
A/Б-тестирование на сервисах Яндекса проводится постоянно. «Раскатить на такую-то долю аудитории» и посмотреть на реакцию людей — настолько стандартная практика, что ни у кого в команде не возникает вопроса, зачем это нужно. А чтобы не было проблем с самим тестированием, у нас есть специальная инфраструктура для экспериментов. Подробности рассказывают разработчики Сергей Мыц и Данил Валгушев.
Сергей:
— Я попробую упрощенно описать задачу A/Б-тестирования. Есть абстрактная система с пользователями, в нее мы вносим какие-то изменения, и нужно уметь измерять в ней пользу. Пока все просто, но слишком абстрактно. Пример. Есть веб-сервис по сравнению пары фотографий котов. Пользователь должен выбрать наиболее понравившуюся фотографию. При этом он может выбрать не только левый или правый снимок, но и «против всех». Значит, мы подобрали картинки не очень хорошо. Наша задача — обоснованно улучшать сервис, доказывая это цифрами.
Как нам экспериментировать? Сперва нужно понять, что такое хорошо. Мы хотим улучшать систему. Нужно выбрать то, к чему стремиться, причем не обязательно в цифрах, а в том, что мы называем направлением к идеалу. Можно хотеть, чтобы пользователь как можно реже говорил, что мы вообще не нашли ничего хорошего. Чтобы было как можно меньше отказов. Также, возможно, хорошо, когда мы можем правильно предугадывать выбор пользователя. Тогда давайте стараться, чтобы левая картинка ему нравилась чаще. Еще можно хотеть, чтобы пользователь все дольше хотел пользоваться нашим сервисом. Вдруг мы потом захотим повесить рекламу, и чем больше он будет пользоваться сервисом, тем больше он увидит рекламы. И ему хорошо, потому что ему нравится сервис, и нам, потому что нам нравится реклама. Шутка.
Это понятие нужно отобразить в цифрах, чтобы как-то его измерять. Можно ввести показатели хорошести — метрики. В качестве метрик — количество отказов от сравнения, количество правильно угаданных левых результатов, какое-нибудь средневзвешенное пользователя на сервисе на количество его действий, время на отдельные картинки и т. д. Отдельные вещи, которые, как мы считаем, отражают наш идеал.
Теперь нам нужны данные, чтобы все посчитать. Выделим действия пользователя. Возможно, нажатия на кнопки, переключение мыши. При этом мы хотим записать сам факт того, какие картинки отобразились и как долго он провел на конкретной странице. Давайте соберем все, что может нам помочь в вычислении метрик.
Научимся запоминать их на стороне клиента. Если это веб-сервис, скорее всего, это JavaScript, который отмечает какие-то действия и сохраняет их локально у себя. Потом научимся их доносить до сервера и сохранять на каждой машинке. И научимся их агрегировать и складывать в хранилище, чтобы потом обрабатывать.
Мы знаем, чего мы хотим и на каких данных это искать. Давайте теперь научимся считать. Нам нужна реализация расчета метрик — просто какой-то процесс, который будет по нашим экспериментам говорить, что в среднем у пользователя такие-то показатели метрик. Результаты стоит хранить с удобным доступом. Не просто один раз посчитать, а например, будут появляться в аналитике менеджеры, чтобы они сами могли легко получить к этому хранилищу доступ и посмотреть результаты.

Хотелось бы, чтобы поиск результатов был не очень долгим. Поэтому в хранилище нужно предусмотреть быстрый поиск и выдачу результатов — чтобы можно было двигаться быстрее. Введем несколько терминов для понимания внутренней терминологии. Экспериментальная выборка — совокупность из двух вещей: набора флагов или параметров с экспериментальной функциональностью, а также всего подмножества людей, которые включены в эти изменения.

Эксперимент — совокупность из нескольких выборок. Как правило, одна из них контрольная, и пользователи видят там наш сервис без экспериментов. Все остальные включают экспериментальные действия. Срез данных — вспомогательный аналитический инструмент. Чаще всего мы хотим посмотреть наши метрики, возможно, на какой-то ограниченной группе пользователей. Иногда нам интересно, как ведут себя пользователи в отдельно взятой стране. Иногда интересно, как мы меняем выдачу по коммерческим запросам, потому что с них приходят деньги. Интересно смотреть не на весь поток данных, а на отдельные срезы.

Надо научиться создавать и проводить эксперимент. В описании экспериментальной выборки надо как-то определить описание параметра, который будет включать этот эксперимент. Допустим, эксперимент будет сравнивать два алгоритма подбора картинок. Первый предпочитает котов по усатости, второй — по пушистости. Тогда в первой экспериментальной выборке может быть флаг isУсатый = true, во второй isПушистый = true.
Еще экспериментальная выборка будет включать то, на какой процент пользователей и, возможно, с какими ограничениями — например, в какой стране — мы хотим запускать наш эксперимент. Это все касается описания и изменения экспериментальной выборки. И нам хорошо бы уметь останавливать эксперименты и запускать их. Следим за здоровьем. Когда есть большая система, хорошо понимать, когда все ломается или когда в результате изменений что-то идет не так, как мы запланировали.
Если мы хотим проводить не один, а много экспериментов — очень полезно смотреть, что происходит в каждом из них. Например, может случиться так, что классификатор усатости будет работать чуть больше и просаживать время ответа. А это порой может быть не очень желаемая ситуация.

Нужно научиться делать выводы, делать отображение метрик по эксперименту и наличию значимых изменений. Должен быть какой-то интерфейс, который скажет, что эти метрики имеют по статистическим критериям значимые изменения — посмотри и сделай какие-то выводы. Если утверждается, что у нас все хорошо по всем метрикам, значит, надо это накатить. Если плохо и мы не понимаем, почему, то нужно разбираться. Если не будет понимания, в следующий раз можно накосячить еще больше.
Также иногда полезно рассмотреть особенности на отдельных важных срезах — например, чтобы убедиться, что время ответа на мобильных не просаживается. И удобно, когда есть инструмент для поиска возможных проблем и аномалий. Не самим смотреть все срезы, а какой-то инструмент может подсказать, что на этом срезе, скорее всего, есть нечто настолько плохое, что оно всем помешало. Вроде все относительно просто.
Данил:
— На самом деле нет. Меня зовут Данил Валгушев. Все непросто. Это связано с тем, что Яндекс — большая компания, и возникает множество интересных нюансов, о которых я хочу рассказать на конкретном примере.

У нас есть не только основной поиск. Есть поиск по картинкам и видео, почта, карты и много других сервисов.
Также у нас много пользователей, много экспериментаторов и экспериментов. Даже внутри каждого сервиса есть много различных направлений, которые мы хотим улучшать. В поиске мы можем улучшать алгоритмы ранжирования, интерфейс или создавать новые функциональные фишки.
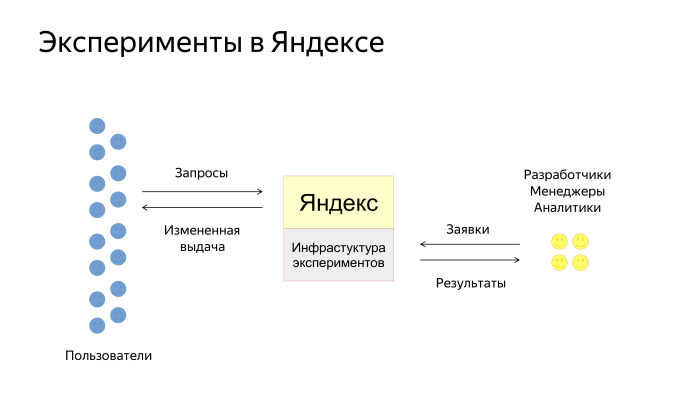
Как происходит взаимодействие наших пользователей с инфраструктурой эксперимента? Упрощенно схема выглядит так. Есть пользователи, есть Яндекс, куда встроена инфраструктура экспериментов. Пользователи задают запросы и получают выдачу, которая каким-то образом изменена экспериментом. Еще есть разработчики, менеджеры и аналитики в Яндексе, которые создают заявки на эксперименты. Мы их потом проводим и даем инструменты для анализа результатов.

Типичный эксперимент состоит из трех шагов. Менеджер или аналитик сначала проводит эксперимент на реальных пользователях и по завершении анализирует результаты и принимает решения.

К примеру, мы решили провести эксперимент и улучшить верстку результатов поиска. Мы должны создать заявку и заполнить все поля. Мы пишем, что критерии выкатки — улучшение основных интерфейсных метрик. Тип заявки — интерфейсы. Дальше создаем две выборки. Одна пустая, А, чистый продакшен. И выборка В, где есть некоторый флажок, например, goodInterface = true. Этот флажок потом через всю нашу инфраструктуру прокидывается до места назначения, до кода, который генерит интерфейс, и по этому флажку код срабатывает. Также в заявке мы говорим о целевых срезах, которые мы хотим обсчитывать в метриках, и отмечаем, на каких регионах, браузерах, платформах и на каком проценте мы хотим завести эксперимент.

Допустим, мы заполнили заявку. Оказывается, мы не можем просто так выкатить ее в продакшен. Мы должны сначала ее протестировать. Тестирование преследует две цели. Есть ручные тесты и автоматические. Ручные — это когда создатель эксперимента сам прощелкивает все, что ему интересно, весь нужный интерфейс, чтобы все работало корректно. Автоматические тесты направлены на то, чтобы избежать факапов, когда эксперимент выкатится в продакшен.
Есть два примера: проверка на падение определенных модулей сервисов или же сбор асессорских оценок по эксперименту — чтобы не допустить в продакшен очень плохие эксперименты, оттестить их еще до выкатки. Есть проблема, что, возможно, мы проводим эксперимент в первый раз и не до конца уверены, что ничего не сломаем. Тогда нам на помощь приходят наши эксперты.

По каждому сервису и по каждому аспекту качества сервиса у нас есть эксперты, которые по каждой заявке приходят и модерируют ее. Они проверяют понятность описания и корректность флагов, дают советы, смотрят, нужны ли дополнительные тесты, и в принципе сопровождают эксперименты, помогая людям, которые недостаточно хорошо в них разбираются.
Когда заявка одобрена, мы должны попасть в продакшен. Здесь тоже возникает проблема: пользователи ограничены, а заявок много. Образуется очередь.

Один из вариантов решения — многомерная схема. Одномерная схема — это когда каждый пользователь попадает ровно в один эксперимент. А многомерная — когда каждый пользователь попадает более чем в один эксперимент. Естественно, пересекающиеся эксперименты не должны конфликтовать друг с другом. Обычно они относятся либо к разным сервисам, либо к разным аспектам качества одного сервиса.

Допустим, мы попали в продакшен. Как же пользователи разбиваются на эксперименты? У нас есть некоторая конфигурация, которая фактически описывает правила. И мы пришли к тому, что эту конфигурацию удобно описывать в виде графа решений. В листьях графа находятся эксперименты, а в нодах — решения по параметрам запроса, которые включают в себя, например, идентификатор пользователя, текст запроса, адрес страницы, регион, юзер-агент, время.

Заявка попадает в конфигурацию в тот момент, когда конфигурация готовится к выкатке. Конфигурация собирается путем удаления старых заявок и добавления новых. Выкатка обычно производится несколько раз в день.

Здесь тоже возникает проблема. Мы вроде бы все эксперименты протестировали, но никто не гарантирует, что если мы накатим новую конфигурацию, у нас ничего не сломается. Поэтому мы всегда при выкатке конфигурации мониторим ключевые показатели поиска — чтобы в случае чего успешно ее откатить. Такого обычно не происходит, но мы все равно страхуемся.
Бывают более мелкие поломки, когда ломается один эксперимент. Здесь сложнее, это видно не сразу, необходимо строить графики по каждому эксперименту, по ключевым метрикам, таким как количество кликов, количество запросов. И есть система автоматического обнаружения аномалий, которая замечает, когда какой-то график начинает вести себя плохо. Есть еще система экстренного отключения, если что-то не так.
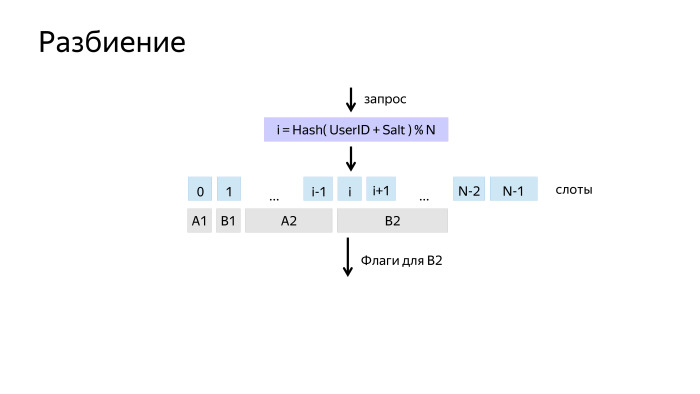
Как работает разбиение? Как разбить пользователей, чтобы они перемешались, но при этом каждый пользователь попадал в один и тот же эксперимент?

Простое решение — взять хэш от его идентификатора, и взять по модулю N. Мы получаем N возможных сходов и называем их слотами. Это разбиение мы обычно называем измерением.
Потом на слоты можно навесить эксперименты и алгоритмы. Но здесь возникла проблема. Допустим, перед нами работал эксперимент, в котором пользователям в одной выборке было хорошо, а в другой — чуть хуже. После отключения эксперимента пользователи привыкли и начали вести себя по-разному. И когда мы включаем свой, у нас возникает смещение, А и В находятся в неравных условиях.

Благодаря тому, что наш алгоритм — граф, мы можем сделать такой финт ушами: взять и еще раз перемешать пользователей перед тем, как они вновь попадут в выборку А и В. Тем самым обеспечим им одинаковые условия.
Многомерная схема тоже выглядит довольно просто. Есть специальная нода, которая распараллеливает обход графа. Обход происходит независимо на каждой ветке, и потом результат складывается.

Когда измерения ведутся в разных ветках, они обычно имеют Salt1 и Salt2 — соль, чтобы они бились независимо и не коррелировали друг с другом.

Последняя проблема связана с тем, как собрать конфигурации. Важно вспомнить, что каждый эксперимент все-таки имеет набор ограничений: проценты, регионы, браузеры, платформы и т. д. Здесь приведен пример — четыре эксперимента, которые идут в разных регионы. Как же их разместить, допустим, на 10 слотах?

Если разместим так, то видим, что каждый эксперимент по чуть-чуть отъел от каждого слота и последний эксперимент не получился, потому что он пересекается со всеми тремя.

Здесь достаточно хорошо работает простая эвристика. Когда мы ставим новый инструмент в конфигурацию, мы обычно пытаемся выбрать слоты, где уже есть какие-то эксперименты. И когда придет жирный эксперимент на широкие ограничения, нам нужно, чтобы для него осталось место.

Вот мы провели эксперимент, он отработал, мы смотрим метрики. Обязательно смотрим обычные метрики: количество пользовательских запросов, кликов — чтобы понимать, сколько данных собралось. Еще одна стандартная метрика — доля некликнутых страниц, CTR. У нас много различных метрик, и приемка происходит не по кликам и запросам, а по синтетическим метрикам. Это отдельная тема, не для нашего доклада.

Есть такие статистические тесты. Когда мы провели эксперимент, то принимаем решение. В первую очередь — проверяем критерии выкатки по метрикам, наши продуктовые соображения и обязательно советуемся с экспертами.

После завершения эксперимент уходит в датасет. Мы собираем всю историю. Она, в первую очередь, позволяет нам проводить различные исследования по методам проведения эксперимента, а также нужна для валидирования новых метрик.


Сергей:
— Это некий обобщенный обзор инфраструктуры инструментов. Мы проговорили первые две темы: что можно делать с интерфейсом взаимодействия и как происходит разбиение. А какие проблемы возникают с логированием в реальном мире?
Поскольку есть много сервисов и много источников данных, у нас получается зоопарк данных. Они разного размера, поставляются с разной скоростью. Какие-то готовы сразу, какие-то через день, какие-то через неделю. Большая проблема в том, что по этим исходным данным распределена ответственность. Каждая команда пишет свои логи, потом нам их хочется собрать. Следовательно, нужно работать с каждым по отдельности.

Из-за зоопарка данных возникают вопросы доставки и агрегации. Значит, нужно заводить сложную инфраструктуру и отлаженные процессы, которые будут со всех команд собирать логи. При этом хорошо бы иметь совместимые форматы данных, чтобы уметь обрабатывать данные по всей компании, а не ходить к каждой команде со своим парсером. Здесь пригодится общая библиотека работы с логами.
В конце концов, данные стоит агрегировать и хранить в одном месте, где их дальше удобно обрабатывать. У нас за отдельные процессы сбора логов на низком и высоком уровне отвечают свои специальные команды, которые пишут библиотеки и отвечают за время доставки данных. Поэтому у команды экспериментов упростилась задача, мы уже пришли на готовое. У нас есть общая библиотека работы с логами — с помощью нее любой аналитик может парсить все основные логи компании, если у него есть соответствующий доступ. Все данные хранятся в хранилище при MapReduce, в системе, а обрабатываются в расчетах MapReduce. У нас есть своя система YT, можно поискать, про нее были доклады.
Данные доставили, нужно рассчитывать. Обработка данных распределенная, расчет идет на сотни терабайт и на петабайты. С точки зрения интерфейса мы хотим за любой день по любому эксперименту и срезу данных получить нужные нам числа. Значит, нужно как-то подготовить данные. Мы справляемся тем, что строим выжимки, куда данные укладываются специальным образом, чтобы их можно было быстро найти в файловой системе, просто двоичным поиском и некоторыми другими специальными предобработанными индексами.
В итоге отдельные инструменты могут за секунды или минуты, если у нас очень сложный эксперимент и много данных, выгрузить цифры по любому эксперименту, который проводился в компании.

Много экспериментов — много потенциальных проблем. Сервисы очень разные, разрабатываются отдельно, своя функциональность, каждый с ними экспериментирует, а мы их собираем в общей точке, где каждый может что-то сломать по-своему. Поэтому мониторинги очень нужны и важны. Первое предложение в том, что агрегация собранных логов требует времени, поэтому хорошо бы иметь мониторинг по срыву счетчиков. Нам нужно хотя бы считать, сколько было запросов, кликов или каких-то простых действий. Эти данные готовятся очень быстро, и по ним можно увидеть, что что-то пошло совсем не так.
С другой стороны, проблемы могут быть сложными и что-то пойти не так может не просто в отдельных цифрах, а на какой-то конкретной метрике. Например, пользователи могут начать проводить меньше времени в интерфейсе или, наоборот, решать какую-то пользовательскую задачу дольше. С одной стороны, это значит, что нужно агрегировать логи и по быстродоезжающим данным расчеты метрик нужны быстрее. С другой стороны, они должны быть более полными, чем какие-то сырые счетчики. Поэтому у нас есть расчет по получасовым данным, которые за каждый получасовой промежуток готовят логи. И в течение некоторого времени можно посмотреть эти более сложные метрики.
Так как у нас много экспериментов и метрик, их необходимо мониторить, и возникает другая проблема: когда много чисел, на них сложно посмотреть. Поэтому у нас есть инструмент для автоматического нахождения проблем. Все параметры всех метрик с экспериментов отправляются туда, и он с помощью алгоритмов анализа временных рядов определяет подозрительные точки, которые мы называем разладками. Ответственному потом уходит уведомление. У нас есть интерфейс просмотра метрик, где можно изучить данные по своему эксперименту за любой день по любому срезу, который вы заказали заранее. Еще иногда хочется исследовать эксперимент более детально, в процессе может прийти идея проверить что-то, хочется как-то повертеть данные. С этим поможет инструмент быстрого анализа по произвольным совокупностям указанных срезов.
Вы говорите: посчитайте мне за эти дни по таким-то метрикам и срезам предварительные данные для этого эксперимента. Потом вы можете быстро считать по любым совокупностям указанных срезов в метрике. Например, можно быстро посмотреть по всем возможным совокупностям браузеров, умноженным на регионы, умноженным на рекламные запросы, всевозможные значения метрик и увидеть, что где-то что-то не так. Возможно, найти ошибку, а возможно, придумать новый эксперимент.
Последняя важная часть инфраструктуры — это то, как мы убеждаемся, что у нас все корректно и адекватно. Мы можем все это построить, но мы хотим экспериментировать правильно, делать правильный вывод. Значит, должны быть механизмы того, как мы за этим следим.

Есть несколько групп людей на разных уровнях, которые следят за правильностью измерений. В первую очередь, это разработчики команды АБТ, куда входим мы с Данилом. Мы разрабатываем инфраструктуру экспериментов и инструменты анализа, а также разбираем возникающие проблемы. У нас есть понимание, что и как должно быть сделано, но мы больше уходим в инфраструктурную поддержку всего этого.
Также есть исследовательские команды, которые отвечают за разработку, валидацию и внедрение новых нетривиальных метрик и подходов. Данил упоминал простые метрики, но уже n лет у нас используются сложные статистические метрики, которые провалидированы на более простых, и они позволяют более чувствительно принимать решения и видеть изменения лучше. Некоторые команды специально разрабатывают метрики. Есть эксперты по направлениям, они отвечают за правильность проведения процедуры эксперимента.
Аналитики сервисов — один из предпоследних рубежей обороны. Они отвечают за адекватность изменений через призму особенностей сервиса. Кто-то может экспериментировать, но в каждом сервисе есть один или несколько аналитиков, которые понимают, что в их случае хорошо и что плохо, и могут предотвратить нечто странное. Есть некоторая экспертиза, которая пытается удержать нас от логических проблем.
Тема обширная, многие вещи были показаны не очень глубоко. Спасибо.
Сергей:
— Я попробую упрощенно описать задачу A/Б-тестирования. Есть абстрактная система с пользователями, в нее мы вносим какие-то изменения, и нужно уметь измерять в ней пользу. Пока все просто, но слишком абстрактно. Пример. Есть веб-сервис по сравнению пары фотографий котов. Пользователь должен выбрать наиболее понравившуюся фотографию. При этом он может выбрать не только левый или правый снимок, но и «против всех». Значит, мы подобрали картинки не очень хорошо. Наша задача — обоснованно улучшать сервис, доказывая это цифрами.
Как нам экспериментировать? Сперва нужно понять, что такое хорошо. Мы хотим улучшать систему. Нужно выбрать то, к чему стремиться, причем не обязательно в цифрах, а в том, что мы называем направлением к идеалу. Можно хотеть, чтобы пользователь как можно реже говорил, что мы вообще не нашли ничего хорошего. Чтобы было как можно меньше отказов. Также, возможно, хорошо, когда мы можем правильно предугадывать выбор пользователя. Тогда давайте стараться, чтобы левая картинка ему нравилась чаще. Еще можно хотеть, чтобы пользователь все дольше хотел пользоваться нашим сервисом. Вдруг мы потом захотим повесить рекламу, и чем больше он будет пользоваться сервисом, тем больше он увидит рекламы. И ему хорошо, потому что ему нравится сервис, и нам, потому что нам нравится реклама. Шутка.
Это понятие нужно отобразить в цифрах, чтобы как-то его измерять. Можно ввести показатели хорошести — метрики. В качестве метрик — количество отказов от сравнения, количество правильно угаданных левых результатов, какое-нибудь средневзвешенное пользователя на сервисе на количество его действий, время на отдельные картинки и т. д. Отдельные вещи, которые, как мы считаем, отражают наш идеал.
Теперь нам нужны данные, чтобы все посчитать. Выделим действия пользователя. Возможно, нажатия на кнопки, переключение мыши. При этом мы хотим записать сам факт того, какие картинки отобразились и как долго он провел на конкретной странице. Давайте соберем все, что может нам помочь в вычислении метрик.
Научимся запоминать их на стороне клиента. Если это веб-сервис, скорее всего, это JavaScript, который отмечает какие-то действия и сохраняет их локально у себя. Потом научимся их доносить до сервера и сохранять на каждой машинке. И научимся их агрегировать и складывать в хранилище, чтобы потом обрабатывать.
Мы знаем, чего мы хотим и на каких данных это искать. Давайте теперь научимся считать. Нам нужна реализация расчета метрик — просто какой-то процесс, который будет по нашим экспериментам говорить, что в среднем у пользователя такие-то показатели метрик. Результаты стоит хранить с удобным доступом. Не просто один раз посчитать, а например, будут появляться в аналитике менеджеры, чтобы они сами могли легко получить к этому хранилищу доступ и посмотреть результаты.

Хотелось бы, чтобы поиск результатов был не очень долгим. Поэтому в хранилище нужно предусмотреть быстрый поиск и выдачу результатов — чтобы можно было двигаться быстрее. Введем несколько терминов для понимания внутренней терминологии. Экспериментальная выборка — совокупность из двух вещей: набора флагов или параметров с экспериментальной функциональностью, а также всего подмножества людей, которые включены в эти изменения.

Эксперимент — совокупность из нескольких выборок. Как правило, одна из них контрольная, и пользователи видят там наш сервис без экспериментов. Все остальные включают экспериментальные действия. Срез данных — вспомогательный аналитический инструмент. Чаще всего мы хотим посмотреть наши метрики, возможно, на какой-то ограниченной группе пользователей. Иногда нам интересно, как ведут себя пользователи в отдельно взятой стране. Иногда интересно, как мы меняем выдачу по коммерческим запросам, потому что с них приходят деньги. Интересно смотреть не на весь поток данных, а на отдельные срезы.

Надо научиться создавать и проводить эксперимент. В описании экспериментальной выборки надо как-то определить описание параметра, который будет включать этот эксперимент. Допустим, эксперимент будет сравнивать два алгоритма подбора картинок. Первый предпочитает котов по усатости, второй — по пушистости. Тогда в первой экспериментальной выборке может быть флаг isУсатый = true, во второй isПушистый = true.
Еще экспериментальная выборка будет включать то, на какой процент пользователей и, возможно, с какими ограничениями — например, в какой стране — мы хотим запускать наш эксперимент. Это все касается описания и изменения экспериментальной выборки. И нам хорошо бы уметь останавливать эксперименты и запускать их. Следим за здоровьем. Когда есть большая система, хорошо понимать, когда все ломается или когда в результате изменений что-то идет не так, как мы запланировали.
Если мы хотим проводить не один, а много экспериментов — очень полезно смотреть, что происходит в каждом из них. Например, может случиться так, что классификатор усатости будет работать чуть больше и просаживать время ответа. А это порой может быть не очень желаемая ситуация.

Нужно научиться делать выводы, делать отображение метрик по эксперименту и наличию значимых изменений. Должен быть какой-то интерфейс, который скажет, что эти метрики имеют по статистическим критериям значимые изменения — посмотри и сделай какие-то выводы. Если утверждается, что у нас все хорошо по всем метрикам, значит, надо это накатить. Если плохо и мы не понимаем, почему, то нужно разбираться. Если не будет понимания, в следующий раз можно накосячить еще больше.
Также иногда полезно рассмотреть особенности на отдельных важных срезах — например, чтобы убедиться, что время ответа на мобильных не просаживается. И удобно, когда есть инструмент для поиска возможных проблем и аномалий. Не самим смотреть все срезы, а какой-то инструмент может подсказать, что на этом срезе, скорее всего, есть нечто настолько плохое, что оно всем помешало. Вроде все относительно просто.
Данил:
— На самом деле нет. Меня зовут Данил Валгушев. Все непросто. Это связано с тем, что Яндекс — большая компания, и возникает множество интересных нюансов, о которых я хочу рассказать на конкретном примере.

У нас есть не только основной поиск. Есть поиск по картинкам и видео, почта, карты и много других сервисов.
Также у нас много пользователей, много экспериментаторов и экспериментов. Даже внутри каждого сервиса есть много различных направлений, которые мы хотим улучшать. В поиске мы можем улучшать алгоритмы ранжирования, интерфейс или создавать новые функциональные фишки.
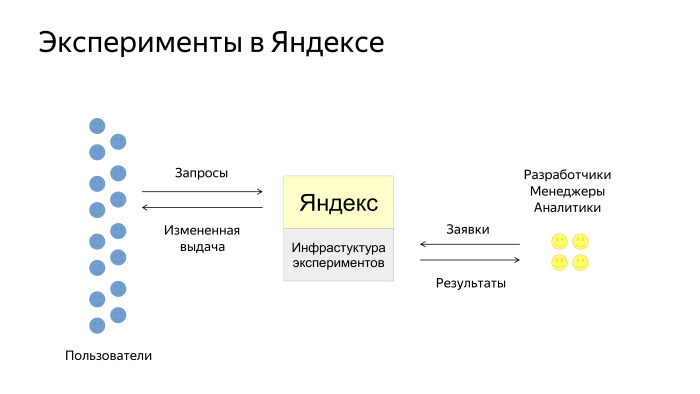
Как происходит взаимодействие наших пользователей с инфраструктурой эксперимента? Упрощенно схема выглядит так. Есть пользователи, есть Яндекс, куда встроена инфраструктура экспериментов. Пользователи задают запросы и получают выдачу, которая каким-то образом изменена экспериментом. Еще есть разработчики, менеджеры и аналитики в Яндексе, которые создают заявки на эксперименты. Мы их потом проводим и даем инструменты для анализа результатов.

Типичный эксперимент состоит из трех шагов. Менеджер или аналитик сначала проводит эксперимент на реальных пользователях и по завершении анализирует результаты и принимает решения.

К примеру, мы решили провести эксперимент и улучшить верстку результатов поиска. Мы должны создать заявку и заполнить все поля. Мы пишем, что критерии выкатки — улучшение основных интерфейсных метрик. Тип заявки — интерфейсы. Дальше создаем две выборки. Одна пустая, А, чистый продакшен. И выборка В, где есть некоторый флажок, например, goodInterface = true. Этот флажок потом через всю нашу инфраструктуру прокидывается до места назначения, до кода, который генерит интерфейс, и по этому флажку код срабатывает. Также в заявке мы говорим о целевых срезах, которые мы хотим обсчитывать в метриках, и отмечаем, на каких регионах, браузерах, платформах и на каком проценте мы хотим завести эксперимент.

Допустим, мы заполнили заявку. Оказывается, мы не можем просто так выкатить ее в продакшен. Мы должны сначала ее протестировать. Тестирование преследует две цели. Есть ручные тесты и автоматические. Ручные — это когда создатель эксперимента сам прощелкивает все, что ему интересно, весь нужный интерфейс, чтобы все работало корректно. Автоматические тесты направлены на то, чтобы избежать факапов, когда эксперимент выкатится в продакшен.
Есть два примера: проверка на падение определенных модулей сервисов или же сбор асессорских оценок по эксперименту — чтобы не допустить в продакшен очень плохие эксперименты, оттестить их еще до выкатки. Есть проблема, что, возможно, мы проводим эксперимент в первый раз и не до конца уверены, что ничего не сломаем. Тогда нам на помощь приходят наши эксперты.

По каждому сервису и по каждому аспекту качества сервиса у нас есть эксперты, которые по каждой заявке приходят и модерируют ее. Они проверяют понятность описания и корректность флагов, дают советы, смотрят, нужны ли дополнительные тесты, и в принципе сопровождают эксперименты, помогая людям, которые недостаточно хорошо в них разбираются.
Когда заявка одобрена, мы должны попасть в продакшен. Здесь тоже возникает проблема: пользователи ограничены, а заявок много. Образуется очередь.

Один из вариантов решения — многомерная схема. Одномерная схема — это когда каждый пользователь попадает ровно в один эксперимент. А многомерная — когда каждый пользователь попадает более чем в один эксперимент. Естественно, пересекающиеся эксперименты не должны конфликтовать друг с другом. Обычно они относятся либо к разным сервисам, либо к разным аспектам качества одного сервиса.

Допустим, мы попали в продакшен. Как же пользователи разбиваются на эксперименты? У нас есть некоторая конфигурация, которая фактически описывает правила. И мы пришли к тому, что эту конфигурацию удобно описывать в виде графа решений. В листьях графа находятся эксперименты, а в нодах — решения по параметрам запроса, которые включают в себя, например, идентификатор пользователя, текст запроса, адрес страницы, регион, юзер-агент, время.

Заявка попадает в конфигурацию в тот момент, когда конфигурация готовится к выкатке. Конфигурация собирается путем удаления старых заявок и добавления новых. Выкатка обычно производится несколько раз в день.

Здесь тоже возникает проблема. Мы вроде бы все эксперименты протестировали, но никто не гарантирует, что если мы накатим новую конфигурацию, у нас ничего не сломается. Поэтому мы всегда при выкатке конфигурации мониторим ключевые показатели поиска — чтобы в случае чего успешно ее откатить. Такого обычно не происходит, но мы все равно страхуемся.
Бывают более мелкие поломки, когда ломается один эксперимент. Здесь сложнее, это видно не сразу, необходимо строить графики по каждому эксперименту, по ключевым метрикам, таким как количество кликов, количество запросов. И есть система автоматического обнаружения аномалий, которая замечает, когда какой-то график начинает вести себя плохо. Есть еще система экстренного отключения, если что-то не так.
Как работает разбиение? Как разбить пользователей, чтобы они перемешались, но при этом каждый пользователь попадал в один и тот же эксперимент?
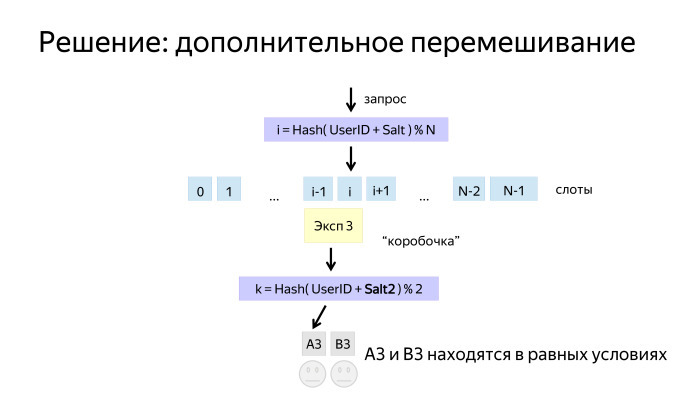
Простое решение — взять хэш от его идентификатора, и взять по модулю N. Мы получаем N возможных сходов и называем их слотами. Это разбиение мы обычно называем измерением.
Потом на слоты можно навесить эксперименты и алгоритмы. Но здесь возникла проблема. Допустим, перед нами работал эксперимент, в котором пользователям в одной выборке было хорошо, а в другой — чуть хуже. После отключения эксперимента пользователи привыкли и начали вести себя по-разному. И когда мы включаем свой, у нас возникает смещение, А и В находятся в неравных условиях.
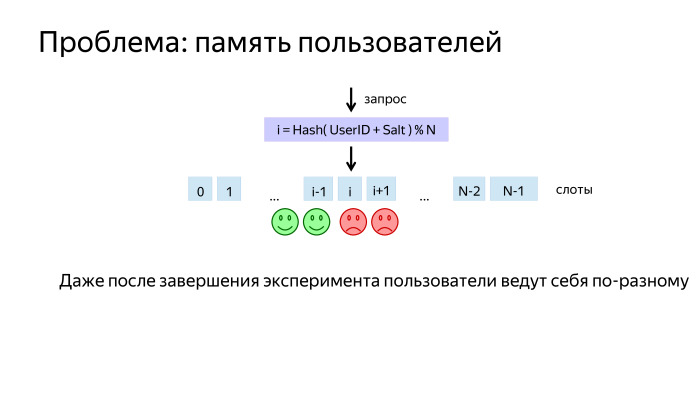
Благодаря тому, что наш алгоритм — граф, мы можем сделать такой финт ушами: взять и еще раз перемешать пользователей перед тем, как они вновь попадут в выборку А и В. Тем самым обеспечим им одинаковые условия.

Многомерная схема тоже выглядит довольно просто. Есть специальная нода, которая распараллеливает обход графа. Обход происходит независимо на каждой ветке, и потом результат складывается.
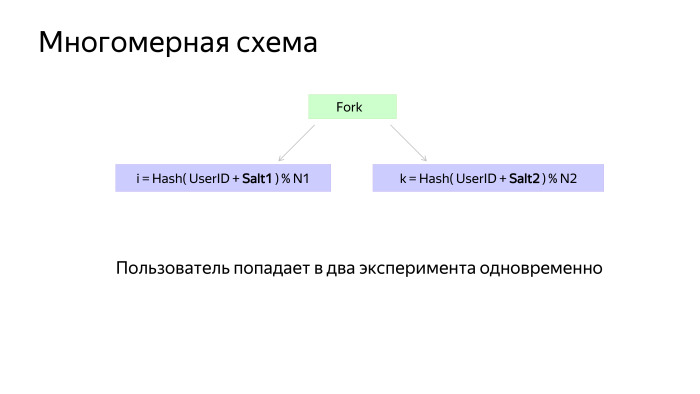
Когда измерения ведутся в разных ветках, они обычно имеют Salt1 и Salt2 — соль, чтобы они бились независимо и не коррелировали друг с другом.

Последняя проблема связана с тем, как собрать конфигурации. Важно вспомнить, что каждый эксперимент все-таки имеет набор ограничений: проценты, регионы, браузеры, платформы и т. д. Здесь приведен пример — четыре эксперимента, которые идут в разных регионы. Как же их разместить, допустим, на 10 слотах?

Если разместим так, то видим, что каждый эксперимент по чуть-чуть отъел от каждого слота и последний эксперимент не получился, потому что он пересекается со всеми тремя.
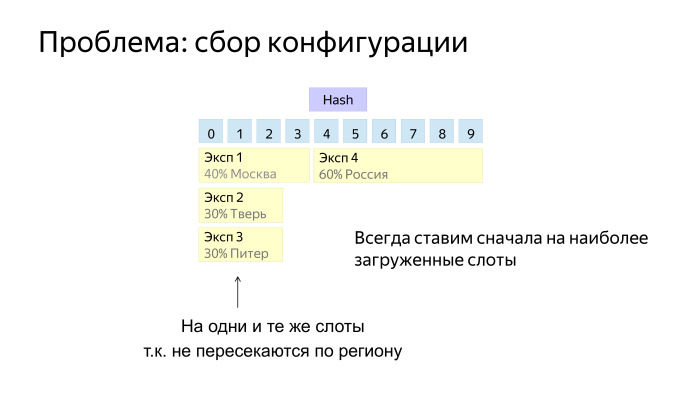
Здесь достаточно хорошо работает простая эвристика. Когда мы ставим новый инструмент в конфигурацию, мы обычно пытаемся выбрать слоты, где уже есть какие-то эксперименты. И когда придет жирный эксперимент на широкие ограничения, нам нужно, чтобы для него осталось место.

Вот мы провели эксперимент, он отработал, мы смотрим метрики. Обязательно смотрим обычные метрики: количество пользовательских запросов, кликов — чтобы понимать, сколько данных собралось. Еще одна стандартная метрика — доля некликнутых страниц, CTR. У нас много различных метрик, и приемка происходит не по кликам и запросам, а по синтетическим метрикам. Это отдельная тема, не для нашего доклада.

Есть такие статистические тесты. Когда мы провели эксперимент, то принимаем решение. В первую очередь — проверяем критерии выкатки по метрикам, наши продуктовые соображения и обязательно советуемся с экспертами.

После завершения эксперимент уходит в датасет. Мы собираем всю историю. Она, в первую очередь, позволяет нам проводить различные исследования по методам проведения эксперимента, а также нужна для валидирования новых метрик.


Сергей:
— Это некий обобщенный обзор инфраструктуры инструментов. Мы проговорили первые две темы: что можно делать с интерфейсом взаимодействия и как происходит разбиение. А какие проблемы возникают с логированием в реальном мире?
Поскольку есть много сервисов и много источников данных, у нас получается зоопарк данных. Они разного размера, поставляются с разной скоростью. Какие-то готовы сразу, какие-то через день, какие-то через неделю. Большая проблема в том, что по этим исходным данным распределена ответственность. Каждая команда пишет свои логи, потом нам их хочется собрать. Следовательно, нужно работать с каждым по отдельности.

Из-за зоопарка данных возникают вопросы доставки и агрегации. Значит, нужно заводить сложную инфраструктуру и отлаженные процессы, которые будут со всех команд собирать логи. При этом хорошо бы иметь совместимые форматы данных, чтобы уметь обрабатывать данные по всей компании, а не ходить к каждой команде со своим парсером. Здесь пригодится общая библиотека работы с логами.
В конце концов, данные стоит агрегировать и хранить в одном месте, где их дальше удобно обрабатывать. У нас за отдельные процессы сбора логов на низком и высоком уровне отвечают свои специальные команды, которые пишут библиотеки и отвечают за время доставки данных. Поэтому у команды экспериментов упростилась задача, мы уже пришли на готовое. У нас есть общая библиотека работы с логами — с помощью нее любой аналитик может парсить все основные логи компании, если у него есть соответствующий доступ. Все данные хранятся в хранилище при MapReduce, в системе, а обрабатываются в расчетах MapReduce. У нас есть своя система YT, можно поискать, про нее были доклады.
Данные доставили, нужно рассчитывать. Обработка данных распределенная, расчет идет на сотни терабайт и на петабайты. С точки зрения интерфейса мы хотим за любой день по любому эксперименту и срезу данных получить нужные нам числа. Значит, нужно как-то подготовить данные. Мы справляемся тем, что строим выжимки, куда данные укладываются специальным образом, чтобы их можно было быстро найти в файловой системе, просто двоичным поиском и некоторыми другими специальными предобработанными индексами.
В итоге отдельные инструменты могут за секунды или минуты, если у нас очень сложный эксперимент и много данных, выгрузить цифры по любому эксперименту, который проводился в компании.

Много экспериментов — много потенциальных проблем. Сервисы очень разные, разрабатываются отдельно, своя функциональность, каждый с ними экспериментирует, а мы их собираем в общей точке, где каждый может что-то сломать по-своему. Поэтому мониторинги очень нужны и важны. Первое предложение в том, что агрегация собранных логов требует времени, поэтому хорошо бы иметь мониторинг по срыву счетчиков. Нам нужно хотя бы считать, сколько было запросов, кликов или каких-то простых действий. Эти данные готовятся очень быстро, и по ним можно увидеть, что что-то пошло совсем не так.
С другой стороны, проблемы могут быть сложными и что-то пойти не так может не просто в отдельных цифрах, а на какой-то конкретной метрике. Например, пользователи могут начать проводить меньше времени в интерфейсе или, наоборот, решать какую-то пользовательскую задачу дольше. С одной стороны, это значит, что нужно агрегировать логи и по быстродоезжающим данным расчеты метрик нужны быстрее. С другой стороны, они должны быть более полными, чем какие-то сырые счетчики. Поэтому у нас есть расчет по получасовым данным, которые за каждый получасовой промежуток готовят логи. И в течение некоторого времени можно посмотреть эти более сложные метрики.
Так как у нас много экспериментов и метрик, их необходимо мониторить, и возникает другая проблема: когда много чисел, на них сложно посмотреть. Поэтому у нас есть инструмент для автоматического нахождения проблем. Все параметры всех метрик с экспериментов отправляются туда, и он с помощью алгоритмов анализа временных рядов определяет подозрительные точки, которые мы называем разладками. Ответственному потом уходит уведомление. У нас есть интерфейс просмотра метрик, где можно изучить данные по своему эксперименту за любой день по любому срезу, который вы заказали заранее. Еще иногда хочется исследовать эксперимент более детально, в процессе может прийти идея проверить что-то, хочется как-то повертеть данные. С этим поможет инструмент быстрого анализа по произвольным совокупностям указанных срезов.
Вы говорите: посчитайте мне за эти дни по таким-то метрикам и срезам предварительные данные для этого эксперимента. Потом вы можете быстро считать по любым совокупностям указанных срезов в метрике. Например, можно быстро посмотреть по всем возможным совокупностям браузеров, умноженным на регионы, умноженным на рекламные запросы, всевозможные значения метрик и увидеть, что где-то что-то не так. Возможно, найти ошибку, а возможно, придумать новый эксперимент.
Последняя важная часть инфраструктуры — это то, как мы убеждаемся, что у нас все корректно и адекватно. Мы можем все это построить, но мы хотим экспериментировать правильно, делать правильный вывод. Значит, должны быть механизмы того, как мы за этим следим.

Есть несколько групп людей на разных уровнях, которые следят за правильностью измерений. В первую очередь, это разработчики команды АБТ, куда входим мы с Данилом. Мы разрабатываем инфраструктуру экспериментов и инструменты анализа, а также разбираем возникающие проблемы. У нас есть понимание, что и как должно быть сделано, но мы больше уходим в инфраструктурную поддержку всего этого.
Также есть исследовательские команды, которые отвечают за разработку, валидацию и внедрение новых нетривиальных метрик и подходов. Данил упоминал простые метрики, но уже n лет у нас используются сложные статистические метрики, которые провалидированы на более простых, и они позволяют более чувствительно принимать решения и видеть изменения лучше. Некоторые команды специально разрабатывают метрики. Есть эксперты по направлениям, они отвечают за правильность проведения процедуры эксперимента.
Аналитики сервисов — один из предпоследних рубежей обороны. Они отвечают за адекватность изменений через призму особенностей сервиса. Кто-то может экспериментировать, но в каждом сервисе есть один или несколько аналитиков, которые понимают, что в их случае хорошо и что плохо, и могут предотвратить нечто странное. Есть некоторая экспертиза, которая пытается удержать нас от логических проблем.
Тема обширная, многие вещи были показаны не очень глубоко. Спасибо.
