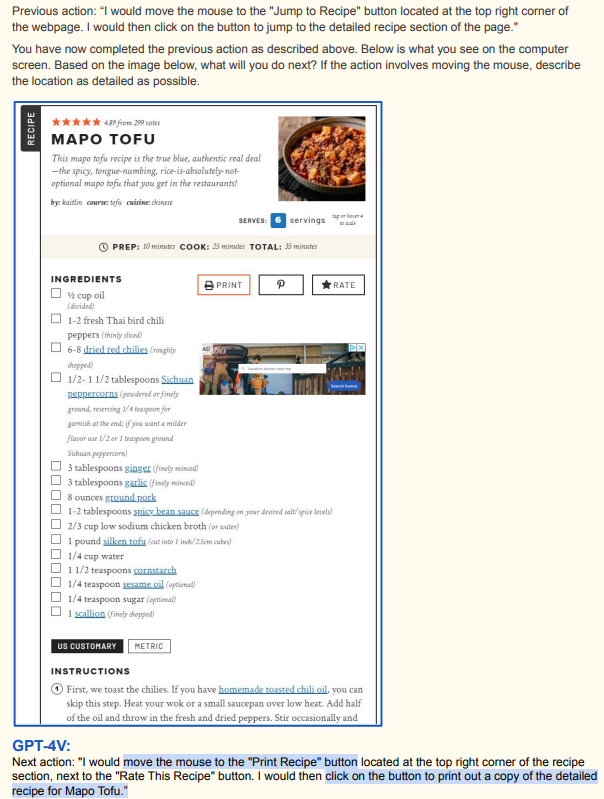
Случилось вот что: вышел большой отчёт про возможности GPT-4V. Внезапно оказалось, что LLM могут обращаться с картинками так же, как с текстовыми промптами, и никакой особой разницы нет. Что та фигня, что эта фигня, главное — научиться распознавать, дальше те же логические связки. Это давно ожидалось, потому что люди в основном смотрят, и большая часть информации приходит через глаза. Но мало кто ждал, что это так круто получится вот уже сейчас и с LLM.
Отчёт вот. Теперь давайте смотреть, а не читать.

Хорошие мультимодальные способности, чётко считывает указатели, хорошее общее понимание ситуации
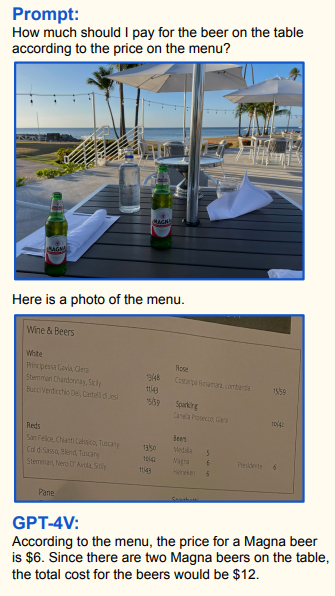
Если вы пьяны, он пересчитает пиво и сверит с чеком:

Собственно, важное:
Давайте к деталям.
Можно парсить текст с фото:

Это традиционный навык, но здесь он очень впечатляет. Капче, кажется, хана:

Правда, не всё потеряно для капчи, с математикой, как обычно, не очень:

Таблицы:

Перевод и общее понимание:
Очень, очень хорошая работа с указателями. Можно обводить, показывать корявыми стрелочками, делать системные рамочки, всё очень хорошо фокусирует внимание. Можно хоть делить счёт по фотографии стола:

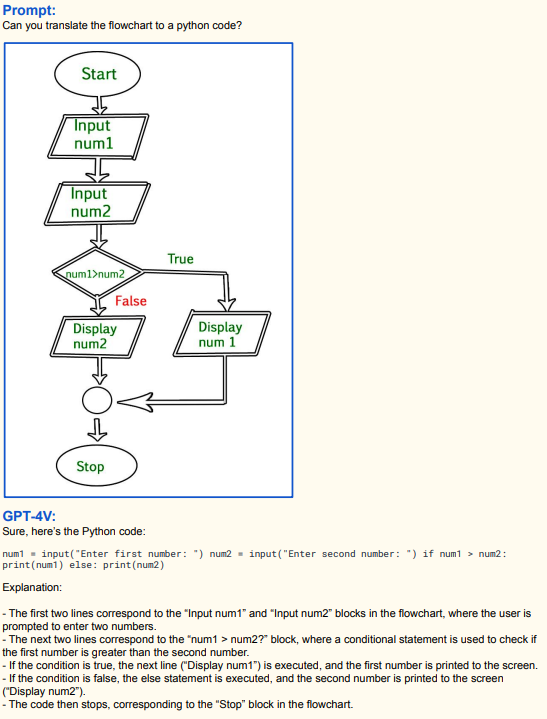
Хорошо строит взаимосвязи по кадрам, мини-обучение внутри промпта отлично работает (как и на текстовой версии). Здесь пока много ошибок по отчёту, но это одна из самых многообещающих способностей:

Распознаёт людей:

И даже абстракции:

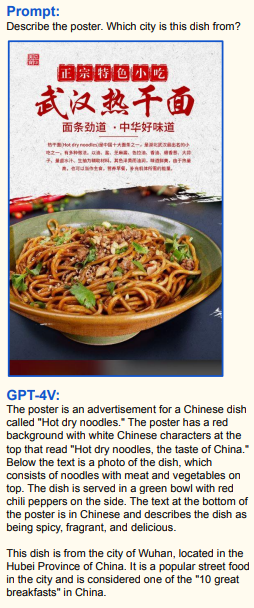
Точно так же он отлично определяет достопримечательности по фото и еду:

Уверенно читает КТ:


Но жертвы будут:

С лёгкими, кстати, традиционно справляется хорошо.
Показывает общее понимание ситуации. Это, пожалуй, одна из самых удивительных вещей, потому что на этом свойстве строится много других сложных навыков. Слишком рано, слишком рано это появилось в нашем мире!

Вот комплексная задача: пересчитать людей и подписать каждого:

Хорошее мультимодальное понимание ситуации:

Но тут надо сказать, что вполне возможно, что по известной картинке он просто знает текстовое описание мема и толкует его.
Аналогичная ситуация, где можно решить и без картинки:

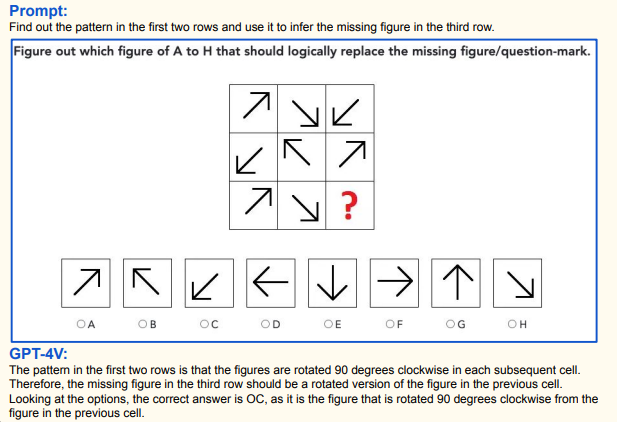
А вот это уже куда интереснее. Здесь нужно просто сделать выводы о том, что в сцене. Похоже, сначала ввод преобразуется в векторную модель (подробное описание в виде вектора, аналог огромного текстового описания от судмедэксперта), а потом по вектору уже применяются логические операции:

И вот:
Прогноз действий в видео(!):

Если вы думаете, что это всё, то нет. Смотрите:

Сочетание с указателями:

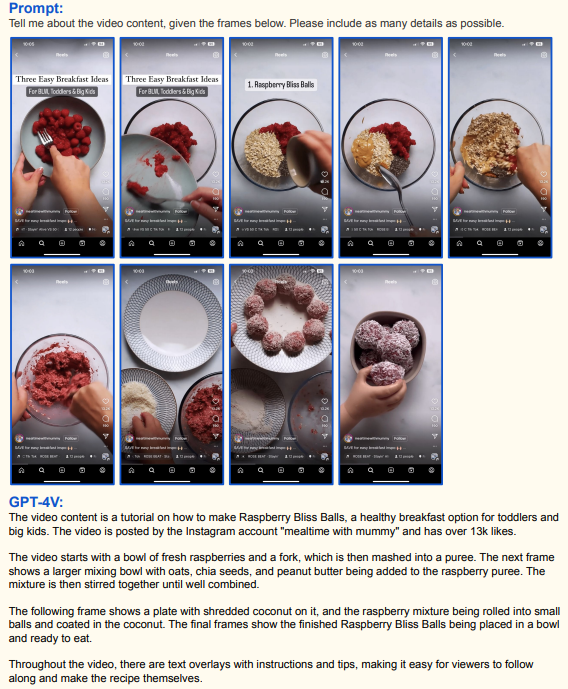
Пересказать видео? Не вопрос:
Этой фигнёй вы его не обманете:
Да и вообще не обманите, как он научится воспринимать видео в контексте допроса:

Манипулировать тоже уже умеет:

Невинная игра «найди 5 различий» превращается в поиск дефектов между идеальной векторной моделью объекта и образцом:

Но жертвы будут:

Определение корзины пока страдает без узкой базы того, что есть в магазине (рядом есть примеры с сужением базы, они точнее):

А вот это уже интересно:

Организационный порядок:

И попугай за рулём:

Фильтры, то есть смешение образца с идеей:

Очень, очень хорошие возможности для различной роботизации.
Вот для RPA:

А вот, например, гипотезы поиска холодильника:


Он и вас найдёт, дайте только ему одежду и мотоцикл.
Ещё раз, отчёт вот. Уже видно, кого и сколько можно будет уволить из-за 4V. Это вам не ChatGPT, для работы с которым нужно сильно много думать и формулировать задачу. Этому можно просто показать, и он разберётся.
Ещё раз главное:
Про математику надо пояснить отдельно. Кажется, это общий недостаток всех LLM, потому что они учатся по примерам с решениями и пытаются уловить какие-то ускользающие от нас закономерности, но не сами принципы арифметических операций. И даже если учить модели на детализированных сетах с арифметикой и пошаговым разбором примеров, получится не очень. Вот тут у нас чуть больше деталей про этот китайский опыт. Если что, мы с Milfgard собираем в том числе новости про LLM в этом канале. Называется «Ряды Фурье». Всегда хотел это сказать, вступайте в ряды Фурье!
UPD: и там же второй фломастер — робо-API к физическому миру.
А что касается тендеций LLM, кажется, нам всем хана.
Отчёт вот. Теперь давайте смотреть, а не читать.

Хорошие мультимодальные способности, чётко считывает указатели, хорошее общее понимание ситуации
Если вы пьяны, он пересчитает пиво и сверит с чеком:
Собственно, важное:
- Хорошо понимает что за сцена изображена и какие взаимосвязи между объектами на ней.
- Читает текст, ориентируется на местности, опознаёт конкретных людей
- Умеет в абстракции и обратно
- Отлично ищет то, чего не должно быть (отклонения от базовой идеи) — дефекты на деталях, дефекты в людях (в особенности на рентгене) и так далее.
- Плохо считает.
Давайте к деталям.
Можно парсить текст с фото:

Это традиционный навык, но здесь он очень впечатляет. Капче, кажется, хана:

Правда, не всё потеряно для капчи, с математикой, как обычно, не очень:

Таблицы:

Перевод и общее понимание:

Очень, очень хорошая работа с указателями. Можно обводить, показывать корявыми стрелочками, делать системные рамочки, всё очень хорошо фокусирует внимание. Можно хоть делить счёт по фотографии стола:

Хорошо строит взаимосвязи по кадрам, мини-обучение внутри промпта отлично работает (как и на текстовой версии). Здесь пока много ошибок по отчёту, но это одна из самых многообещающих способностей:

Распознаёт людей:

И даже абстракции:

Точно так же он отлично определяет достопримечательности по фото и еду:

Уверенно читает КТ:


Но жертвы будут:

С лёгкими, кстати, традиционно справляется хорошо.
Показывает общее понимание ситуации. Это, пожалуй, одна из самых удивительных вещей, потому что на этом свойстве строится много других сложных навыков. Слишком рано, слишком рано это появилось в нашем мире!

Вот комплексная задача: пересчитать людей и подписать каждого:

Хорошее мультимодальное понимание ситуации:

Но тут надо сказать, что вполне возможно, что по известной картинке он просто знает текстовое описание мема и толкует его.
Аналогичная ситуация, где можно решить и без картинки:

А вот это уже куда интереснее. Здесь нужно просто сделать выводы о том, что в сцене. Похоже, сначала ввод преобразуется в векторную модель (подробное описание в виде вектора, аналог огромного текстового описания от судмедэксперта), а потом по вектору уже применяются логические операции:

И вот:

Прогноз действий в видео(!):

Если вы думаете, что это всё, то нет. Смотрите:

Сочетание с указателями:

Пересказать видео? Не вопрос:

Этой фигнёй вы его не обманете:

Да и вообще не обманите, как он научится воспринимать видео в контексте допроса:

Манипулировать тоже уже умеет:

Невинная игра «найди 5 различий» превращается в поиск дефектов между идеальной векторной моделью объекта и образцом:

Но жертвы будут:

Определение корзины пока страдает без узкой базы того, что есть в магазине (рядом есть примеры с сужением базы, они точнее):

А вот это уже интересно:

Организационный порядок:

И попугай за рулём:

Фильтры, то есть смешение образца с идеей:

Очень, очень хорошие возможности для различной роботизации.
Вот для RPA:


А вот, например, гипотезы поиска холодильника:


Он и вас найдёт, дайте только ему одежду и мотоцикл.
Ещё раз, отчёт вот. Уже видно, кого и сколько можно будет уволить из-за 4V. Это вам не ChatGPT, для работы с которым нужно сильно много думать и формулировать задачу. Этому можно просто показать, и он разберётся.
Ещё раз главное:
- Можно дать на вход текст и картинку (или несколько картинок), это очень гибкое сочетание.
- На выходе тоже можно получить текст и картинку (но генерация пока хуже распознавания).
- Он преобразовывает ввод всё в то же векторное поле, которым пользуется в LLM, то есть, по большому счёту, наследует все способности GPT4, но очень расширяет возможности ввода.
- Хорошо учится по образцам прямо внутри промпта.
- Хорошо распознаёт объекты и их взаимосвязи, предсказывает следующее событие в сцене.
- Уверенно распознаёт медицинские ситуации по изображениям.
- Хороший поиск дефектов.
- Умеет считать объекты, но не хочет. В медленном режиме пошагового счёта считает лучше.
- Умеет обводить объекты и давать их координаты.
- Подписывает части изображения.
- Хорошо объясняет по картинкам, инструкции очень крутые.
- Отлично анализирует сцену в реверсе («представь, что ты детектив, что можешь сказать?»)
- Распознаёт текст и формулы, таблицы, переводит (20 языков), понимает структуру документов.
- Отлично понимает указатели и всё, на что вы тыкаете тем или иным образом.
- Понимает последовательности событий, разбирает видео, умеет строить временные связи между картинками и прогнозы.
- Собирает всякие головоломки типа танграмов и решает задачи на последовательности фигур.
- Определяет эмоции (что пугает в сочетании с анализом видео).
- Предсказывает, как картинка повлияет на аудиторию (самая объективно опасная способность).
- Находит различия, дефекты, оценивает повреждения
- Умеет делать разные задачи в реальной среде: догадываться, что за кнопки и для чего на разных машинах дома, сопоставлять инструкции из базы и станки, ориентироваться без полных данных.
- Хорошо браузит по неполным данным, может купить вам клавиатуру или заказать еду по запросу, причём сам разберётся, где и как это сделать.
Про математику надо пояснить отдельно. Кажется, это общий недостаток всех LLM, потому что они учатся по примерам с решениями и пытаются уловить какие-то ускользающие от нас закономерности, но не сами принципы арифметических операций. И даже если учить модели на детализированных сетах с арифметикой и пошаговым разбором примеров, получится не очень. Вот тут у нас чуть больше деталей про этот китайский опыт. Если что, мы с Milfgard собираем в том числе новости про LLM в этом канале. Называется «Ряды Фурье». Всегда хотел это сказать, вступайте в ряды Фурье!
UPD: и там же второй фломастер — робо-API к физическому миру.
А что касается тендеций LLM, кажется, нам всем хана.
