
Или: Как переход от публикации P-значений к публикации функций правдоподобия поможет справиться с кризисом воспроизводимости: личное мнение Элиезера Юдковского.

Комментарий переводчика: Юдковский, автор HPMOR, создатель Lesswrong и прочая и прочая, изложил свою позицию по поводу пользы байесовской статистики в естественных науках в форме диалога. Прямо классический такой диалог из античности или эпохи возрождения, с персонажами, излагающими идеи, обменом колкостями вперемешку с запутанными аргументами и неизбежно тупящим Симплицио. Диалог довольно длинный, минут на двадцать чтения, но по-моему, он того стоит.
Модератор: Добрый вечер. Сегодня в нашей студии: Учёный, практикующий специалист в области… химической психологии или чего-то типа того; его оппонент Байесовец, который намерен доказать, что кризис воспроизводимости в науке можно как-то преодолеть с помощью замены P-значений на что-то из Байесовской статистики…
Студент: Извините, как это пишется?
Модератор:… и, наконец, ничего не понимающий Студент справа от меня.
Комментарий переводчика: Юдковский, автор HPMOR, создатель Lesswrong и прочая и прочая, изложил свою позицию по поводу пользы байесовской статистики в естественных науках в форме диалога. Прямо классический такой диалог из античности или эпохи возрождения, с персонажами, излагающими идеи, обменом колкостями вперемешку с запутанными аргументами и неизбежно тупящим Симплицио. Диалог довольно длинный, минут на двадцать чтения, но по-моему, он того стоит.
Дисклеймеры
Если вы ещё не знакомы с правилом Байеса, на сайте Arbital есть подробное введение.
- Этот диалог был написан сторонником байесовского подхода. Реплики Учёного в нижеприведённом диалоге могут и не пройти идеологический тест Тьюринга на фреквентизм. Возможно, что они не отдают должное аргументам и контраргументам сторонников частотного подхода к вероятности.
- Автор не рассчитывает, что описанные ниже предложения будут приняты широким научным сообществом в ближайшие десять лет. Тем не менее, это стоило написать.
Если вы ещё не знакомы с правилом Байеса, на сайте Arbital есть подробное введение.
Модератор: Добрый вечер. Сегодня в нашей студии: Учёный, практикующий специалист в области… химической психологии или чего-то типа того; его оппонент Байесовец, который намерен доказать, что кризис воспроизводимости в науке можно как-то преодолеть с помощью замены P-значений на что-то из Байесовской статистики…
Студент: Извините, как это пишется?
Модератор:… и, наконец, ничего не понимающий Студент справа от меня.




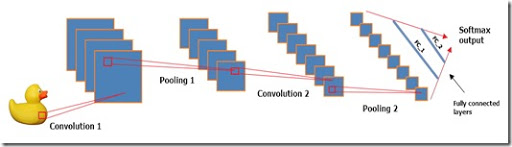
 Data Science — это совокупность понятий и методов, позволяющих придать смысл и понятный вид огромным объемам данных.
Data Science — это совокупность понятий и методов, позволяющих придать смысл и понятный вид огромным объемам данных.


{kind=link}