответа при условии контекста, который необязательно имеет вероятностную природу. Но, в принципе, это условное распределение из порождающего подхода тоже может быть с этой функцией уместности. А потом берем некоторый пул кандидатов ответов и выбираем из него лучший ответ для заданного контекста с помощью нашей функции уместности.
Сперва поговорим про первый подход — порождающий.
Здесь нам нужно знать, что такое рекуррентные сети. Я, честно говоря, надеюсь, что если вы пришли на доклад, где в названии есть нейросети, то вы знаете, что такое рекуррентные сети — потому что из моего сбивчивого минутного объяснения вы все равно вряд ли поймете, что это такое. Но правила такие, что я должен о них рассказать.
Итак, рекуррентные сети — это такая нейросетевая архитектура для работы с последовательностями произвольной длины. Работает она следующим образом.
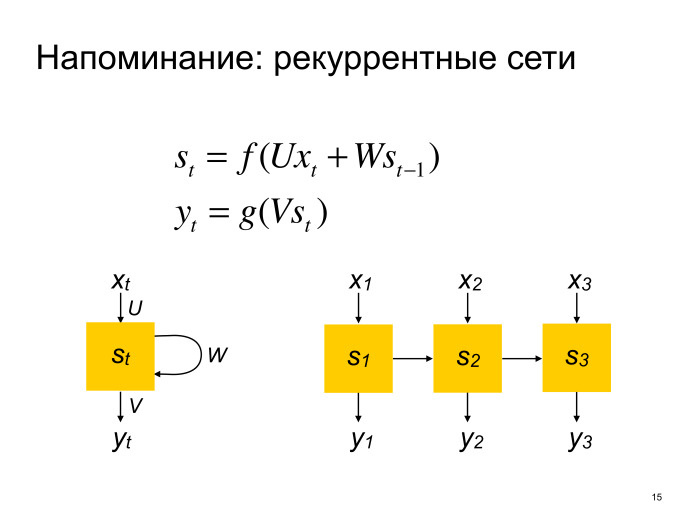
У рекуррентной сети есть некоторое внутреннее состояние, которое она обновляет, проходясь по всем элементам последовательности. Условно можно считать, что проходит она слева направо. И так же опционально рекуррентная сеть на каждом шаге может сгенерировать какой-то выход, который идет куда-то дальше в вашей многослойной нейронной сети. И в классических нейронных сетях под названием vanilla RNN функция обновления внутреннего состояния — это просто некоторая нелинейность поверх линейного преобразования входа и предыдущего состояния, а выход — тоже нелинейность поверх линейного преобразования внутреннего состояния. Все любят рисовать вот так, или еще разворачивать по последовательностям. Мы в дальнейшем будем пользоваться второй нотацией.
На самом деле такими формулами обновления никто не пользуется, потому что если обучать такие нейронные сети, возникает очень много неприятных проблем. Пользуются более продвинутыми архитектурами. Например, LSTM (Long short-term memory) и GRU (Gated recurrent units). Дальше, когда мы будем говорить «рекуррентная сеть», мы будем предполагать что-то более продвинутое, чем простые рекуррентные сети.

Порождающий подход. О нашей задаче генерации реплики в диалоге по контексту можно думать как о задаче генерации строки по строке. То есть представим, что мы возьмем весь контекст, все предыдущие сказанные реплики, и просто сконкатенируем их, разделяя реплики разных спикеров некоторым специальным символом. Получается задача генерации строки по строке, а такие задачи неплохо изучены в машинном обучении, в частности — в машинном переводе. И стандартная архитектура в машинном переводе — так называемая sequence-to-sequence. И state of the art в машинном переводе — это все еще модификация подхода sequence-to-sequence. Он был предложен Суцкевером в 2014 году, а позже как раз адаптирован его соавторами для нашей задачи, Neural Conversational Models.
Что такое sequence-to-sequence? Это рекуррентная архитектура encoder-decoder, то есть это две рекуррентных сети: encoder и decoder. Encoder прочитывает исходную строку и генерирует некоторое ее конденсированное представление. Это конденсированное представление подается на вход декодеру, который уже должен сгенерировать выходную строку или для каждой выходной строки сказать, какая же у нее вероятность в этом условном распределении, которое мы пытаемся смоделировать.

Выглядит это следующим образом. Желтенькое — сеть encoder. Допустим, у нас есть диалог двух спикеров из двух реплик «Привет» и «Здаров», для которого мы хотим сгенерировать ответ. Реплики спикеров мы разделим специальным символом end-of-sentense, eos. На самом деле не всегда разделяют предложение, но исторически его называют именно так. Каждое слово мы сперва погрузим в некоторое векторное пространство, сделаем то, что называется vector embedding. Затем этот вектор для каждого слова мы подадим на вход сети encoder, и последнее состояние сети encoder после того, как она обработает последнее слово, как раз и будет нашим конденсированным представлением контекста, которое мы подадим на вход в decoder. Мы можем, например, инициализировать первое скрытое состояние сети decoder этим вектором или, в качестве альтернативы, например, подать его на каждый timestamp вместе со словами. Сеть decoder на каждом шаге генерирует очередное слово реплики и на вход получает предыдущее слово, которое она сгенерировала. Это позволяет действительно лучше моделировать условное распределение. Почему? Я не хочу вдаваться сейчас в детали.
Генерирует decoder все до тех пор, пока не сгенерирует токен end-of-sentence. Это значит, что «Все, хватит». А на вход на первом шаге decoder, как правило, тоже получает токен end-of-sentence. И непонятно, что ему на вход нужно подать.

Обычно такие архитектуры обучаются с помощью обучения maximum likelihood. То есть мы берем условное распределение на ответы при известных нам контекстах в обучающей выборке и пытаемся сделать известные нам ответы как можно более вероятными. То есть максимизируем, допустим, логарифм такой вероятности по параметрам нейронной сети. А когда нам нужно сгенерировать реплику, у нас параметры нейронной сети уже известны, потому что мы их обучили и зафиксировали. И мы просто максимизируем условное распределение по ответу или сэмплируем из него. На самом деле точно его промаксимизировать нельзя, поэтому приходится пользоваться некоторыми приближенными методами. Например, есть метод стохастического поиска максимума в таких архитектурах encoder-decoder. Называется beam search. Что это такое, я тоже сейчас рассказать не успею, но ответ на данный вопрос легко найти в интернете.
Все модификации этой архитектуры, которые были придуманы для машинного перевода, можно попробовать применить и для Neural Conversational Models. Например, encoder и decoder, как правило, многослойные. Они работают лучше, чем однослойная архитектура. Как я уже сказал, это, скорее всего, LSTM- или GRU-сети, а не обычные RNN.
Encoder, как правило, двунаправленный. То есть на самом деле это две рекуррентные сети, которые проходятся по последовательности слева направо и справа налево. Практика показывает, что если идти только с одного направления, то пока вы дойдете до конца, сеть уже забудет, что там было сначала. А если идти с двух сторон, то у вас есть информация и слева, и справа в каждый момент. Это работает лучше.
Потом в машинном переводе есть такой трюк, прием, который называется attention. Его идея примерно в следующем. Каждый раз, когда ваш декодер генерирует очередное слово, вы можете еще дополнительно посмотреть на все слова или на скрытое представление на каждом timestamp в encoder и как-то их взвесить согласно тому, что вам сейчас нужно. Например, для генерации очередного слова вам нужно найти какой-нибудь следующий предлог во входной последовательности или понять, какая именованная сущность там определялась. Механизм attention помогает это сделать, и он немного помогает в Neural Conversational Models, но на самом деле намного меньше, чем в машинном переводе. Кажется, так происходит потому, что в машинном переводе в большинстве случаев для перевода очередного слова нужно посмотреть на одно слово в исходной последовательности. А при генерации реплики нужно посмотреть на много слов. И возможно, здесь будут работать лучше какие-то приемы, аналогичные тем, которые используются в memory networks. Типа multi-hole potential.
На самом деле того, что я вам сейчас рассказал, уже достаточно для создания некой Neural Conversational Model — при условии, что у вас есть данные. И она как-то будет разговаривать. Не могу сказать, что прямо очень плохо, но если вы будете с ней говорить, вы неизбежно столкнетесь с рядом проблем.
Первая проблема, которую вы увидите, — так называемая проблема слишком «общих» реплик. Это известная проблема модели encoder-decoder sequence-to-sequence, которая заключается в следующем. Такие модели склонны генерировать некие очень общие короткие по длине фразы, которые подходят к большому числу контекстов. Например, «Я не знаю», «Окей», «Я не могу сказать» и т. д. Почему так происходит? Можно, например, почитать статью, где авторы попытались формализовать некоторым образом это явление и показали, что в таких архитектурах оно будет происходить неизбежно.
В литературе про Neural Conversational Models предложен ряд решений или, я бы сказал, «костылей» для решения этой проблемы. Все они основаны на том, что мы по-прежнему обучаем модели в режиме максимизации правдоподобия, но когда генерируем реплику, то максимизируем не правдоподобие, а некоторый модифицированный функционал, который в себе это правдоподобие содержит.

Первая идея, которая появилась в литературе, — вместо правдоподобия максимизировать взаимную информацию между ответом и контекстом.
Что это значит на практике? Вот было такое выражение, которое мы максимизировали по ответу. А теперь давайте добавим к нему такой член. Это некий коэффициент, умноженный на априорную вероятность ответа. На самом деле это некое обобщение взаимной информации между ответом и контекстом. Такой коэффициент равен единице — получается как раз взаимная информация. Если он равен нулю, то получается исходный функционал. Но он может принимать этот параметр и промежуточные значения, чтобы вам можно было что-нибудь настроить в своем методе.
Какой у этого выражения смысл? Если мы его будем максимизировать, то теперь мы ищем не только уместный ответ при условии контекста, но и пенализируем ответы с большой априорной вероятностью. То есть, грубо говоря, пенализируем те ответы, которые часто встречаются в обучающем корпусе и которые можно сказать по поводу и без повода — как раз эти «Привет», «Как дела» и т. д.
Чтобы этим методом воспользоваться, вам теперь нужно не только обучить модель sequence-to-sequence, которая выдает указанную вероятность, но и обучить некоторую языковую модель на всевозможных ответах — чтобы получить эту вероятность. То есть возникает минус — нужно две модели.

Есть альтернативный способ переписать этот функционал, а точнее — записать другой функционал, который равен предыдущему с точностью до константы. Он факторизован немножко по-другому. Здесь все еще есть наша условная вероятность ответа при условии контекста, а еще есть вероятность контекста при условии ответа. Это можно проинтерпретировать следующим образом. Мы хотим не только ответы, уместные в данном контексте, но и такие ответы, по которым легко восстановить исходный контекст. То есть если ответ слишком общий, «Окей» или «Я не знаю», то совершенно непонятно, в каком контексте это было сказано. И такие ответы мы хотим штрафовать. Чтобы таким приемом воспользоваться, вам нужна и модель sequence-to-sequence, которая ответ генерирует по контексту, и модель sequence-to-sequence, которая контекст генерирует по ответу. То есть вам всё ещё нужны две модели.
Сравнительно недавно в статье, которую подали на ICLR, был предложен метод, в котором нужна всего одна модель. Тут идея такая. Мы при генерации реплики случайно выбираем сколько-то контекстов из нашего пула — допустим, из обучающей выборки. Затем наш функционал меняется следующим образом. Мы вычитаем из него такую пронормированную вероятность ответа при условии случайного контекста. Тут идея примерно такая же, как и на предыдущем слайде. Если наш ответ уместен для какого-то значительного числа случайных контекстов — это плохо, это значит, что он слишком общий. И на самом деле, если посмотреть на это формально, то перед нами всего лишь оценка Monte Carlo для MMI, который был записан на предыдущем слайде. Но ее прелесть в том, что дополнительная модель вам не нужна, и эмпирически почему-то это работает даже лучше, чем честный MMI.
Например, у честного MMI есть такое неприятное свойство, что этот член штрафует не только слишком общие ответы, но и грамматически корректные ответы, потому что грамматически корректные ответы более вероятны, чем грамматически некорректные. В результате, если неаккуратно подстроить коэффициент А, то сеть начинает разговаривать совершенно некогерентно. Это плохо.

Следующая проблема, с которой вы столкнетесь, — проблема консистентности ответов. Заключается она в следующем. Сеть на одни и те же вопросы, сформулированные по-разному или заданные в разных контекстах, будет давать разные ответы. Почему? Потому что сеть обучали на всем датасете в режиме максимизации правдоподобия, то есть она обучилась отвечать правильно в среднем по датасету. Если какой-то ответ часто встречается в датасете, значит, так можно отвечать. У сети нет никакого понятия о собственной личности и о том, что все ее ответы должны быть когерентными.
Если весь ваш датасет состоит из ответов одного и того же спикера, это никаких проблем не создаст, но вряд ли у вас есть датасет, в котором миллионы или десятки миллионов таких ответов. Поэтому проблему как-то надо решать.
Вот одно из решений, которое было предложено в литературе, в статье «A Persona-Based Neural Conversation Model»: давайте мы каждому спикеру дополнительно сопоставим вектор в некотором латентном пространстве спикеров. Так же, как мы слова погружаем в латентное пространство, мы и этот вектор будем подавать на вход декодеру в надежде, что при обучении мы туда запишем какую-то информацию, которая нужна, чтобы генерировать ответы от имени данного спикера. То есть, грубо говоря, запишем туда его пол, возраст, какие-то лексические особенности и т. д. И тут же у нас появится некий инструмент контроля поведения модели. Другими словами, мы компоненты этого вектора потом как-то сможем настраивать и, возможно, добиваться от сети желаемого поведения.
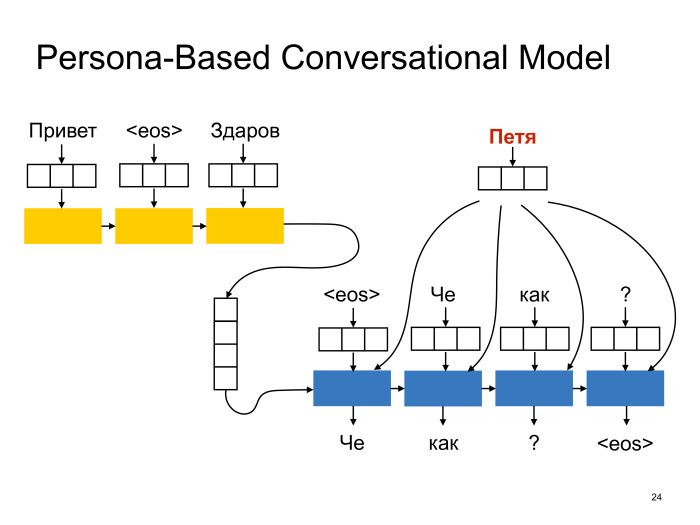
Но выглядит это в архитектуре sequence-to-sequence примерно следующим образом: все как раньше, только тут добавляется еще один вектор, который подается на каждый timestamp декодера. Например — конкатинируется с этим embedding-вектором слова.
В моделях с латентными переменными обычно есть проблема: тот факт, что мы хотим, чтобы в этот вектор записалась какая-то информация о спикере, еще не означает, что так действительно произойдет при обучении. В общем, нейронная сеть вправе распорядиться вектором как угодно. Ее представления необязательно совпадают с нашими. Но если обучить такую модель, а потом нарисовать, допустим, это пространство спикеров на плоскости с помощью алгоритма t-SNE или чего-нибудь подобного и поискать в нем какую-нибудь структуру, окажется, что она есть.
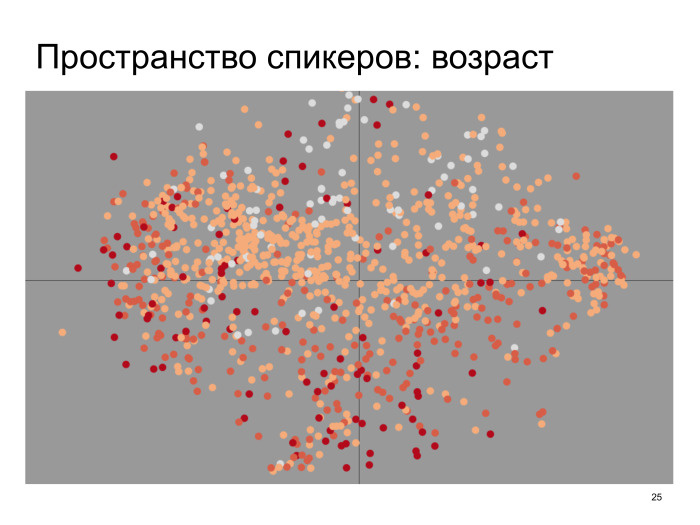
Например, можно нарисовать это пространство и отметить на нем возраст спикеров. Здесь светлые точки — это, грубо говоря, школьники, а красные точки — люди, которым больше 30 лет, если я не ошибаюсь. То есть видно, что это пространство слоистое, и сверху там находятся в основном школьники. Дальше идут студенты, потом молодые профессионалы и, наконец, люди, которым больше 30 или скольки-то лет. Другими словами, какая-то структура есть. Хорошо.

Можно сделать еще так. Я для некоторого числа пользователей Твиттера посмотрел, фолловят ли они некоторые аккаунты либеральных политиков или не фолловят, и это тоже нарисовал в указанном пространстве. Те, кто фоловят, оказались в основном в правом нижнем углу пространства. Это еще одно свидетельство, что там присутствует некоторая структура.

Сами авторы в статье приводят такую табличку, которая иллюстрирует, что их сеть научилась отвечать на вопросы консистентно. Тут ей задается ряд вопросов про ее домашний город, про то, откуда она, из какой страны, чем она занималась в колледже и т. д. И вроде как она консистентно отвечает. И вообще они там приводят, скажем, сравнение log-likelihood у моделей, в которых есть информация о спикере и в которых нет. Утверждается, что log-likelihood у моделей, которые знают про спикера, лучше.
Но они дальше говорят: «Наша цель не была полностью достигнута, потому что так же легко можно найти диалог, где это свойство не выполняется и где модель вроде как бы и уверенно, но периодически сбивается и отвечает в среднем по датасету». То есть проблема окончательно не решена, нужно работать. Это все, что я про порождающие модели хотел рассказать. Давайте теперь немного поговорим про ранжирующие.
Тут идея такая: вместо того, чтобы генерировать ответ с помощью какого-то вероятностного распределения, мы будем ранжировать ответы из некоторого пула согласно функции уместности ответа при условии контекста, которую мы обучим. Какие плюсы у такого подхода? Вы полностью контролируете пул ответов. Вы можете исключить грамматически некорректные ответы или ответы с обсценной лексикой, например. Тогда вы их никогда не сгенерируете, и вы меньше рискуете, чем при использовании порождающей модели, о которой я говорил раньше. Обучение таких архитектур происходит на порядки быстрее, и меньше проявляется проблема общих ответов — потому что она, скорее, свойственна архитектурам sequence-to-sequence encoder-decoder.
А минус, очевидно, такой: множество реплик, которые вы можете сказать, ограничено. И там, скорее всего, окажется реплика не на каждую ситуацию. Как только вам понадобится нечто не совсем тривиальное, скорее всего, его в вашем пуле не окажется.
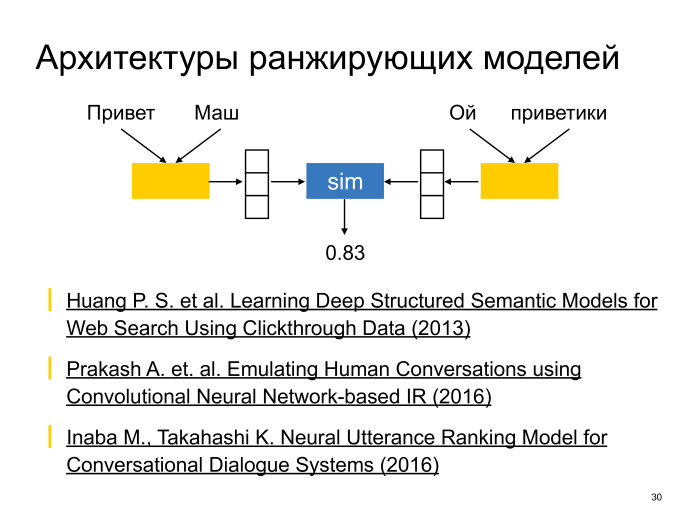
Как обычно устроены ранжирующие модели? Примерно следующим образом. Есть две сети, которые тут уже называются — и та сеть, и другая — encoder. Задача одной сети — получить некоторое конденсированное векторное представление контекста, другой — векторное представление ответа. Дальше уместность контекста при условии ответа считается с помощью некоторой функции сравнения двух векторов, но и получается в итоге некоторое число, которое говорит об уместности. Такая архитектура стала популярной после статьи Microsoft Research про DSSM, Deep Structure Semantic Models, в 2013 году. И впоследствии указанная архитектура тоже была не раз адаптирована во множестве разных статей для Neural Conversational Models.
Сети encoder, в принципе, могут быть любыми, если они по набору слов могут получить вектор. Например, это тоже могут быть рекуррентные сети — как и в архитектурах sequence-to-sequence. Или можно пойти более простым путем: это могут быть полносвязанные сети поверх усредненных эмбединговых слов. Тоже на удивление неплохо работает.
Как правило, функция уместности ответа в контексте — что-то простое, ведь нам нужно просто сравнить два вектора, скалярное произведение или косинусное расстояние, например.
Как обучаются такие модели? Поскольку они не порождающие, то тут уже положительных примеров недостаточно, нужны отрицательные. Если вы хотите, чтобы что-то отранжировалось высоко согласно вашей функции, вам нужно сказать, что должно отранжироваться низко.
Где брать отрицательные примеры? Классический подход — random sampling, когда вы просто берете случайные реплики в вашем датасете, говорите, что с большой вероятностью они неуместны и на это предположение опираетесь. Есть чуть более нетривиальный подход, который называется hard negative mining. Там идея такая: вы выбираете случайные реплики, но потом из случайных выбираете те, на которых сейчас модель сильнее всего ошибается.
С недавних пор в веб-ранжировании Яндекса существует алгоритм «Палех». Он во многом опирается на аналогичную архитектуру, и в статье на Хабрахабре написано, как этот hard negative mining может работать.
Теперь у вас есть положительные и отрицательные примеры. Что со всем этим делать? Нужна какая-то функция штрафа. Как правило, поступают очень просто: берут выходы этой функции Sim, которая является скалярным произведением или косинусным расстоянием, прогоняют через softmax и получают вероятностное распределение на ваш положительный пример и сколько-то отрицательных примеров, которые вы нагенерировали. А потом, как и в порождающих моделях, просто пользуются кроссэнтропийным лоссом, то есть хотят, чтобы вероятность правильного ответа была большой по сравнению с вероятностью неправильных. Есть всякие модификации на основе tripletloss. Это что-то типа подходов max margin, когда вы хотите, чтобы уместность вашего ответа при условии контакта была больше, чем уместность случайного ответа при условии контекста на некоторый margin, как в SVN. Про это тоже в интернете можно много всего интересного найти.
Как узнать, какая модель лучше? Как в машинном обучении обычно решают этот вопрос? У вас есть тестовая выборка, и вы по ней считаете какую-то метрику. Проблема в том, что здесь это не сработает, поскольку если ответ вашей модели не похож на ответ из тестовой выборки, это не говорит вообще ни о чем. Другими словами, даже на банальное «Привет» можно придумать десятки ответов, которые уместны, но у которых с ответом в тестовой выборке пара общих букв, не более того. Поэтому изначально все пытались использовать метрики из машинного перевода для решения этой задачи, которая сравнивает как-то ваш ответ с тем, что у вас было написано в тестовой выборке. Но все эти попытки провалились. Есть даже такая статья, где считается корреляция метрик, используемых в машинном переводе, с воспринимаемой людьми уместностью ответов. Корреляцию можно посчитать по тестовой выборке. И оказывается, что корреляции практически нет. Значит, этим способом лучше не пользоваться.
Каким же способом пользоваться тогда? Сейчас State of the art, если можно так сказать, подход — использовать краудсорсинг, то есть брать условный mechanical turk, и спрашивать у тёркеров: «Уместен ли данный ответ в данном контексте? Оцените по шкале от 0 до 5». Или: «Какой из данных ответов более уместен в этом контексте?». Если вы посмотрите литературу, в конечном итоге всем приходится сравнивать модели именно так.

А что лучше: порождающие или ранжирующие модели? Вот мы взяли некоторую модель, которую обучили сами на Твиттере sequence-to-sequence, взяли ранжирующую DSSM-подобную модель и дальше на нашей краудсорсинговой платформе попросили работников оценить уместность каждого ответа при данном контексте, поставить одну из трех меток: bad, neutral или good. Bad значит, что ответ синтаксически некорректен, абсолютно неуместен или, например, содержит обсценную лексику. Neutral значит, что он уместен, но является общим и неинтересным. А good — что это синтаксически корректный и уместный ответ. И еще мы попросили людей сгенерировать сколько-то ответов, чтобы у нас был некий baseline, к которому можно стремиться. Вот какие получились цифры.
Что интересно, у людей есть 10% плохих ответов. Почему так происходит? Оказывается, в большинстве случаев люди пытались пошутить, но работники на краудсорсинговой платформе их шутку не поняли. Там, по-моему, в пуле был вопрос: «Какой главный ответ на все?». Ответ был «42», и видимо, никто не понял, что это значит. Там 9 из 10 — bad.
Что тут можно видеть? Очевидно, до людей еще далеко. Ранжирующие модели работают лучше — хотя бы потому, что в пуле много более интересных ответов и такой моделью проще ответ сгенерировать. А модели sequence-to-sequence работают хуже, но не то чтобы сильно хуже. Зато, как вы помните, они могут генерировать ответ в любой ситуации, так что, возможно, моделями sequence-to-sequence надо пользоваться. Или нужно комбинировать sequence-to-sequence и ранжирующие модели в виде какого-то ансамбля.
В заключение повторю основные поинты своего доклада. В последние пару лет Neural Conversational Models — по-настоящему горячая область исследований в deep learning, одна из таких областей. Ей очень много занимаются, в том числе крупные компании: Facebook, Google. Там происходит много интересного. В принципе, какими-то ее плодами можно пользоваться уже сейчас, но не следует ожидать, что у вас сразу получится искусственный интеллект. Осталось очень-очень много проблем, которые предстоит решать. И если у вас есть значительный опыт работы с текстами на естественном языке, опыт работы с диалоговыми системами или с deep learning в этой области — скорее всего, мы найдем что вам предложить.
Если вам интересно, вы можете, например, мне написать. У меня все. Спасибо.
