

Недавно мы обсуждали ИИ-агентов, способных найти решение для произвольных задач и улучшать его до бесконечности. Предполагается, что в будущем множество автономных ИИ-агентов смогут наладить коммуникацию между собой и сформировать коллективный интеллект. Сейчас это одна из самых актуальных тем исследований. Появились даже специальные платформы для разработки и тестирования агентов, такие как SuperAGI.
Один из интересных аспектов обучения ИИ-агентов — внедрение любопытства и саморефлексии, самоанализа. Это позволяет лучше адаптироваться к изменениям среды, обращая внимание на новые и потенциально важные явления вокруг. Примерно тем же занимается человеческий мозг (гиппокамп) во время сна, прокручивая воспоминания за день и оценивая их важность/новизну для долговременного хранения или удаления из памяти.
Базовый алгоритм работы агента (на примере BabyAGI):

В обучении агента действует принцип рекурсии. После получения задачи создаётся список подзадач, которые по результатам выполнения обновляются.
Однако этот стандартный алгоритм не слишком приспособлен к реальной жизни в открытом мире, где постоянно встречаются новые, незнакомые объекты, с которыми нет опыта взаимодействия.
Группа учёных из Стэнфордского университета провела эксперимент: они поместили живую мышь в небольшую пустую коробку. Такую же виртуальную среду сделали для ИИ-агента. Затем исследователи опустили в обе коробки красный мячик — и провели замеры, кто из них быстрее исследует новый объект. Мышь быстро подошла к мячику и в течение следующих нескольких минут неоднократно взаимодействовала с ним.

Что касается ИИ-агента, он словно не заметил ничего нового. Учёные задумались, как реализовать на первый взгляд простой алгоритм поведения животных для совершенствования ИИ. Чтобы решить эту проблему, они предложили улучшенный алгоритм работы агентов под названием Curious Replay, то есть «повтор с любопытством», нечто вроде саморефлексии.

Тест на взаимодействие с новыми объектами. a) В 3D-симуляции агент исследует пустую арену в течение 500 тыс. шагов, после чего в неё вводится новый объект. b) Метод Curious Replay улучшает адаптивность агента Plan2Explore. c) Интервал времени до взаимодействия, включая Plan2Explore с приоритетом на temporal-difference error (TD). d) Plan2Explore не может быстро смоделировать новый объект, даже несмотря на значительный опыт наблюдения за ним. Напротив, Curious Replay быстро учится. e) Производительность с течением времени
Метод «саморефлексии» программирует ИИ-агентов вспоминать о самых новых и интересных вещах, с которыми они недавно столкнулись. Внедрение этого алгоритма значительно изменило поведение ИИ-агента. В том же тесте он стал гораздо быстрее приближаться к красному шару и взаимодействовать с ним.
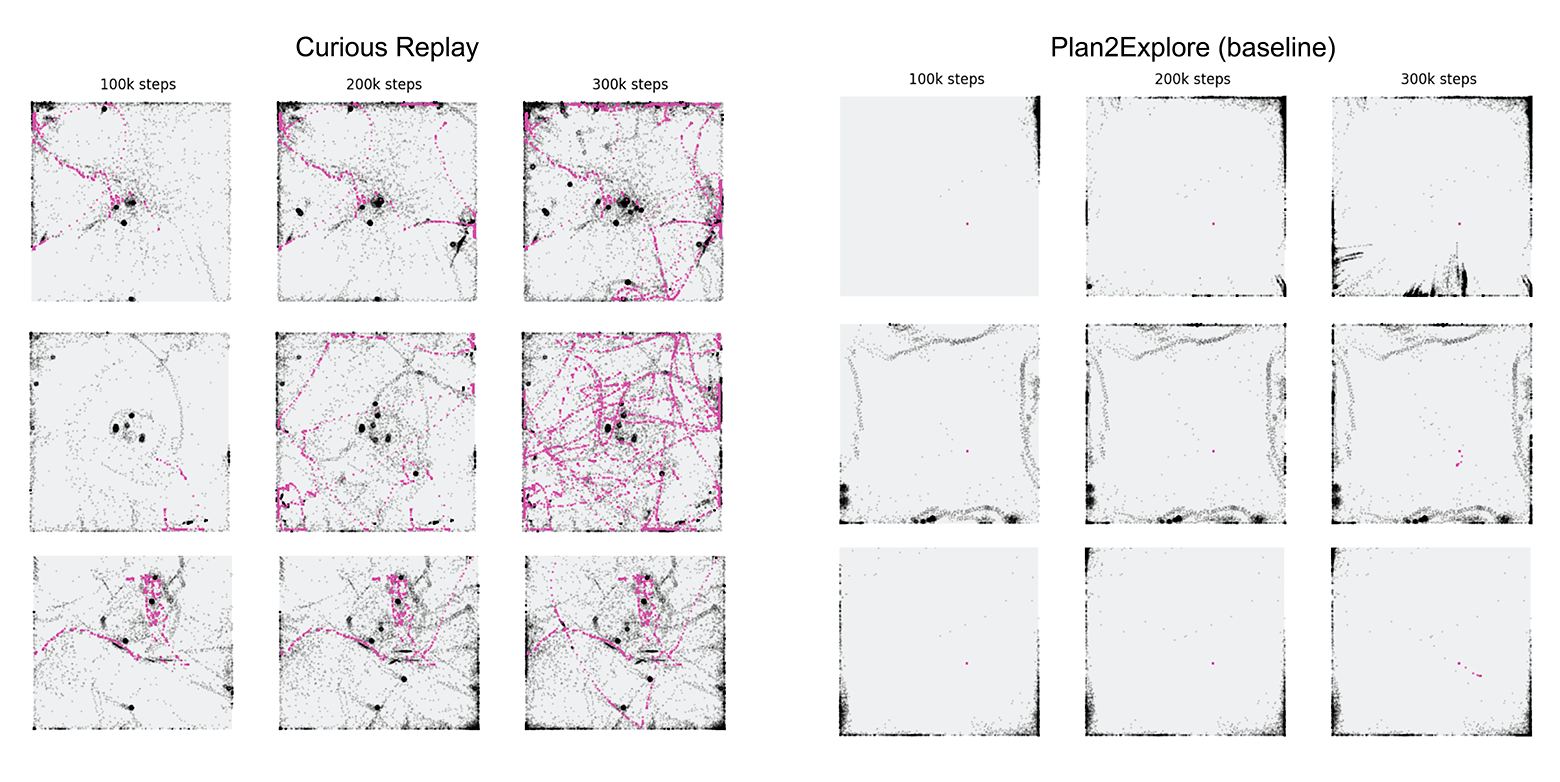
Пример базовых траекторий агентов Dreamer и Curious Replay на 100 тыс., 200 тыс. и 300 тыс. шагах после появления объекта. Чёрной точкой обозначено местоположение агента, пурпурным (маджента) — объект
Учёные говорят, что они использовали любопытство для ИИ-агента по-новому: «Вместо выбора действия программа выбирает, о чём думать — какой опыт из прошлого нужно изучить тщательнее». Другими словами, разработчики побудили ИИ-агента к самоанализу.
На практике для самоанализа ИИ используется распространённый метод обучения агентов «воспроизведение опыта» (experience replay). В этом случае агент хранит воспоминания обо всех своих взаимодействиях, а затем воспроизводит некоторые в случайном порядке, чтобы извлечь новые знания (так же делает гиппокамп человеческого мозга во сне для закрепления важных воспоминаний в долговременной памяти). Код Curious Replay см. здесь (Python).

Долгосрочная надёжность Curious Replay (интервал времени до 50-го и 500-го взаимодействия)
Любопытство имеет решающее значение для выживания человека и других животных, позволяя избегать опасных ситуаций и находить предметы первой необходимости. К примеру, красный шарик в эксперименте может оказаться утечкой смертельного яда или спрятанным ресурсом. И если мы не обратим на него внимания, то не узнаем это вовремя. Поэтому любопытство и размышление над увиденным — критически важные навыки для жизни людей. А значит, и для эффективного ИИ.
Благодаря такому подходу (любопытство и саморефлексия) реализация на модели DreamerV3 показала абсолютно лучший результат в бенчмарке Crafter:

В целом применение любопытства и саморефлексии позволит создавать агентов, способных использовать предыдущий опыт и хорошо адаптироваться, эффективно исследуя новую или меняющуюся среду.
▍ Базовые факты
Вот некоторые основные цифры, которые следует знать разработчикам о LLM:
- 1,3 токена на одно слово (в среднем).
- 10:1 — примерное соотношение стоимости преобразования слов в векторы (embeddings) в сервисе OpenAI и на своём хостинге (инстанс g4dn.4xlarge за $1,20 в час обрабатывает до 9000 токенов в секунду на модели SentenceTransformers от Hugging Face).
- $1 млн — стоимость обучения модели с 13 млрд параметров на 1,4 трлн токенов. В статье по LLaMA указано, что обучение заняло 21 день на 2048 видеоускорителях A100 80GB. Правда, сейчас Hugging Face открывает собственный Training Cluster. Судя по предварительным расчётам, там цены в полтора раза ниже:
- Более 1000:1 — разница в стоимости обучения с нуля и настройки (дообучения) уже готовой модели. Настройка модели с 6 млрд параметров стоит около $7. Даже в OpenAI настройка самой дорогой в дообучении модели Davinci стоит примерно три цента за 1000 токенов, то есть настройка на всей базе Шекспира обойдётся всего в $40.
- V100: 16GB, A10G: 24GB, A100: 40/80GB — важно знать объём видеопамяти. От этого зависит количество параметров модели, которая способна работать на сервере.
- 2:1 — примерное соотношение объёма видеопамяти и максимального количества параметров, то есть для работы модели на 7 млрд параметров с точностью fp16 нужно примерно 14 ГБ видеопамяти на GPU. Если на один параметр приходится одно 16-битное число с плавающей запятой (fp16), то оно занимает два байта. Хотя при увеличении количества параметров вполне нормально проводить квантование векторов.
Квантование с fp16 до int8
Например,llama.cppза счёт агрессивного квантования до 4 бит нормально работает на GPU 6 ГБ с 13 млрд параметров.
- Около 1 ГБ — типичный объём видеопамяти, необходимый для преобразования слов в векторы математического пространства с учётом контекста (embeddings).
- 10x — повышение производительности от объединения запросов в группы (batching), потому что LLM на самом деле довольно медленно их обрабатывает: что-то вроде 0,2 запроса в секунду на обычном GPU. Однако запросы хорошо распараллеливаются.
- Около 1 МБ — объём видеопамяти для выдачи 1 токена в модели с 13 млрд параметров (над этим тоже работают оптимизаторы).


▍ Хостинг LLM на своём сервере. Никакой цензуры
Очевидно, что самое ценное применение LLM связано с обработкой персональных данных, внутренней корпоративной документации, бухгалтерии, собранной статистики и т. д. По определению, такую информацию нельзя передавать третьим лицам, во внешнее облако или SaaS-сервис. Её можно обрабатывать только локально. Поэтому сейчас огромный спрос на корпоративные локальные версии LLM, работающие на собственном хостинге внутри компании. Сама OpenAI пытается ответить на этот запрос, выпустив в августе корпоративную версию ChatGPT Enterprise. Google тоже выпустила NotebookLM — программу для генерации приватных моделей ИИ на основе пользовательских документов (на базе PaLM 2).
Свой хостинг допускает тонкую настройку на кастомном датасете, а также устранение цензуры, что позволяет получить рецепт и инструкцию по изготовлению любого вещества:
Для локальной модели мы платим только за хостинг, но не платим OpenAI за обработку запросов, поэтому при интенсивном использовании система выходит дешевле в обслуживании (см. анализ стоимости и производительности: 1, 2).
См. также руководство по локальной установке Llama 2 на своём сервере и тонкой настройке параметров.
▍ Оптимизация моделей
Если большие корпорации могут позволить себе развернуть модель на серверном кластере, то обычным людям такое недоступно. Единственный выход — максимальная оптимизация существующих моделей для работы на обычном ПК, а ещё лучше на смартфоне, без мощного GPU и большого объёма RAM.
Это тоже передовой край исследований, где новости появляются каждый день.
Например, в репозитории Lit-GPT под открытой лицензией выкладываются модели LLM, приспособленные для работы на обычном компьютере. Lit-GPT является базой для конкурса NeurIPS Large Language Model Efficiency Challenge с целевой установкой 1 LLM + 1 GPU + 1 день. Задача в том, чтобы базовая модель могла дообучаться для конкретных задач на одном GPU 4090 или A100 (40 ГБ) в течение 24 часов (1 день), сохраняя при этом высокую точность для этих задач.
«Результатом конкурса станет обобщение полученных знаний и уроков в виде набора хорошо документированных шагов и простых в освоении руководств. В распоряжении сообщества специалистов в области ML будет документация по достижению той же производительности, что и у победителей конкурса, что послужит отправной точкой для создания собственных LLM-решений», — сказано на сайте конкурса.
В области генераторов изображений text-to-image (T2I) тоже идут оптимизации. Исследователи из Nvidia AI недавно разработали метод персонализации Perfusion для модели генерации картинок по текстовому описанию. Эта модель по качеству изображений не уступает передовым моделям типа Stable Diffusion 1.5, новой Stable Diffusion XL (SDXL) от Stability AI или MidJourney. Разница только в высокой производительности: обучение Perfusion на пользовательских изображениях занимает несколько минут, а прибавка в размере дообученной модели — всего 100 КБ на каждую концепцию (вдобавок к основной предобученной модели в несколько гигабайт). Это очень серьёзное достижение. Для сравнения, популярный метод персонализации/настройки LoRA для Stable Diffusion добавляет к модели от нескольких десятков мегабайт до гигабайта на каждую новую концепцию.
Как вообще работает персонализация (настройка модели)? Предположим, у нас есть игрушечный медвежонок — и мы хотим сгенерировать фантазийное изображение конкретно с этим медвежонком. Так вот, после дообучения на одной или нескольких фотографиях медвежонка она способна объединять выученные концепции в рамках нового сгенерированного изображения (технология Key-Locking):

Perfusion от Nvidia AI, научная статья представлена на SIGGRAPH 2023
Сравнение Perfusion с другими моделями по нескольким одинаковым промтам:

Скорее всего, что в будущем с учётом роста производительности смартфонов и оптимизации моделей очень мощные ИИ-агенты смогут работать локально на обычном телефоне. Уже сейчас есть модели, которые запускаются на стодолларовом одноплатнике Orange Pi 5 с Mali GPU.
Ещё один вариант оптимизации для серверного бэкенда LLM — снижение нагрузки за счёт переноса вычислений на компьютеры клиентов, когда LLM запускается непосредственно в браузере, как Web LLM. То есть локально на клиенте, полностью внутри браузера, без серверной части. См. демо (требуется поддержка WebGPU и шейдеров fp16 в некоторых моделях, Chrome 113+, GPU с 3-6 ГБ RAM и несколько минут на скачивание параметров в локальный кэш):

Список моделей, которые поддерживаются в Web LLM
Если LLM запускается локально в браузере, то это не только снижает нагрузку на сервер, но и обеспечивает защиту приватности для персональных ИИ-агентов, которые обучаются на конфиденциальных данных пользователя.
На Github самым популярным репозиторием августа стал Candle от Hugging Face: минималистичный фреймворк на Rust с упором на производительность и простоту использования, см. демо: whisper, LLaMA2, yolo. Всё это можно поставить на своём сервере.
P. S. Сейчас в сфере AI происходит много событий. Модели LLM от марта 2023 года, советы по их установке и оптимизации к осени 2023 года уже устарели. Почти каждый день выходит что-то новое. Модели и инструменты LLM занимают больше половины списка самых популярных репозиториев на Github. Тот же Training Cluster от Hugging Face анонсировали пару дней назад. Кажется, для разработки сейчас самое интересное время за последние десятилетия.
Вот некоторые открытые темы исследования в области LLM, над которыми идёт работа:
- Измерение и уменьшение галлюцинаций.
- Оптимизация длины контекста и его построения.
- Включение новых модальностей данных.
- Повышение производительности и снижение цены LLM.
- Новые архитектуры.
- Разработка специализированного железа (вместо GPU).
- Повышение удобства использования агентов.
- Улучшение обучения на основе человеческих предпочтений.
- Улучшение интерфейса чата.
- Построение LLM для неанглийских языков.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх 🕹️

