

Yandex Query Language (YQL) — универсальный декларативный язык запросов к системам хранения и обработки данных, разработанный в Яндексе. А ещё это один из самых нагруженных сервисов: YQL ежедневно обрабатывает около 800 петабайт данных и 600 000 SQL-запросов, и эти показатели постоянно растут.
Изначально YQL основывался на операциях MapReduce, которые эффективны для больших данных. Но для средних объёмов данных (до 50 Гб, которые составляют около 60% запросов) этот подход оказался неоптимальным, потому что нужно было обмениваться данными между операциями через диск. Поэтому разработчики создали новый более гибкий стриминговый движок, который значительно ускоряет обработку данных за счёт выполнения всех вычислений в памяти.
В этой статье я хочу рассказать о подходах и технологиях в разработке систем для обработки данных на примере YQL. Основное внимание я уделил переходу от MapReduce к стриминговому движку, который обеспечивает более эффективную обработку данных, вмещающихся в память, и который доступен в опенсорсе.
С чего мы начинали
История создания YQL началась с понимания потребности в едином высокоуровневом языке запросов, чтобы унифицировать доступ к различным системам хранения и обработки данных в Яндексе. YQL разработали как универсальный декларативный язык, чтобы упростить работу с типовыми абстракциями и обеспечить поддержку существующих данных и вычислительных систем в компании. Параллельно с разработкой YQL проводился переход на новую систему MapReduce (YT), что также влияло на требования к YQL. Подробнее об этом можно прочитать в этой статье.
В YQL SQL-запрос преобразуется в серию MapReduce-операций. Каждая такая операция обрабатывает данные и записывает результат на диск, который затем используется следующей операцией в цепочке. Это означает, что результат каждого шага (Map или Reduce) сохраняется, обеспечивая входные данные для последующих шагов обработки, что поддерживает последовательное выполнение сложных запросов. На диаграмме показан процесс, где SQL-движок инициирует MapReduce-операции, которые обмениваются данными через диск. Каждая операция ожидает завершения предыдущей перед стартом. Хотя на схеме отображены три операции (Map, Reduce, Reduce), в реальности их количество может варьироваться в зависимости от конкретного SQL-запроса.
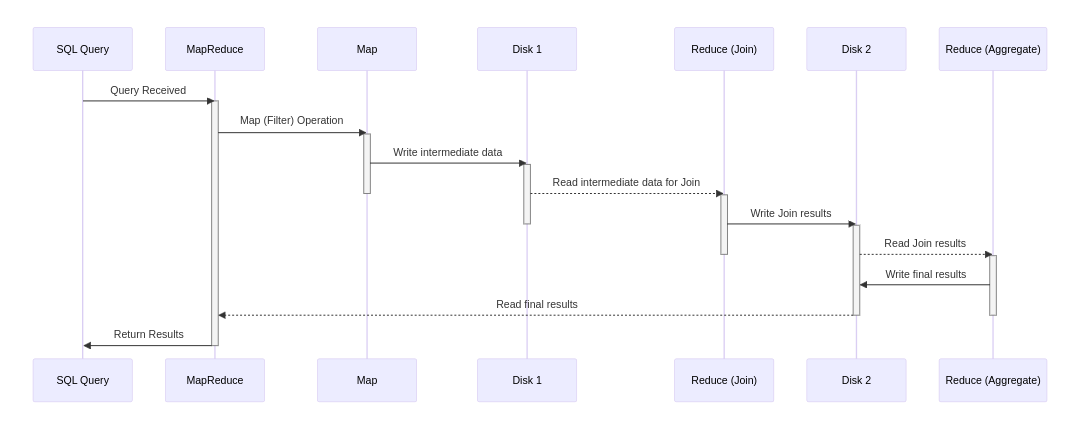
Такой подход может быть неэффективным для данных небольшого объёма, потому что процесс записи результатов каждой операции на диск и последующее их чтение вызывает задержки из-за операций ввода-вывода. Кроме того, каждая операция MapReduce требует планирования, что добавляет время на обработку — и оно становится значительным при малых объёмах данных.
Однако при работе с большими объёмами данных, где время обработки значительно превышает время задержек, эти накладные расходы становятся относительно меньше и, следовательно, более приемлемыми. Поэтому MapReduce хорошо подходит для масштабных вычислений, несмотря на его недостатки для обработки меньших объёмов данных.
К моменту разработки нашего стримингового движка в индустрии уже существовали подобные технологии обработки данных, такие как Apache Spark. Мы не стремились изобретать что-то совершенно новое, а скорее использовали для создания своего решения проверенные идеи и концепции уже известные в сфере больших данных.

В стриминговых движках данные обрабатываются блоками в режиме непрерывного потока. Эти блоки данных последовательно проходят через различные этапы обработки, включая чтение, преобразование (аналогично операции Map в MapReduce), агрегацию (аналогично операции Reduce) и запись результатов. Этапы обработки выполняются параллельно, позволяя системе эффективно обрабатывать данные в реальном времени.
С нашей стороны основные требования к новому стриминговому движку YQL были такими:
Прозрачность для пользователя. Система автоматически выбирает между MapReduce и стриминговым движком, оптимизируя выбор в зависимости от SQL-запроса и объёма входных данных.
Совместимость с данными. Движок должен эффективно работать с теми же данными, что и MapReduce, без необходимости их перекладывать, трансформировать или переформатировать.
То есть с точки зрения пользователя система остаётся прежней, но когда запросы подходят для обработки стриминговым движком, они выполняются значительно быстрее.
Как работает новый движок
Построение плана запроса
Для анализа высокоуровневой архитектуры нового SQL-движка YQL, рассмотрим типичный SQL-запрос:
select c_name, sum(o_totalprice) as totalprice from orders
join customer on o_custkey = c_custkey
where o_orderstatus = 'O' group by c_name
order by totalprice desc limit 5Этот запрос агрегирует данные по клиентам и их заказам, фильтруя и сортируя результаты.

Движок начинает с парсинга SQL-запроса и построения плана выполнения. Ранее план YQL состоял из MapReduce-операций, но сейчас он представлен в виде графа, разделённого на стейджи и таски. Каждый таск внутри одного стейджа выполняет одну и ту же программу, возможно, с разными параметрами. Например, на нижнем уровне графа находятся стейджи чтения, где каждый таск читает определённые диапазоны строк. Фильтры, как в примере с o_orderstatus = 'O', могут быть интегрированы непосредственно в стейджи чтения, что повышает эффективность обработки запроса.
После стейджей чтения в плане выполнения следует стейдж join, который использует алгоритм Grace Join. Этот алгоритм хорошо подходит для распараллеливания по таскам. Каждый таск обрабатывает строки с одинаковым хэшем ключа join, что делает процесс эффективным и масштабируемым. Этот подход позволяет оптимально распределить нагрузку и обработать большие объёмы данных в распределенной системе.
После стейджа join идёт стейдж, который отвечает за агрегацию данных и выделение топ-5 результатов. На этом стейдже строки распределяются по таскам на основе значения хэша ключа группировки: в данном случае — c_name.
И финальный стейдж, предназначенный для формирования итогового результата, всегда состоит из одной таски. В этом случае она отвечает за выборку топ-5 результатов, окончательно суммируя и сортируя данные в соответствии с запросом.
Использование акторной модели вычислений
Таски в новом SQL-движке YQL выполняются в распределённой системе, используя акторную модель вычислений, которая реализуется библиотекой actors. Для каждой таски создаётся актор (ComputeActor), который может взаимодействовать с другими акторами по сети. Они запускаются в специальных джобах, для деплоя которых используется система YTsaurus. Изначально она была предназначена для MapReduce-операций, но разработчики смогли адаптировать её и для vanilla operations — то есть операций, предназначенных для запуска произвольного кода, включая сетевые сервисы.
Решаем проблемы совместимости кода и изоляции запросов
Следует отметить, что низкоуровневая программа, которая исполняется внутри таски, зависит от ревизии кода, которым она создана. То есть нельзя создать план запроса с тасками одной версии кода, а исполнять на распределенной системе — другой. Также нужно уметь отделять друг от друга таски разных пользователей, так как в нашей системе возможны запросы такого вида:
$f=Python3::f(@@
def f(x):
"""
Callable<(Int32)->Int32>
"""
import ctypes
print(ctypes
.cast(1, ctypes.POINTER(ctypes.c_int))
.contents)
return 0
@@);
select $f(0);В этом примере пользователь исполняет SQL с интегрированным python-скриптом. У нас нет особых ограничений для подобных скриптов, поэтому в этом случае пользователь с помощью библиотеки ctypes сделал dereference невалидного указателя. В итоге он получит примерно такой результат:
Container killed by signal: 11 (Segmentation fault)
?? at .../b4382c8e-78fcb74c-519140b6-33:0:0
Simple_repr at .../_ctypes.c:4979:12
PyObject_Str at .../object.c:492:11
PyFile_WriteObject at .../fileobject.c:129:17
builtin_print at .../bltinmodule.c:2039:15
cfunction_vectorcall... at .../methodobject.c:443:24
PyObject_Vectorcall at .../pycore_call.h:92:11
_PyEval_EvalFrameDefault at .../ceval.c:0:0
…Если один бинарник исполняет таски разных пользователей, то такое поведение может привести к печальным последствиям — запрос одного пользователя повалит запросы других.
Для MapReduce-исполнения обе проблемы решались автоматически. Во-первых, при запуске MapReduce-операции при необходимости загружался бинарник правильной версии. Во-вторых, изоляцию джобов друг от друга обеспечивает сама MapReduce-система YTsaurus «из коробки».
Изоляция вычислительного кода в контейнерах
Для решения проблем изоляции и совместимости версий в YQL, мы разделили каждую таску на две части. Одна часть — это ComputeActor, который отвечает за взаимодействие с другими тасками. Вторая часть — вычислительный компонент, который был размещён в отдельном процессе внутри контейнера Porto (или Docker, но в YtSaurus уже была интеграция с Porto). Общение между ComputeActor и вычислительной частью в контейнере осуществляется через Unix pipes, что обеспечивает необходимую изоляцию и безопасность.

Обновление системы
В нашей архитектуре именно вычислительная часть зависит от конкретной ревизии кода, и благодаря новой схеме она может обновляться так часто, как это требуется. Таким образом, рядом с процессом, который обслуживает таски, могут находиться контейнеры с разными версиями кода. Vanilla jobs обновляются реже с помощью rolling update, так как код ComputeActor меняется не так часто. Мы предзапускаем контейнеры с последней версией бинарника для ускорения процесса, а затем распределяем таски по этим контейнерам. Это позволяет сократить время запуска и предоставить более гибкую и эффективную систему исполнения запросов.
Для обновления управляющей части системы, отвечающей за создание плана запроса и его распределение в vanilla operations, используется метод постепенного перехода. Текущие процессы переводятся в режим завершения работы, в то время как рядом запускаются процессы новой ревизии. Новые запросы обрабатываются уже на этих новых процессах, а старые постепенно завершают своё выполнение. Это позволяет обновлять систему без остановки и без влияния на работу пользователей, гарантируя бесшовный процесс обновления.
Новый стриминговый движок стал использоваться не только в самом YQL, но и нашёл применение в наших продуктах: в YDB и в сервисе Yandex Cloud. Это расширение области применения движка позволило улучшить обработку и анализ данных как внутри компании, так и для пользователей облачных сервисов.
Код движка YQL был выпущен в открытый доступ вместе с YDB. Вы можете опробовать его без установки самого YDB, используя следующие инструменты:
dqrun для обработки SQL-запросов и построения плана,
worker_node для запуска ComputeActor с возможностью выделить вычислительный код в отдельный процесс,
service_node — управляющий процесс, который запускает готовый план запроса.
Эти инструменты позволяют работать с SQL-запросами на основе файлов в формате Parquet без необходимости развертывать YDB. Делитесь опытом использования в комментариях.
