
Я расскажу о такой проблеме, как хеширование паролей в веб-сервисах. На первый взгляд кажется, что тут все «яснопонятно» и надо просто взять нормальный алгоритм, которых уже напридумывали много, написать чуть-чуть кода и выкатить все в продакшн. Но как обычно, когда начинаешь работать над проблемой, возникает куча подводных камней, которые надо обязательно учесть. Каких именно? Первый из них — это, пожалуй, выбор алгоритма: хоть их и много, но у каждого есть свои особенности. Второй — как выбирать параметры? Побольше и получше? Как быть с временем ответа пользователю? Сколько памяти, CPU, потоков? И третий — что делать с computational DoS? В этой статье я хочу поделиться некоторыми своими мыслями об этих трех проблемах, опытом внедрения нового алгоритма хеширования паролей в Яндексе и небольшим количеством кода.

Прежде чем переходить к алгоритмам и построению схемы хеширования, надо вообще понять, от чего же мы защищаемся и какую роль в безопасности веб-сервиса должно играть хеширование паролей. Обычно сценарий таков, что атакующий ломает веб-сервис (или несколько веб-сервисов) через цепочку уязвимостей, получает доступ к базе данных пользователей, видит там хеши паролей, дампит базу и идет развлекаться с GPU (и, в редких случаях, с FPGA и ASIС).
Что в этом случае делает защищающийся? В первую очередь — отправляет пользователей, хеши паролей которых были скомпрометированы, на принудительную смену пароля и дополнительную аутентификацию при помощи привязанного телефона, почты и т. д. В этом случае хороший алгоритм хеширования дает время на то, чтобы понять масштаб бедствия, запустить все необходимые процедуры и, в итоге, спасти аккаунты пользователей от захвата злоумышленником.
Как я упонянул выше, для ускорения вычислений атакующий может использовать такое оборудование, как GPU, FPGA, ASIC. На мой взгляд, самое опасное из этого списка — GPU, потому что очень много людей увлекается майнингом криптовалют, трехмерными играми и т. д. GPU держат наготове, чтобы начать перебирать хеши паролей. FPGA, в свою очередь, не распространены массово, стоят дорого, часто возможностей отладочной платы недостаточно, а припаять что-то в домашних условиях обычно нереально (на больших частотах повышенные требования к качеству пайки и т. д.). И, наконец, ASIC требует довольно существенных инвестиций, проектирования, запуска цикла производства. Зачастую это будет дороже, чем стоимость информации, которую злоумышлениик может добыть, взломав ваш сервис.
Ну а защищающаяся сторона обычно использует серверные CPU, на которых работают веб-приложения. У серверных CPU много ядер (но меньше, чем в GPU), большой L3-кэш и т. д. Поэтому очевидная идея при разработке алгоритмов хеширования — оптимизировать их под возможности CPU и максимально замедлять их на GPU, FPGA и ASIC. Среди подобных способов замедления можно выделить следующие:
1. Использование большого количества RAM (на GPU shared memory ограничена, а поход в global memory очень «дорогой»; на FPGA и ASIC нужно припаивать внешнюю память, что приводит к удорожанию всей схемы, задержкам при доступе и т. д.) и устойчивость к Time-Memory Tradeoff (так называемые алгоритмы Memory Hard).
2. Использование чтений/записей малого количества данных по случайным адресам в маленьком регионе памяти, который помещается в L1-кэш (если попытаться прочитать 4 байта из GPU global memory, то на самом деле будет прочитано 32 байта, что заставляет GPU впустую использовать шину памяти).
3. Использование операции умножения MUL. На CPU она выполняется так же быстро, как и обычные операции типа сдвигов и ADD, но на FPGA и ASIC это приводит к более сложной конфигурации, большим задержкам в обработке данных и т. д.
4. Использование так называемого instruction-level parallelism и алгоритма хешировния SIMD-friendly design. Современные CPU несут на борту разные advanced-наборы инструкций типа SSE2, SSSE3, AVX2 и т. д., которые позволяют проводить несколько операций за один раз и значительно ускорить вычисления.
Перечисленные техники используются не во всех алгоритмах. Так, в Argon2 (победителе Password Hashing Competition) используются все перечисленных техники, кроме второй. В Yescrypt, который получил special recognition в конкурсе PHC, используются все четыре техники (но надо включить специальный режим работы).
Для себя мы выбрали Argon2, поскольку этот алгоритм хорошо исследован, прост для понимания и реализации, а также хорошо оптимизирован для x64 и SIMD.
Если алгоритм в процессе работы использует много памяти и гарантированно занимает определенное количество времени CPU, то бездумный выбор параметров может привести к ситуации computational DoS, когда небольшие RPS могут вывести из строя веб-сервис или значительно замедлить ответы пользователю. Реальность такова, что путей выхода из ситуации не очень много. Вот некоторые из них:
1. «Залить проблему железом» — добавить много дополнительных северов, на которых работает веб-сервис. Это в каком-то смысле поможет справиться с computational DoS при должной балансировке нагрузки, но такой способ не решает проблему долгих ответов пользователю. Другими словами, добавление большого количества ресурсов не уменьшает время ответа, а всего лишь увеличивает пиковые RPS на кластер. Как вы можете догадаться, это не наш путь.
2. Максимальная оптимизация кода алгоритма хеширования, использование SIMD-инструкций и т. д.
3. Уменьшение используемых параметров алгоритма до приемлемого уровня — с добавлением различных mitigations на уровне всей схемы хеширования паролей.
Очевидно, что стоит заниматься последними двумя пунктами. Если высокая производительность для вас не так важна, то, используя оптимизированную версию алгоритма, вы можете позволить себе бóльшие параметры, что еще сильнее затруднит перебор паролей на GPU, FPGA, ASIC. А добавление mitigations на уровне схемы хеширования паролей может также сделать невозможными (или, по крайней мере, трудноисполнимыми) офлайн-атаки на базу хешей и допустить перебор хешей только в том случае, если злоумышленник находится в вашей сети, что облегчает детектирование такой ситуации и расследование инцидента.
Какие mitigations на уровне схемы хеширования существуют в настоящее время:
1. Использование локальных параметров (local parameters). Эта идея довольно проста — надо добавить в алгоритм секретный параметр, который хранится не в базе данных, а в приложении (например, в environment-переменных). Таким образом, злоумышленнику будет недостаточно получить доступ к базе данных с хешами паролей — придется ломать еще и приложение. Также администратор базы данных не сможет сдампить хеши и развлекаться с ними дома с GPU.
2. Использование большого ROM (Read-only memory) для подмешивания значений из него при хешировании паролей. Эта идея была предложена авторами Yescrypt как одна из адаптаций алгоритма для large scale password hashing. По сути, если использовать ROM порядка 100 ГБ, то его будет сложно украсть — для быстрого перебора на CPU надо иметь сервер с минимальной памятью 100 ГБ. На GPU, FPGA и ASIC все тоже будет медленно, поскольку мы не только используем большой ROM, но и оптимизируем алгоритм хеширования так, чтобы он был медленным на этих типах оборудования и т. д. К недостаткам идеи можно отнести то, что вам придется все время жить с этим большим ROM и вы, скорее всего, никогда от него не избавитесь.
3. Использование CryptoAnchors — маленьких микросервисов, которые выполняют только одну операцию: применяют PRF с секретным ключом, например HMAC. Секретный ключ хранится в микросервисе и никогда не покидает его. Суть идеи в том, что микросервис маленький, простой. Провести его аудит легко, а взломать — очень трудно, поэтому его использование позволяет превратить офлайн-атаки в онлайн-атаки. Другими словами, для атаки на базу хешей злоумышленник должен оставаться внутри сети и слать запросы к этому микросервису.

Идея CryptoAnchors используется в схеме хеширования паролей Facebook под названием Passwords Onion, но может быть задействована и в других частях инфраструктуры.
4. Использование так называемых Partially-Oblivious PRF (по сути? это часть пункта 3). Если использовать CryptoAnchors с чем-то типа HMAC, то возникает проблема смены секретного ключа при его компрометации. Один из способов решить проблему — создать еще один слой HMAC, что приводит к различным неудобствам. Кроме того, в случае обычных CryptoAnchors этот микросервис видит все хеши, которые присылает приложение. Другими словами, если сервис будет взломан, злоумышленник сможет собирать хеши в чистом виде и проводить офлайн-атаку. Для решения этих двух проблем исследователи из CornellTech предложили использовать Partially-Oblivious PRF, основанные на billinear pairing. Такая конструкция позволяет менять секретный ключ, организовывать логирование и ограничения по количеству запросов для каждого пользователя. При этом микросервис не видит хеши в открытом виде. Подробнее можно почитать в их статье.
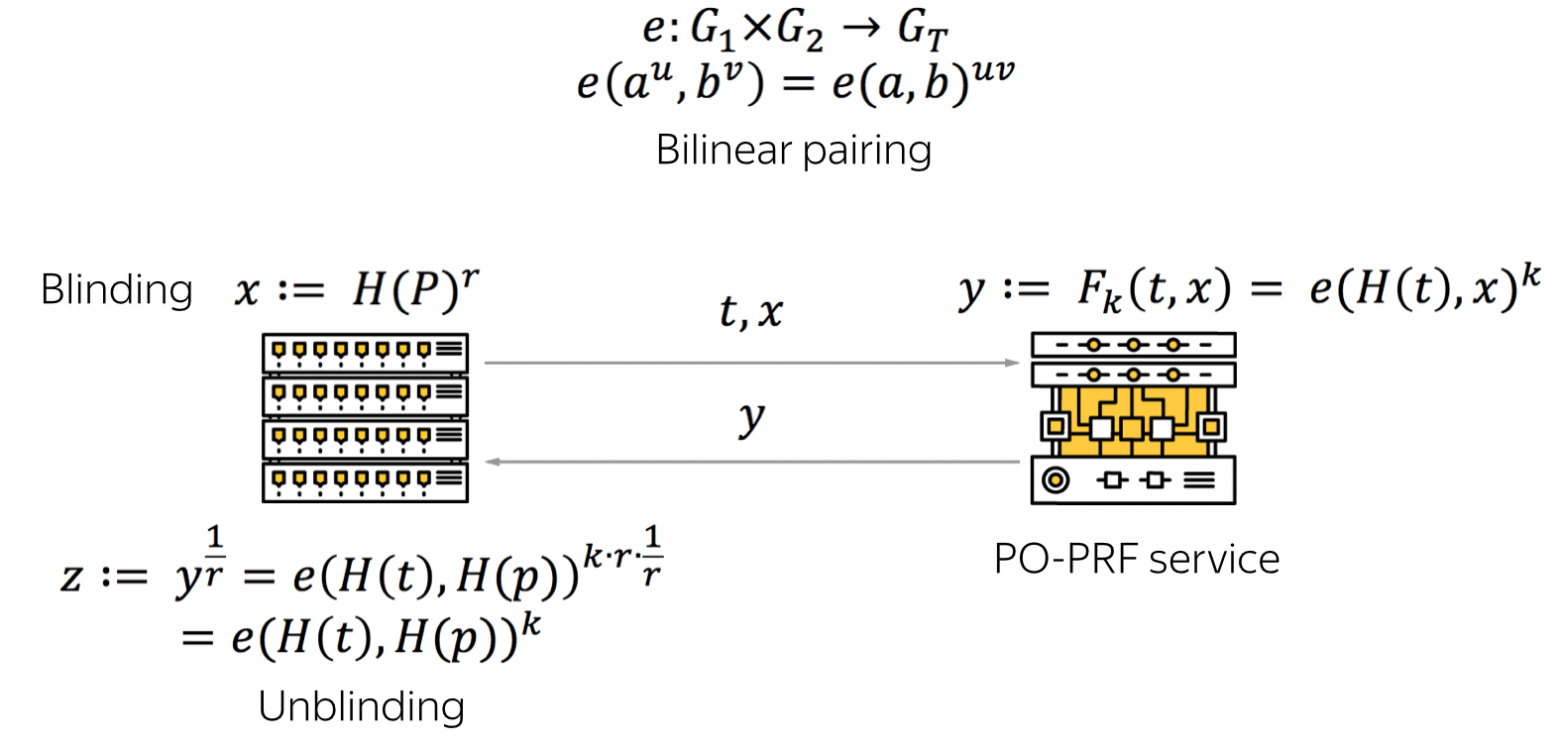
Вкратце идея такова, что приложение хеширует пароль, использует blinding для его маскировки и передает в микросервис маскированный пароль вместе с идентификатором пользователя t. Микросервис применяет billinear pairing к этим значениям, используя известный только ему ключ k и передает результат в приложение, которое, в свою очередь, может применить unblinding (снять маскировку) и сравнить результат с тем, что хранится в БД. При этом линейность billinear pairing позволяет микросервису с POPRF выдать приложению токен для обновления ключа, и приложение может пройтись по БД и обновить записи.
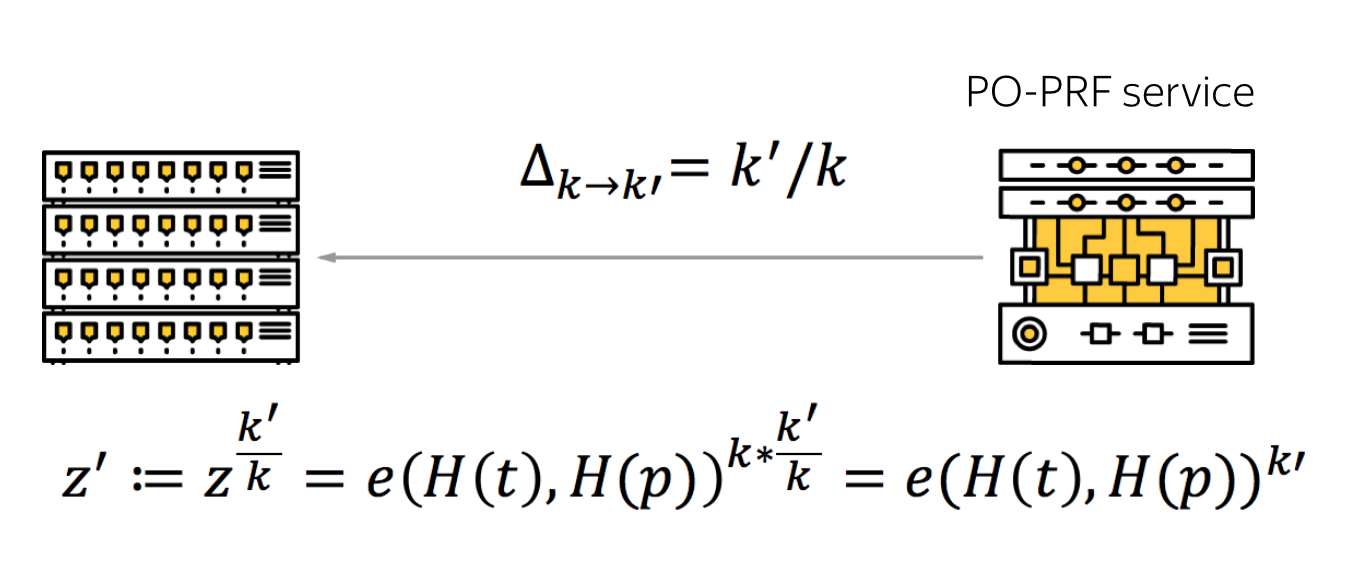
На GitHub есть официальная реализация алгоритма Argon2, однако она использует
Наша реализация использует технику под названием Runtime CPU dispatching. Ее суть в том, что при инициализации библиотеки с кодом алгоритма выполняется инструкция
И так как Argon2 использует Blake2B, то мы в качестве бонуса получили Blake2B, оптимизированный под перечисленные выше наборы инструкций. Внутри компании мы рекомендуем использовать Blake2B в качестве быстрой и безопасной замены
1. C++14 и cmake в качестве системы сборки.
2. Runtime CPU dispatching.
3. Blake2B, оптимизированный под SSE2, SSSE3, SSE4.1, AVX2.
4. OpenMP вместо pthread, а если OpenMP нет, то все вычисления будут производиться последовательно.
Также в процессе работы мы написали с нуля версию Argon2 для набора инструкций AVX2 и отправили PR в официальный репозиторий, где наши изменения были приняты мейнтейнерами.
В целом, проблема хеширования паролей в больших и высоконагруженных сервисах решаема. Для ее решения надо:
• ускорять реализацию алгоритма хеширования,
• подбирать параметры алгоритма исходя из KPI на время отклика,
• вносить изменения в схему хеширования для защиты от офлайн-атак.
Мы благодарим Solar Designer (он же Александр Песляк) за огромное количество мыслей, идей, экспериментов и полезных обсуждений проблемы хеширования паролей в больших интернет-компаниях. Еще хотим сказать спасибо Дмитрию Ховратовичу за различные идеи, совместное обсуждение и анализ разных подходов к хешированию паролей. Большое спасибо Игорю cerevra Клеванцу, который в перерывах между внесениями правок в стандарт C++ нашел время на ревью кода нашей реализации Argon2.
• Проект Аргонище на GitHub
• Официальный репозиторий Argon2
• Статья про Pythia и Partially-Oblivious PRF
• Intel Intrinsics Guide
• PASS: Strengthening and Democratizing Enterprise Password Hardening

Attacker & Defender
Прежде чем переходить к алгоритмам и построению схемы хеширования, надо вообще понять, от чего же мы защищаемся и какую роль в безопасности веб-сервиса должно играть хеширование паролей. Обычно сценарий таков, что атакующий ломает веб-сервис (или несколько веб-сервисов) через цепочку уязвимостей, получает доступ к базе данных пользователей, видит там хеши паролей, дампит базу и идет развлекаться с GPU (и, в редких случаях, с FPGA и ASIС).
Что в этом случае делает защищающийся? В первую очередь — отправляет пользователей, хеши паролей которых были скомпрометированы, на принудительную смену пароля и дополнительную аутентификацию при помощи привязанного телефона, почты и т. д. В этом случае хороший алгоритм хеширования дает время на то, чтобы понять масштаб бедствия, запустить все необходимые процедуры и, в итоге, спасти аккаунты пользователей от захвата злоумышленником.
Hardware
Как я упонянул выше, для ускорения вычислений атакующий может использовать такое оборудование, как GPU, FPGA, ASIC. На мой взгляд, самое опасное из этого списка — GPU, потому что очень много людей увлекается майнингом криптовалют, трехмерными играми и т. д. GPU держат наготове, чтобы начать перебирать хеши паролей. FPGA, в свою очередь, не распространены массово, стоят дорого, часто возможностей отладочной платы недостаточно, а припаять что-то в домашних условиях обычно нереально (на больших частотах повышенные требования к качеству пайки и т. д.). И, наконец, ASIC требует довольно существенных инвестиций, проектирования, запуска цикла производства. Зачастую это будет дороже, чем стоимость информации, которую злоумышлениик может добыть, взломав ваш сервис.
Ну а защищающаяся сторона обычно использует серверные CPU, на которых работают веб-приложения. У серверных CPU много ядер (но меньше, чем в GPU), большой L3-кэш и т. д. Поэтому очевидная идея при разработке алгоритмов хеширования — оптимизировать их под возможности CPU и максимально замедлять их на GPU, FPGA и ASIC. Среди подобных способов замедления можно выделить следующие:
1. Использование большого количества RAM (на GPU shared memory ограничена, а поход в global memory очень «дорогой»; на FPGA и ASIC нужно припаивать внешнюю память, что приводит к удорожанию всей схемы, задержкам при доступе и т. д.) и устойчивость к Time-Memory Tradeoff (так называемые алгоритмы Memory Hard).
2. Использование чтений/записей малого количества данных по случайным адресам в маленьком регионе памяти, который помещается в L1-кэш (если попытаться прочитать 4 байта из GPU global memory, то на самом деле будет прочитано 32 байта, что заставляет GPU впустую использовать шину памяти).
3. Использование операции умножения MUL. На CPU она выполняется так же быстро, как и обычные операции типа сдвигов и ADD, но на FPGA и ASIC это приводит к более сложной конфигурации, большим задержкам в обработке данных и т. д.
4. Использование так называемого instruction-level parallelism и алгоритма хешировния SIMD-friendly design. Современные CPU несут на борту разные advanced-наборы инструкций типа SSE2, SSSE3, AVX2 и т. д., которые позволяют проводить несколько операций за один раз и значительно ускорить вычисления.
Перечисленные техники используются не во всех алгоритмах. Так, в Argon2 (победителе Password Hashing Competition) используются все перечисленных техники, кроме второй. В Yescrypt, который получил special recognition в конкурсе PHC, используются все четыре техники (но надо включить специальный режим работы).
Для себя мы выбрали Argon2, поскольку этот алгоритм хорошо исследован, прост для понимания и реализации, а также хорошо оптимизирован для x64 и SIMD.
Проблема computational DoS
Если алгоритм в процессе работы использует много памяти и гарантированно занимает определенное количество времени CPU, то бездумный выбор параметров может привести к ситуации computational DoS, когда небольшие RPS могут вывести из строя веб-сервис или значительно замедлить ответы пользователю. Реальность такова, что путей выхода из ситуации не очень много. Вот некоторые из них:
1. «Залить проблему железом» — добавить много дополнительных северов, на которых работает веб-сервис. Это в каком-то смысле поможет справиться с computational DoS при должной балансировке нагрузки, но такой способ не решает проблему долгих ответов пользователю. Другими словами, добавление большого количества ресурсов не уменьшает время ответа, а всего лишь увеличивает пиковые RPS на кластер. Как вы можете догадаться, это не наш путь.
2. Максимальная оптимизация кода алгоритма хеширования, использование SIMD-инструкций и т. д.
3. Уменьшение используемых параметров алгоритма до приемлемого уровня — с добавлением различных mitigations на уровне всей схемы хеширования паролей.
Очевидно, что стоит заниматься последними двумя пунктами. Если высокая производительность для вас не так важна, то, используя оптимизированную версию алгоритма, вы можете позволить себе бóльшие параметры, что еще сильнее затруднит перебор паролей на GPU, FPGA, ASIC. А добавление mitigations на уровне схемы хеширования паролей может также сделать невозможными (или, по крайней мере, трудноисполнимыми) офлайн-атаки на базу хешей и допустить перебор хешей только в том случае, если злоумышленник находится в вашей сети, что облегчает детектирование такой ситуации и расследование инцидента.
Mitigations на уровне протокола
Какие mitigations на уровне схемы хеширования существуют в настоящее время:
1. Использование локальных параметров (local parameters). Эта идея довольно проста — надо добавить в алгоритм секретный параметр, который хранится не в базе данных, а в приложении (например, в environment-переменных). Таким образом, злоумышленнику будет недостаточно получить доступ к базе данных с хешами паролей — придется ломать еще и приложение. Также администратор базы данных не сможет сдампить хеши и развлекаться с ними дома с GPU.
2. Использование большого ROM (Read-only memory) для подмешивания значений из него при хешировании паролей. Эта идея была предложена авторами Yescrypt как одна из адаптаций алгоритма для large scale password hashing. По сути, если использовать ROM порядка 100 ГБ, то его будет сложно украсть — для быстрого перебора на CPU надо иметь сервер с минимальной памятью 100 ГБ. На GPU, FPGA и ASIC все тоже будет медленно, поскольку мы не только используем большой ROM, но и оптимизируем алгоритм хеширования так, чтобы он был медленным на этих типах оборудования и т. д. К недостаткам идеи можно отнести то, что вам придется все время жить с этим большим ROM и вы, скорее всего, никогда от него не избавитесь.
3. Использование CryptoAnchors — маленьких микросервисов, которые выполняют только одну операцию: применяют PRF с секретным ключом, например HMAC. Секретный ключ хранится в микросервисе и никогда не покидает его. Суть идеи в том, что микросервис маленький, простой. Провести его аудит легко, а взломать — очень трудно, поэтому его использование позволяет превратить офлайн-атаки в онлайн-атаки. Другими словами, для атаки на базу хешей злоумышленник должен оставаться внутри сети и слать запросы к этому микросервису.

Идея CryptoAnchors используется в схеме хеширования паролей Facebook под названием Passwords Onion, но может быть задействована и в других частях инфраструктуры.
4. Использование так называемых Partially-Oblivious PRF (по сути? это часть пункта 3). Если использовать CryptoAnchors с чем-то типа HMAC, то возникает проблема смены секретного ключа при его компрометации. Один из способов решить проблему — создать еще один слой HMAC, что приводит к различным неудобствам. Кроме того, в случае обычных CryptoAnchors этот микросервис видит все хеши, которые присылает приложение. Другими словами, если сервис будет взломан, злоумышленник сможет собирать хеши в чистом виде и проводить офлайн-атаку. Для решения этих двух проблем исследователи из CornellTech предложили использовать Partially-Oblivious PRF, основанные на billinear pairing. Такая конструкция позволяет менять секретный ключ, организовывать логирование и ограничения по количеству запросов для каждого пользователя. При этом микросервис не видит хеши в открытом виде. Подробнее можно почитать в их статье.

Вкратце идея такова, что приложение хеширует пароль, использует blinding для его маскировки и передает в микросервис маскированный пароль вместе с идентификатором пользователя t. Микросервис применяет billinear pairing к этим значениям, используя известный только ему ключ k и передает результат в приложение, которое, в свою очередь, может применить unblinding (снять маскировку) и сравнить результат с тем, что хранится в БД. При этом линейность billinear pairing позволяет микросервису с POPRF выдать приложению токен для обновления ключа, и приложение может пройтись по БД и обновить записи.

Оптимизация производительности. Аргонище — наша реализация Argon2
На GitHub есть официальная реализация алгоритма Argon2, однако она использует
‑march=native, что для нас чревато падениями сервиса с исключением Illegal instruction, поскольку у нас используются разные модели процессоров, а эта настройка заставляет компилятор оптимизировать код под модель процессора, на котором происходит сборка. Если мы создадим максимально переносимую конфигурацию сборки, то потеряем где-то 15–20 процентов возможной производительности (а в случае AVX2 — до 65 процентов). Поэтому мы создали свою реализацию алгоритма Argon2, которая позволяет максимально использовать возможности CPU, на котором происходит выполнение кода.
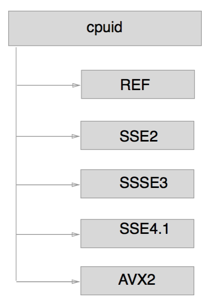
Наша реализация использует технику под названием Runtime CPU dispatching. Ее суть в том, что при инициализации библиотеки с кодом алгоритма выполняется инструкция
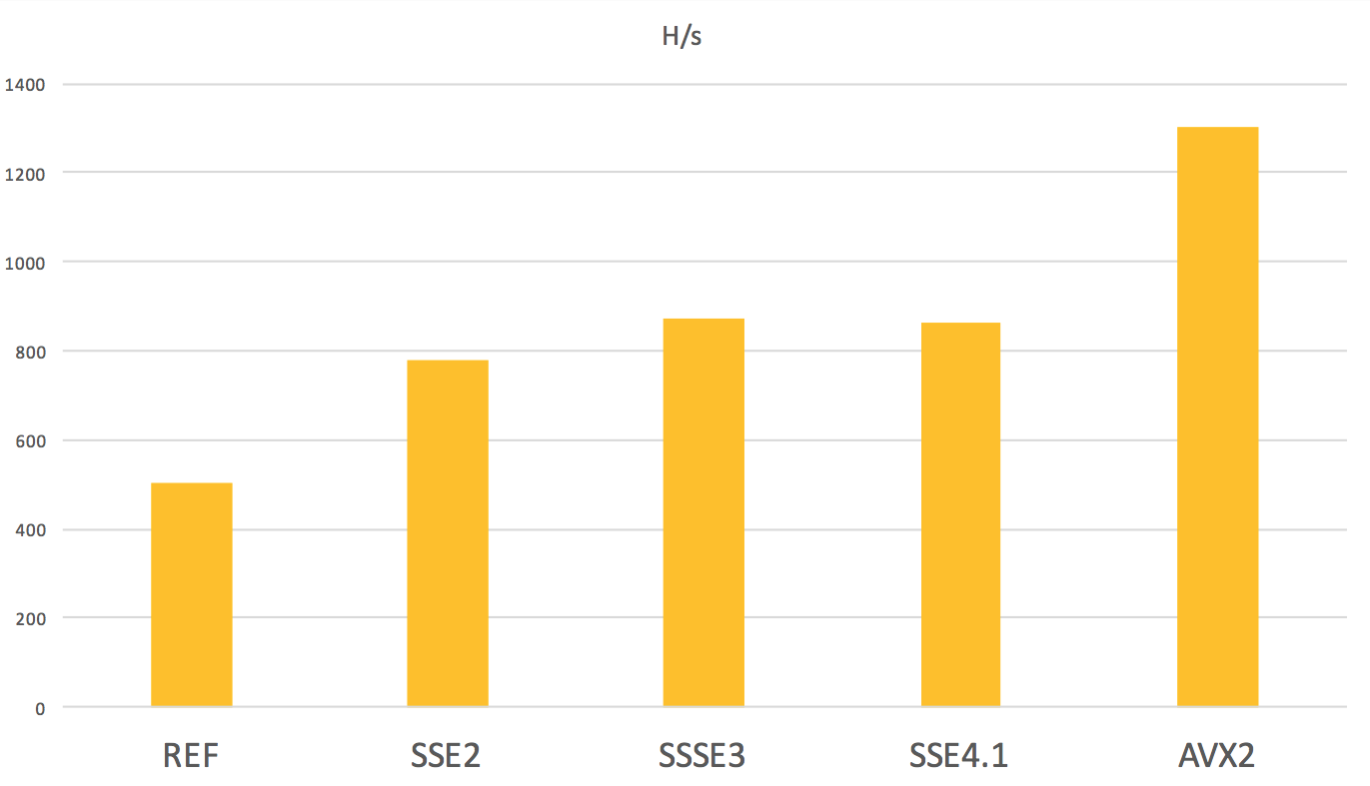
cpuid, которая определяет, какие из наборов advanced instructions поддерживаются текущим CPU, и выбирает ветку кода с соответствующими оптимизациями. Наша библиотека содержит код, оптимизированный под наборы инструкций SSE2, SSSE3, SSE4.1 и AVX2. Разницу в производительности на Argon2d с параметрами p=1,m=2048,t=1 можно увидеть на графике ниже.
И так как Argon2 использует Blake2B, то мы в качестве бонуса получили Blake2B, оптимизированный под перечисленные выше наборы инструкций. Внутри компании мы рекомендуем использовать Blake2B в качестве быстрой и безопасной замены
SHA-1 и HMAC-SHA-1. Итак, отличия от официальной реализации Argon2 следующие:1. C++14 и cmake в качестве системы сборки.
2. Runtime CPU dispatching.
3. Blake2B, оптимизированный под SSE2, SSSE3, SSE4.1, AVX2.
4. OpenMP вместо pthread, а если OpenMP нет, то все вычисления будут производиться последовательно.
Также в процессе работы мы написали с нуля версию Argon2 для набора инструкций AVX2 и отправили PR в официальный репозиторий, где наши изменения были приняты мейнтейнерами.
В целом, проблема хеширования паролей в больших и высоконагруженных сервисах решаема. Для ее решения надо:
• ускорять реализацию алгоритма хеширования,
• подбирать параметры алгоритма исходя из KPI на время отклика,
• вносить изменения в схему хеширования для защиты от офлайн-атак.
Благодарности
Мы благодарим Solar Designer (он же Александр Песляк) за огромное количество мыслей, идей, экспериментов и полезных обсуждений проблемы хеширования паролей в больших интернет-компаниях. Еще хотим сказать спасибо Дмитрию Ховратовичу за различные идеи, совместное обсуждение и анализ разных подходов к хешированию паролей. Большое спасибо Игорю cerevra Клеванцу, который в перерывах между внесениями правок в стандарт C++ нашел время на ревью кода нашей реализации Argon2.
Полезные ссылки
• Проект Аргонище на GitHub
• Официальный репозиторий Argon2
• Статья про Pythia и Partially-Oblivious PRF
• Intel Intrinsics Guide
• PASS: Strengthening and Democratizing Enterprise Password Hardening
