
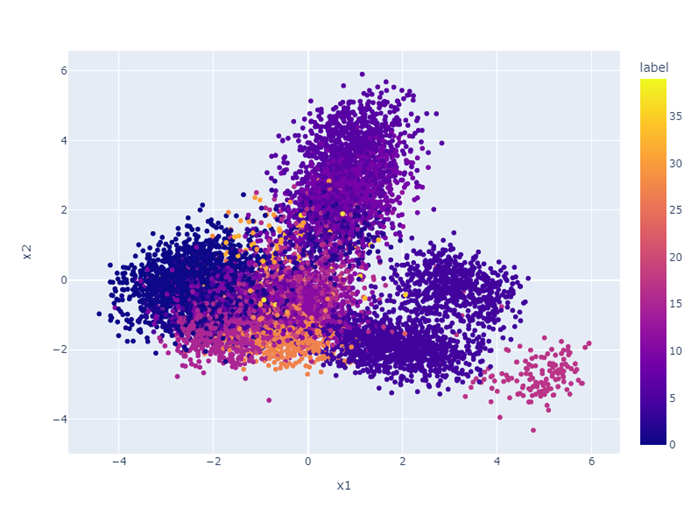
В статье я покажу как искать зависимости и проверять гипотезы. Мы познакомимся с данными и реализуем предсказание на основе одной логики=)

Преподаватель-исследователь
В статье я покажу как искать зависимости и проверять гипотезы. Мы познакомимся с данными и реализуем предсказание на основе одной логики=)
Обработка естественного языка одно из востребованных направлений машинного обучения, которое постоянно развивается. В 2018 году компания Google представила новую модель - BERT, сделавшую прорыв в области обработки естественного языка. Несмотря на то, что сейчас у BERT много конкурентов, включая модификации классической модели (RoBERTa, DistilBERT и др.) так и совершенно новые (например, XLNet), BERT всё ещё остается в топе nlp-моделей.

Во многих популярных курсах машинного и глубокого обучения вас научат классифицировать собак и кошек, предсказывать цены на недвижимость, покажут еще десятки задач, в которых машинное обучение, вроде как, отлично работает. Но вам расскажут намного меньше (или вообще ничего) о тех случаях, когда ML-модели не работают так, как ожидалось.
Частой проблемой в машинном обучении является неспособность ML-моделей корректно работать на большем разнообразии примеров, чем те, что встречались при обучении. Здесь идет речь не просто о других примерах (например, тестовых), а о других типах примеров. Например, сеть обучалась на изображениях коровы, в которых чаще всего корова был на фоне травы, а при тестировании требуется корректное распознавание коровы на любом фоне. Почему ML-модели часто не справляются с такой задачей и что с этим делать – мы рассмотрим далее. Работа над этой проблемой важна не только для решения практических задач, но и в целом для дальнейшего развития ИИ.

Как при помощи языка программирования Пайтон и библиотеки Samila создавать красивые изображения, даже с минимальными усилиями.

Data Science — это не только данные о клиентах. К старту нашего флагманского курса рассмотрим пример геопространственной семантической сегментации, где с помощью данных цифровой модели рельефа отобразим шлаковые конусы на Гавайях.

“С бедностью тесно связано отсутствие социальной мобильности. Я сам это видел: вам не нужно расти богатым или даже принадлежать к верхнему среднему классу, чтобы разбогатеть как основатель стартапа, но очень немногие успешные основатели выросли в крайней бедности ”. (Источник)

Привет, я Денис Соколов, руковожу R&D в Zenia — это платформа для йоги и фитнеса, которая использует ИИ для трекинга поз человека (подробнее об этом — в другой моей статье). Наша система распознавания работает на трёх платформах — iOS, Android, Web. В этой статье поговорим о ключевых отличиях между ними. Расскажу, как устроена подготовка моделей компьютерного зрения к использованию, какими фреймворками пользуемся для запуска на устройствах клиентов, какие сложности решали и чем остались довольны. Если вы занимаетесь запуском нейронных сетей на мобильных устройствах или вебе, статья для вас.
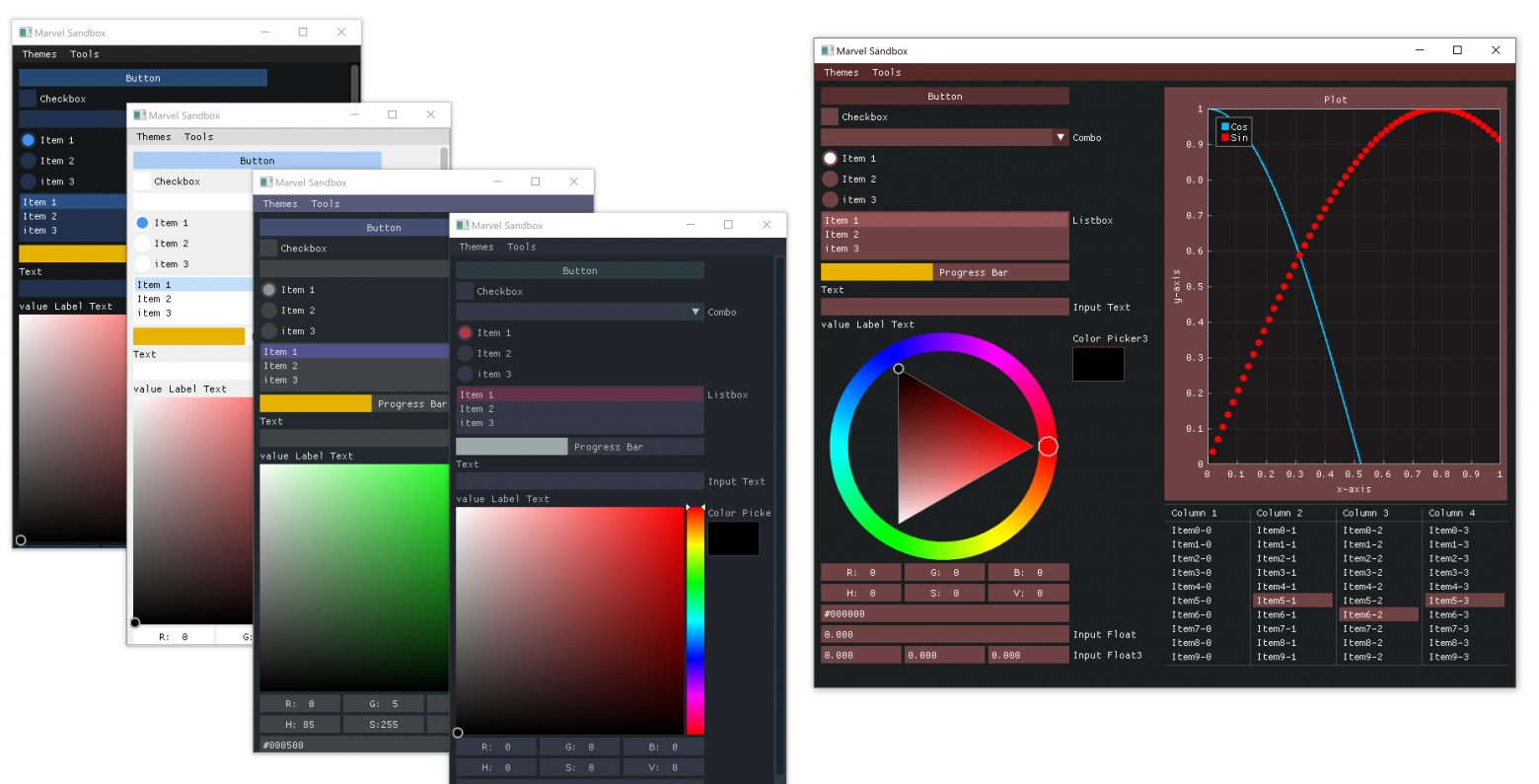
Dear PyGui принципиально отличается от других фреймворков GUI Python. Рендеринг на GPU, более 70 виджетов, встроенная поддержка асинхронности — это лишь некоторые возможности Dear PyGui. Руководством по работе с этим пакетом делимся к старту курса по разработке на Python.

Orchest содержит Jupyter Notebook, не требует ациклических ориентированных графов, а работать можно на Python, R и Julia. Также можно запустить сервис VSCode, метрики TensorBoard — и это далеко не всё. Руководством о создании конвейера ML при помощи Orchest делимся к старту флагманского курса по Data Science.
В стремлении прояснить языковые модели Transformer с помощью пакета Ecco авторы показывают механизм генерации предложений внутри предварительно обученной языковой модели. После генерации предложения возможно визуализировать представление о том, как модель пришла к каждому слову — речь идёт о столбце на рисунке выше. Строки — это слои модели. Чем темнее элемент строки, тем выше ранг токена в слое. Слой 0 расположен на самом верху. Слой 47 — в самом низу. К старту курса о машинном и глубоком обучении показываем и рассказываем о том, как мыслит GPT.
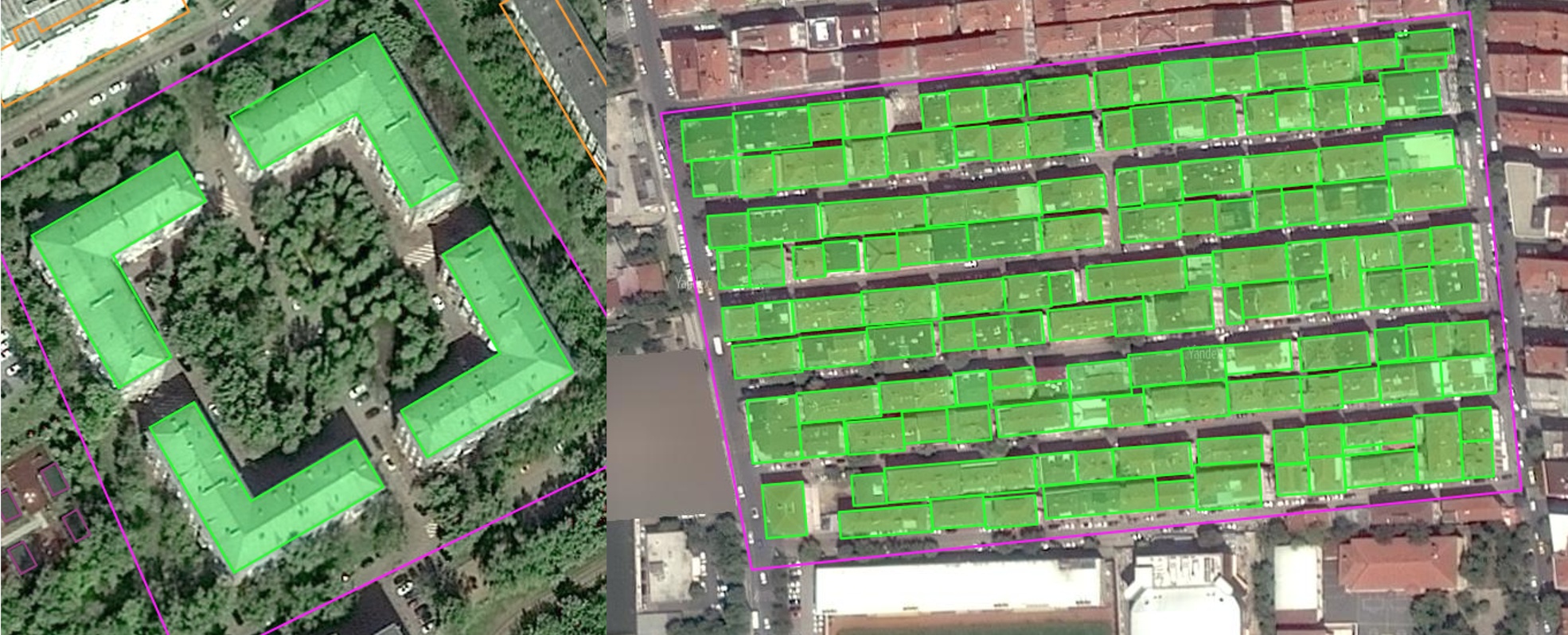

Преподаватели, работающие в российских ВУЗах, периодически сталкиваются с необходимостью предоставить администрации список своих научных и учебно-методических работ. Например, для (пере)избрания на должность, присвоения звания и т. д. Формат представления информации, форма № 16, разработан невесть когда и до сих пор используется в бюрократических недрах Министерства Науки и Высшего Образования РФ. Мне стало лень заполнять эту форму вручную и я написал небольшой python сценарий, который генерирует нужную таблицу на основе информации, полученной из научной электронной библиотеки elibrary.ru. Возможно, кому-то это будет интересно, так что ниже приведено описание этой процедуры...

Эффективность экспериментов базируется на организационной и технической стороне работы. Начинающие инженеры, которые занимаются нейросетями и обучают модели, совершают достаточно типовые ошибки. Например, увлекаясь перебором и тюнингом моделей машинного обучения, упускают важнейший этап подготовки данных, не задумываются о том, как сделать эксперименты воспроизводимыми, а этап программирования быстрым. Давайте поговорим об этом - как эффективно проводить эксперименты с нейросетями.

Если у вас есть проект с интенсивной обработкой данных глубокими моделями (или еще нет, но вы собираетесь его создать), то вам будет полезно познакомиться с приемами по повышению их производительности и уменьшению затрат на покупку / аренду вычислительных мощностей. Тем более, что многие из приемов сейчас выполняются буквально за несколько кликов мышкой, но при этом позволяют повысить производительность на порядок. В этом посте мы рассмотрим какие оптимизации бывают, установим Docker на Windows 10 и запустим DL Workbench, измерим производительность инференса без оптимизации и с применением оных.
Меня зовут Васильев Евгений, и команда в составе Дмитрия, Вячеслава и меня заняла 2 место на хакатоне "Цифровой прорыв" в Нижнем Новгороде в кейсе Ростелекома: Разработка системы мониторинга за поведением студента во время экзамена, и забрала приз в 100 000 рублей. После просмотра решений всех команд и возникла идея для данной заметки с громким названием.


Кустикова Валентина, Васильев Евгений, Вихрев Иван, Дудченко Антон, Уткин Константин и Коробейников Алексей.
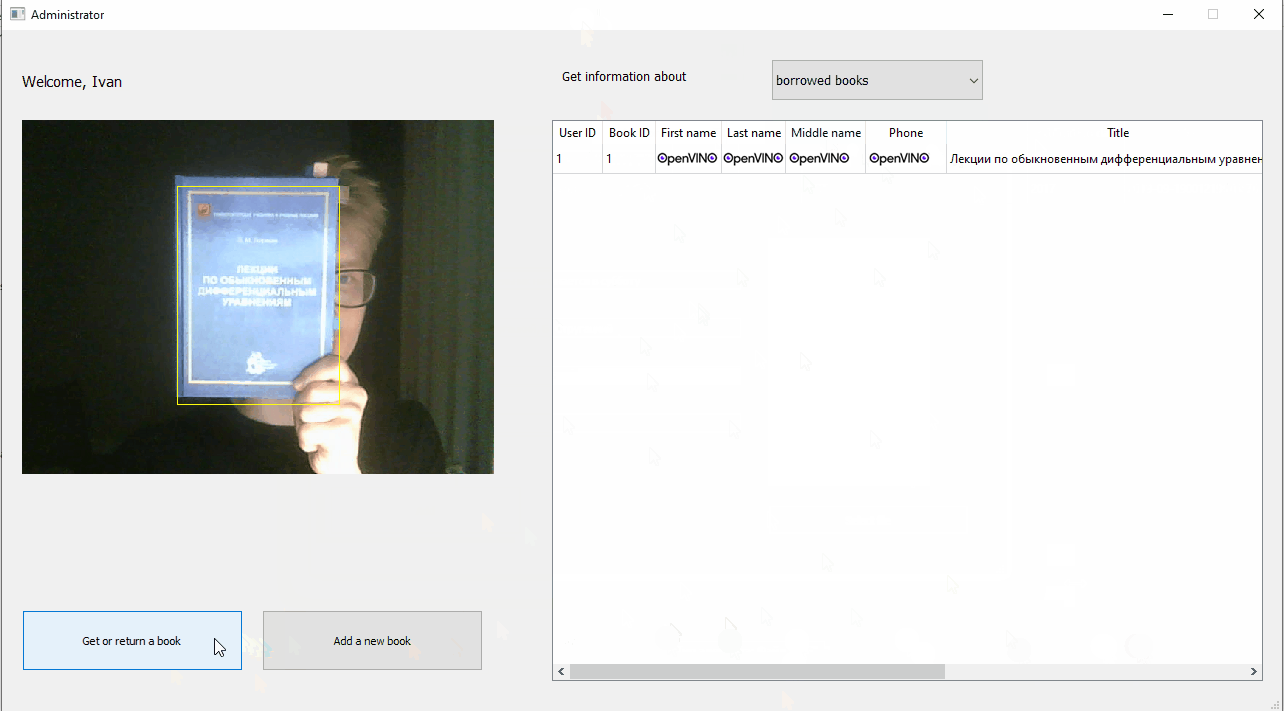
Intel Distribution of OpenVINO Toolkit — набор библиотек для разработки приложений, использующих машинное зрение и Deep Learning. А эта статья расскажет, как создавалось демо-приложение «Умная библиотека» на основе библиотеки OpenVINO силами студентов младших курсов. Мы считаем, что данная статья будет интересна начинающим свой путь в программировании и использовании глубоких нейронных сетей.