Базы данных — явление не новое. Способы хранения, поиска и предоставления данных пользователям являются ключевыми аспектами разработки веб-приложений на протяжении многих лет. Однако это не означает, что все осталось по-прежнему.
Сегодня мы узнаем про перспективы развития баз данных — 8 тенденций управления информацией и рассмотрим 11 наглядных примеров.
В настоящее время многие компании обращаются к более новым решениям, нежели к традиционным реляционным базам данных, которые были разработаны в 70-х годах и до сих пор являются основой большинства современных IT-систем.
Компании стремятся предоставить нам больше возможностей, таких как ускоренный доступ к информации, новые подходы к представлению данных, которые точнее соответствуют реальному миру или области знаний, которую мы пытаемся смоделировать.
Сегодня мы хотим поговорить о некоторых тенденциях в разработке баз данных, которые способствуют таким изменениям, а также о компаниях, являющихся лидерами в этой области.
В итоге вы сможете воспользоваться преимуществами новых разработок и использовать эти футуристичные базы данных в своем следующем проекте.
Начнем.
Как меняется ситуация с данными?
За последнее десятилетие роль данных в ежедневной коммерческой деятельности претерпела фундаментальные изменения.
Говорят, что данные — новая нефть. Сегодня организации хранят и обрабатывают больше информации, чем когда-либо в истории. Это принесло огромный ряд преимуществ, но также создало новые проблемы.
Прежде всего, нам нужны безопасные и эффективные решения для хранения, доступа и использования больших и разнообразных массивов данных. Важно также сохранять качество, точность и целостность данных и при этом предоставлять бизнес-пользователям возможность получать необходимые им сведения.
Это вызвало стремительный рост новых подходов к хранению и обработке данных.
8 тенденций управления данными
Сегодня мы рассмотрим восемь тенденций из области управления данными в 2023 году, которые все больше доминируют на рынке. Помимо этого, приведем несколько примеров каждой из них — всего одиннадцать новых и интересных платформ.
Не будем медлить, давайте приступим к делу.
1. Serverless базы данных
Итак, на первом месте у нас бессерверные версии баз данных (serverless databases).
Бессерверные базы данных — это не новая концепция, но она становится все более популярной.
Несмотря на название, речь не идет об отсутствии серверов. Это означает, что за управление, поддержку и обслуживание инфраструктуры, на которой построены ваши облачные базы данных, отвечает кто-нибудь другой.
Благодаря этому пользователи могут начать работу с данными быстро и без лишних сложностей. Вам не нужно создавать инфраструктуру или разбираться в технических деталях настройки.
Такой подход зачастую более экономичен, поскольку вы платите только за то, что используете.
И, как правило, это масштабируемое решение. Легче получить доступ к большему количеству баз данных. Вы просто запрашиваете их, и поставщик бессерверных баз данных их вам предоставляет.
Стоит отметить две компании, которые работают с базами данных образца 70-х годов и предоставляют их в в виде облачных serverless-сервисов.
Одним из преимуществ использования баз данных 70-х годов в качестве serverless-сервиса является то, что они обычно более дешевы, чем современные. Кроме того, эти базы данных могут быть проще в использовании и иметь хорошую производительность для определенных типов рабочих нагрузок.

PlanetScale
PlanetScale — это платформа, предоставляющая MySQL в виде serverless-сервиса. Она обеспечивает пользователю удобную панель управления (дашборд), с помощью которой можно мониторить трафик и отслеживать работу базы данных. Кроме того, PlanetScale выполняет высокооптимизированные и кэшированные запросы, что идеально подходит для широкого диапазона процессов работы с данными.
На начальном этапе, когда потребности в базе данных не велики, можно использовать бесплатную версию или тариф с минимальной стоимостью. Однако, когда по мере роста бизнеса или проекта возникает необходимость в надежной работе базы данных, высокой производительности, большем количестве хранимой информации или развертывании баз данных в других регионах для обеспечения лучшей доступности, можно перейти на тариф подороже, который предоставляет необходимые ресурсы и функциональность.
Это подход, основанный на потребностях клиента, позволяет экономить деньги на начальном этапе и масштабировать расходы на базу данных по мере роста.
PlanetScale также предоставляет возможность создания отдельных баз данных для продакшна и разработки всего лишь одним кликом. Это позволяет избежать конфликтов и ошибок, которые могут возникнуть при использовании одной базы данных для различных целей.

SupaBase
SupaBase — платформа, обеспечивающая использование базы данных Postgres в serverless-режиме. Если вы знакомы с Firebase, SupaBase станет отличной альтернативой, позволяющей управлять своими данными без сервера. Эта платформа предоставляет возможность управления авторизацией и настройки edge-функций, которые выполняются непосредственно на устройствах пользователей, подключенных к сети, а не на центральном сервере. Например, edge-функции могут использоваться для обработки данных, генерируемых датчиками Интернета вещей (IoT). Вместо отправки всех данных на центральный сервер для обработки, edge-функции могут фильтровать и агрегировать данные непосредственно на устройствах, а затем отправлять только необходимую информацию на сервер для дальнейшей обработки и хранения.
Опять же, есть хороший бесплатный уровень для начинающих и существует гибкая ценовая политика, которая зависит от объема использования и потребностей в доступности. Например, вы можете оплатить поддержку горячего резервирования базы данных, чтобы она была всегда готова к работе в зависимости от ситуации.
2. Cloud-native базы данных
Следующим направлением, о котором мы хотим поговорить, являются cloud-native (облачно-ориентированные) базы данных. Они не просто функционируют в облаке, а созданы специально для работы в облаке с нуля.
Это означает, что они, как правило, более устойчивы к внешним воздействиям, лучше самовосстанавливаются и могут использовать преимущества распределенной обработки способами, которые недоступны для других баз данных.
Как и бессерверные базы данных, они могут масштабироваться по мере необходимости. А такие процедуры, как резервное копирование, обновление и масштабирование, можно полностью автоматизировать. Эти базы данных были разработаны с учетом облачных технологий, благодаря чему они изначально используют все преимущества таких функциональных возможностей.

FaunaDB
FaunaDB — это база данных, которая была разработана специально для работы в облаке. Она быстрая и надежная. Fauna предоставляет разработчикам удобный интерфейс, вдохновленный TypeScript. Синтаксис и структура кода в FaunaDB похожи на TypeScript.
Вы можете устанавливать типы данных, и база будет проверять соответствие схеме всех документов, которые вы храните. Это также предоставляет мощные возможности для запросов и извлечения необходимой информации в нужном виде, особенно в контексте аналитики больших данных.
В целом, TypeScript-инспирированный интерфейс FaunaDB обеспечивает комфортную среду разработки для тех, кто знаком с TypeScript или JavaScript, и предоставляет мощные инструменты для работы с данными в безопасном и надежном режиме.
Кроме того, FaunaDB является первой документной базой данных, которую мы рассматриваем. Документная база данных — это тип NoSQL-базы данных, которая хранит информацию в виде документов, представляющих собой набор пар ключ-значение, где ключ — это имя поля, а значение — соответствующие данные. Документы могут иметь произвольную структуру и содержать вложенные документы.
При изменении структуры данных с течением времени или при работе с неструктурированными данными, такими как логи или фидбэки устройств Интернета вещей (IoT), мы можем принимать такую информацию в исходном виде и обрабатывать позже.
FaunaDB предоставляет профессиональный план, который доступен бесплатно в течение 30 дней после регистрации.
Более продвинутые планы включают в себя такие возможности, как ведение журналов, неограниченное количество разработчиков, неограниченное количество баз данных, высокая производительность, поддержка нескольких регионов и многое другое.
Также существует бесплатный план, который в основном предназначен для тех, кто только осваивает FaunaDB. Он накладывает довольно жесткие ограничения на то, что вам может понадобиться, но можно их снять всего за 25 долларов в месяц, чтобы иметь возможность изучать и масштабировать свой сценарий использования.
3. Branching
Далее рассмотрим базы данных, поддерживающие branching (ветвление). Если вы когда-либо использовали Git, то создание отдельных структур данных или копий существующих данных для тестирования или разработки а затем их последующий мерч с основной веткой будет вам знакомо.
Теперь существуют базы данных, которые позволяют делать то же самое. Мы можем создать новую ветку, которая будет содержать снапшот данных и структуры на текущий момент времени. Затем мы можем вносить изменения в эту структуру и объединять ее с основной веткой — как только убедимся, что новая структура данных — это то, что мы хотим реализовать.
Branching в базах данных позволяет разработчикам экспериментировать с изменениями в структуре данных без риска нарушить работу приложения. Это также позволяет легко откатить изменения, если они окажутся неудачными. Кроме того, branching позволяет нескольким разработчикам работать над одним проектом, не мешая друг другу, и объединять свои изменения в одну общую ветку.

NeonDB
Одна из компаний, познакомивших нас с branching, — Neon. Neon — это бессерверная база данных Postgres, такая же, как Superbase.
И, что очень важно, она также предоставляет возможность создавать разветвления или альтернативные ветви выполнения на основе определенных условий или событий.
В бесплатной версии вы можете иметь до 10 веток. Вы можете создавать новые ветви с дашборда или автоматически генерировать их на основе событий, таких как git push, новая фич-ветка или другие триггеры.
Neon ведет себя как обычная база данных Postgres, поэтому мы можем взаимодействовать с ней так же, как и привыкли, но только с дополнительным преимуществом в виде branching.
В плане тарифов NeonDB предоставляет щедрую бесплатную версию с одним проектом, 10 ветками и 3 ГБ хранилища.
Ценообразование основано на ряде показателей, которые масштабируются в зависимости от того, что вы используете.
Так что если у вас есть клиенты, которые часто пользуются вашим сервисом, то будете платить больше. Если же ваш сервис не задействован или находится в стадии разработки, не будете платить ничего — либо не очень много.
Вы можете создавать ветки одним кликом через API, деплоя и реинтегрируя их.
Можно создавать предварительную версию базы данных для каждого PR (Pull Request). Это позволяет обеспечить хорошую изоляцию данных в больших командах, которые работают над несколькими фичами одновременно.
4. Мультимодельные базы данных
Далее рассмотрим базы данных с поддержкой нескольких моделей (мультимодельные). Такие базы данных предназначены для интеграции различных типов данных через единый бэкенд. Это означает, что они могут работать с данными разных типов — реляционными, нереляционными или графовыми.
Это дает разработчикам возможность выбора наиболее подходящего типа данных для конкретного случая использования, при этом данные не будут изолированы от остальной части приложения или экосистемы.
Главное преимущество здесь — универсальность. Базы данных с поддержкой нескольких моделей предоставляют разработчикам большую гибкость.
Это также позволяет повысить эффективность и сделать ее более целенаправленной. Иногда при разработке определенной фичи лучше использовать реляционную базу данных, даже если остальная часть приложения построена на документной или NoSQL-базе, и наоборот.
А поскольку данные интегрируются через единый бэкенд, мы также можем достичь высокого уровня согласованности.

SurealDB
SurealDB позиционирует себя как универсальную мультимодельную базу данных. Она предоставляет язык запросов, который работает подобно традиционному SQL, но может применяться также к графам и временным рядам данных.
Она обеспечивает потрясающую производительность запросов и позволяет использовать машинное обучение, а также другие интересные фичи.
На данный момент SurealDB не предоставляет услугу хостинга для своей базы данных. Чтобы работать с ней самостоятельно, необходимо запустить свою машину. Таким образом, для ее использования требуются дополнительные знания DevOps.
Однако эффективность и гибкость SurealDB могут стоить этих усилий.

Couchbase Capella
Couchbase Capella — еще одна база данных, созданная для работы с мультимодельными данными.
Она позволяет объединить несколько технологий обработки данных в единую архитектуру. Все данные поступают в Couchbase, а затем их можно запрашивать через API.
По существу, Capella является NoSQL документно-ориентированной базой данных, поэтому структура данных, как правило, читается человеком, как стандартный JSON. Вы также можете запрашивать данные, используя SQL-подобный синтаксис — включая операторы SELECT с JOIN (для выбора и объединения данных из нескольких таблиц).
Если вы работаете с SQL и хотите освоить NoSQL, Capella может стать отличным переходным вариантом, пока не решите, в какую сторону двигаться.
Бесплатного тарифа нет, но вы можете установить Couchbase на различных облачных платформах самостоятельно, без привлечения провайдера для управления инфраструктурой.
Когда вы устанавливаете Couchbase на облачной платформе самостоятельно, то сами решаете, где будет храниться ваша база данных, как будут организованы резервные копии данных, как обеспечивается безопасность и т. д. Это может быть важно для компаний, которые работают с чувствительной информацией и стремятся обеспечить максимальную защиту данных, включая air-gap (воздушный зазор).
Есть также вариант с опцией управления.
В отличие от других баз данных, которые могут оплачиваться в соответствии с использованием (то есть стоимость зависит от объема данных, хранящихся или обрабатываемых в базе данных), Couchbase оплачивается по времени. То есть, вы платите за то время, когда кластер баз данных развернут и готов к работе, независимо от того, насколько интенсивно вы его используете. Это связано с тем, что узлы кластера Couchbase всегда доступны, всегда имеют доступ к данным и всегда обрабатывают эти данные, даже если вы не выполняете активные запросы к базе данных. Оплата по времени может быть более предсказуемой и удобной для организаций, которые предпочитают планировать свои расходы на базу данных заранее.
5. Графовые базы данных
Далее рассмотрим графовые базы данных. Это базы данных NoSQL, в которых взаимосвязи между данными считаются столь же важными, как и сами данные. Они особенно полезны при работе с высокосвязанными данными, такими как социальные сети или цепочки поставок.
Графы также используются в рекомендательных системах или для выявления мошенничества.
В графах выделяют три основных компонента:
Узел, представляющий конкретную сущность — например, человека или товар.
Ребра — связи между различными узлами.
Пары ключ-значение, называемые свойствами, которые существуют на узлах или ребрах.
Графовые базы данных отражают естественную структуру и взаимосвязи в реальном мире. Мы часто мысленно представляем связи между объектами или сущностями в виде графа. Такая модель становится более интуитивной для понимания и использования, поскольку она отражает наш обычный способ мышления о взаимосвязях между объектами.
При росте объема данных графовые базы по прежнему способны эффективно обрабатывать запросы. Здесь нет необходимости использовать операторы объединения (JOIN), как это делается в реляционных базах данных. Они не требуют объединения, поскольку связи между узлами уже встроены в базу данных.
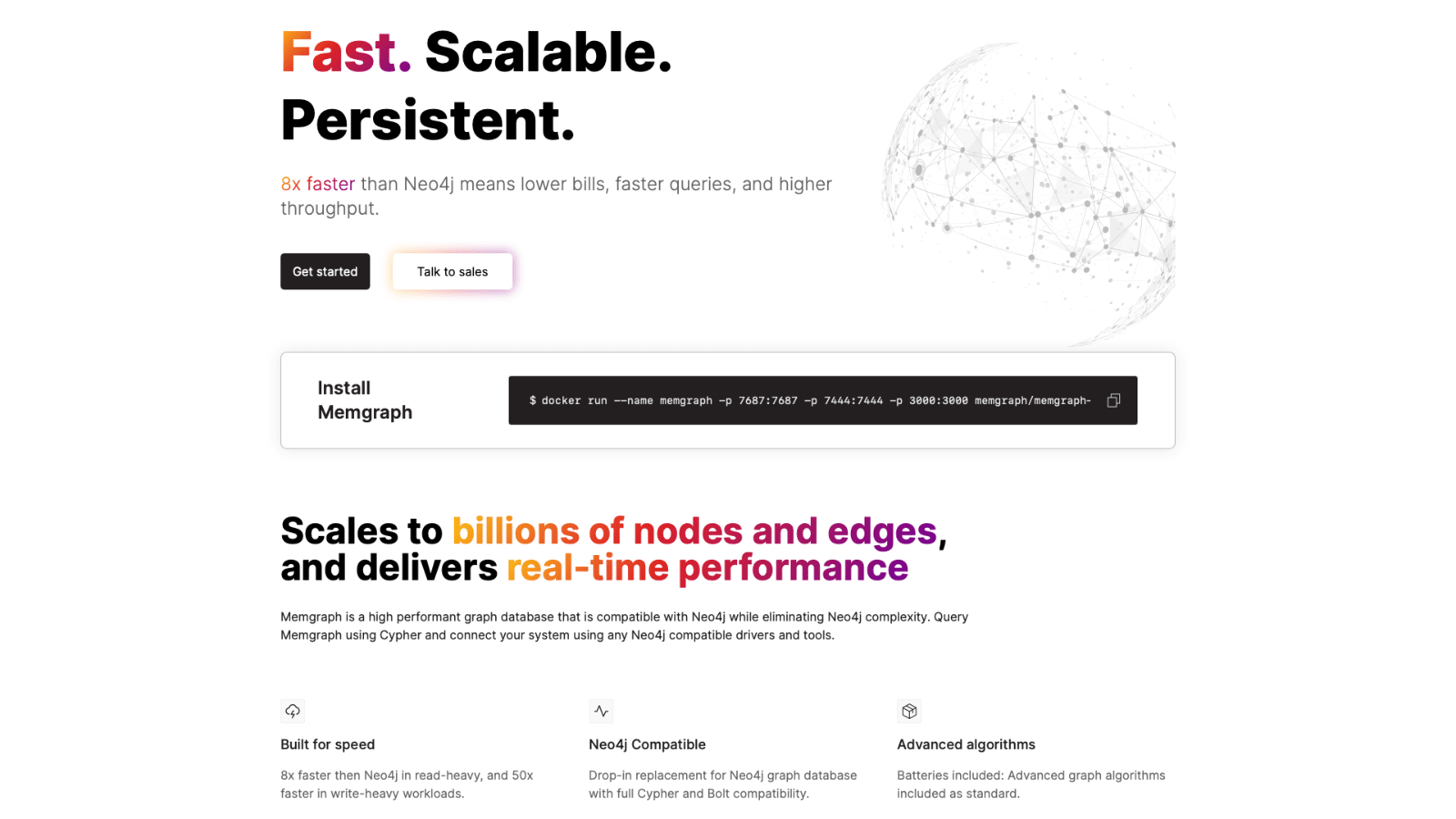
Memgraph
Memgraph — это решение для графовых баз данных, которое представляет собой более производительную и быструю альтернативу Neo4j. Вы можете запускать Memgraph на Docker, на вашей локальной инфраструктуре или использовать бесплатную Community Edition. Memgraph масштабируется до миллиардов узлов и ребер, при этом не теряя высокой производительности.
Кроме того, Memgraph поддерживает использование любых графов, которые вы уже реализовали с помощью Neo4j, их можно легко в нее импортировать.
Что касается цен, то Community Edition бесплатна. Есть версия Enterprise Edition, включающая в себя такие функции, как аутентификация, контроль доступа на основе ролей и полный аудит деятельности — для повышения безопасности данных. Недавно Memgraph также выпустил бета-версию в облаке с поддержкой нескольких регионов, автоматическими обновлениями и управляемыми резервными копиями.
Стоимость зависит от размера вашего экземпляра. Если вы размещаете базу данных в облаке, цена начинается от $25 в месяц за один экземпляр размером в один гигабайт.
6. Базы данных временных рядов
Еще один тренд развития баз данных — это базы данных временных рядов. В которых каждая точка данных имеет метку времени. Данные временных рядов могут быть измерениями или событиями, которые отслеживаются и агрегируются в течение определенного периода времени.
К ним могут относиться такие показатели, как температура, курс акций, использование CPE (Customer Premises Equipment — клиентское оборудование) и широкий спектр других явлений и систем в реальном мире.
Базы данных временных рядов должны быть оптимизированы для больших объемов записи. Поэтому, поскольку мы ожидаем, что запись в эту базу данных будет осуществляться практически непрерывно, то быстрая и эффективная обработка этих записей будет иметь решающее значение.
Нам также нужны возможности агрегирования данных — например, вычисление сумм и средних значений за определенные периоды времени для получения инсайтов.
Как правило, существуют и определенные политики хранения данных. Данных может быть так много, что вам придется задуматься о том, сколько времени их следует сохранять.
Базы данных временных рядов должны быть высокомасштабируемыми. Они, как правило, масштабируются горизонтально, чтобы справиться с растущим объемом информации. Часто используется расширенная функциональная возможность по сжатию данных — учитывая большие объемы хранимой информации.
Некоторые базы данных временных рядов работают со специализированными языками запросов, в то время как другие поддерживают SQL-подобные запросы.

InfluxDB
InfluxDB является отличным примером базы данных временных рядов.
Это специализированное решение, которое сосредоточено на одной задаче. Она способна масштабироваться в облаке, локально или на периферии. Вы можете запустить ее без сервера или на собственной инфраструктуре.
Influx также поддерживает SQL в качестве нативного языка, а также предоставляет другие методы для работы с данными.
Например, InfluxDB предоставляет SDK (Software Development Kit — комплект для разработки программного обеспечения) практически для всех языков программирования, включая JavaScript, Python, Go, C# и Java.
В плане тарифов, вы можете начать бесплатно, Это позволяет нам сразу приступить к работе с этим полностью управляемым, гибким, многопользовательским сервисом. Вы платите только за то, что используете, когда превышаете установленные лимиты.
Кроме того, Influx предлагает установку в один клик, чтобы начать эксплуатацию на планах с самостоятельным хостингом.
Вам также может понравиться наш гид по платформам цифровой трансформации.
7. Внедрение искусственного интеллекта (AI) в базы данных
Следующая тенденция, о которой мы хотим поговорить, — это внедрение искусственного интеллекта (AI) в базы данных. Встраивание AI позволяет получить действительно мощные инструменты управления и анализа данных непосредственно в базе данных.
Как администраторы и разработчики баз данных, мы можем использовать AI и машинное обучение на месте. Например, использовать модели AI с помощью SQL или улучшать раз за разом наши данные с помощью машинного обучения.
Есть много преимуществ в том, чтобы делать это непосредственно в базе данных.
Во-первых, это проще в эксплуатации — мы применяем тот же язык запросов, с которым уже знакомы, — поэтому мы можем использовать AI без изучения новых технологий.
С другой стороны, это более эффективный, производительный и безопасный способ. Мы не переносим для обработки данные из нашей базы данных в другую систему.
Все происходит на месте, а это значит, что мы сокращаем издержки и снижаем риски различных атак и утечек данных.

MindsDB
MindsDB — это база данных, ориентированная на искусственный интеллект (AI). Она интегрируется со множеством различных источников данных, таких как Slack или Shopify, Postgres и другие. MindsDB также может получать данные в реальном времени и применять к ним передовые методы машинного обучения и AI.
А затем может снова улучшить эти данные, и еще раз по кругу, чтобы получить невероятно мощную функциональность, такую как создание собственного чат-бота или большой языковой модели.
MindsDB также может быть использована для обнаружения мошенничества или аномалий. Если вы планируете создать приложение с использованием AI, то реализация его на уровне базы данных предоставляет множество возможностей.
Что касается цен, то есть демо-уровень, где MindsDB можно просто запустить и посмотреть на нее бесплатно. А также версия с открытым исходным кодом, которая разворачивается самостоятельно одним кликом.
Таким образом, MindsDB соответствует нескольким тенденциям, о которых шла речь в этом руководстве. У нас есть мультимодельная, облачная инфраструктура, и мы добавляем дополнительные компоненты искусственного интеллекта, чтобы сделать ее невероятно мощным средством для создания производительных приложений на основе AI.
8. Базы данных и low-code разработка
BudiBase — это платформа для создания приложений, которая помогает командам превращать свои данные в действия.
Мы стремимся помочь командам создавать профессиональные и эффективные внутренние инструменты на основе ваших бизнес-данных.
Мы предоставляем специальные коннекторы для создания пользовательских интерфейсов и процессов на основе Postgres, MySQL, MSSQL, Couch, Mongo, Arango, S3, Oracle, Google Sheets, REST API и многих других — наряду с поддержкой пользовательских источников данных.
Если вы хотите создать приложение, но еще не определились с источником данных, у нас уже есть собственная внутренняя база данных. BudibaseDB предлагает быстрый и интуитивно понятный способ создания модели данных с нуля — включая поддержку отношений и переменных формул JavaScript.
Budibase позволяет компаниям сэкономить тысячи на разработке. Ознакомьтесь с нашим обзором возможностей, чтобы узнать больше.
В заключение хотим напомнить про открытый урок, который пройдёт 11 марта. На нём мы рассмотрим Aggregation Framework: зачем он нужен, основные возможности и ограничения. Записаться можно на странице курса «NoSQL».
