Docker в значительной мере изменил подход к настройке серверов, поддержке и доставке приложений. Разработчики начинают задумываться о том, можно ли архитектуру их приложений разделить на более мелкие компоненты, которые будут запускаться в изолированных контейнерах, что позволит достичь большего ускорения, параллелизации исполнения и надежности. Также Docker решает важную проблему снятия облачного vendor–lock и позволяет легко мигрировать настроенные приложения между собственными серверами и облаками. Все что требуется от сервера, чтобы запустить Docker – более-менее современная ОС Linux с ядром не ниже 3.8.
В этой статье мы расскажем о том, как просто использовать Docker и какие преимущества он даст сисадмину и разработчику. Забудьте про проблемы с зависимостями, запускайте на одном сервере софт, требующий разные дистрибутивы Linux, не бойтесь «загрязнить» систему неправильными действиями. И делитесь наработками с сообществом. Docker решает множество актуальных проблем и помогает сделать IaaS гораздо более похожими на PaaS, без vendor-lock.

На облачных VPS от Infobox мы сделали готовый образ Ubuntu 14.04 с Docker. Получите бесплатную пробную версию (кнопка «Тестировать 10 дней») и начните использовать Docker прямо сейчас! Не забудьте поставить галочку «Разрешить управление ядром ОС» при создании сервера, это требуется для работы Docker. В самое ближайшее время у нас появятся и другие ОС с Docker внутри.
Под катом вы узнаете, что же в Docker настолько воодушевило автора статьи, что за пару дней он перевел свои облачные сервера, автоматизирующие части процесса разработки, в контейнеры Docker.
В этой статье мы расскажем о том, как просто использовать Docker и какие преимущества он даст сисадмину и разработчику. Забудьте про проблемы с зависимостями, запускайте на одном сервере софт, требующий разные дистрибутивы Linux, не бойтесь «загрязнить» систему неправильными действиями. И делитесь наработками с сообществом. Docker решает множество актуальных проблем и помогает сделать IaaS гораздо более похожими на PaaS, без vendor-lock.
На облачных VPS от Infobox мы сделали готовый образ Ubuntu 14.04 с Docker. Получите бесплатную пробную версию (кнопка «Тестировать 10 дней») и начните использовать Docker прямо сейчас! Не забудьте поставить галочку «Разрешить управление ядром ОС» при создании сервера, это требуется для работы Docker. В самое ближайшее время у нас появятся и другие ОС с Docker внутри.
Под катом вы узнаете, что же в Docker настолько воодушевило автора статьи, что за пару дней он перевел свои облачные сервера, автоматизирующие части процесса разработки, в контейнеры Docker.
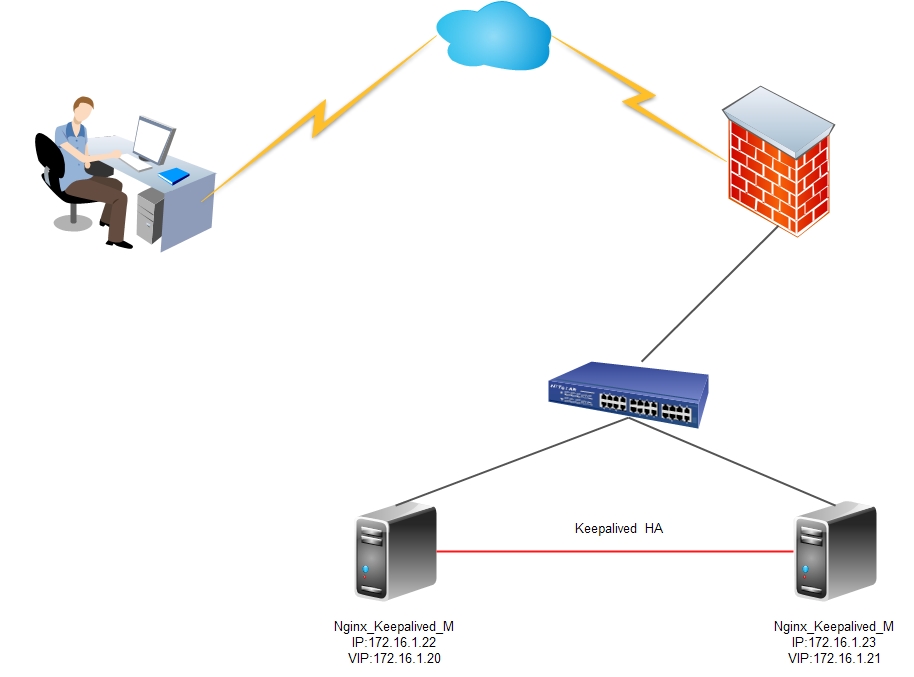
 Назрела необходимость замены медленного rdiff-backup на более шустрое решение для инкрементальных бекапов на удаленый сервер. Сперва рассматривался Rsnapshot, но причине того, что он не умеет без костылей делать бекапы именно на удаленные серверы от него отказались. Прочие аналоги нам также не подошли по тем или иным причинам. Искать что-то готовое на просторах github и допиливать под себя мы не захотели, поэтому было решено написать новый скрипт с нуля своими силами. Главная цель сделать решение для инкрементального бекапа на удаленный сервер схожее с rdiff, но с использованием жестких ссылок rsync.
Назрела необходимость замены медленного rdiff-backup на более шустрое решение для инкрементальных бекапов на удаленый сервер. Сперва рассматривался Rsnapshot, но причине того, что он не умеет без костылей делать бекапы именно на удаленные серверы от него отказались. Прочие аналоги нам также не подошли по тем или иным причинам. Искать что-то готовое на просторах github и допиливать под себя мы не захотели, поэтому было решено написать новый скрипт с нуля своими силами. Главная цель сделать решение для инкрементального бекапа на удаленный сервер схожее с rdiff, но с использованием жестких ссылок rsync.
 Вот и настал тот день, когда пришлось отложить в сторону кукбуки, рецепты, нож шеф-повара и немного позаниматься кукловодством.
Вот и настал тот день, когда пришлось отложить в сторону кукбуки, рецепты, нож шеф-повара и немного позаниматься кукловодством.