Вариантов и инструментов профилирования JVM много, так много, что обо всех и не рассказать. И каждый имеет свои особенности, плюсы и минусы.
Вячеславу повезло использовать разные инструменты. И повезло найти разные дефекты микросервисов на основе JVM. Спикер проанализировал, разделил инструменты и дефекты микросервисов на группы, и хочет рассказать о:
- подборе профайлеров и их настройках под задачу;
- собранных рецептах профилирования JVM в Kubernetes;
- моментах, когда профилирование вредит, а когда помогает.
Видео:
(Сергей Бойцов) Я бы хотел начать с легкого, разгоняющего вопроса. Микросервисы и Kubernetes – это наша новая реальность. Вы согласны с этим?
(Вячеслав Смирнов) Скорее всего, да. Микросервисы есть сейчас почти во всех проектах так или иначе. Их выделают, даже если это большие сервисы, т. е. макросервисы, упакованные в контейнеры и раскатанные с помощью Kubernetes, чтобы они лучше масштабировались. Все равно их называют микросервисами. Так что эта новая реальность.
(Владимир Ситников) Я вижу, что люди движутся и в одну, и другую сторону. Кто-то движется в сторону разделения, кто-то уже попробовал и движется в противоположную сторону, поэтому предсказывать, что будет через 5-10 лет я бы не стал. Я бы Вячеславу задал бы следующий вопрос. Когда был один монолит, то его как-то разработали, потом администраторы устанавливали и единороги-нагрузочники тестировали под нагрузкой. Когда делят на микросервисы, команды говорят, что мы сами с усами, все сами сделаем, все сами протестируем и не приставайте к нам. Слава, когда возникает Kubernetes, там нагрузочники вымирают или нет?
(Вячеслав Смирнов) Не совсем. Есть множество технологий, которые обещают, что тестирование производительности не понадобится, но тестирование производительности нужно и профилирование в том числе, как некий такой следующий шаг после того, как вы получили результаты и они вам не понравились. Этот этап все равно остается. И о нем я как раз хочу рассказать.
(Сергей Бойцов) Здорово! Давайте тогда послушаем. Очень интересно. Задавайте вопросы в Телеграм-чат, чтобы что-то узнать, чему-то научиться. Потому что самое плохое – это незаданный вопрос.
(Вячеслав Смирнов) Начнем.

Я вам расскажу про профилирование JVM в Kubernetes. Я назвал этот доклад «Три больших шага». Меня зовут Вячеслав и я из ВТБ.

В ВТБ занимаюсь тем, что исследую и создаю результаты нагрузки. Проект у меня называется ДБО. Если вам интересно, то зайдите на сайт vtbbo.ru.
Кроме работы занимаюсь развитием чата @qa_load, где помогаю инженерам. Помогаю я не один. Там мы делимся опытом. Отвечаем на вопросы тех, кто впервые начал заниматься тестированием производительности. У них вопросов много. Мы общаемся достаточно дружелюбно.

Проект, который мы нагружаем, можно описать в двух словах. Это 100 Java Virtual Machines, работающие друг с другом и с базой данной. Это так на тестовом стенде.
На продуктивном стенде он гораздо мощнее, он геораспределенный. Там более 200 микросервисов. С учетом геораспределения можно сказать, что даже более 400, но они так или иначе совпадают с тем, что есть на тестовом стенде.
Доклад посвящен как раз профилированию на тестовом стенде, где вам можно в любой момент перезапустить поду, поменять какие-то настройки, поэкспериментировать, поэтому он пригодится в таком случае.

Расскажу про особенности профилирования JVM в Kubernetes. Что же именно добавил Kubernetes?

Kubernetes добавил выделение ресурсов для нужд профилирования: что есть различные requests, есть различные лимиты и об этом надо помнить.

Расскажу о том, как выполнять анализ результатов, как перейти от анализа потоков к детализации что же в этом потоке выполняется и перейти на код.

Тут будет интересный момент, как оценить взаимодействие микросервисов. Например, есть медленно работающий запрос. Он работает медленно, потому что мы ждем ответа от другого сервиса.

И расскажу, как стандартизировать процесс профилирования в большой команде. У нас в команде 6 человек. Ее уже можно назвать большой командой. Я не везде такие команды видел. Тут уже требуется масштабирование.
И следующий этап – это обмен знаниями, т. е. как масштабировать, как обменяться знаниями, как стандартизировать все, чтобы процесс мог выполнять любой человек на любом количестве контуров, пусть у вас даже 3 Kubernetes-кластеров.

Доклад можно представить, как сложный пазл. И мы по кусочкам будем его собирать. Расскажу про мелкие детали и про крупные блоки.

Начнем с первого этапа. Какие есть в Kubernetes особенности при профилировании? Что он добавляет сам Kubernetes в весь процесс?

Раньше мы проводили два вида тестирования: нагрузочный и стабильности, т. е. находили максимум во время нагрузки. И во время стабильности подтверждаем, что в найденном максимуме 8-10 часов держится система и не падает.
А теперь, как минимум, нужно еще тестирование масштабируемости.

После того, как вы провели 3 вида тестирования, во всем этом есть еще одна особенность. Заказчику интересно уже не только число, что мы достигаем такой-то производительности. Важен и второй фактор. Заказчик спрашивает: «Сколько реплик сервису нужно? Какие настройки нужны? Сколько ресурсов нам нужно на кластер, чтобы все это работало достаточно производительно». Т. е. появляются дополнительные вопросы.

Самый легкий – это вопрос настроек, т. е. мы ничего не масштабируем, а меняем настройки. Поменяли некоторые конфигурации и все стало быстрее.

Если мы настройками справиться не можем и натыкаемся на то, что на тестовом стенде закончились ресурсы, то появляется интересная задача – ускорение всей этой системы.
Мне очень повезло. Я попал в команду ВТБ, когда как раз этих ресурсов не хватало, и команда занималась ускорением. Поэтому я набрался опыта по ускорению Kubernetes-кластера. И первое время занимался не столько рутинной работой по запуску тестов, сколько профилированием. И могу поделиться этим.
Когда вы начнете ускорение, сначала нужно посмотреть на результаты мониторинга, на логи. И, предположим, вы по результату мониторинга, по логам, по высокоуровневым метрикам не смогли найти способ оптимизировать систему. Условно, есть у нас кластер, 10 серверов. В него влезает 100 сервисов. Зафиксировали, промониторили и так ничего не смогли найти.

Тогда уже можно подключить профайлер. Можно не сильно масштабировать. И можно посмотреть изнутри JVM с помощью профайлера изменение каких настроек нам сможет помочь все это ускорить и сократить ресурсы.

Я несколько раз сказал уже о настройках. В Kubernetes принято увеличивать производительность системы очень просто, т. е. увеличивать количество реплик. Считается, что 2 реплики работают быстрее, чем одна. Но на самом деле нет.
Есть способ не увеличивать количество реплик, а увеличивать количество потоков внутри каждой реплики. Если мы говорим про JVM, то тут, как правило не однопоточное приложение, а многопоточное.

Я написал несложный алгоритм, чтобы понять нужно ли нам сейчас реплики увеличивать или нет.
Если у нас приложение однопоточное, но упакованное в Kubernetes и у нас нет возможности количество потоков изменить, то чтобы его масштабировать, будем увеличивать количество реплик. И это черный прямоугольник снизу.
А если количество потоков можно менять, то стоит попробовать их увеличить или уменьшить, т. е. как-то настроить, чтобы добиться лучшей производительности.
Если производительность при этом увеличивается и после увеличения пула потоков у нас все еще есть свободные ресурсы, то можем этот процесс повторять до тех пор, пока мы не упремся в лимит нашего контейнера, в лимит нашей поды.
И когда мы уже уперлись в лимит нашей поды (можем создавать там 2-3-4 поды), то мы знаем, что для 50 потоков нужна такая конфигурация.

При увеличении количества реплик аналогичная ситуация. Если мы изменяем количество реплик, и становится быстрее, и при этом у нас еще есть свободные ресурсы, то мы можем этот процесс наращивать, т. е. проводить тестирование масштабируемости.
А если мы увеличиваем количество реплик, например, сделали вместо одной две, но быстрее не становится, то это второй момент, когда нам нужно подключить профайлер или какие-то другие инструменты, которые нам помогут узнать, почему не становится быстрее.

Какие это могут быть инструменты? Это тоже хороший вопрос. В Kubernetes не все так однозначно. Иногда Kubernetes JVM профайлер не нужен.

- Есть цикл тестирования, где мы сначала проводим регрессионный тест, т. е. просто сравниваем. Например, была версия 1, у нее производительность стала версия 2. И ее метрики в JMeter, Gatling сравниваем. И можем определить узкое место, если видим деградацию по той дельте изменений, которая была между версией 1 и версией 2. И даже можем определить место, которое сильнее всего тормозит.
- Если нужно копнуть глубже, то нужно посмотреть на статистику балансировщика нагрузки, детализацию по логам ошибок, если вдруг в новой версии появились ошибки.
- Можем посмотреть на бизнес-метрики производительности. Например, посмотреть в Яндекс.Метрике, Google Analytics, как там пользователь на prod’е чувствует себя. В нашем проекте есть встроенные метрики внутренней производительности.
- Кроме этих метрик, как правило, во всех Kubernetes-инсталляциях есть такие сервисы, как Zipkin, Jaeger, которые собирают статистику за счет трассировки запросов при передачи их от микросервиса к сервису. Это более детальная статистика, чем даже в самом JMeter.
- Кроме того, не стоит забывать про мониторинг системных метрик.
- Мониторинг более внутренних метрик, например, внутри JML, SQL
- И если после всего этого объема информации вам недостаточно, то тогда 7-ым этапом можно запрофилировать JVM.
- Профилировщик сможет найти не все. Иногда в моей практике пригождаются утилиты strace, perf и другие, которые позволяют найти то, что изнутри JVM не видно.

Если это визуализировать как-то в картинку, то визуализацию я смогу для вас изобразить вот такую.
Вот у вас есть браузер, т. е. клиент. Этот браузер обращается к вашему сервису. Он представляет из себя 4 сервиса переднего уровня и там есть 100 микросервисов на бэке.
И нам нужно определить, какой микросервис самый медленный.

Чтобы это определить, нам не обязательно использовать профилировщик. Нам хватит отчета по нагрузке. Т. е. такая статистика будет в JMeter, Gatling. А также бизнес-метрики или даже статистики по логам. В том же nginx можно настроить детальное логирование.

Предположим, вам нужно определить, при каких параметрам этого запроса данный микросервис более медленный.

Это в отчете по нагрузке, если вы эти параметры использовали или в более детальных логах. Там можно уровень логирования поднять и узнать все детали, т. е. какой же параметр приводит к замедлению.
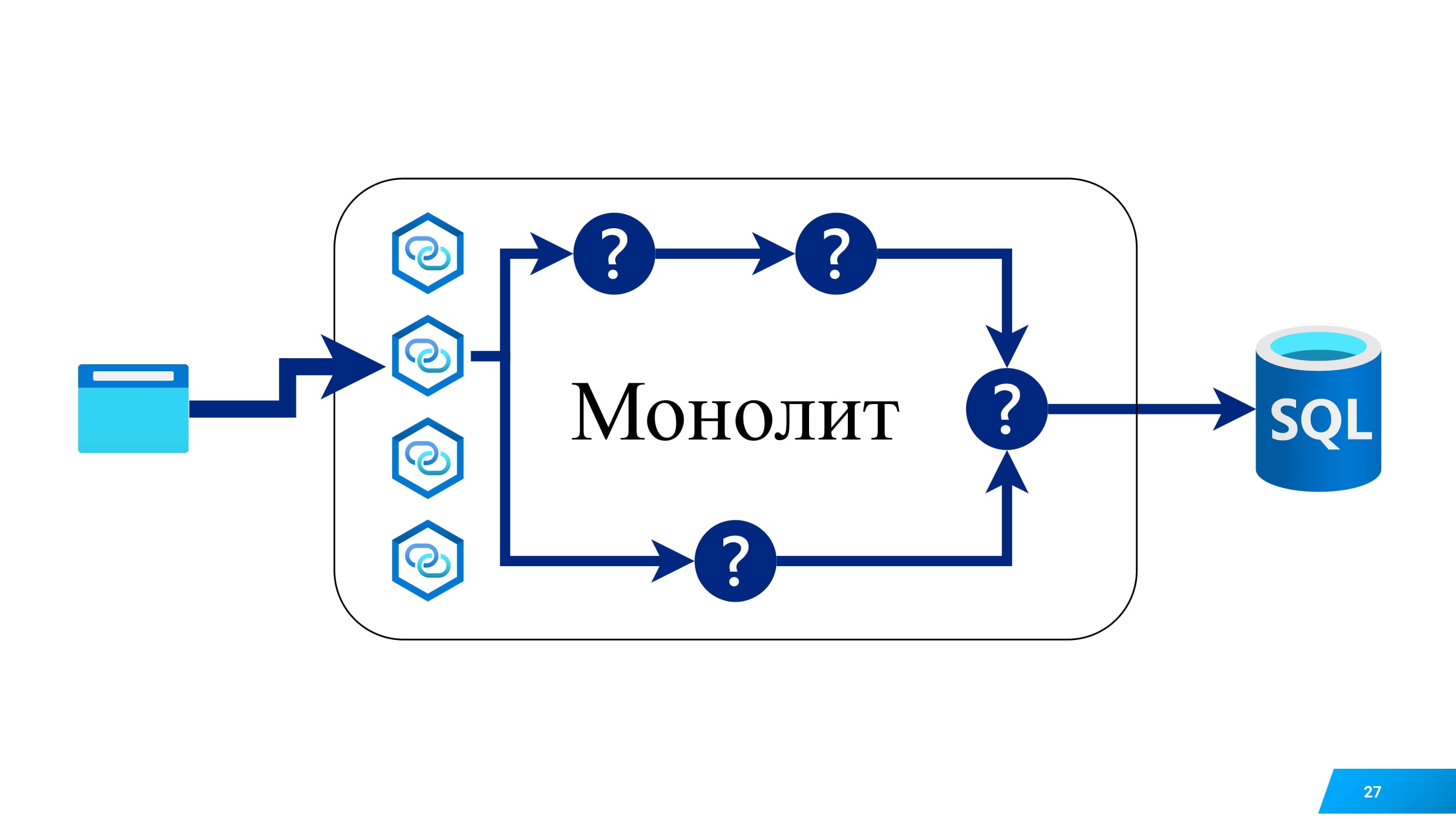
Если бы у нас был монолит, мы бы тыкали в какую-нибудь url монолита и желали узнать, что внутри приложения тормозит, т. е. какой модуль, компонент, то, скорее всего, мы бы взяли профайлер.

Мы бы профилировали этот монолит и сказали, что тормозит.

А с микросервисами не так все просто. Нет единого исполняемого файла. У нас целая россыпь микросервисов. Они общаются друг с другом. Каждый из них может самостоятельно ходить в базу и другие системы.

И тут очень полезными являются инструменты Zipkin и Jaeger, которые трассируют запросы между сервисами и предоставляют полезную статистику.
О чем я? О том, что профайлер нужен не всегда. Иногда могут пригодиться и другие инструменты, чтобы закрыть все ваши нужды.

Чуть ранее я упоминал о особенности Kubernetes, что при начальном масштабировании мы можем увеличивать количество потоков.
Но бывает и обратная ситуация, когда потоков внутри нашего приложения изначально очень много, т. е. больше, чем нужно. И если мы занялись профилированием, и мой доклад об этом, то расскажу вам, как влияет количество ненужных потоков на эффективность профилирования.

Самый частый способ профилирования, который использую я, это вычисление процента активности того или иного метода. Делается это, как правило семплированием.
В JFR, SJK, AsyncProfiler, VisualVM и т. д. есть режим семплирования.

Если вы не знаете, что это такое, то вы наверняка знаете, что такое Stack Trace. Видели это в логах или в различных инструментах. Это последовательность вызовов Java-методов.

И если накопить статистику по этим Stack Trace, то можно что-то понять. Например, вот у нас 4 раза метод putVal, 8 раз метод sample в строчке 613.

Я накапливаю, накапливаю и получаю статистику, какие методы у меня более часто встречаются во время работы потока, какие менее часто.

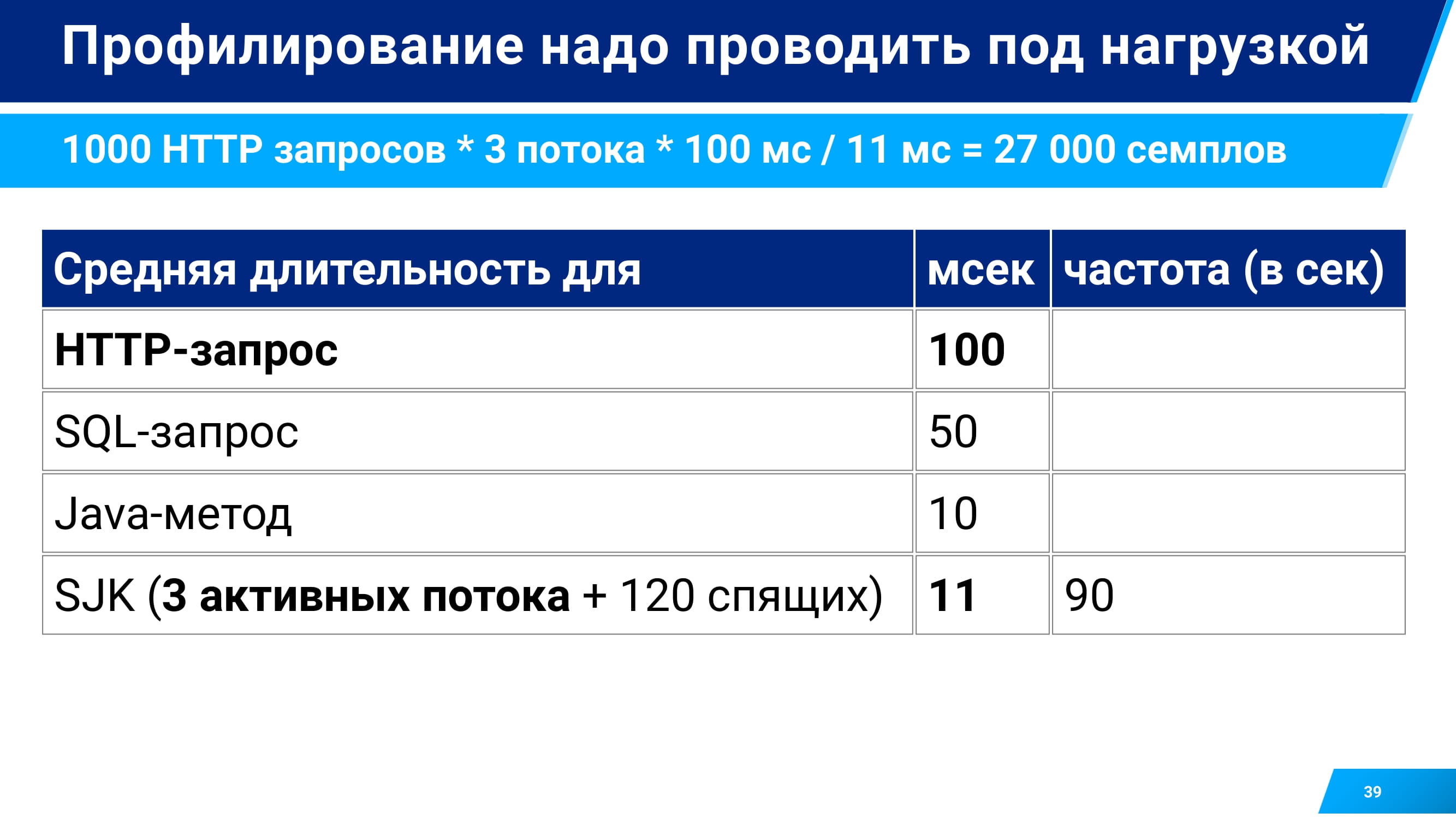
И как на сбор этой статистики, т. е. на процесс семплирования, влияет количество потоков? Чтобы это определить, я собрал небольшой тестовый стенд. У меня был один сервис, принимающий запросы по http. В нем можно было менять количество потоков от 200 (по умолчанию) до 5. И использовать JMeter, который подавал нагрузку всего лишь тремя потоками. Т. е. чтобы со всеми этими запросами справится, сервису достаточно тоже всего лишь 3 потока у себя. Все остальные спали и ждали, когда к ним перепадет запрос и перепрофилироваться с помощью SJK.

Какие результаты я получил? Получил такие результаты, что запросы в среднем выполнялись 100 миллисекунд. Самые тяжелые методы – 10 миллисекунд.

И когда у меня было 120 лишних потоков, то SJK, профилируя все активные потоки, в том числе 120 спящих, собирал метрики с интенсивностью 90 раз в секунду. Получается, что в среднем каждые 11 миллисекунд он лишь собирал stack trace.
При такой интенсивности он мог легко пропустить Java-методы, которые работают даже в среднем быстрее.
Конечно, он ловит все http-запросы, т. е. кто их отправляет и как долго ждет, а Java-методы может легко пропустить.

Если снизить количество потоков до 20, оставить только 20 спящих, то частота семплирования гораздо выше становилась. И уже интервал семплирования снижался до 3 миллисекунд. Это значит, что туда попадали даже те методы Java, которые быстрее, чем средние.

Результаты можно представить на таком графике.

Я провел серию замеров.

Если снизить количество потоков со 120 до 20, то у нас интенсивность семплирования повышается в 3 раза.

А по умолчанию tomcat.mat-threads – это 200 потоков.
Если постепенно снижаться с 200 до 5, то интенсивность повышается в 5 раз. Это о том, что не только увеличение количества потоков полезно. Для задач профилирования снижение – это тоже интересный момент, хоть и неочевидный.

Какая получалась частота семплирования в SJK? Я измерял с помощью команды ssa, которая есть в SJK. Это Stack Analyzer. Выводил колонку интенсивности, которая получилась. И смотрел, что по интенсивности получается. В данном случае почти 60 раз в секунду.

Следующей особенностью в Kubernetes является влияние CPU Limit на профилирование и на сам процесс профилирования.

Я использовал тот же самый стенд, но в нем ограничил возможности использования процессора данным сервисом до 1 ядра.

Получились следующие результаты. Когда я не ограничивал, то я собирал интенсивность метрики 90 раз в секунду, а как ограничил, и весь сервис замедлился, то интенсивность профилирования снизилась. Стало всего лишь 7 раз в секунду. И с такой интенсивностью я не поймаю различные супербыстрые метрики. Т. е. при неправильной настроенном лимите и запуске профилирования можно хорошие метрики не собрать.

Примеры показали, что SJK на большом количестве потоков затрачивает где-то 0,36 ядра. Об этом надо помнить.

И если вы начали профилирование в Kubernetes, то чуть-чуть добавьте для накладных расходов самого профайлера CPU, т. е. поднимите лимит.

Если вы не можете поднять, то можете просто снизить интенсивность семплирования. Это настраивается во всех профайлерах. В VisualVM, например, интенсивность семплирования по умолчанию 100 миллисекунд. И такую же интенсивность можно задать во всех других профайлерах. Но в этом случае вам нужно будет профилировать чуть подольше. Не 10-30 секунд, а, например, 10 минут профилировать.

Кроме CPU Limit в Docker и Kubernetes есть Memory Limit. Он также влияет на профайлер, но уже на другие.

Здесь несколько иная задача профилирования. Задача посчитать не просто процент активности, а посчитать точную длительность и количество выполнений каждого метода. И это позволяют уже выполнить инструментирующие профайлеры.
Среди тех, которые я успешно пробовал, могу назвать VisualVM. В режиме Startup Profiler его можно подключить и запрофилировать в таком инструментирующем виде. А также JProfiler и YourKit Java Profiler.

Что такое инструментация? Если ее описывать в виде схемы, то это непростой процесс при работе с JVM профайлером. Например, для C проектов инструментация есть на уровне компилятора. В GCC вы можете заинструментировать компилируемый код и получить там какие-то метрики. И все эти метрики будут на уровне исходников туда вшиты, и выполняться до запуска.
А при JVM инструментации более популярен подход на лету с помощью JVM-агентов, когда меняется JVM Byte-код. Это уникальная фишка JVM.

Когда ваше приложение запустилось, в нем уже 1 000 классов, различные объекты, и вы начинаете каждый класс перелопачивать, т. е. до запуска каждого метода вставлять некий быстрый, но все же код, то это все потребует дополнительных расходов памяти.

И сам процесс инструментации потребует дополнительных расходов процессора.
Мы сталкивались в команде с такими эффектами, что приложение падало из-за недостатка ресурсов памяти, если сделали вот такое инструментирующие профилирование.

Тут общая рекомендация, что если вы запускаете еще инструментирующее профилирование с помощью JVM-агента, то добавьте себе в поду немножко памяти тоже.
Если вы явно не влияете в вашей поде на размер heap size, т. е. Xmx, а влияете только на лимит. Например, Xmx вычисляется с помощью MAX_MEM_RATIO, есть такая опция в некоторых контейнерах. И чтобы добавить 1 гигабайт, вам нужно лимит поднять на + 2 гигабайта.

Так или иначе помните, что нужно добавлять ресурсы, если вы делаете тяжелое профилирование.

Почему это важно? Что это за такие ресурсы? Можно описать это двумя словами.

Вот здесь request, т. е. внутренняя граница контейнера. И есть лимит – внешняя граница контейнера.
Для контейнера можно задавать только request – это первая картинка. И делать его изначально маленьким.
Можно задавать маленький request и достаточно крупный лимит – это вторая картинка.
Некоторые выбирают стратегию, когда request практически равен лимиту и он изначально большой.
Некоторые выбирают, когда request огромный, а лимит не задан. Это для тяжелых гибких сервисов.
А рекомендация – накинуть 1 гигабайт и 1 гигабайт CPU.

Что будет, если мы не накинем и у нас есть вот такая инсталляция, где есть профилируемые сервисы и в двух из них лимиты не заданы?
Сначала они будут маленькими. Под нагрузкой, конечно, сервисы начнут потреблять больше ресурсов.

И вот они все выросли.

И первому центральному сервису стало не хватать ресурсов.
Если ему не хватает CPU, то ничего страшного не случится. Как я вам рассказал, интенсивность семплирования снизится, т. е. она застынет на какой-то планке. Возможно, это будет даже 7 sample в секунду, но ничего не случится.
А если так случилось, что в приложение выделено heap в 2 гигабайта, а у нас физически на кластере остался один гигабайт памяти, то JVM будет думать, что ей можно выделить столько памяти, а физически столько памяти нет. И контейнер, т. е. приложение упадет по out of memory error. В этом случае весь контейнер схлопнется и перезапустится. Там начнется все с начала.

Но процесс профилирования прекратиться, т. е. что-то разломается, сессию с профайлером мы потеряем.

Второй случай, если у нас лимит задан, но не у всех. Сначала тоже будет все хорошо.

Мы начнем подавать нагрузку.

Контейнеры начнут потреблять больше ресурсов.

И может так случиться, что одному из контейнеров, у которого лимит задан, ресурсов будет не хватать.
Тут важный момент проявляется в особенностях самого Kubernetes.

Если ресурсы можно выделить Kubernetes’у за счет того, чтобы погасить какие-либо сервисы, у которых ниже приоритет, чем у текущего, а если у нас лимит задан и приоритет выше, то Kubernetes так и поступит. Он возьмет другую поду, у которой лимит не задан и погасит ее, перезапустит ее.

В этом случае данная пода не сломается, она получит свои ресурсы, но, возможно, сломается что-то еще. Сервис контроля доступа и профилирование или весь процесс все равно разрушатся, потому что что-то пошло не так.
В случае, если у нас всех сервисов по одной штуке, тогда вообще бизнес-процесс остановится.

И самый желательный вариант, когда везде лимиты заданы.

Мы начинаем нагрузку. Сервисы были маленькие.

Вот они стали побольше.

И вот им ресурсов не хватило.
Какой тут вариант? Мы знаем, что этому сервису нужно столько-то ресурсов.

И при профилировании накидываем чуть-чуть.
Можно 0,3-0,4, можно +1. И все будет работать, как будто бы и не было никакого профилирования. Это такая особенность Kubernetes.

Какие есть особенности у самих профайлеров при работе с распределенными системами?

Можно все профайлеры и способы их подключения разделить на 2 больших типа:
- Мы подключаемся удаленно, т. е. запускаем профайлер у себя на рабочей станции и подключаемся к поде или сервису;
- Мы подключаемся локально.

Самый привычный, когда вы запускаете профайлер с графической оболочкой у себя на рабочей станции. Это удаленный вариант.
В чем его особенности? Его особенности в том, что вам нужно пробросить сетевое подключение от вашей рабочей станции до профайлера, т. е. есть несколько фишек самого Kubernetes.

- Предположим, вам нужен доступ до поды лишь на время. Тогда воспользуйтесь kubectl и ее опцией PortForward с пробросом локального порта в поду.
- Если вам нужен постоянный доступ, то проще зафиксировать выставление порта для профилирования из пода наружу, например, задав эти настройки уже в сервисе.
- Очень удобно делать, если ваш сервис всегда заскейлен в 1. В этом случае вы всегда, начиная профилирование, будете попадать в профилируемую вами поду.
- Это можно сделать через NodePort.
- Можно сделать через LoadBalancer.
- А если вы заскейлили сервис в две реплики и хотите сделать тоже самое через внешний порт, то, скорее всего, не получится.
- Потому что ваш профайлер будет обращаться за результатами профилирования в поду. И будет попадать то на первую, то на вторую. И профилирование не получится. Или получится каким-то неправильным. Это единственное такое ограничение.

Если вы выбрали такой способ, то две техники: с помощью Java-агента и с помощью технологии JSR 160 Standard, где вам нужно открыть два порта: JMX и RMI и пробросить их себе.

Расскажу сначала про этот вариант.

Чтобы открыть эти порты JMX, RMI, вам понадобится в опции JVM запускаемого сервиса внутри докера добавить вот такой перечень опций. Как правило, я задаю такие опции в deployment-файле.
Вот вы открываете порт 9010. Можно и для JMX, и для RMI задать одинаковый порт. В данном случае это не критично. И с помощью kubectl или с помощью другого инструмента взаимодействия с Kubernetes CPI пробрасываете свой порт внутрь поды.

Если вам нужно запрофилировать и пробросить порты и для сервиса аутентификации и для сервиса генерации отчетов, и для сервиса генерации отчета, то у вас получится такое сделать, если вы во всех подах задали одинаковый порт. Потому что, когда вы будете открывать соответствующий порт у себя на станции, kubectl скажет: «Я не могу дважды открыть порт 9010, он уже кем-то занят».

В этом случае вам в другом сервисе нужно отсылать в другой порт. Например, 9011, т. е. какой-то иной. Помните об этом. И нужный порт к нужному подсоединить.

Если вы решили это делать не с помощью таких постоянных действий, как пробрасывание порта, можете зафиксировать порт через NodePort в разделе Service. В этом случае вам в опции JVM нужно прописать именно тот порт, который вы открываете в сервисе.
И тут последовательность несколько иная. Вы сначала в разделе Service говорите: «Я хочу, чтобы из данного сервиса наружу торчал порт 31111». Если такой порт не занят, то он открывается. Если вы убедились, что он открылся, он зафиксирован и вашему сервису принадлежит, то потом идете в настройки сервиса в раздел Deployment и там соответствующий порт задаете, т. е. в обратном порядке.

Если вы никогда работали с Kubernetes-дашбордом, то это Deployments и Service. Т. е. сначала во внешний раздел идете, там настраиваете, открываете порт. А потом в Deployment его указываете.

Хорошую документацию, где есть инструкции с картинками, что это за порты и как их прокинуть именно из докер-контейнера, описал Алексей Рагозин в блоге компании BellSoft. Это один из разработчиков JVM. Называется «JVM in Linux containers, surviving the isolation». Всем рекомендую прочитать эту статью, если вы пользуетесь таким способом. Она доступна по ссылке, данная ссылочка кликабельная.

По такой технологии вы можете подключить различные инструменты: SJK, JMC, VisualVM.

Один из самых простых инструментов – это SJK.

Вот вы пробросили порт, потом у себя пишите такую команду, где можете выставить профилирование с ограниченной интенсивностью или с максимальной интенсивностью на 5 минут.

Второй по простоте – это, наверное, JMC и технология Java Flight Recorder.

С ней есть несколько особенностей. Она заключается в том, что технология JFR появилась в OpenJDK в 8-ой не сразу, а только с версией 272.
И если у вас версия 272, то открывайте JMX, RMI также, как для предыдущих инструментов и пользуетесь.
Если у вас старый 8-й OpenJDK, то у вас просто ничего не получится. Вам нужно или монтировать Java в контейнер, или не пользоваться этим способом.
Если у вас Oracle JDK, то там есть еще более тонкий момент. До build 161, даже до build 162 лицензия на Oracle JDK позволяла использовать JFR на тестовых стендах при включении опции UnlockCommercialFeatures и опции FLightRecorder.
Если у вас более старшая версия, то вам нужно будет купить лицензию. Она исчисляется стоимостью по ядрам. Сам я не использовал такой способ после смены лицензии.

Если вы все настроили, то дальше в Java Mission Control создаете подключение.

Указываете порт, который вы открыли. Например, 9010.

Открываете JMX Console с помощью Java Mission Control.
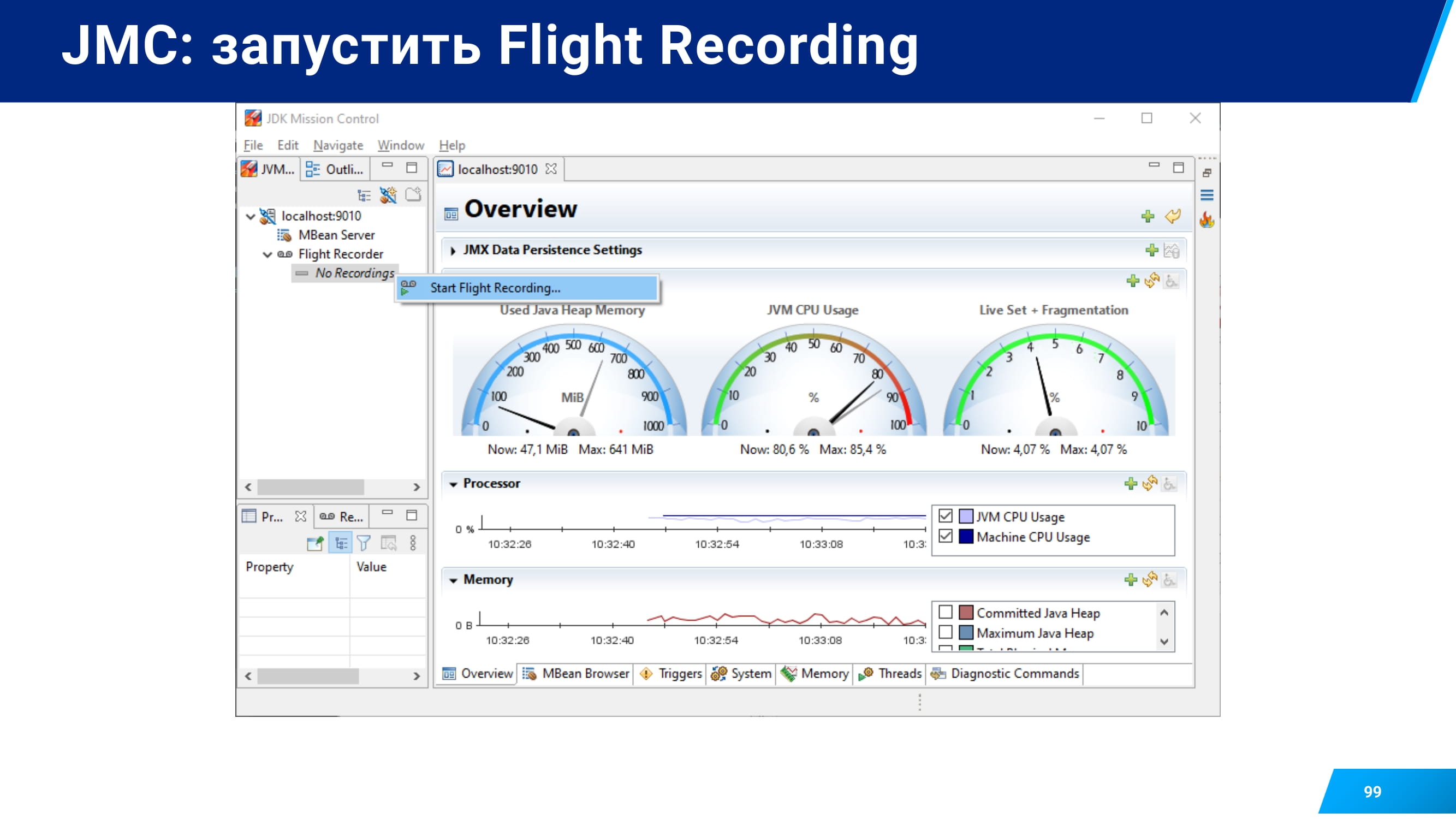
Проверяете, что с вашей подой все хорошо и запускаете с помощью пункта Start Flight Recording процесс профилирования.

С VisualVM все аналогично.
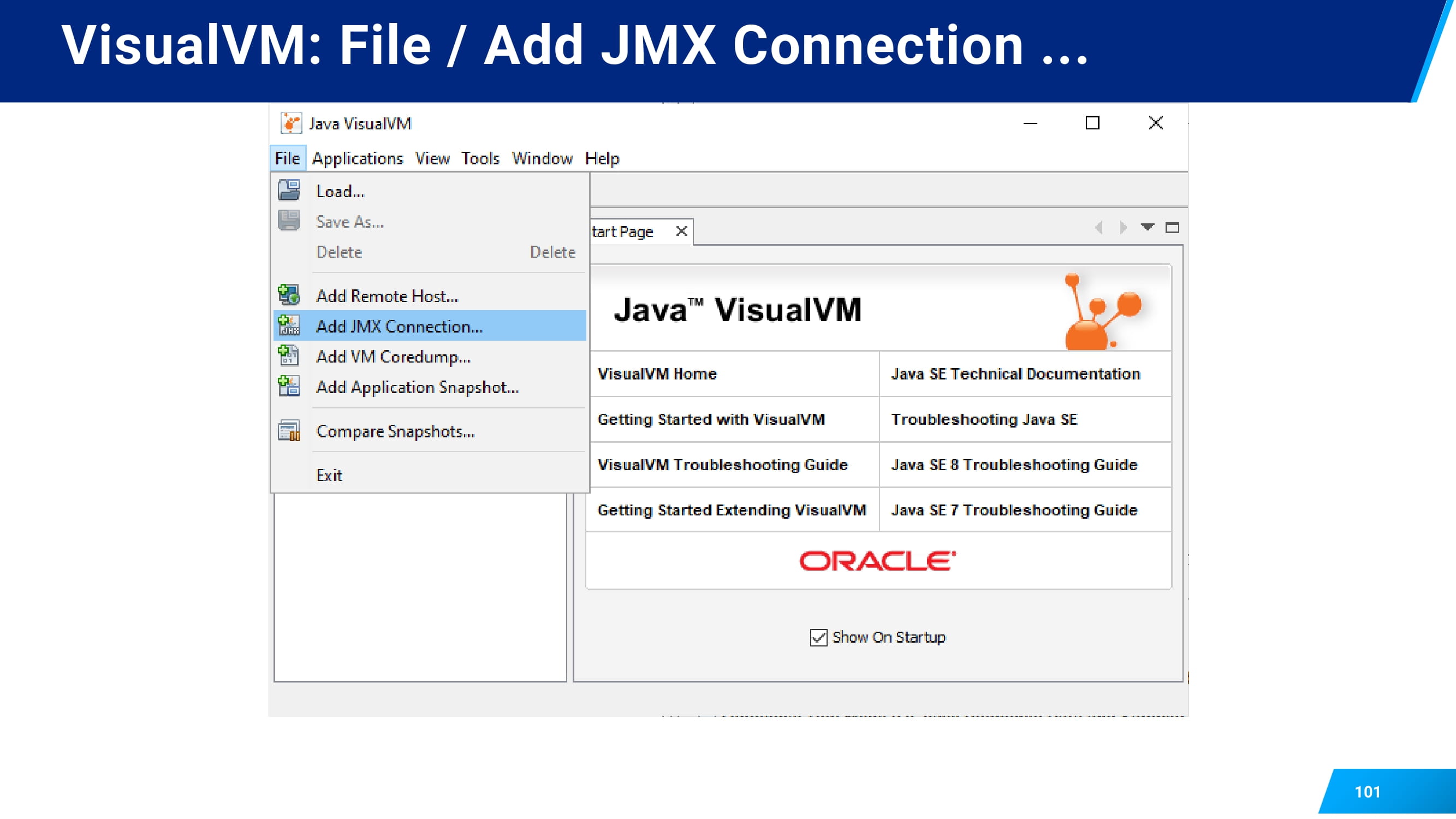
Вы так же создаете подключение.

Так же указываете локальный хост и порт после того, как пробросили все.

Открываете. У вас появляется в разделе Local созданное вами подключение. Locolhost 9010 открываете.

И на вкладке Sampler можно начать профилирование потоков, нажав на кнопку CPU.

Более интересную и, возможно, более детальную информацию можно получить у JavaAgent-профайлеров.

Таких как JProfiler, YourKit Java Profiler.

Но тут несколько иной способ подключения. Вам нужно доставить и сам профайлер внутрь поды. Вот эти агенты нельзя просто опциями подключить. Это не встроенная возможность Java. Это определенный программный код, т. е. программный продукт, который подключается дополнительно к JVM. И мы в команде такие опции кладем в некий каталог, а каталог монтируем в поду. И потом настраиваем все эти опции, создаем сетевое подключение.
Какие тут преимущества?
- Всего один порт, нет JMX, RMI. Всего один сетевой порт для агента.
- Можно уже подключаться к двум подам одного сервиса. И у самих этих инструментов более интересный интерфейс.

Расскажу про интерфейс для профайлера. Он достаточно хороший.

Если вы начнете профилировать с ним, то вам понадобится 2 дистрибутива. Один для вашего клиентского рабочего места, например, у вас Windows.

Второй дистрибутив, который будет работать внутри поды. Как правило, это Linux.

Но вам не все файлы из этого дистрибутива понадобятся, а лишь две подпапки.

В случае Alpine Linux папка называется Linux_musl.

В случае всех остальных – Lunux-x64.

Узнать, какая у вас ОС используется несложно. Откройте командную консоль для вашей поды и введите туда команду «cat /etc/os-release». Увидите там Alpine, значит Alpine, иначе это что-то другое.

При подключении агента нужно в deployment смонтировать этот агент, чтобы он появился на диске, т. е. чтобы он был у вас на сервере. Далее смонтировать это в поду. И подключить уже к Java через Java options. Как правило, можно сделать вот таким образом.

для CentOS получится тоже самое, только каталог из дистрибутива, который будет подключаться в поду, будет другой, т. е. linux-x64.

Особенность тут в том, что если вы подключаете это на несколько сервисов, то настройки можно оставить такие, т. е. сохранить тот же самый порт. Максимум, что будет меняться в зависимости от дистрибутива это musl или x64.
Вы это сделали, сервис перезапустился.
И вы в JProfiler создаете новую сессию. Про это тоже буду рассказывать, потому что не самый тривиальный интерфейс, можете запутаться.

Пробросили себе порт. Вы говорите, что хотите удаленное подключение, но к своему локальному рабочему месту: 127.0.0.1 и указываете порт, который вы пробросили.

Далее в настройках Call Recording выбрать обычное семплирование. Этот способ называется full sampling, потому что он выполняется максимально быстро, но с дополнительной опцией, что нужно сохранять и номера строчек, чтобы потом это можно было проще смапить на код.

А дальше в профайлере открываются все его фишки. Он может перехватывать все SQL-запросы с параметрами. Вы видите всю статистику по каждому SQL-запросу.

А также http-запросы к exceptions, т. е. то, чего нет, например, в VisualVM. Тут оно есть.

Тут вы подтверждаете, что хотите простое семплирование.
Но и после этого семплирование не запустится. В этом сложность интерфейса. Чтобы запустить вам нужно нажать Start recording. И когда вы попытаетесь в первый раз это сделать, увидите, что все эти опции, которые вы выставили, все равно собираться не станут.
Нажмите на пункт, что вы хотите настроить новый профиль сбора метрик.
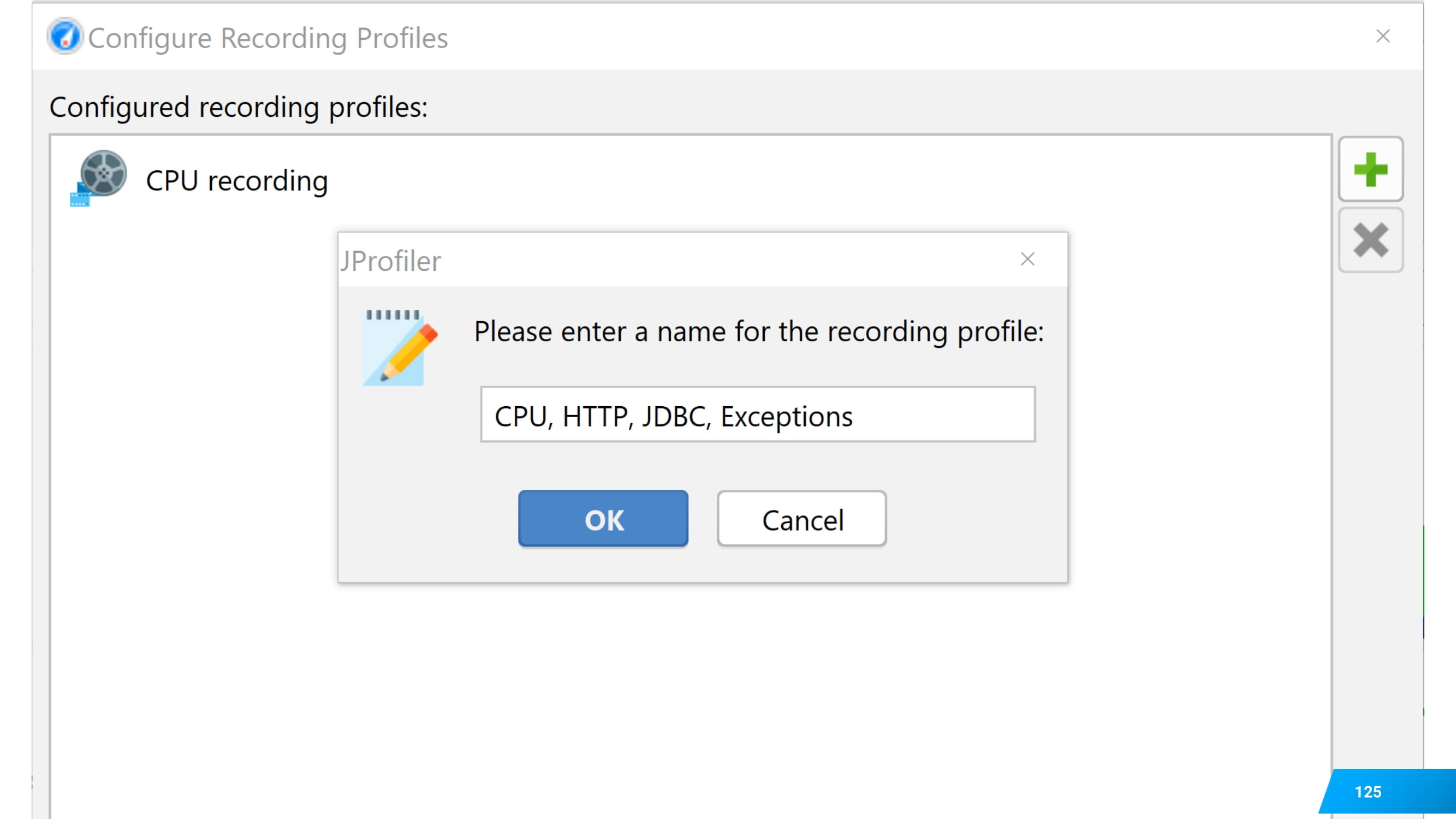
Назовите его как-нибудь по-своему. Например, что я буду собирать CPU, HTTP, JDBC, Exceptions.

Отметьте среди галочек CPU и все, что вы включили при начале сессии.

Это будет уже более тяжелое профилирование. И тогда его запускайте.

Я попробовал так на тестовом стенде и при профилировании в JMeter, и при различных профилированиях миникуба. Мне очень понравился JProfiler.
Но с использованием удаленного, сложного, долгого профилирования есть один недостаток.

Давным-давно мы работали из офиса и не знали таких проблем, как лаганул wi-fi, отвалился VPN.

А теперь у нас счастливая жизнь, а, возможно, кому-то это и не нравится, когда мы работаем из дома и про все эти проблемы знаем.

И в этом случае удаленное профилирование становится не совсем удобным. Когда вы профилируете через 5 firewalls, то, во-первых, трафик лишний гоняется, во-вторых, может это все прекратиться по независящим от вас причинам.

И тут свое применение нашло локальное профилирование. Есть очень много способов его выполнить.

Один из самых простых – это сделать nginx подключение с помощью SJK, но уже изнутри пода.

SJK (Swiss Java Knife) – это профайлер, разработанный Алексеем Рагозиным. Он очень простой, позволяет подключаться и удаленно, и локально. И он очень маленький, поэтому его можно запускать изнутри контейнера. Это большого overhead не создаст.

Кроме того, при запуске из контейнера его опции подключения сильно проще. Можно уже некоторые опции не задавать.

А задать только те, которые необходимы тоже в Java options.

Узнать имя пода, который вы хотите профилировать с помощью get pods. Скопировать маленький jar внутрь контейнера с помощью команды cp. И с помощью команды exec собрать результаты профилирования.

Все эти опции вы можете записать в командный файл. Вот этот предлагаемый командный файл позволяет уже больший перечень команд выполнять за раз. Позволяет сохранить результаты в tmp/result.

И потом с помощью kubectl или других инструментов скачать результаты.
Я делал это следующим образом. Внутри пода захожу в каталог с результатами и упаковываю их в старый архив. Передаю результаты выполнения, т. е. вот этой упаковки, на консоль, на стандартный вывод. Через pipe получаю с консоли уже в своей станции эти результаты. И с помощью того же инструмента tar распаковываю результаты со стандартного вывода в текущий каталог.
После чего данный каталог можно там открыть. В Windows это будет команда explorer. Этот скрипт можно выполнять в Git Bash, т. е. он для Windows тоже будет работать, если у вас есть Git, а Git есть у всех.

Не менее сложный способ подключения с помощью Java Flight Recorder.

Его лучше всех описал в статье на Habr Виктор Вербицкий. Статья называется «Управление Java Flight Recorder». И опции, которые я пробовал, как раз подчерпнул из этой статьи.

Основные – это две опции: это StartFlightRecording и FlightRecorderOptions. В этом случае нет интерактивного подключения с помощью Mission Control.
Вы говорите, что метрики нужно собирать и писать на диск, не хранить в оперативной памяти.
Чтобы дисковая квота не переполнилась, задаете какое-то ограничение, например, 1 гигабайт.
Перечень событий, который нужно собирать, загружаете из файлика, путь к которому указываете в этом параметре.
Говорите в какой каталог сохранять.
И можно еще некоторые опции задать, например, максимальный размер одного файла. Если вы будете запускать с настройками семплирования по умолчанию, то при задании максимального размера файла в 1 мегабайт, фактически будет 2-3 мегабайта. Потому что после сбора метрик, т. е. когда они в сыром виде собрались на мегабайт, из записи этого сбора записываются еще дополнительные события, и файлик становится чуть больше. Если вы собираете помимо стандартных реплик еще метрики по памяти, то при задании maxchunksize=1m размер результирующего файла будет 300 мегабайт.
И еще полезная опция stackdepth. Глубина stack по умолчанию 64. И для spring-boot приложения, где stack очень огромный, вы не увидите, где у вас узкое место. И рекомендую его увеличить.

Все опции семплирования для JFR, которые задаются в filename, мы можем посмотреть, как они выглядят по умолчанию в файле jre\lib\jfr\default.jfc.
Это простой файл в формате XML.
Но его можно редактировать в JMC.

Если вы хотите сделать процесс профилирования, то там будет кнопка Template Manager. Нажмите ее, откроется Flight Recording Template Manager, где вы можете сдублировать существующие профили, отредактировать их, нажав «Edit» или экспортировать в файл. А потом этот файл замонтировать в поду и использовать.

Если вы вообще ничего не замонтируете, то можете использовать настройки по умолчанию.

Если у вас есть какие-то пожелания по выбору метрик, то вам нужно смонтировать также, как и для агента каталог. Это необходимый для вас файлик. И нужно подключить этот файлик в опциях JVM.

Вот так можно называть каталог, в котором будут опции.

Вот так его подмонтировать.

И вот так указать этот путь: filename /tmp/jfr/prof.jfc.
Вот такой способ подключения JFR.

С помощью JavaAgent тоже можно все локально делать самыми разными профайлерами. Я, правда, не пользовался, поэтому и рассказывать вам не буду.

И есть очень интересный способ, как все сделать на лету. Он обещает, что вы можете в любую поду зайти и начать профилирование.
Сложность в том, что у меня этот способ сработал ровно с одним профайлером и не сработал со всеми остальными.
В чем суть? Чтобы все это на лету сработало, вам нужны инструменты разработчика, т. е. не просто Java Runtime Environment, а JDK внутри контейнера. А все стремятся сделать контейнеры легковесным, никаких дополнительных инструментов и утилит в контейнере нет. Я пробовал это сделать, но у меня ничего не получалось. А с Async Profiler получилось.
Его фишка еще в том, что он может не только stack traces собирать, а собирать большее количество метрик более точно.

Поэтому на него я бы хотел обратить особое ваше внимание.

Разработал его Андрей Паньгин. И в Async Profiler я могу отметить наилучшую поддержку Alpine Linux и не только.

Что это за штука Alpine Linux? Почему на нее нужно обращать внимание? Если вы зададитесь вопросом: «Какие Linux-дистрибутивы и с какими опциями используются в ваших контейнерах?», то вы, скорее всего, зайдете на Docker Hub, начнете выбирать контейнеры, которые у вас будут базовыми для ваших сервисов.

И у вас будут некоторые факторы выбора их.

Среди них – это операционная система, т. к. они бывают разными. А также – JDK или JRE, какая там версия. Можете обращать внимание на популярность.

Я зашел и составил табличку для тех контейнеров, которые используются у нас на проекте.
По статистике среди пользователей Docker Hub наиболее популярный дистрибутив – это CentOS. Наиболее популярная версия – Java 8.

На нашем проекте первое место совпадает с этой статистикой. А второе место – это Alpine.
И в разделении CentOS против Alpine есть важный фактор для инженера производительности при выборе профайлера. При выборе профайлера вам нужно будет выбирать Linux-musl различные инструменты, которые содержат слово «musl» в своем названии.

При скачивании Async Profiler нужно выбрать нужную сборку. У него есть сборки и для Macos, и для самых разных Linuxs. У вас будет выбор между x64 и musl.

И как вы заметили, внутри Alpine есть JDK. Это популярный дистрибутив. У нас он тоже встроен.
И я пытался пользоваться утилитами JDK из контейнера, и оказалось, что они не работают. Все-таки Alpine-дистрибутив урезанный. Несмотря на то, что там есть утилиты, ими нельзя воспользоваться.
Я расстроился, что вообще никакого шанса нет, но оказалось, что в Async Profiler есть замечательная утилита jattach.
Она выполняет функции jcmd.

Его особенность в том, что нужны ROOT-права и они не всегда есть. Но если они есть, то все получится.

Вот такая сложная получилась схема, как подключиться и начать профилирование. Надеюсь, она вам когда-нибудь пригодится в жизни, и вы сэкономите свое время.
Рассказывая про удаленное профилирование, я немного затронул тему того, что иногда можно запрофилировать две поды, а иногда одну. Это тоже важный аспект профилирования в Kubernetes.

Но он все-таки зависит не от того способа профилирования, который вы выбрали, а от другого момента.

Если ваш дефект производительности проявляется при единичном запросе, при ручном, то тут один способ масштабирования и подбора инструментов.
Например, вы в браузере тыкаете на ссылку, и ваш сервис зависает.

Чтобы найти узкое место в таком сервисе, вам не нужно 10 реплик, достаточно одной.

И ее можно профилировать максимально детально с инструментацией, с использованием Java-агентов.

А также с помощью таких инструментов, как JProfiler, YourKit для детального сбора метрик по всем аспектам.

А если для профилирования вам надо подать большую нагрузку, а при большой нагрузке, как правило, нужен более большой кластер, например, 5 реплик выдерживают такую нагрузку, то в этом случае рекомендую оставить все 5 реплик, но к ним добавить 6-ую реплику для дополнительного масштабирования. И 6-ую начать нагружать.

Если от данного сервиса зависят другие сервисы, то из всех созданных 6 реплик рекомендую профилировать только одну, чтобы 5 других не замедлялись.

Это у меня на схеме отмечено, как быстрое выборочное профилирование.

Тут выберите такие инструменты, как JDK или Async Profiler. Они создают наименьшую нагрузку на профилирование приложения.
Если у вас задача запрофилировать все поды с небольшим overhead, то можете выбрать те же самые инструменты или сделать массовый запуск JFR.

Решая вопрос, какое количество под, сервисов профилировать, идите по пути наименьшего сопротивления.
Если у вас есть возможность использовать тяжелый профайлер, то используйте его в одной реплике. Если вам нужно много реплик, то используйте более легкие инструменты. Если у вас есть ROOT-права, то используйте Async Profiler. Если у вас нет ROOT-прав, то JDK. Если у вас достаточно новая OpenJDK и там есть поддержка JFR, то попробуйте его.

Надеюсь, я рассказал все про подключение и особенности Kubernetes и роли профилирования в нем. И некоторые части пазла у вас сложились и осталось совсем немного белых пятен.

Сейчас быстро расскажу, как анализировать результаты.

Самая частая у меня задача – это анализировать результаты семплирования.
- Первый шаг – это визуально оценить работу потоков.
- Собрать статистику по работе потоков. Т. е. мы посмотрели визуально, оценили это в виде чисел.
- Выбрать из всех этих потоков только проблемные, исключить непроблемные.
- Детально собрать статистику только по проблемным.
- И разделить на методы прикладные.
- Т. е. тут у нас Postgres тормозил, тут какой-то http-запрос.
- И наложить эту статистику на исходный код.
Вот такой семишаговый процесс.

Первый этап – визуальная оценка. Этот этап очень важен.
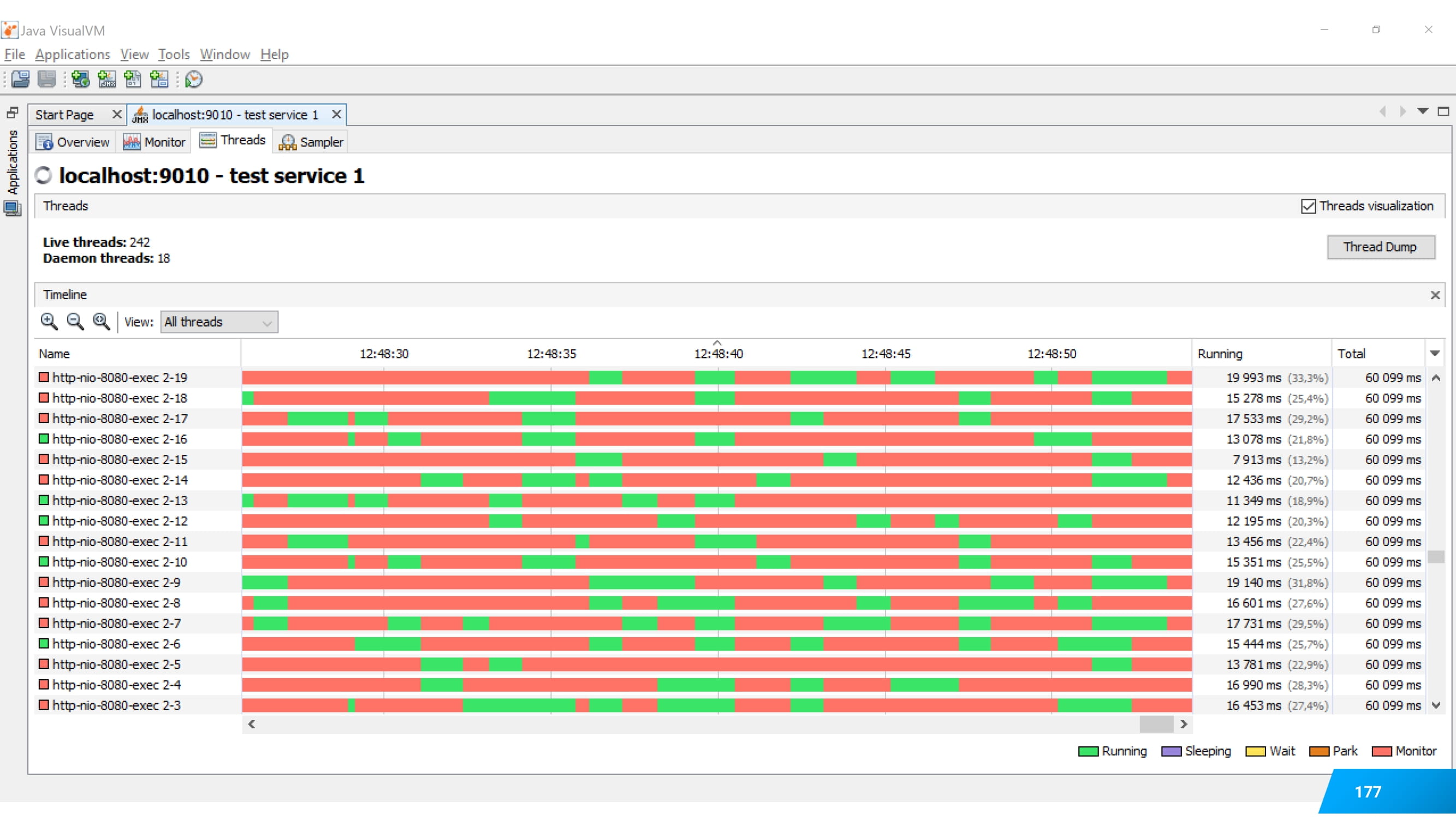
Его можно сделать в бесплатном инструменте JVisionVM.

Если вы посмотрите на свои потоки и увидите, что они параллельно работают, то у вас нет проблем с параллельностью. Вы создали 20 или 120 потоков, и они как-то параллельно живут.

В этом случае вы будете сосредоточены на анализе эффективности, на работе каждого отдельного потока.

А бывает другая картина. Вы смотрите визуально в JVisionVM и видите, что ни один поток параллельно с другим не работает. И даже если кажется, что они накладываются, то это не так.

В этом случае у вас совсем другая проблема.

Система работает медленно не из-за недостатка масштабирования, а по причинам блокировок. И вам нужно анализировать уже этот момент.

Еще замечу, что при выборе потоков важно ориентироваться в них хоть немножко.

Статистику достаточно смотреть по ключевым местам. И совсем не смотреть, например, по JMX и RMI. Это RMI Scheduler, RMI TCP Accept, RMI TCP Connection. Kafka Heartbeat обычно не доставляет проблем. И различные потоки, которые отвечают за сборку мусора, тоже нам не интересны.
Нам достаточно посмотреть, какой вес они занимают в процессе профилирования, т. е. в работе сервиса, но не нужно залезать в детали, потому что мы ничего там не поменяем. Если только вы заметили, что поток сборщика мусора выделяется из всех потоков, то посмотрите на настройки сборки мусора.

А заглянуть внутрь нужно уже при таких потоках: http-nio-8080, Thread-pool, OkHttp, WebSocket.

Как это делается в больших профайлерах?

В том же JProfiler рекомендую зайти в Thread History. Там можно увидеть диаграмму работы потоков. Выбрать самый тяжелый. И перейти по пункту Show Call Three Selected Thread.
Недостаток или особенность JProfiler в том, что для двух потоков эту статистику собрать нельзя, т. е. нельзя объединить.

Но такое можно сделать с помощью других инструментов.

С помощью того же JDK.

Я на слайдах привел пошаговые готовые скрипты, которые вы сможете использовать у себя, чтобы объединить статистику.

И построить в диаграмму.

Диаграмма – это такой красивый график.
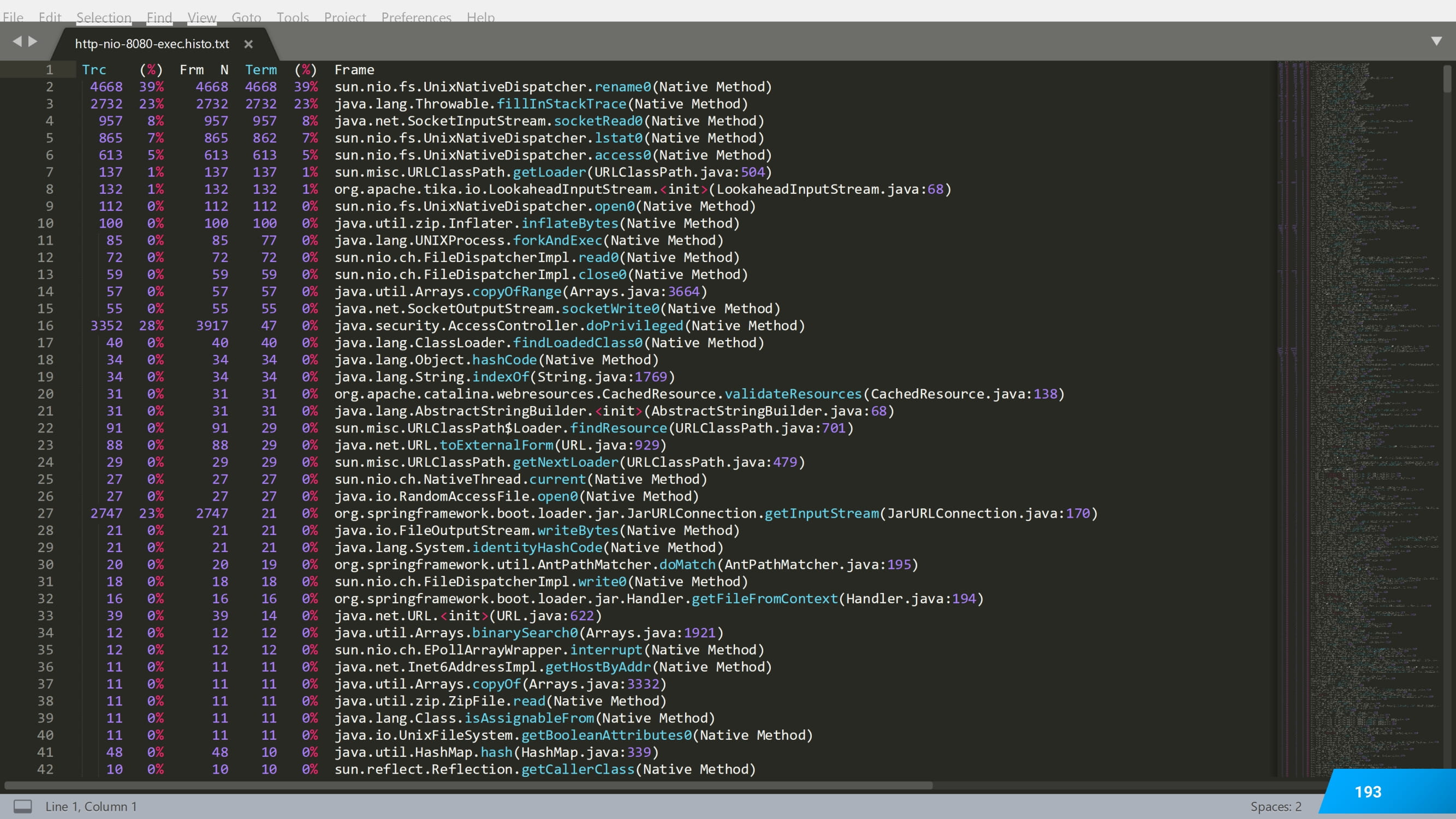
Кроме того, он будет снабжен статистикой уже с номерами строк.

А если вам нужно из всей работы потоков выделить отдельный метод, то это тоже возможно.

Вот вы смотрите на эту большую flame-диаграмму.

Она может показаться на первый взгляд непонятной.

Давайте к ней приглядимся.

Вот мы приглядываемся-приглядываемся и понимаем, что у нас есть post-запросы и get-запросы. Вот в данном случае есть post-запрос, есть get-запрос. И это уже нам позволяет как-то сориентироваться и выделить наши запросы среди всех. Т. е. смапить их на некоторые бизнес-задачи.

Наши запросы, как правило, выделяются по префиксу. Если наша команда называется ВТБ, то вот наши прикладные методы. Вот ru.vtb.dbo и т. д.

Кроме этого, есть имя самого запроса.

Вот оно: organizationsSearch.

Все эти три признака позволяют из stack traces выделить интересующие вас участки.

Фишкой JDK является то, что можно объединить фильтры, т. е. ряд фильтров накладывать на собранные stack traces и таким образом автоматизировать выделение статистики по отдельному методу.

Вот таким несложным скриптом у вас это получится сделать.

И после этого можно даже накладывать на эти отдельные методы еще дополнительные фильтры.

Вот такие. Тут уже trace-filter. И можно сказать, какую долю в этом методе занимает PostgreSQL.

Или, наоборот, без PostgreSQL. За счет таких фильтров вы можете оценить взаимодействие текущего сервиса и текущего метода с другими сервисами и с другими компонентами.
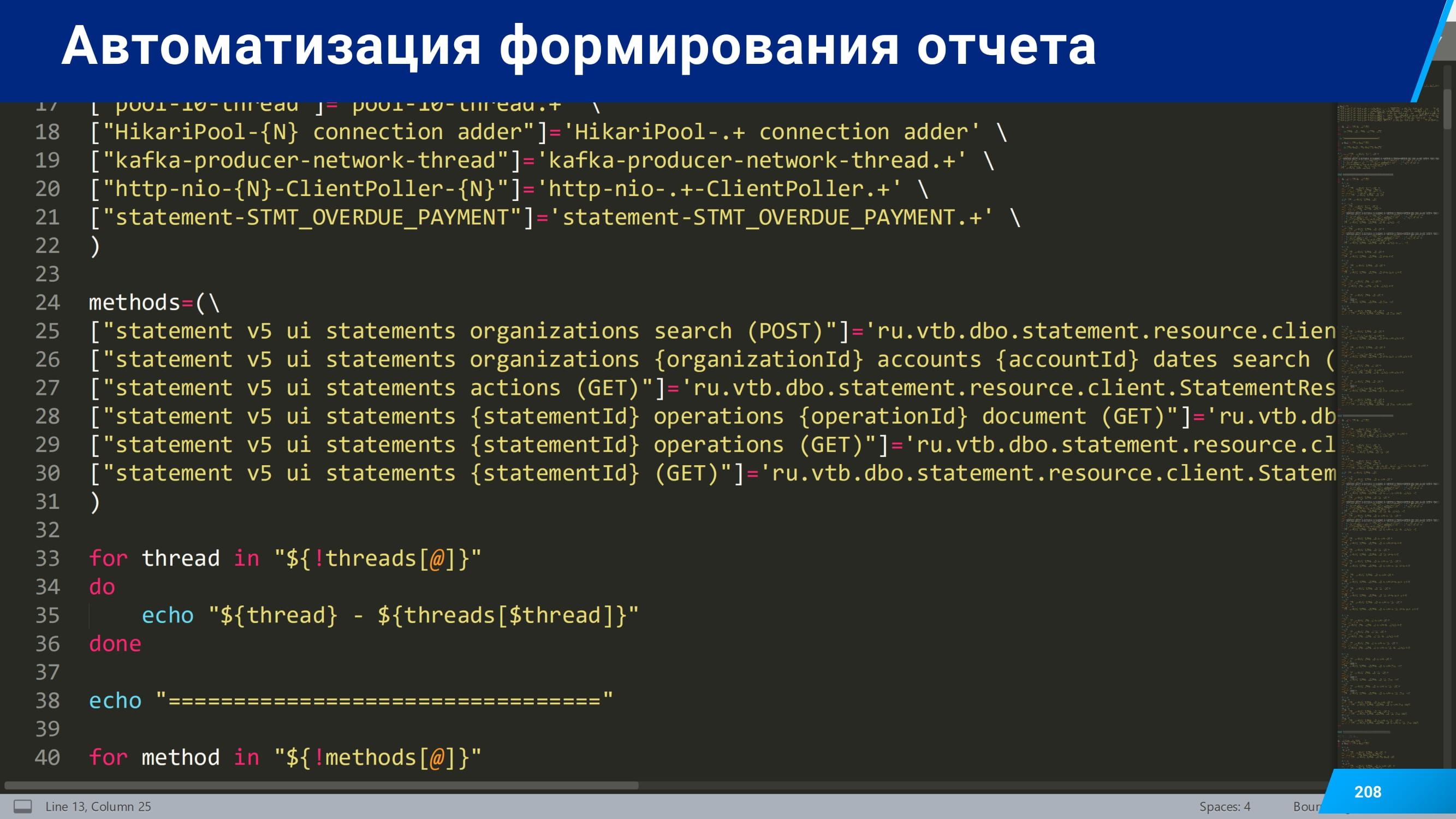
И после всего этого у вас получится автоматическое формирование отчета с разбивкой по методам, потокам, классам и другим интересующим вас моментам.

Это все, что я хотел бы вам рассказать про анализ метрик. Надеюсь, у вас еще меньше белых пятен осталось.

И финальный шаг – это как масштабировать профилирование на всю команду. Об этом расскажу быстро.

Первое, что я вам рекомендую делать, это если вы разобрались в профилировании и успешно нашли какие-то дефекты с помощью профайлера, — напишите самый подробный отчет результатов вашей работы.

Вот я пишу суперподробный отчет по профилированию. В шапке есть отчеты по бизнес-составляющим, которые прочитают все. Это какую версию мы тестировали, какие дефекты нашли и какие узкие места были или не были.
Ниже этой шапки, ниже бизнес-составляющей есть пошаговый процесс, какие окна я посмотрел, какие потоки смотрел, почему я решил, что это узкое место. Эту часть уже не будет читать никто: ни разработчики, ни менеджеры. Но ее прочитают ваши коллеги, которые при следующей итерации регрессионного тестирования, возможно, захотят проверить осталось ли это узкое место. Таким образом ваш подробный отчет – это своеобразная инструкция для ваших коллег. Это обучающий материал.

Кроме обучающего материала нужно написать саму инструкцию.

Первым делом рекомендую написать инструкцию, как выполнить профилирование в ручном режиме. Я вам рассказывал про Alpine и о том, как посмотреть версию, и т. д. Все это нужно задокументировать в том же Confluence.

Инструкцию нужно не просто записать и сохранить в Confluence, а еще и снабдить видео. Я понял, что это важный шаг.

И вот моя суперпростая диаграмма, что же делать, если вы написали инструкцию.
Если вы написали инструкцию и решили замолчать о ней, то это неправильный вариант. Надо рассказать о ней. Если вы решили рассказать об инструкции и в где-то в чате скинули ссылку, то это тоже неправильный вариант. Вам нужно скинуть ссылку и прямо по шагам пройтись по инструкции, записав коротенькое видео минуты на 2. Что вот это я открываю, сюда кликаю, потому что кому-то проще воспринимать такой формат.

И среди тех, кому проще воспринимать такой формат, найдутся те, кто не сможет это сделать с первого раза. И тут я рекомендую вам парное профилирование и анализ результатов профилирования.

Т. е. кроме того, что вы рассказали инструкцию о том, что она существует и, возможно, даже записали видео, приложили скрипты, попробуйте спрофилировать какой-то сервис чужими руками. По Skype подключитесь, пусть он расшарит экран. И он будет выполнять все эти действия с вашей помощью, с вашими подсказками, но сам. В этом случае это сильно отложится в памяти и будет большим подспорьем для человека.

И последний шаг – это записать все в виде скриптом автоматизации, чтобы это выполнялось как-то совсем просто.

Как вы поняли, автоматизировать надо не сильно много вещей.

Нужно примонтировать, загрузить какие-то файлы в поду.

Нужно поменять Java options.

Запустить процесс профилирования удаленно, локально.

И потом скачать результаты.

Как вы понимаете, все это в Kubernetes возможно, например, с помощью Kubectl.

А также с помощью Web-дашборда, который есть. Там, конечно, не совсем тривиальный способ будет по скачиванию результатов, но отдельные шаги можно реализовать.

Или какие-то другие инструменты использовать. Мне понравился Lens.

Когда вы это сделали и заскриптовали, то к скриптам тоже напишите документацию, потому что программный продукт – это не только код, но и документация к нему. После того, как вы написали документацию, можно считать, что вы что-то заскриптовали.
И когда у вас есть скрипты, неплохо бы поместить это в CI/CD окружение, чем я в текущий момент и стараюсь заниматься.

На этом у меня, наверное, все. Надеюсь, совсем минимум белых пятен у вас осталось.

Я вам рассказывал про то, что с переходом на микросервисы задач меньше не стало. Тут появилось много особенностей Kubernetes’а. Вам нужно профилировать больше сервисов.

Топ-3 советов для Kubernetes такие:
- Начали профилирование, добавьте чуть-чуть ресурсов и задайте какие-то границы для этих ресурсов.
- При большой нагрузке лучше использовать семплирование локально, чем инструментацию удаленно.
- И важный момент про Alpline. Я не знал раньше про такую особенность, что musl реализации инструментов как раз для него, а Alpline сейчас популярен.

При выполнении анализа результатов профилирования стремитесь идти от крупного к мелкому, т. е. дробите-дробите.

- Сначала оцените все визуально.
- Соберите статистику.
- И перейдите к деталям. Возможно, отфильтруете что-то по обращению в другие сервисы.
- JProfiler и YourKit могут перехватывать SQL и HTTP-запросы.
- С SJK несложно автоматизировать процесс формирования отчета.
- И с JDK тоже такое можно.

Обмен знаниями – это очень индивидуальный процесс.

- Документируйте все, что делаете.
- Будьте терпеливы, когда объясняете и передаете знания.
- И стремитесь делать так, чтобы при следующей итерации вам не нужно было повторять все снова, чтобы это было как-то автоматизировано.

На этом у меня все. Я вам рассказывал про профилирование. Если у вас есть вопросы, я буду рад ответить на них.
(Владимир Ситников) У нас времени осталось мало, поэтому будут блиц-вопросы. Тебе Kubernetes нравится: да или нет?
(Вячеслав Смирнов) Нравится.
Профилировать Kubernetes нравится?
Не очень.
На монолит вернешься?
Нет, не получится.
Java или Go?
Я пока что знаю только Java.
Alpine или нет?
Наверное, нет, слишком он урезанный.
Немного рекламы: На платформе https://rotoro.cloud/ вы можете найти курсы с практическими занятиями:
