Представляем вашему вниманию наш продукт — DataRetriever — сервис, предназначенный для мониторинга открытых источников (Интернет-СМИ, социальных сетей, блогов, форумов, мультимедийных сервисов) и анализа полученных данных.

Что это все значит?
Все просто :) С помощью нашего сервиса можно находить упоминания в СМИ и социальных сетях — компаний, продуктов, людей и т.д., строить графики количества публикаций, проводить анализ источников, формировать отчеты, экспортировать данные в MS Office.
Базовые настройки предусматривают работу со следующими источниками:
1. Все СМИ, представленные в Интернете и доступные для обработки
поисковыми машинами
2. Крупные блогоплощадки: Livejournal, LiveInternet, Blogspot, Wordpress, и т.д.
3. Twitter
4. Социальные сети: Facebook, В Контакте
5. Flickr, Youtube
Причем список может дополняться и изменяться без ограничений. Отслеживаются
как тексты, так и графические материалы и видео.
Как это работает?
Рабочий процесс пользователя близок к работе с поисковой системой: надо
задать список ключевых слов или фраз, и, спустя некоторое время (необходимое для
проведения мониторинга), появляются первые результаты. Далее система продолжает
мониторинг источников по заданным ключевым словам в автономном режиме, пополняя список результатов:

Поиск информации может производиться на нескольких языках. Система является
самообучающейся: если в процессе мониторинга выявляются новые источники информации, они автоматически запоминаются, расширяется первоначальный список источников, и источник автоматически удаляется из списка, если пользователь удаляет ключевые слова, связанные с этим источником.
Полученную информацию можно обрабатывать. Для этого пользователю предоставляется набор инструментов для анализа количества публикаций во времени, выявления наиболее активных источников, определения тональности публикаций, составления отчетов и экспорта их в формат MS Office, а также средства коллективной работы (чат).
Вот так выглядит график частоты упоминаний определенной темы:

Технически система основана на Drupal 6; прототипом стала одна из его малоизвестных сборок аналогичного назначения (Tattler) — мы научили ее работать с русским языком, исправили множественные ошибки и недочеты и добавили некоторые новые функции.
Кому это нужно?
Это инструмент пиарщика, маркетолога, SMO-оптимизатора, пресс-аналитика. Наличие свободной версии и работоспособной демки выгодно отличает наш продукт от конкурентов.
Варианты системы
DataRetriever существует в виде интернет-сервиса (демо версия), и в виде серверного приложения, распространяемого по лицензии GPL версии 3 (скоро выложим на сайте). Оба варианта снабжены пользовательским руководством.
Чего наш продукт не делает, но скоро будет делать
Пока нет определения местоположения авторов, надеемся оно появится в следующей версии. Также планируем снабдить систему семантическим анализатором, который позволит более точно находить упоминания и отсеивать мусор.
Собственно, это мы все к чему
DataRetriever является открытым программным продуктом. Мы приглашаем
всех заинтересованных разработчиков и пользователей к сотрудничеству в целях
дальнейшего развития продукта. А где искать таких людей, как не на Хабре.
Спасибо что потратили время. Всем удачи!

Что это все значит?
Все просто :) С помощью нашего сервиса можно находить упоминания в СМИ и социальных сетях — компаний, продуктов, людей и т.д., строить графики количества публикаций, проводить анализ источников, формировать отчеты, экспортировать данные в MS Office.
Базовые настройки предусматривают работу со следующими источниками:
1. Все СМИ, представленные в Интернете и доступные для обработки
поисковыми машинами
2. Крупные блогоплощадки: Livejournal, LiveInternet, Blogspot, Wordpress, и т.д.
3. Twitter
4. Социальные сети: Facebook, В Контакте
5. Flickr, Youtube
Причем список может дополняться и изменяться без ограничений. Отслеживаются
как тексты, так и графические материалы и видео.
Как это работает?
Рабочий процесс пользователя близок к работе с поисковой системой: надо
задать список ключевых слов или фраз, и, спустя некоторое время (необходимое для
проведения мониторинга), появляются первые результаты. Далее система продолжает
мониторинг источников по заданным ключевым словам в автономном режиме, пополняя список результатов:
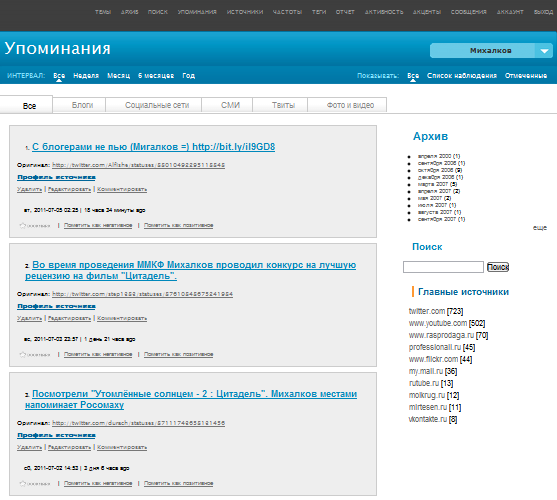
Поиск информации может производиться на нескольких языках. Система является
самообучающейся: если в процессе мониторинга выявляются новые источники информации, они автоматически запоминаются, расширяется первоначальный список источников, и источник автоматически удаляется из списка, если пользователь удаляет ключевые слова, связанные с этим источником.
Полученную информацию можно обрабатывать. Для этого пользователю предоставляется набор инструментов для анализа количества публикаций во времени, выявления наиболее активных источников, определения тональности публикаций, составления отчетов и экспорта их в формат MS Office, а также средства коллективной работы (чат).
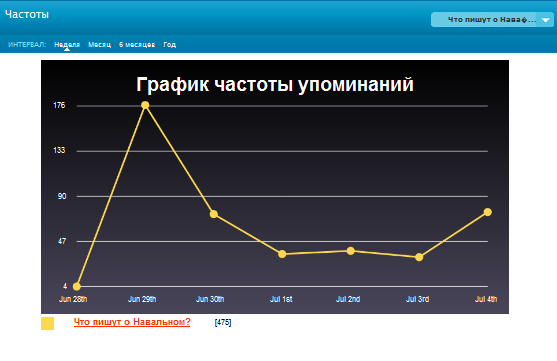
Вот так выглядит график частоты упоминаний определенной темы:
Технически система основана на Drupal 6; прототипом стала одна из его малоизвестных сборок аналогичного назначения (Tattler) — мы научили ее работать с русским языком, исправили множественные ошибки и недочеты и добавили некоторые новые функции.
Кому это нужно?
Это инструмент пиарщика, маркетолога, SMO-оптимизатора, пресс-аналитика. Наличие свободной версии и работоспособной демки выгодно отличает наш продукт от конкурентов.
Варианты системы
DataRetriever существует в виде интернет-сервиса (демо версия), и в виде серверного приложения, распространяемого по лицензии GPL версии 3 (скоро выложим на сайте). Оба варианта снабжены пользовательским руководством.
Чего наш продукт не делает, но скоро будет делать
Пока нет определения местоположения авторов, надеемся оно появится в следующей версии. Также планируем снабдить систему семантическим анализатором, который позволит более точно находить упоминания и отсеивать мусор.
Собственно, это мы все к чему
DataRetriever является открытым программным продуктом. Мы приглашаем
всех заинтересованных разработчиков и пользователей к сотрудничеству в целях
дальнейшего развития продукта. А где искать таких людей, как не на Хабре.
Спасибо что потратили время. Всем удачи!
