
Abstract: Рассказ про некоторые возможности IPv6 на примере конфигурации сложной домашней IPv6-сети. Включает в себя описания мультикаста, подробности настройки и отладки router advertisement, stateless DHCP и т.д. Описано для linux-системы. Помимо самой конфигурации мы внимательно обсудим некоторые понятия IPv6 в теоретическом плане, а так же некоторые приёмы при работе с IPv6.
Вполне понятный вопрос: почему я ношусь с IPv6 сейчас, когда от него сейчас нет практически никакой пользы?
Сейчас с IPv6 можно возиться совершенно безопасно, без каких-либо негативных последствий. Можно мирно разбираться в граблях и особенностях, иметь его неработающим месяцами и nobody cares. Я не планирую в свои старшие годы становиться зашоренным коболистом-консерватором, который всю жизнь писал кобол и больше ничего, и все новинки для него «чушь и ерунда». А вот мой досточтимый воображаемый конкурент, когда IPv6 станет продакт-реальностью, будет либо мне не конкурентом, либо мучительно и в состоянии дистресса разбираться с DAD, RA, temporary dynamic addresses и прочими странными вещами, которым посвящено 30+ RFC. А что IPv6 станет основным протоколом ещё при моей жизни — это очевидно, так как альтернатив нет (даже если бы они были, их внедрение — это количество усилий бОльшее, чем завершение внедрения IPv6, то есть любая альтернатива всегда будет отставать). И что адреса таки заканчиваются видно, по тому, как процесс управления ими перешёл во вторую стадию — стадию вторичного рынка. Когда свободные резервы спекуляций и хомячаяния адресов закончится, начнётся этап суровой консолидации — то есть выкидывание всего неважного с адресов, перенос всех «на один адрес» и т.д. Примерно в это время IPv6 начнёт использоваться для реальной работы.
Впрочем, рассказ не про будущее IPv6, а про практику работы с ним. В Санкт-Петербурге есть такой провайдер — Tierа. И я их домашний пользователь. Это один из немногих провайдеров, или, может быть, единственный в городе, кто предоставляет IPv6 домашним пользователям. Пользователю выделяется один IPv6 адрес (для маршрутизатора или компьютера), плюс /64 сетка для всего остального (то есть в четыре миллиарда раз больше адресов, чем всего IPv4 адресов быть может — и всё это в одни руки). Я попробую не просто описать «как настроить IPv6», но разобрать базовые понятия протокола на практических примерах с теоретическими вставками.
Структура сети:
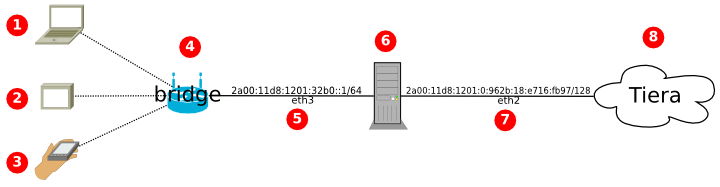
(Оригиналы картинок: github.com/amarao/dia_schemes)
Зачем IPv6?
Вполне понятный вопрос: почему я ношусь с IPv6 сейчас, когда от него сейчас нет практически никакой пользы?
Сейчас с IPv6 можно возиться совершенно безопасно, без каких-либо негативных последствий. Можно мирно разбираться в граблях и особенностях, иметь его неработающим месяцами и nobody cares. Я не планирую в свои старшие годы становиться зашоренным коболистом-консерватором, который всю жизнь писал кобол и больше ничего, и все новинки для него «чушь и ерунда». А вот мой досточтимый воображаемый конкурент, когда IPv6 станет продакт-реальностью, будет либо мне не конкурентом, либо мучительно и в состоянии дистресса разбираться с DAD, RA, temporary dynamic addresses и прочими странными вещами, которым посвящено 30+ RFC. А что IPv6 станет основным протоколом ещё при моей жизни — это очевидно, так как альтернатив нет (даже если бы они были, их внедрение — это количество усилий бОльшее, чем завершение внедрения IPv6, то есть любая альтернатива всегда будет отставать). И что адреса таки заканчиваются видно, по тому, как процесс управления ими перешёл во вторую стадию — стадию вторичного рынка. Когда свободные резервы спекуляций и хомячаяния адресов закончится, начнётся этап суровой консолидации — то есть выкидывание всего неважного с адресов, перенос всех «на один адрес» и т.д. Примерно в это время IPv6 начнёт использоваться для реальной работы.
Впрочем, рассказ не про будущее IPv6, а про практику работы с ним. В Санкт-Петербурге есть такой провайдер — Tierа. И я их домашний пользователь. Это один из немногих провайдеров, или, может быть, единственный в городе, кто предоставляет IPv6 домашним пользователям. Пользователю выделяется один IPv6 адрес (для маршрутизатора или компьютера), плюс /64 сетка для всего остального (то есть в четыре миллиарда раз больше адресов, чем всего IPv4 адресов быть может — и всё это в одни руки). Я попробую не просто описать «как настроить IPv6», но разобрать базовые понятия протокола на практических примерах с теоретическими вставками.
Структура сети:
(Оригиналы картинок: github.com/amarao/dia_schemes)
- 1, 2, 3 — устройства в локальной сети, работают по WiFi
- 4 — WiFi-роутер, принужденный к работе в роле access point (bridge), то есть коммутатора между WiFi и LAN
- 5 — eth3 сетевой интерфейс, который раздаёт интернет в локальной сети
- 6 — мой домашний компьютер (основной) — desunote.ru, который раздачей интернета и занимается, то есть работает маршрутизатором
- 7 — eth2, интерфейс подключения к сети Tiera



 Данные обещания надо выполнять, тем более, если они сделаны сначала в
Данные обещания надо выполнять, тем более, если они сделаны сначала в 



 Много статей написано про всем известный Network Time Protocol (NTP), в некоторых из них упоминается про Precision Time Protocol, который якобы позволяет добиться точности синхронизации времени порядка наносекунд (например,
Много статей написано про всем известный Network Time Protocol (NTP), в некоторых из них упоминается про Precision Time Protocol, который якобы позволяет добиться точности синхронизации времени порядка наносекунд (например,