Некоммерческая организация LAION и энтузиасты по всему миру занимаются разработкой Open Assistant — это проект, цель которого в предоставлении всем желающим доступа к продвинутой большой языковой модели, основанной на принципах чат-бота, с конечной целью революции в инновациях в области обработки естественного языка.
Open Assistant ставит перед собой цель не просто повторить ChatGPT, но создать Ассистента будущего. Он будет понимать и решать поставленные задачи, использовать API, динамически исследовать информацию и многое другое.
Мы хотим создать Ассистента, которого каждый сможет настроить и расширить под свои нужды открытым и доступным способом. Одна из ключевых целей — сделать модель одновременно наиболее эффективной и небольшой, чтобы она могла работать на потребительском оборудовании.
Мы находимся в процессе разработки, опираясь на результаты уже проведённых исследований по применению RLHF к большим языковым моделям. В основном — InstructGPT.
В этой статье поговорим о проекте Open Assistant — и как вы можете внести свой вклад.

А кто это?
LAION занимаются развитием открытых инструментов, моделей и датасетов. Более того, раннее они участвовали в крупных проектах, существенно повлиявших на индустрию — датасет LAION-5B лёг в основу моделей Stable Diffusion.
Однако внести вклад может каждый — даже если вы не имеете никакого отношения к разработке или к машинному обучению: участвуйте в сборе данных для RLHF, общаясь от лица человека или Ассистента, модерируйте контент, переводите, рассказывайте друзьям и публике!
Но... Ведь есть аналоги!
Да, есть, вот их список:
ChatGPT, GPT-4, Bing Search от OpenAI & Mircosoft
закрытый исходный код; закрытый датасет; проприетарная лицензия
Bard от Google
закрытый исходный код; закрытый датасет; проприетарная лицензия
YaLM от Yandex
открытый исходный код; закрытый датасет; Apache 2.0
LLaMa от Meta*
открытый исходный код; открытый датасет; GPLv3.0
Alpaca от Stanford
открытый исходный код; открытый датасет; MIT
BLOOMZ от BigScience
открытый исходный код; открытый датасет; RAIL 1.0
Dolly от Databricks Labs
открытый исходный код; открытый датасет; Apache 2.0
Однако давайте подробнее разберём достоинства и недостатки каждой из этих моделей и причину, по которой всё же нужно нечто новое:
ChatGPT, GPT-4, Bing Search:
Первые в своём роде на подобном уровне, на текущий момент самые продвинутые. Но если в названии вашей компании или продукта содержится "Open", то вы обычно стремитесь соответствовать названию — открываете исходники и делаете политику вашей компании прозрачной. Однако OpenAI так не думает. Исходный код ChatGPT (GPT-3.5, GPT-4) закрыт, как и данные, использованные при обучении (верно и для DALL-E 2, Copilot и т. д.). Продукты OpenAI недоступны во многих местах — граждане не из этих стран не могут их использовать официально. Стоит ещё отметить непостоянную доступность и сбои веб-интерфейса ChatGPT. В OpenAI верят, что лишь они могут справиться с такой огромной ответственностью, но допускают утчеки части диалогов и платёжных данных. Есть вероятность закрытия ChatGPT в текущем виде для бесплатного использования — де-факто в любой момент OpenAI оставляют за собой право закрыть доступ к системе или перейти на платную основу (ну… Они отчасти так и сделали с GPT-4, фактически перенеся конечный продукт из категории free во freemium). Сотрудничество с Microsoft внесло свои коррективы. Смысл Open Assistant как раз в создании свободной и открытой альтернативы, чего корпорация нам не даёт, несмотря на своё название.

As a large language model... Bard
Сложно сделать анализ, проект на ранних стадиях развития. Можно лишь предположить, что, может быть, датасет у Google будет более широким и объемлющим. На текущий момент, судя по отзывам пользователей, получивших ранний доступ, и моим экспериментам, Бард не отличается умом и сообразительностью. А ещё всё, что описано выше для ChatGPT в плане закрытости, верно и для сего творения.

И пользоваться в РФ нельзя. 
Хочу сказать спасибо straafe#7840 за предоставленный доступ. Нас сразу предупреждают, что генерация кода на данный момент не является доступной. 
Стоило изменить последнюю букву в названии модели на 't'. 
Ты точно уверен? ![Ну и куда без Theory of Mind! [1/2]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/a14/3a9/73b/a143a973b755fefad88d666e0a6073d5.png "Ну и куда без Theory of Mind! [1/2]")
Ну и куда без Theory of Mind! [1/2] ![[2/2]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/35c/641/392/35c6413925b8239f25ef6c57e7802313.png "[2/2]")
[2/2] LLaMa
Неплохая языковая модель с качественной оптимизацией, но лицензия ограничивает конечного потребителя, подразумевая, что большинство бизнесов просто не смогут воспользоваться (по крайней мере легально) моделью без открытия исходного кода конечного продукта. Ну и качество, к сожалению, пока не на том же уровне, что и продукты OpenAI.
Веса, кстати, официально так и не выпустили. Они доступны только по запросу для "исследователей".
Но не будьте слишком оптимистично настроены, ведь следующий пример вовсю покажет, что с виду открытые продукты таких корпораций не стоят ничего, пока остаётся сама суть этой корпорации.

Не верьте ей. Она злая. Alpaca
Можно назвать Alpaca форком LLaMa. Интересный подход к обучению на основе SFT с применением text-davinci-003 (модель OpenAI).

Шутливая альпака. Но и тут есть поводы для грусти: технически, датасет легально использовать проблематично, так как TOS у OpenAI запрещает подобное использование пунктом 2.C.iii.
Вероятно, их всё ещё не засудили только в силу того, что проект некоммерческий, ну и судебный процесс ещё сильнее испортил бы уже достаточно тёмную репутацию компании. А ещё лицензия MIT не имеет силы, ведь GPLv3 оригинала ограничивает распространение форкнутой модели под иными лицензиями. Ну и история с весами LLaMa, а ещё их «копирайтом»...

Альпаки. Стоит отметить, что эту статью я начинал писать задолго до того, как выпускать, а именно этот кусок был написан ещё 20.03.23. Дело в том, что история получила неожиданное продолжение:
Также с официальных ресурсов были удалены финальные модели Alpaca. Стали недоступные сайты https://crfm.stanford.edu/alpaca/, https://alpaca-ai.ngrok.io/. 
DMCA, такой DMCA. Свобода и открытость, такие свобода и открытость. https://github.com/github/dmca/blob/master/2023/03/2023-03-21-meta.md YaLM
На данный момент одна из крупнейших GPT-подобных языковых моделей в открытом доступе, действительно открытая и свободная лицензия (а ещё в связи с относительно недавним сливом исходников компании, можно назвать Yandex одним из крупнейших Open Source разработчиков).

Оно живое! Вот только, увы, возможность запустить YaLM на потребительском железе отсутствует: мало у кого есть видеокарты на 200GB VRAM, а более ёмкие модели Yandex на момент написания статьи не выпускали.
Технически, можно попробовать оптимизировать процесс долгим и упорным трудом, один энтузиаст даже выпускал об этом статью, но зачем оно вам? Даже с оптимизацией в виде квантизации и иных методов навряд ли удастся запустить её на вашем компьютере. Да и не в параметрах счастье! Параметры — не главное!

Вы бы знали, ах, как сильно мне хотелось вставить сюда эту картинку! BLOOMZ
Интересное решение, особенно если учесть то, как впоследствии реализовали Petals. Но и тут (как жаль) прячутся подвохи: основной претензией является лицензия RAIL 1.0. В этом видео были подняты темы её несовершенства: неуниверсальность, спорные ограничения, странные и неудобные условия.

Интересная биография у BLOOMZ... Dolly от Databricks Labs
Совсем недавно выпустили модель. Но сохраняется та же проблема, что и у Alpaca, — легальность. Был использован тот же датасет, а значит могут возникнуть проблемы с OpenAI.

Чудеса творит файн-тьюнинг животворящий...





![Ну и куда без Theory of Mind! [1/2]](https://habrastorage.org/getpro/habr/upload_files/a14/3a9/73b/a143a973b755fefad88d666e0a6073d5.png "Ну и куда без Theory of Mind! [1/2]")
![[2/2]](https://habrastorage.org/getpro/habr/upload_files/35c/641/392/35c6413925b8239f25ef6c57e7802313.png "[2/2]")









Также стоит отметить, что не все вышеперечисленные проекты удачны с точки зрения качества. Результаты многих из них удручают, особенно условно открытых.
А что под капотом? Готово ли хоть что-то?
За всё время мы уже собрали невероятное количество данных: 124500 сообщений и 11500 деревьев диалогов (из ready_for_export и growing trees; всего — 60000, но на большую часть изначальных запросов пока что не ответили. Но даже с этим получается больше, чем у InstructGPT).

После отчистки датасета от спама, персональной информации и CSAM (Child Sexual Abuse Material) мы публично его выпустим для свободного использования 15 апреля. В этот же день будет выпущена первая готовая версия.
Мы уже в процессе тренировки моделей, были опубликованы ранние прототипы (которые необязательно лягут в основу готовой модели, на них не применялось RLHF), можете ознакомиться с одним из них здесь — это первая пробная попытка создания модели на английском языке с применением метода SFT (supervised-fine-tuning) в рамках проекта Open Assistant. Она основана на Pythia 12B и дообучена на ~22 тысячах примерах, собранных через https://open-assistant.io/ до 7 марта 2023 года.
Конечный вариант будет тоже использовать SFT, RM, RL.
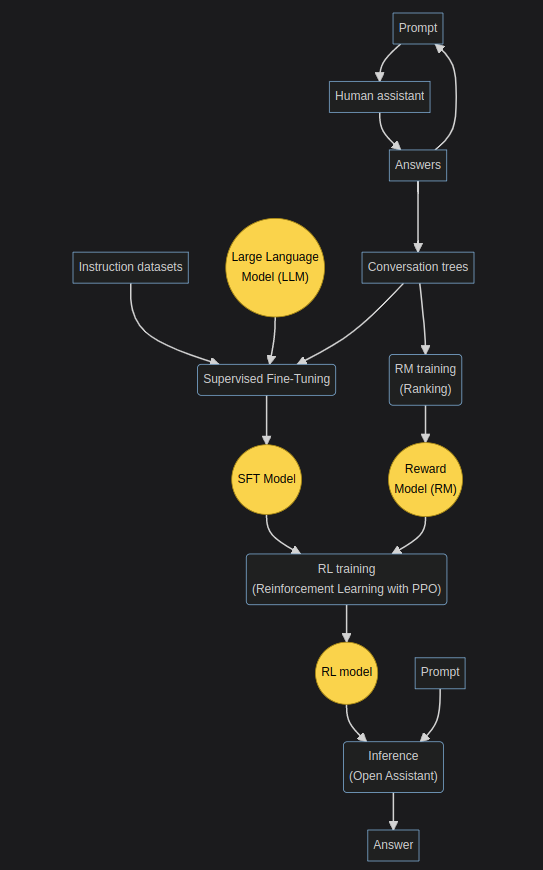

Ещё есть Safety Bot, который будет использоваться поверх Open Assistant. Впрочем, никто ведь не помешает вам его отключить у себя, да? ;)

Идёт бурная работа над inference. В конце концов этот проект может использоваться в дальнейшем для похожих задач по задачам, основанным на HF (Human Feedback) или подобным методам, ведь весь исходный код открыт прямо сейчас.
Начинается планирование функций для следующих версий: например, внедрение LangChain (плагины, инструменты и динамическое извлечение данных из источников, включая поисковые системы)
Итог!
Как видите, на самом деле ещё нет ни одной по-настоящему свободной языковой модели. И наш проект стремится это исправить.
Никто не должен обладать монополией и централизацией на подобные вещи. Это должны быть свободные и открытые технологии.
Я в деле! А теперь... Что?
Если вы являетесь веб-разработчиком, ML-engineer, специалистом по Data Science, нашли какой-то баг или можете помочь в чём-то ещё, то стоит ознакомиться с этим и этим.
Но самое важное, что вы можете сделать, — помочь нам в сборе данных. Присоединяйтесь. Каждый ответ важен. Возможно, именно этот проект повлияет на будущее языковых моделей. По крайней мере в сегменте Open Source.
Ну и пару примеров с предварительной версии, для русского языка использовался автоматический перевод:



* Meta признана экстремистской организацией, её деятельность на территории РФ запрещена.
