
Всем привет!
Иногда кажется, что для решения проблемы недостаточно простого выполнения расчётов в Spark и хочется более эффективно использовать доступные ресурсы. Меня зовут Илья Панов, я инженер данных в продукте CVM5 (Customer Value Management торговой сети Пятёрочка) группы X5, и хочу поделиться некоторыми подходами параллельных вычислений в Apache Spark.
Содержание
Параллельное выполнение методов
Настройка равномерного выделения ресурсов
Join множества признаков
Постановка задачи продиктована потребностью разрабатываемого продукта, а именно - необходимо создать витрину со множеством признаков и поддерживать регулярное её перестроение. Признаки (или группы признаков) для витрины можно получить с помощью отдельных методов, которые в целом независимы и не пересекаются между собой. Результат каждого метода представляет собой датафрейм, в котором есть идентификатор гостя (так в торговых сетях называют всех посетителей) и список значений. После выполнения методов все данные следует собрать в общую таблицу и зарелизить витрину.
Если формализовать цели, то их две:
Вычисление независимых методов.
Объединение отдельных признаков в общую витрину.
Способы решения, которые приходят в голову, такие:
Провести вычисления последовательно.
Провести вычисления параллельно. Существует две опции:
1. Считать в параллельных Spark приложениях.
2. Считать параллельно в одном приложении.
Очевидно, что делая всё последовательно, получим успех. Но что по времени? Кажется, что параллельные подходы могут оказаться более эффективными. В параллельных подходах есть два варианта. Можно разделить методы на отдельные группы и запустить расчёт групп в параллельных приложениях. Такой подход имеет два существенных недостатка. Во-первых, отдельное приложение требует дополнительного оверхеда ресурсов на запуск. А во-вторых, приложения запускаются в некотором оркестраторе, например, Airflow, и каждое приложение требует отдельный слот выполнения, что может привести к долгому блокированию оркестратора и, как следствие, очереди из других пайплайнов.
Параллельные расчёты в рамках одного приложения лишены указанных недостатков, и в настоящей статье будет рассмотрен именно такой подход.
Параллельное выполнение методов
Отмечу, что в статье все примеры для PySpark, но и для Scala (Java) интерфейса это будет актуально. Также стоит отметить, что в статье описан опыт использования Spark-2.4, живущем в "железном" кластере Hadoop, однако, полагаю, рассуждения и подходы будут справедливы и для cloud native решения.
Для иллюстрации рассмотрим следующий код. Предположим, у нас есть исходные данные в виде датафрейма с ключом v и квадратом этого ключа v2:
from pyspark.sql import DataFrame, functions as F
def get_df() -> DataFrame:
data = range(10)
data = map(lambda v: (v, v*v), data)
df = spark.createDataFrame(data, ["v", "v2"])
return df
df = get_df().cache()
df.show()
+---+---+
| v| v2|
+---+---+
| 0| 0|
| 1| 1|
| 2| 4|
...
| 9| 81|
+---+---+Далее в процессе работы команды аналитиков появляется метод method, умеющий из квадрата значения получать четвёртую степень:
# Некоторый полезный код, который совершает сложный расчёт
@F.udf(returnType="integer")
def pow_udf(v):
return v*v
# Метод, который совершает расчёт признака
def method(df: DataFrame):
result = df.withColumn("v4", pow_udf("v2"))
result.count()Допустим, четвёртую степень можно посчитать исключительно задействовав user defined functions (конечно, нет). И ещё одно замечание - нам нужно из кода метода материализовать данные. В реальном пайплайне это происходит через сохранение предрасчёта в stage-area (например, parquete в HDFS), но для иллюстрации сгодится запуск вычислений через вызов .count().
Итак, вызовем наш метод последовательно три раза:
for _ in range(3):
method(df)В итоге в веб-интерфейсе Spark в timeline увидим, что расчёты производились последовательно:

Добавим параллельности - вызовем метод из параллельных потоков:
from concurrent import futures
executor = futures.ThreadPoolExecutor(max_workers=5)
for _ in range(3):
future = executor.submit(method, (df))И в результате на timeline видим, что расчёты действительно выполнялись параллельно:
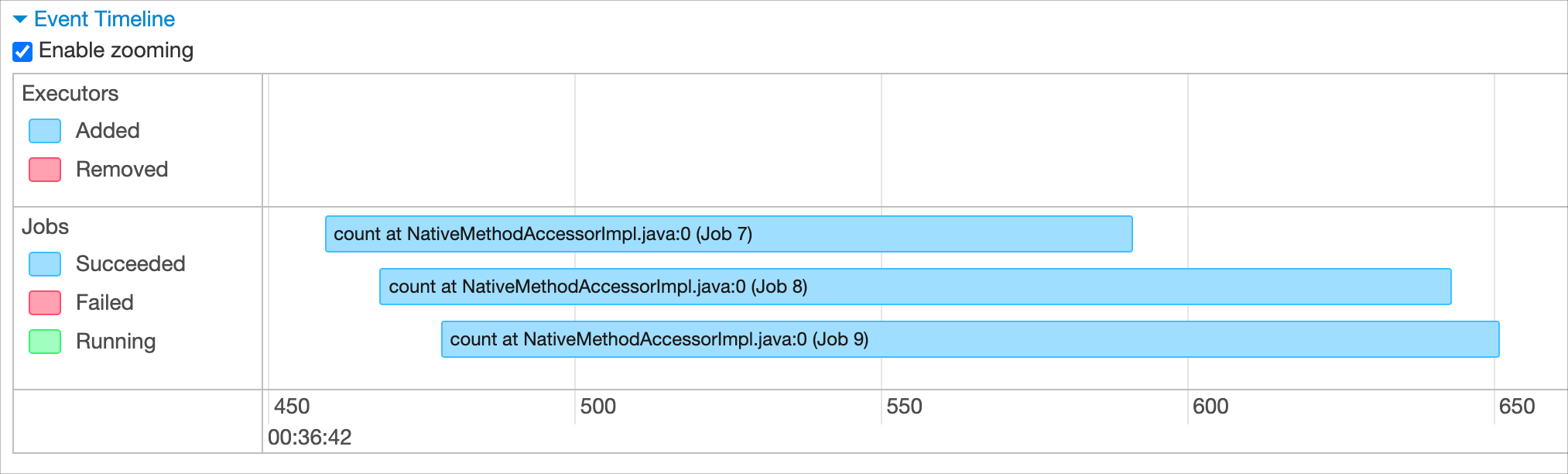
Таким образом, в рамках одного Spark-приложения можно одновременно выполнять сразу несколько методов. Это возможно благодаря тому, что из параллельных потоков можно обращаться как к отдельному датафрейму, так и к SparkSession.
Однако, если подобный подход применить к реальным методам с тяжёлыми вычислениями над большими массивами данных, нас ждёт неприятный сюрприз. Вот как выглядит типичная картина для параллельно выполняемых методов:

Некоторые задачи получают много ресурсов, а некоторые просто стоят и ждут своей очереди. Это сводит всю параллельность обратно к последовательному выполнению: задачи выполняются "почти" последовательно, согласно выделяемым им ресурсам.
Проблема заключается в том, что Spark для выделения ресурсов (ядер) использует свой внутренний планировщик по-умолчание. А именно FIFO Scheduler - планировщик по типу очереди - первая большая задача забирает множество ядер, а остальным достаются остатки.
Чтобы исправить эту проблему и уравнять распределение ядер по задачам, необходимо перенастроить планировщик.
Настройка равномерного выделения ресурсов
В недрах Spark существует cправедливый (fair) планировщик, более пригодный для параллельного выполнения методов. Для его включения необходимо при запуске Spark передать небольшой конфиг fair-scheduler.xml, описывающий ресурсный пул:
<?xml version="1.0"?>
<allocations>
<pool name="fair-pool">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>1</minShare>
</pool>
</allocations>Здесь указаны следующие параметры:
weight - задаёт вес конфигурируемого нами пула относительно других. Вес позволяет задать пропорции, согласно которым пулы "расходуют" ресурсы для задач, которые в них запускаются. По-умолчанию, это 1. Так и оставим, чтобы наш пул мог "забирать" ресурсы наравне с другими;
minShare - задаёт минимальное количество ядер, выделяемых для задачи. Пусть будет хотя бы 1 ядро на задачу;
schedulingMode - задаёт тот самый параметр, благодаря которому ресурсы в рамках пула должны делиться равномерно между задачами.
Подробнее про конфигурацию ресурсных пулов можно почитать в первоисточнике - документации к Spark.
Кроме конфигурации своего справедливого пула, нужно перевести и сам Spark в FAIR режим. Всё вместе это выглядит примерно так:
pyspark \
--conf spark.scheduler.mode=FAIR \
--conf spark.scheduler.allocation.file=./fair-scheduler.xmlЧто же касается кода приложения, то изменения минимальны - нужно в потоке-воркере добавить инициализацию параметра spark.scheduler.pool и задать наш пул:
def method_fair(df: DataFrame):
spark.sparkContext.setLocalProperty("spark.scheduler.pool", "fair-pool")
df.withColumn("v4", pow_udf("v2")).count()Теперь выполняемые методы будут получать ресурсы из нашего fair-пула, что приводит к максимально равномерному распределению ядер между нашими задачами:

Зачем всё это?
Возможно, существует некоторая теория, которая позволяет построить метрику для сравнения производительности системы, выполняющей последовательные или параллельные вычисления с одинаковыми ограничениями по доступным ресурсам. Но мне такая теория неизвестна (либо я не догадываюсь про неё), поэтому приходится руководствоваться экспериментами и капелькой здравомыслия для попытки описать результаты. Если кто-то знает, как это можно формализовать, прошу в комментариях поделиться.
Стоит отметить, что проведение экспериментов в высококонкурентной среде, коим является Hadoop-кластер, - это то ещё удовольствие. Каждый тестовый запуск не похож на предыдущий, т.к. постоянно кто-то ещё что-то считает. И мой i-ый тестовый запуск может получить ресурсов меньше/больше, чем i-1. Также скорость получения ресурсов неодинаковая: можно со старта получить 100 ядер, а можно эти 100 ядер добирать на протяжении долгого времени.
Таким образом для объективного сравнения двух подходов проводилось множество экспериментов на протяжении достаточно долгого времени (более недели). А также сами запуски проводились в различное время: и утром, и ночью, и в самые часы-пик.
В итоге подход с параллельным выполнением методов всегда превосходил последовательный. В самом худшем раскладе параллельное выполнение на 40% быстрее. В самом лучшем - когда сошлись все звёзды - получалось 3х-кратное превосходство. Если взять средние показатели для целевого времени расчёта признаков (раннее утро), то параллельный подход выигрывает примерно в 2 раза.
Как можно объяснить?
Моё предположение состоит из двух составляющих.
Во-первых, параллельное выполнение обеспечивает максимальную утилизацию вычислительных ресурсов. Простои выделенных ядер сводятся к минимуму, потому что почти отсутствуют временные моменты, когда следующая задача должна дождаться выполнения предыдущей. На эти мысли наводит старенькая статья в блоге Cloudera.
Во-вторых, кажется, что для одной задачи прирост производительности от увеличения количества ядер не является линейным, а постепенно замедляется. Таким образом, большей эффективности получается добиться от параллельного запуска нескольких методов.
Join множества признаков
Итак, мы умеем выполнять методы параллельно, теперь из результатов этих методов необходимо собрать витрину. Заодно разберём ещё один подход к параллельному вычислению.
Предположим у нас есть список датафреймов с признаками, которые можно джойнить по общему ключу:
frames = []
for _ in range(10):
df = get_df()
frames.append(df)Самое естественное решение в духе доступного интерфейса Spark - последовательный join:
def merge(frames: List[DataFrame]) -> DataFrame:
union = frames[0]
for df in frames[1:]:
union = union.join(df, on=["v"], how="full")
return unionПлан выполнения такого расчёта будет выглядеть так:
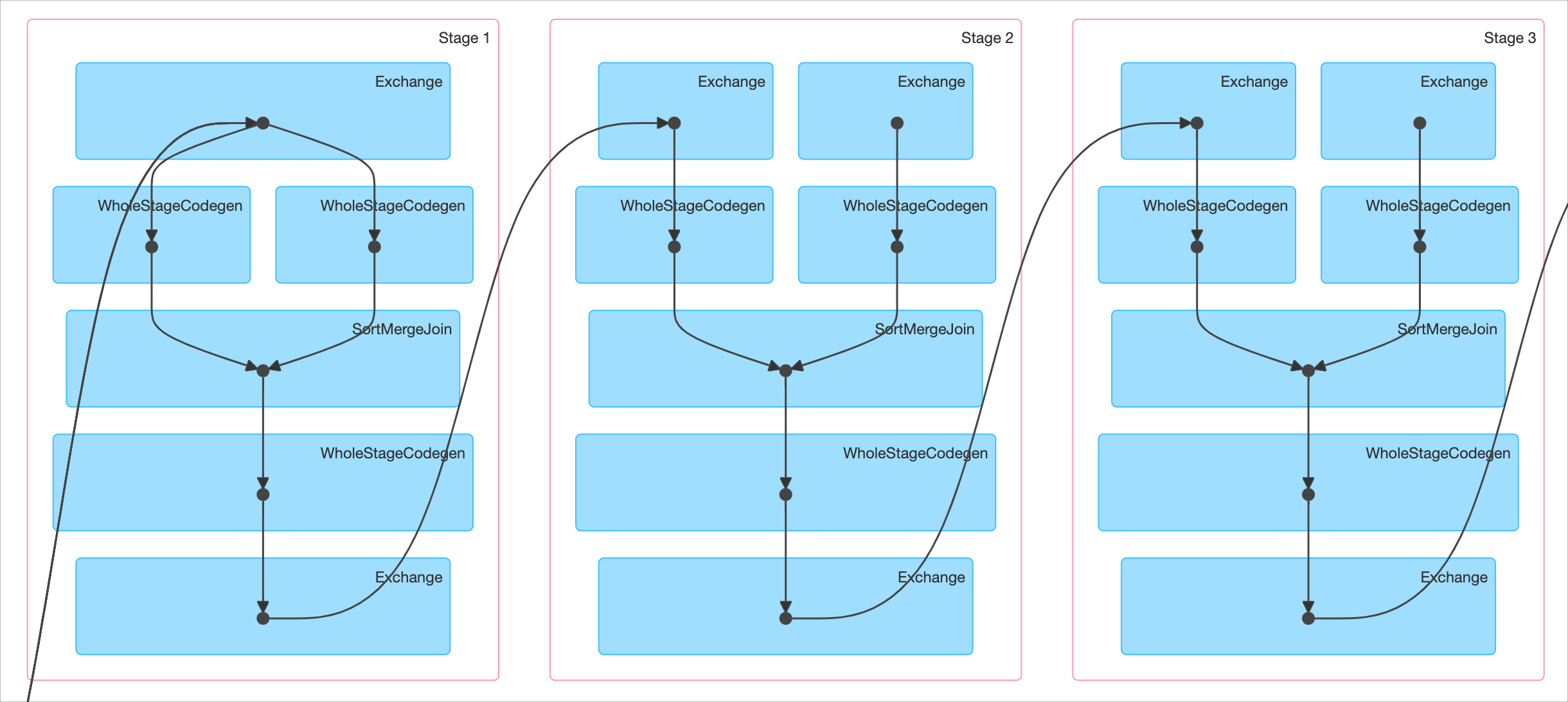
На вход следующего шага поступает результат предыдущего. Всё ожидаемо, хотя Spark мог бы попробовать это оптимизировать. Но он так явно не умеет.
Реализуем свой Join с параллельностью. Будем иерархически на каждом шаге проводить попарный join признаков. Таким образом, получим древовидную структуру, в которой каждая вершина совершает join своих потомков.
Класс вершины - хранит пару (или один) датафреймов, для которых выполняется join:
class Node(object):
def __init__(self):
self.children: List[DataFrame] = []
def add_child(self, child: DataFrame):
self.children.append(child)
def join(self) -> DataFrame:
if len(self.children) == 1:
return self.children[0]
else:
df1 = self.children[0]
df2 = self.children[1]
df = df1.join(df2, on=["v"], how="full")
return dfВ итоге получится метод, похожий на построение турнирной таблицы - участники (датафреймы) находясь внизу турнирной таблицы, продвигаются вверх через попарный join. И в итоге в вершине таблицы (в корне) получается датафрейм с общим набором признаков.
def tournament_merge(leafs: List[DataFrame]=[]) -> DataFrame:
nodes = []
while(len(nodes) != 1):
nodes = []
for i in range(0, len(leafs), 2):
pair = leafs[i : i+2]
node = Node()
for v in pair:
node.add_child(v)
nodes.append(node)
leafs = []
for n in nodes:
leaf = n.join()
leafs.append(leaf)
root = nodes[0]
union = root.join()
return unionВместо тысячи слов про деревья и турнирные таблицы предлагаю посмотреть на анимированный пример:

В этом методе не используются параллельные потоки для отдельных джойнов, потому что общий план выполнения будет выглядеть примерно так:

Два параллельных join'а идут на вход третьему. Что в результате реального запуска приведёт к параллельному вычислению в Spark. А так как используется fair-пул, то параллельные джойны будут стремиться выполняться на равном количестве ядер.
Применение tournament_merge достигает трёхкратного превосходства над последовательным подходом. Объяснение этому, по моему мнению, заключается в том, что, конечно, количество джойнов будет одинаковым, но некоторые из них выполняются параллельно относительно друг друга. Это приводит к экономии общего времени.
Заключение
В статье рассмотрены некоторые подходы к параллельному выполнению методов в Spark. Основная идея заключается в возможности использовать SparkSession в параллельных потоках. И для истинной параллельности необходимо немного поправить конфиг в Spark. Проведённые эксперименты показывают существенный прирост производительности от использования параллельности.
Автор: Илья Панов
