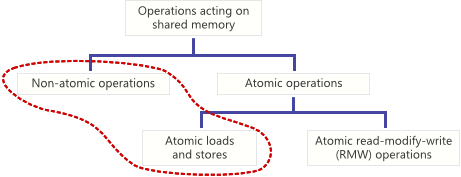
Предисловие
Как оказалось, не так много людей знают что такое DNSSec, для чего он нужен, для чего нет и стоит ли его внедрять у себя. Так как на русском языке информации на этот счет мало, я постараюсь пролить свет на эти вопросы.

Пользователь


Всем салют!
Хочу рассказать вам историю о том, как я начинал с уровня — «не могу решить даже 1 easy задачу из 10» до уровня — «могу решить каждую вторую medium задачу» и прошел несколько coding сессий в таких компаниях как Meta, Booking, Careem, Avito...
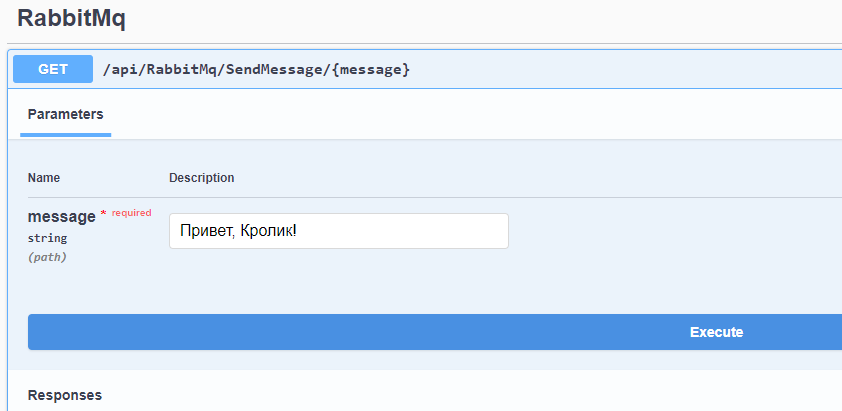
RabbitMQ – это брокер сообщений, служба, отвечающая за обмен сообщениями между разными программными сервисами.
RabbitMQ держит сообщения в очереди (Queue), которая является именованным буфером, хранящим адресованные ему сообщения.
Программа, посылающая сообщения в очередь RabbitMQ, называется поставщиком (Producer).
Программа, принимающая сообщения, называется подписчиком (Consumer). Такие программы подписываются на события поступления сообщения в очередь, и всегда находятся в ожидании новых сообщений.
Множество поставщиков могут отправлять сообщения в очередь, и множество подписчиков могут считывать сообщения из очереди.
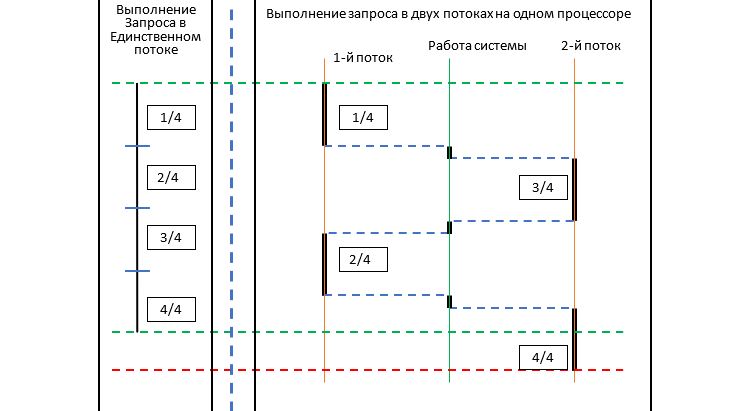
Чтобы написать продолжение предыдущей статьи мне пришлось перечитать множество материалов, имеющих отношение к теме. Я так и не нашел пример хоть какой‑то практической задачи, определяющей хоть какие‑то детали, имеющие отношение к возможности распараллеливания. По большому счету все пишут о том, что распараллеливание улучшает производительность, и это в общем‑то все к чему нужно стремиться с невнятными оговорками о том, что при этом можно получить кучу проблем.
Но хуже того, что никто не рассматривает практических задач, для которых можно или нужно применять многопоточность никто не вспоминает что многопоточность придумали в те времена, когда никто не рассчитывал на то, что процессоры могут быть многоядерными.
Мне кажется нельзя считать что вы до конца понимаете концепцию многопоточности (Multithreading/ Concurrency) если вы не понимаете когда (для каких задач) ее можно и/или нужно использовать на однопроцессорной машине, 2-х процессорной, N‑процессорной машине и от чего это зависит.

Несмотря на то, что с предыдущей статьей-переводом мы выяснили что перевод уже есть на Хабре я рискну продолжить анализ этой работы.
Теперь это НЕ перевод. Это моя интерпретация тех частей содержания первой половины Поста: Как на самом деле Async/Await работают в C#, которые мне показались заслуживающими внимания в этой работе, с моими пояснениями относительно того почему у меня возникла именно такая интерпретация материала.
Судя по количеству просмотров, работа вызывает интерес, но пробиться сквозь нагромождение терминов трудно даже для подготовленного читателя, как мне кажется. Я хочу попробовать перевести не с английского на русский, а с некоторого кулуарно-профессионального на какой-то более доступный язык. Не знаю, насколько доступный, надеюсь получить некоторый отклик, который поможет мне понять, насколько у меня это получилось. Заранее хочу сказать, что автор действительно изложил как или во что компилируются конструкции Async/Await и, соответственно, как они работают изнутри. Проблема в том, что автору пришлось написать большую подготовительную часть чтобы подвести к изложению этого внутреннего устройства Async/Await. И мне, волей неволей, придется пройтись по всему что предваряет, собственно, основную идею в реализации Async/Await. Поэтому запаситесь терпением либо начинайте читать сразу последнюю часть.
Это обзор только первой половины Поста, возможно по результатам анализа второй половины или по вашим замечаниям мне придётся пересмотреть какие-то мои выводы, я не претендую на абсолютное знание.
Дисклеймер 1
Я подозреваю что некоторых может шокировать, что я объясняю высокие проблемы, связанные с асинхронными вызовами самыми простыми или даже приземленными словами, поэтому не рекомендую читать эту статью слишком чувствительным натурам.
Добрый день, Хабр! Хочу поделиться учебником-справочником знаний, которые мне удалось собрать по RabbitMQ и сжать в короткие рекомендации и выводы.

Мы все были там: Вы работали над множеством изменений одновременно, некоторые из которых не имели ничего общего. Для удобства вы решили объединить все эти изменения в один коммит и на этом закончить. Но хотя это может показаться заманчивым, на самом деле это может привести к большим проблемам в дальнейшем. Большие коммиты могут:
 Недавно мы в Voximplant улучшали авторизацию в SDK. Посмотрев на результаты, я несколько опечалился, что вместо простого и понятного токена их стало две штуки: access token и refresh token. Которые мало того что надо регулярно обновлять, так еще документировать и объяснять в обучающих материалах. Помня, что в OAuth два токена нужны в основном из-за разных сервисов, на которых они используются (даже вопрос на stackoverflow есть), а у нас такой сервис один, я несколько офигел и пошел на второй этаж вытрясать души из разработчиков. Ответ получился неожиданным. Его нет на stackoverflow. Зато он есть под катом.
Недавно мы в Voximplant улучшали авторизацию в SDK. Посмотрев на результаты, я несколько опечалился, что вместо простого и понятного токена их стало две штуки: access token и refresh token. Которые мало того что надо регулярно обновлять, так еще документировать и объяснять в обучающих материалах. Помня, что в OAuth два токена нужны в основном из-за разных сервисов, на которых они используются (даже вопрос на stackoverflow есть), а у нас такой сервис один, я несколько офигел и пошел на второй этаж вытрясать души из разработчиков. Ответ получился неожиданным. Его нет на stackoverflow. Зато он есть под катом.
Так получилось, что я провожу довольно много собеседований на должность веб-программиста. Один из обязательных вопросов, который я задаю — это чем отличается INNER JOIN от LEFT JOIN.
Чаще всего ответ примерно такой: "inner join — это как бы пересечение множеств, т.е. остается только то, что есть в обеих таблицах, а left join — это когда левая таблица остается без изменений, а от правой добавляется пересечение множеств. Для всех остальных строк добавляется null". Еще, бывает, рисуют пересекающиеся круги.
Я так устал от этих ответов с пересечениями множеств и кругов, что даже перестал поправлять людей.
Дело в том, что этот ответ в общем случае неверен. Ну или, как минимум, не точен.
ORM Entity Framework Core с каждой версией становится все более и более богатой на фичи. Команда разработчиков тратит много времени на перфоманс и вероятно простое обновление Nuget-пакета уже приведет к некоторому бусту, который почувствуют пользователи. Но сегодня я хочу рассказать о совершенно конкретной фиче: это новый режим запросов — "разделённые запросы" или "split queries" в оригинале.

Привет! Меня зовут Михаил Боровиков, я тимлид команды, которая отвечает за систему процессинга заказов Lamoda — Orders Management. Эта система, словно «сердце» Lamoda, через которое проходит самый важный для бизнеса шаг — оформление заказа.
Раньше система представляла из себя монолит. Теперь вместо него у нас много отдельных сервисов, которые общаются по сети. В рамках новой схемы взаимодействия сервисов между собой мы и столкнулись с проблемой потери данных в процессе создания заказа, чего допускать в важной для нас системе было категорически нельзя.
Для решения этой проблемы мы выбрали паттерн Outbox. И в этой статье я расскажу, что он из себя представляет, как мы его применили, почему пошли по пути at-least-once и не положились на работу одного брокера сообщений.

Привет всем!
Сразу хочется отметить, что данная статья написана исключительно для людей, начинающих свое путь в изучении SQL и оконных функций. Здесь могут быть не разобраны сложные применения функций и могут не использоваться сложные формулировки определений - все написано максимально простым языком для базового понимания.
P.S. Если автор что-то не разобрал и не написал, значит он посчитал это не обязательным в рамках этой статьи)))
Для примеров будем использовать небольшую таблицу, которая показывает оценки учеников по разным предметам. В БД табличка выглядит следующим образом

Индексы — это первое, что необходимо хорошо понимать в работе SQL Server, но странным образом базовые вопросы не слишком часто задаются на форумах и получают не так уж много ответов.
Роб Шелдон отвечает на эти, вызывающие смущение в профессиональных кругах, вопросы об индексах в SQL Server: одни из них мы просто стесняемся задать, а прежде чем задать другие сначала подумаем дважды.

ASP.NET Core — это мощный и универсальный фреймворк для создания веб-приложений. Он предоставляет широкий набор возможностей для создания надежных и масштабируемых приложений, и одной из ключевых фич, расширяющих его функциональность, являются фильтры действий (Action Filters). Фильтры действий позволяют выполнять код до или после выполнения метода контроллера (или метода действия), что дает возможность добавить в приложение сквозной функционал.
В этой статье мы рассмотрим фильтры действий в ASP.NET Core, разберемся в их типах и научимся создавать пользовательские фильтры для расширения функциональности нашего веб-приложения.