Данный текст не является переводом с английского, хотя кому-то может так показаться. Описываемый в статье продукт был изначально рассчитан на англоязычную аудиторию, хотя разрабатывается в РФ. И так бывает.
Предыстория
Много лет мы (команда Epsilon Web Manufactory) занимались разработкой сайтов и разных приложений на заказ, в основном это были проекты на базе популярного движка WordPress. И как правило самой сложной и интересной задачей всегда был полнотекстовый поиск. Если на сайте были только статьи и какие-то кастомные типы записей, содержащие заголовок и основной текст, то достаточно было использовать встроенный класс WP_Query, который с небольшой подстройкой входных параметров отлично справлялся с задачей. Но это было лет 10-12 назад.
Кто не в курсе - нативно WordPress для полнотекстового поиска до сих пор (в 2022 году) использует конструкцию LIKE "%слово%", которая работает, но крайне неэффективно. Выручает тот факт, что все записи (страницы, посты, меню, и т.д. и т.п.) в WordPress хранятся в одной таблице wp_posts, так что сделать поисковый запрос не так сложно.
По мере того, как WordPress становился более популярным, потребности клиентов также росли. И всё чаще и чаще появлялась необходимость осуществлять поиск не только по заголовкам и тексту статьи, но и по другим немаловажным текстовым данным. Это и мета-данные публикаций, которые хранятся в отдельной таблице, а зачастую их значения ещё и сериализованы, это и таксономии, и другие данные. Обычный WP_Query уже не вывозил эту задачку. Мы начали делать свои собственные запросы в MySQL и всю обвязку к ним (кастомные формы, кастомные страницы результатов поиска). Потом появился плагин ACF, очень удобный инструмент для прикручивания к записям разных данных и пользователи начали создавать не только блоги, но и сложные приложения, прикручивая всё, что можно прикручивать - файлы, галереи фотографий, тонны кастомных текстовых полей и др.
Пользователям удобно, но для полнотекстового поиска эта ситуация аховая. Теперь простой запрос для поиска по всем этим данным сделать стало невозможно. И если раньше мы применяли всякие "LEFT JOIN" для поиска по мета-полям и таксономиям, то теперь сами данные стали настолько сложными, что LIKE и даже REGEXP туда ну никак не прикрутить.
Решение есть - индексированный поиск!

Появилась необходимость в глобальном решении проблемы. Конечно, мы в курсе существования мощных систем поиска вроде Elastic Search, Apache Solr и Sphinx, только вот для WordPress они не всегда применимы. Для них нужен как минимум VPS или аренда облачного сервиса, ну и надо добавить, что из коробки WordPress не умеет с ними работать.
Поэтому мы решили сделать свой собственный плагин, который не требовал бы дополнительных затрат от клиента. Поиск должен работать только с использованием MySQL и PHP - только этим в основе своей располагает WordPress.
Идеально также, если бы плагин не использовал свою точку входа, а заменял стандартный вызов WP_Query, чтобы другие плагины могли бы воспользоваться новым функционалом.
Сперва мы хотели просто собирать все текстовые данные, по которым планируем искать, в отдельной таблице, и дальше делать по ним LIKE или MATCH AGAINST. Но в конце концов остановились на создании полноценного индекса, состоящего из таблиц слов и векторов. Как показали тесты - этот подход даёт намного большую (в десятки раз) скорость поиска на большом объёме данных (более 100к постов), а кроме того, позволяет реализовать много других функций, например, вычислять релевантность, придавать вес различным публикациям и частям публикаций (например, отдельным мета-полям), да и вообще намного более гибкий.
В целом эта концепция хорошо известна как TF-IDF и широко применяется во всех современных системах полнотекстового поиска (включая вышеупомянутые Elastic Search, Apache Solr, Sphinx и др.).
И ведь действительно, вместо того, чтобы искать слово в огромном массиве текста, можно заранее найти все тексты, в которых конкретное слово встречается, сохранить список этих текстов, а затем, когда кто-то ищет это конкретное слово, просто выдать готовый список. Здорово?
Да, и мы пошли по этому пути.
Шаг 1. Индексирование
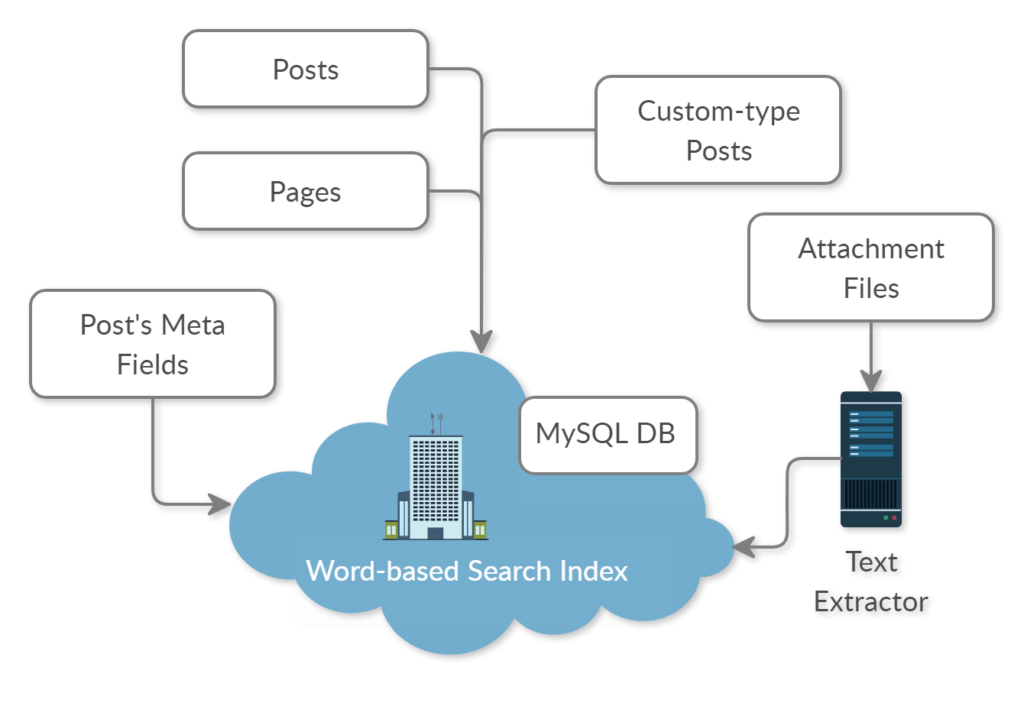
В нашем плагине поиск разбивается на два шага. Первый шаг называется "индексирование". Мы последовательно проходим по всем записям WordPress из таблицы wp_posts, вытаскиваем все тексты, которые прилинкованы к записи (сюда относятся мета-данные, таксономии, тэги и проч.), и полученные данные сохраняем в формате слово-вектор в индексных таблицах. Здесь нужно отметить, что плагин покрыт хуками, и на индексирование также имеется хук wpfts_index_post, внутри которого программист может помочь плагину подтянуть нужные текстовые данные, связанные с конкретным постом.
Плагин также следит за всеми изменениями, и если какая-то запись в wp_posts изменяется, то производится инкрементное обновление индекса.
Индексирование происходит в фоновом режиме. Владельцу сайта не приходится что-либо проверять или нажимать время от времени какие-то кнопки. Данные для поиска появляются в индексе спустя 1-2 секунды после обновления данных в публикации.
Ещё раз напомню, что весь поисковый индекс хранится в той же базе данных, что и весь остальной сайт на WordPress. При этом никакие существующие таблицы WordPress не модифицируются.
Шаг 2. Собственно, поиск.

Когда пользователь выполняет стандартный поиск в WordPress, то система вызывает экземпляр класса WP_Query с параметром "s = поисковая фраза".
Поскольку метод WP_Query хорошо оснащён хуками, мы контролируем его поведение в той части, где он пытается создать список частей основного запроса для MySQL и делаем так, чтобы вместо стандартного LIKE использовался подзапрос по нашим индексным таблицам. Я не буду тут расписывать подробную логику, поскольку это - самая сложная часть. Напишу лишь, что после того, как от MySQL получен список векторов (то есть пар вида "слово-документ") мы производим дополнительную обработку с помощью кода PHP, чтобы посчитать релевантность. Далее список ID постов вместе со значением релевантности возвращается из WP_Query и вызывающий код (будь то сам WordPress или какой-то плагин) даже не подозревает, что произошло что-то хорошее.
Немного о вычислении релевантности
Релевантность - очень важный показатель. Именно она определяет, какой из постов будет показан пользователю в топе списка. Именно это определяет качество поиска.
К слову сказать, нативный поиск WordPress определяет релевантность очень просто - каждое найденное слово из фразы добавляет +1 к релевантности. Если во фразе 3 слова, а в тексте поста встретилось только одно из них, то релевантность будет 0,33. Постов с одинаковой релевантностью может быть множество. Поэтому по умолчанию WordPress сортирует результаты поиска просто по дате последнего изменения записи. Как вам такое?
В нашем же плагине реальная релевантность вычисляется на основе множества показателей.
Во-первых, для каждого слова в искомой фразе учитывается степень его совпадения с найденным словом. Так, если мы ищем слово "слон", то у слова "слоновый" будет меньший вес, чем у слова "слоник", а максимальный вес будет у слова "слон".
Учитывается количество повторений слова в одном документе (эта часть известна как "TF") и количество повторений слова во всех документах ("IDF"). Чем больше документов содержит это слово, тем менее значимым в целом оно считается. Таким образом, например, слово "как" в поисковой фразе "устал как конь" будет добавлять наименьший вес к релевантности, поскольку "как" встречается почти во всех документах.
Также учитывается вес слова во фразе. Например, если мы ищем фразу "крепкий кофе", то будут найдены все документы, содержащие оба слова, но релевантность тех документов, где эти слова стоят близко друг от друга будет намного выше. То есть документ с фразой "крепкий чёрный кофе" будет выше, чем "крепкий ароматный чёрный кофе".
На вес документа в выдаче также влияет то, в каком месте документа найдена фраза. В процессе индексирования каждая часть документа попадает в отдельный кластер (например, заголовки попадают в кластер "post_title", основной текст в "post_content" - идентификатор кластера можно выбрать). У каждого кластера есть свой вес от 0 до 1. И этот вес потом учитывается в формуле для релевантности.
Вывод результатов поиска

Стандартный вывод результатов поиска в WordPress тоже никуда не годится. Они просто берут начало основного текста статьи, обрезают 115 символов и выводят это как цитату. Разумеется, нет никакой гарантии, что искомая фраза попадёт в этот кусок и контекст, в котором эта фраза встречается.
Поэтому мы решили переделать и эту часть. Для основы взяли вывод результатов поиска в Google Search, который выбирает из текста отдельные предложения, в которые входит поисковая фраза, подрезает их немного (если они слишком длинные) и составляет их них поисковую цитату. Мы назвали это "Smart Excerpts".
На наш взгляд, получилось неплохо. Клиенты тоже довольны. Кроме всего прочего, в качестве основы для построения цитаты используется весь текстовый массив, который попадает в индекс, а не только основной текст статьи.
Что ещё реализовано
Кроме того, что описано выше, плагин уже поддерживает
Технологию WordPress Multisite.
Возможность использовать OR и AND логику.
Выбор способа сортировки результатов (по релевантности, дате, ID, количеству комментариев и т.д.).
"Живой поиск" Live Search с помощью виджета поиска, которым надо заменить стандартный.
Поиск внутри шоткодов (shortcode) и Gutenberg-блоков.
Поиск медиа-файлов и файлов, прилинкованных к публикациям, по текстовому содержимому файлов (поддерживаются PDF, DOC, DOCX, XLS, XLSX, RTF и многие другие форматы) - для извлечения текста мы используем свой собственный микро-сервис.
Что планируется добавить в ближайшем будущем
Подробную и исчерпывающую документацию по всем хукам и принципу работы.
Поддержку логических выражений в запросе ("чёрный кофе" OR "чай с молоком" OR ("кефир" AND "огурец")).
Возможность добавлять таблицы синонимов.
Возможность добавлять таблицы стоп-слов.
Автоматическую стемизацию запроса (когда вместе с запрошенным словом "слоник" будет искаться и "слон" и "слоновый").
Поиск изображений по EXIF и тексту, найденному на них (ага, OCR).
Конструктор запросов и фильтров (что позволит добавлять несколько разных видов поиска на один сайт).
Конструктор индекса (чтобы не добавлять правила индексирования через код, а легко делать это через админку).
...планов громадьё!
Ресурсы
Плагин совершенно бесплатен, он регулярно обновляется в репозитории WordPress
Также есть его платная версия (в которую включена поддержка поиска файлов по содержимому и персональная техническая поддержка), которую можно приобрести на официальном сайте WP FullText Search Pro.
Вы можете купить Pro версию просто для того, чтобы поддержать разработку плагина, поскольку на его разработку уходит масса времени и лишняя денежка точно не помешает.
Ваши комментарии и рекомендации помогут нам сделать продукт ещё лучше. Спасибо, что дочитали до конца.
