Привет, Хабр! Меня зовут Никита Ильин, и я занимаюсь разработкой архитектуры BI-платформы Visiology. Сегодня мы поговорим про оптимизацию ClickHouse — ведущей СУБД, которую все чаще используют для решения задач аналитики на больших объемах данных. В этой статье я расскажу, почему важно оптимизировать ClickHouse, в каких направлениях это можно делать, и почему разумный подход к размещению информации, кэшированию и индексированию особенно важен с точки зрения производительности BI-платформы. Также мы поговорим о том, к каким нюансам нужно готовиться, если вы решаете оптимизировать CH самостоятельно, сколько времени и сил может потребовать этот процесс и почему мы решили “зашить” в новый движок ViQube 2 десятки алгоритмов автоматической оптимизации.

Бесспорно, ClickHouse — очень гибкая и высокопроизводительная СУБД с колоночным типом хранения. Она прекрасно подходит для решения целого ряда задач и горячо любима российскими разработчиками, так как распространяется по лицензии Apache 2.0. Как опенсорсный продукт ClickHouse позволяет заменить множество других систем, у нее есть важные для аналитического хранилища больших данных плюсы:
В ClickHouse реализовано колоночное хранение, что позволяет ему быть эффективным в сценариях анализа данных
По емкости и производительности система на базе ClickHouse может быть сопоставима с ПАК на базе SAP HANA или Oracle Exadata, но при этом работает на обычном железе
ClickHouse позволяет загружать данные без остановки и перезагрузки, фактически “заливая” информацию с моментальным отображением на дашбордах
В общем, как только мы поняли, что потребности в аналитике BigData будут только нарастать, приступили к переработке ядра Visiology, чтобы “зашить” ClickHouse со всеми его преимуществами внутрь системы. И скажу честно, у нас на это ушло больше двух лет работы моей команды, но и сейчас мы продолжаем производить тюнинг движка на основе Clickhouse под типовые задачи аналитики, потому что…
Не все так просто!
Впрочем, удивляться тут нечему. Разумеется, в мире нет такого опенсорсного продукта, который лучше всех и может делать все что угодно без доработок. Так же обстоят и дела с ClickHouse. Если кто-то будет рассказывать вам, что просто развернул СH, залил в него кучу данных и все это прекрасно работает как аналитическое хранилище данных с внешним подключением к BI-платформе, попросите показать, как это все происходит…ну или просто не верьте, потому что у ClickHouse есть свои ограничения. Например:
Основная проблема — это операции JOIN, которые часто используются в стандартных запросах. В частности, аналитические системы, “привыкшие” работать с PostgreSQL, часто используют JOINы, что при бездумном переносе на CH сразу сводит к минимуму все преимущества по производительности.
В CH нет транзакций как таковых, а SQL-синтаксис хоть и совместим, но отличается. Чтобы работать с CH, используя все преимущества СУБД, нужно провести ревизию всех процессов обращения платформы к базе.
Точечная запись и удаление являются проблематичными задачами в CH. Инкрементальная загрузка также должна быть реализована с умом, иначе добавление каждого элемента будет отнимать непростительно много ресурсов у железа.
Когда вы начинаете деплоить СН на своих мощностях, то неизбежно сталкиваетесь с особенностями опенсорса. Мы встречали в ClickHouse самые разные баги — вплоть до неправильных расчетов. Так что выбор “годной” версии CH или исправления ошибок в коде — задача непростая.
У ClickHouse имеются свои довольно специфичные схемы индексации, которые надо хорошо понимать, и чтобы они вам помогали, а не мешали, нужна соответствующая квалификация. Для "привыкших" к postgresql и строковым СУБД это особенно актуально.
Аналитическое хранилище — это долго и дорого
По этим и некоторым другим причинам, каждый раз создавая аналитическое хранилище, специалисты вкладывают немало ресурсов в тюнинг как схемы данных внутри самого ClickHouse, так и инструментов, которые с ним работают (ручная оптимизация запросов, внешнего кэша и так далее). Более того, следить за развитием КХД также должны дорогостоящие специалисты, которые продолжат оптимизации по мере изменения профилей нагрузок и требований к СУБД.
Все это имеет прямое отношение к работе BI. И прямое доказательство тому — данные свежего рейтинга TAdviser. В действительности, системные интеграторы, лидеры отрасли, зарабатывают значительную часть своих денег, создавая сложные и эффективные КХД (аналитическая часть которых сегодня все чаще запускается на ClickHouse), а уже после этого речь идет о продажах лицензий и внедрении BI. .
Рассмотрим основные оптимизации, которые должны быть реализованы в любом приличном проекте по созданию аналитического хранилища данных на Clickhouse:
Оптимизируем ClickHouse
Загрузка данных в ClickHouse. Процессы загрузки должны быть построены так, чтобы не создавать лишних сложностей для СУБД. То есть нельзя просто взять и перенести 1-в-1 то, что было в Postgres или другом OLTP источнике данных. Было бы легко и хорошо просто скопировать 10 табличек, связанных друг с другом. Но чтобы все работало оптимально нужно менять принципы индексирования и выбирать оптимальные ключи. Производительность снижают:
Не лучшие типы данных для CH
Неоптимизированная для CH схема модели данных
Неверно выбранные ключи
Отсутствие продуманных процессов группировки
Типы данных. В целях достижения более высокой производительности форматы можно менять. Например, если у вас есть две таблицы и настроены связи между ними. По умолчанию они могут быть сохранены как большой Integer. Но если связей не более 200 штук, значит нам нужно хранить всего 200 элементов. Зачем для 200 элементов использовать integer, если можно short integer? Благодаря этому уменьшается объем хранимых данных, ускоряются группировки и быстрее идут JOINы. Другой пример — колонка типа string. При небольшом количестве уникальных значений строчек можно выбрать для нее тип low cardinality. И в этом случае любые запросы будут обрабатываться быстрее. Но для всего этого нужно сначала понять, что подобная оптимизация возможна — то есть выяснить количество связей и убедиться, что в колонке действительно мало уникальных значений.
Дополнительные представления под часто используемые типы аналитических запросов. Заранее готовить представления также очень важно, потому что в BI есть целый набор характерных запросов, выполнение которых подразумевает определенные шаблоны обращения к СУБД. Аналитикам нужны сводные таблицы (то есть — столбцы в строках), данные для виджетов, поддержка иерархичных фильтров, итоги и подитоги на всех уровнях. Для всех этих запросов желательно готовить отдельные представления прямо в самом CH. В идеале нужна предподготволенная структура размещения и дублирования данных. Если ее не предусмотреть, то даже не самые сложные на первый взгляд SQL-запросы могут очень долго выполняться на ClickHouse и потреблять огромное количество памяти и ресурсов CPU.
Кэширование. У ClickHouse есть своя история с кэшированием. Система действительно создает кэш и позволяет быстрее получать доступ к “горячим” данным. И если раньше в CH был только Page-кэш, то в новых версиях уже работает Query-кэш, встроенный в саму СУБД. Более того в ClickHouse есть и другие кэши, например, marks cache, metadata cache и другие.
Но можно сделать работу СУБД еще лучше, если кэшировать агрегаты на лету, кэшировать запросы, которые генерирует пользователь, заранее готовить наборы данных для статичных запросов BI-платформы, создавать отдельные кэши под каждый виджет, который видит на экране пользователь BI-системы. Все это — наукоемкие задача в области алгоритмики. И далеко не все BI инструменты это умеют, а те кто умеют, могут требовать очень детальной настройки этого кэша, если вообще не доработки.
Индексирование. Это и сильная и слабая сторона ClickHouse одновременно. И я могу вам точно сказать, что история с индексацией для задач BI требует особого подхода. Всегда можно сделать еще лучше! Да, чтобы вы ни на оптимизировали, Алексей Миловидов (основатель и CTO ClickHouse) с его огромным опытом и экспертизой, точно выбрал бы индекс лучше, повысил эффективность СУБД, например, еще на 10%. Но время Алексея — бесценно, а стоимость услуг любых опытных специалистов по ClickHouse— на вес золота. Именно поэтому предподготовленные (и постоянно развивающиеся) алгоритмы оптимизации индексирования оказываются предпочтительными. Они позволяют получить 90% эффекта оптимизации прямо из коробки — то есть сразу после развертывания ПО. Такой подход будет давать результаты намного лучше, чем попытки просто запустить ClickHouse и “немного его подкрутить” руками неопытного ИТ-шника, который не погружался глубоко и в ClickHouse, и в тематику BI одновременно, а также позволит избежать огромных расходов на заказную разработку индексов для ClickHouse.
Горизонтальное масштабирование. Как вы знаете, CH cам по себе неплохо умеет работать в кластере. Каждая таблица может реплицироваться, движок ClikHouse сам распределяет данные на таблицы и направляет запросы к нужной.
Но когда речь идет об одновременной загрузке данных и работе пользователей, возникает вопрос —- как сделать так, чтобы в момент загрузки или по истечении времени для всех были видны консистентные данные? Ведь одновременно с их работой идет постоянная сортировка, балансировка, масштабирование? Увы, инструментами “по умолчанию” сделать это не получится, потребуется привлечение разработчика.
Отказоустойчивость. Это еще один очень важный вопрос — ведь аналитика должна работать, даже если один из инстансов СУБД падает. Что делать, если у вас есть 3 сервера, а вы хотите чтобы пользователь даже не заметил, если один из них перестал отвечать? Да, ClickHouse имеет механизмы восстановления, и если одна нода упала, она поднимется и автоматически подгрузит те данные, которые изменились, пока она лежала. Но чтобы направить запросы пользователей к тем нодам, которые работают — требуется дополнительные усилия. Например, можно использовать Chproxy, специальный балансировщик для CH, который не только следит за состоянием узлов и не дает отправлять запросы на “нездоровые” ноды, но также по-умному распределяет запросы между узлами, гарантируя доступ исключительно к новейшей информации. Но, как вы понимаете, Chproxy нужно еще припаять к ClickHouse и настроить его.
ClickHouse - кликхаусом, но какой движок?
Если вы работали с ClickHouse, то прекрасно знаете, что эта СУБД может работать в разных режимах. Все зависит от того, какой движок вы выберете. На уровне движка можно провести оптимизацию пост-обработки данных. При правильной настройке движок перемелет, отфильтрует и посчитает. Если у вас есть очень большая таблица — миллиарды строк — бывает эффективнее заранее подготовить структуры под частые запросы. Пусть у вас есть 100 колонок, но система знает, что одну конкретную колонку часто суммируют по другим 5 колонкам. В этом случае использовать подготовленную структуру будет намного быстрее, чем ходить по всему миллиарду строк каждый раз.
Например, если мы знаем, что две таблицы связаны, причем одна — большая, а вторая — не очень, можно использовать специальный движок — Dictionary. Он работает в режиме “словаря”, сопоставляя данные между таблицами. В принципе, Dictionary можно настроить на любой источник данных, и он автоматически будет их забирать в работу.
Однако в случае с BI, как правило, все намного сложнее. Обычно используется движок MergeTree. Это основной, самый известный движок. Он помогает очень компактно хранить данные, производить их фильтрацию и агрегацию, а также хорош в сжатии и добавлении новых данных в хранилище.
Движок ReplicatedMergeTree — содержит в себе все плюсы MergeTree, но также позволяет реплицировать таблицы на разные сервера автоматически. Это полезно для распределенных и отказоустойчивых систем.
SummingMergeTree — еще один полезный движок. Он автоматически слушает апдейты основного MergeTree и подстраивает структуру так, чтобы ваши запросы работали быстрее. SummingMergeTree на лету генерирует таблицу из 6 колонок. BI-система автоматически шлет запрос в дополнительную колонку и получает ответ быстрее.
Также есть специальные движки, которые позволяют работать с данными из определенных источников (а значит имеющими характерную структуру). В их число входят:
Postgres,
JDBC
File (в т.ч. CSV)
Эти движки ничего не хранят, но помогают интегрироваться, работают как proxy. Фактически они создают окно в другую СУБД. Можно получать данные из Postgres, MySQL, грузить разные файлы, большие объемы данных в формате CSV.
Стоит отдельно отметить движок Join, который позволяет быстро приджойнивать справочники или таблицы с небольшим количеством строк. Если у вас есть миллиардная таблица фактов, а к ней в модели данных привязаны небольшие справочники — отличная идея загрузить их в Join. Он размещает данные в памяти и хранит так, чтобы можно быстро джойнить столбцы. Если загрузить все в MergeTree, в большинстве случаев те же самые процедуры будут работать хуже.
Хардкорные практики ClickHouse показывают, что иногда одну и ту же таблицу имеет смысл хранить с несколькими движками. Можно дублировать таблицы полностью, или загружать в с разными движками только части таблиц – все зависит от конкретной ситуации.
И все это — еще не все! На уровне движков Clickhouse можно долго вести умный разговор и выбирать оптимальные режимы работы. Выбор и настройка движка может привести как к повышению эффективности работы аналитического хранилища, так и к его просадке. Каждый отдельный кейс нужно разбирать в отдельности, что долго, дорого и требует особых компетенций.
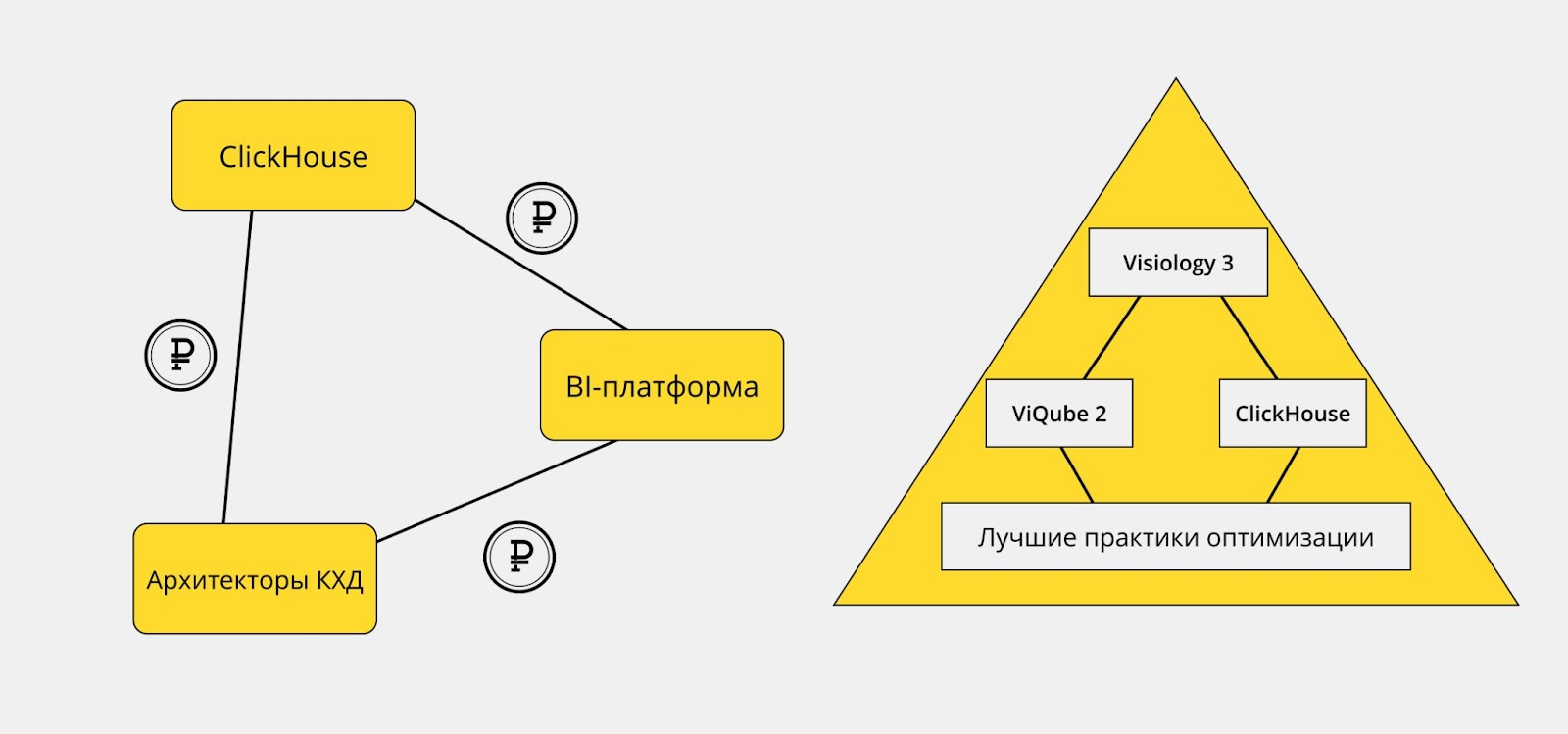
За годы сотрудничества с нашими партнерами-интеграторами мы убедились, что создание аналитического хранилища данных — длительный и сложный процесс. Он может занимать до 6 месяцев (отодвигая дату начала работы с BI), при этом стоимость подобных проектов нередко превышает десятки и сотни миллионов рублей. Это хорошая новость для специалистов с такой квалификацией, но плохая — для бизнеса.
Что мы сделали в Visiology 3
Если вы работали с Visiology 2, то, вероятно, сталкивались с режимом SQL Backend. В этом случае движок ViQube обращается к внешней СУБД и получает данные из нее напрямую. Реализовав поддержку ClickHouse на уровне SQL Backend, мы были свидетелями десятков проектов, когда пользователи подключали ClickHouse через SQL Backend…но не получали желаемого результата, пока не проводили оптимизацию CH. В результате было принято решение внедрить в новый аналитический движок ViQube 2 (на котором работает Visiology 3) лучшие практики оптимизации ClickHouse.
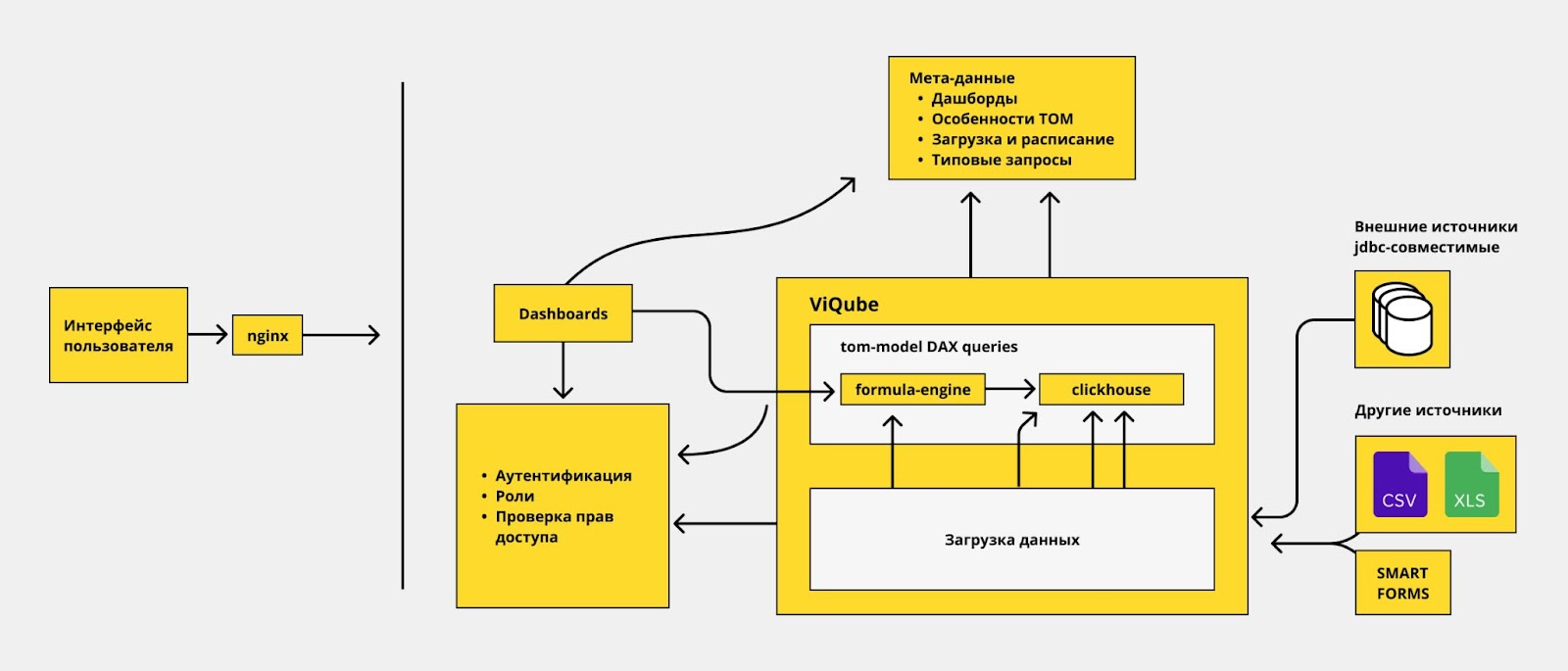
Такой подход позволяет отрабатывать разные типы запросов. Например, у вас может быть большая таблица фактов…но в ней есть 2 колонки, по которым хочется быстро-быстро фильтровать. И тогда разумно сделать в ClikHouse дублирование этих колонок с другим движком.
Более того, полезно бывает загрузить одну и ту же таблицу несколько раз с разными индексами, хранить ее отсортированной по одному ключу, а потом — по другому ключу.
Можно заранее приджойнить таблицу, если вам уже понятны связи между фактами и справочниками, благодаря метамодели (в нашем случае - Tabular Object Model). Для этого используются специальные алгоритмы, определение связей и многое другое.
Построить индекс самостоятельно бывает сложно. Возникают вопросы: “На основе чего сортировать?”, “Как именно оптимизировать таблицы?”. Для решения этих задач создаются специальные алгоритмы, которые отслеживают кардинальность данных, а также связи между таблицами. Индекс, по которому таблицы будут партиционированы, в Visiology 3 выбирается по сотням параметров, и мы потратили немало времени на разработку этих алгоритмов.
Если с оптимизацией отказоустойчивости, масштабированием и подключением новых интерфейсов все более-менее понятно, то принципы построения индексов — это настоящая магия. Как их строить? Какие будут эффективнее? Давайте разберем на примерах.
Мы как раз реализовали в Visiology 3 графическую модель данных (TOM). Пользователь формирует модель данных: загружает таблицы, выстраивает связи между ними. Что-то приходит из Excel, что-то подгружаем из PostgreSQL, где-то подцепили MySQL, какие-то вещи пришли из Smart Forms, а что-то вообще из веба. Модель данных Visiology 3, как и любой серьезной BI-платформы, позволяет выстраивать связи одни к одному, один ко многим, а также иные, нестандартные связи. И если все это бездумно загрузить в CH, на 99% можно гарантировать, что собственные методы индексирования не дадут и 50% эффекта в оптимизации.

Каждая связь — это повод не только для создания еще одного индекса, но и для формирования дополнительных таблиц. Если мы заранее подготовим в ClickHouse структуру данных, которая позволит проводить быструю обработку запросов, это даст хороший буст к производительности.
Еще один момент — оптимизация под типовые запросы. Как вы помните, Visiology 3 поддерживает расчеты с использованием синтаксиса DAX. И для разных выражений, которые могут написать аналитики, лучше будут подходить разные схемы индексов и организации таблиц. Поэтому при загрузке для одной и той же модели данных мы автоматически формируем несколько физических представлений (таблиц). Благодаря этому большинство произвольных запросов DAX работают намного быстрее.
Более того, если не контролировать процесс загрузки, выбор таблиц для каждого запроса на мета-языке (на DAX или его аналоге) остается исключительно на application слое BI-платформы. Если вы подключаетесь с ClickHouse как к внешней СУБД, создавать подобные таблицы не получится. Поэтому другие BI-платформы данных лишены такого преимущества.
Выводы
Вообще говорить о том, что еще можно затюнить в ClickHouse можно долго. Однако факт остается фактом — есть ClickHouse, а есть лучшие практики его использования. И если вы решите самостоятельно оптимизировать хранение данных, вам придется пройти через этот путь своими силами…или заплатить кому-Ыто чтобы он прошел его за вас.
Разрабатывая Visiology 3 мы ставили перед собой цель автоматизировать применение этих самых лучших практик. Поэтому было написано около сотни алгоритмов, которые проверяют, можно ли применять ту или иную оптимизацию, будет ли польза от определенного индексирования или дублирования таблиц именно на ваших наборах данных.
Благодаря этому Visiology 3 из коробки дает высокую производительность аналитических запросов, и мы продолжаем “зашивать” все новые и новые элементы тюнинга в саму архитектуру движка ViQube 2. А пользователи могут взять и просто залить данные во встроенное хранилище ViQube 2 — хоть из таблиц Excel, хоть из СУБД Postgres — алгоритмы оптимизации сами разложат эти данные и будут проводить с ними дополнительные манипуляции по мере того, как станут ясны ваши паттерны работы с этими данными.
Подобный подход как минимум экономит 3-6 месяцев на разработку и кастомизацию хранилища, позволяет не держать в штате дорогостоящего специалиста по архитектуре КХД (потому что несколько таких есть у нас), но при этом дает серьезный прирост в производительности — по различным оценкам вплоть до 10 раз по сравнению с не оптимизированным ClickHouse. Кстати, недавно об этом недавно рассказывал эксперт по высоконагруженным внедрениям Visiology 3 — Сергей Орловский из Ланит. Его команда как раз успешно решила задачу аналитики на больших объемах меняющихся данных на базе Visiology 3.
А вам приходилось оптимизировать ClickHouse? Вы сталкивались со снижением производительности из-за несоответствия структур данных архитектуре хранилища? Поделитесь в комментариях.
