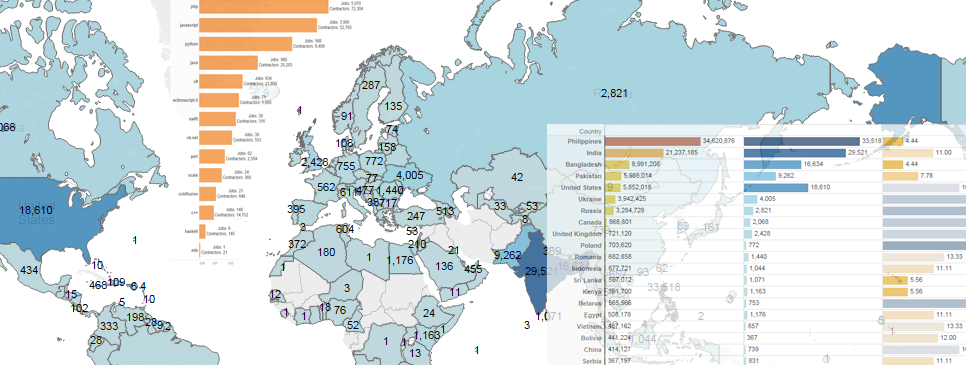
Disclaimer
- Статья не претендует на открытие Америки и носит популяризаторско-реферативный характер. Способы борьбы с NPE в коде далеко не новые, но намного менее известные, чем этого хотелось бы.
- Разовый NPE — это, наверное, самая простая из все возможных ошибок. Речь идет именно о ситуации, когда из-за отсутствия политики их обработки наступает засилье NPE.
- В статье не рассматриваются подходы, не применимые для Java 6 и 7 (монада MayBe, JSR-308 и Type Annotations).
- Повсеместное защитное программирование не рассматривается в качестве метода борьбы, так как сильно замусоривает код, снижает производительность и в итоге все равно не дает нужного эффекта.
- Возможны некоторые расхождения в используемой терминологии и общепринятой. Так же описание используемых проверок Intellij Idea не претендует на полноту и точность, так как взято из документации и наблюдаемого поведения, а не исходного кода.
JSR-305 спешит на помощь
Здесь я хочу поделиться используемой мной практикой, которая помогает мне успешно писать почти полностью NPE-free код. Основная ее идея состоит в использовании аннотаций о необязательности значений из библиотеки, реализующей JSR-305 (com.google.code.findbugs: jsr305: 1.3.9):
- @Nullable — аннотированное значение является необязательным;
- @Nonnull — соответственно наоборот.
Естественно обе аннотации применимы к полям объектов и классов, аргументам и возвращаемым значениям методов, локальным переменным. Таким образом эти аннотации дополняют информацию о типе в части обязательности наличия значения.
 Добрый день, сегодня хотелось бы рассказать, как наша команда работает с базами данных. У нас в компании в основном используется Oracle и в нашей команде много людей, кто умеет хорошо его готовить. Нам изначально хотелось получить полный доступ к его возможностям: иерархическим запросам, аналитическим функциям, передаче объектов и коллекций, как параметров запросов, и, может быть, если не будет другого способа — хинтам. Модель у нас не очень сложная, поэтому сознательно отказались от ORM.
Добрый день, сегодня хотелось бы рассказать, как наша команда работает с базами данных. У нас в компании в основном используется Oracle и в нашей команде много людей, кто умеет хорошо его готовить. Нам изначально хотелось получить полный доступ к его возможностям: иерархическим запросам, аналитическим функциям, передаче объектов и коллекций, как параметров запросов, и, может быть, если не будет другого способа — хинтам. Модель у нас не очень сложная, поэтому сознательно отказались от ORM. В практически любом веб-приложении нельзя обойтись без сторонних javascript-библиотек. Самый простой способ добавить их: скачать и добавить в проект, а также добавить файл в git-репозиторий. Решение годное, но лично для меня наличие в проекте какой-либо статики малость раздражает. Есть другой метод: указывать ссылку на внешний хостинг js-библиотек такой как google, yandex. В принципе вариант, но в моей практике были случаи, когда необходимо было продолжить разработку а доступ в интернет оставлял желать лучшего либо его вообще не было, в итоге клиентская часть не функционировала. Наиболее годным решением мне видится добавления js библиотеки в качестве зависимости в проект, с подобным подходом вы могли сталкивать в Ruby on Rails.
В практически любом веб-приложении нельзя обойтись без сторонних javascript-библиотек. Самый простой способ добавить их: скачать и добавить в проект, а также добавить файл в git-репозиторий. Решение годное, но лично для меня наличие в проекте какой-либо статики малость раздражает. Есть другой метод: указывать ссылку на внешний хостинг js-библиотек такой как google, yandex. В принципе вариант, но в моей практике были случаи, когда необходимо было продолжить разработку а доступ в интернет оставлял желать лучшего либо его вообще не было, в итоге клиентская часть не функционировала. Наиболее годным решением мне видится добавления js библиотеки в качестве зависимости в проект, с подобным подходом вы могли сталкивать в Ruby on Rails.