
В данной статье представлен способ максимально быстро получить результат используя Google Colab в качестве платформы для обучения модели HTR.

Пользователь
В данной статье представлен способ максимально быстро получить результат используя Google Colab в качестве платформы для обучения модели HTR.

Пользователи iFunny ежедневно загружают в приложение около 100 000 единиц контента, среди которого не только мемы, но и расизм, насилие, порнография и другие недопустимые вещи.
Раньше мы отсматривали это вручную, а сейчас разрабатываем автоматическую модерацию на основе свёрточных нейросетей. Систему уже обучили на разделение контента по трём классам: она распознает, что пропустить в ленты пользователей, что удалить, а что скрыть из общей ленты. Чтобы сделать алгоритмы точнее, решили добавить конкретизацию причины удаления контента, у которого до этого не было подобной разметки.
Как мы это в итоге сделали — расскажу под катом на наглядном примере. Статья рассчитана на тех, кто знаком с Python (при этом необязательно разбираться в Data Science и Machine Learning).

Исследователи Google из команды Brain Team поделились своими достижениями в области масштабирования изображений.
Результаты, мягко говоря, поражают...

В этой статье вы узнаете про глубокий нейросетевой подход Neural Radiance Fields — метод для генерации новых изображений сцены с различных ракурсов. Основная задача — интерполяция новых views между исходными оригинальными изображениями для получения “непрерывной сцены” из ограниченного числа фотографий.
Поскольку в нашем стартапе twin3d мы занимаемся созданием фотореалистичных 3D моделей людей, то упор будет сделан именно на фотографии людей. Мы расскажем, какие подзадачи нам пришлось решить, чтобы получить новые фотореалистичные изображения людей с разных ракурсов.

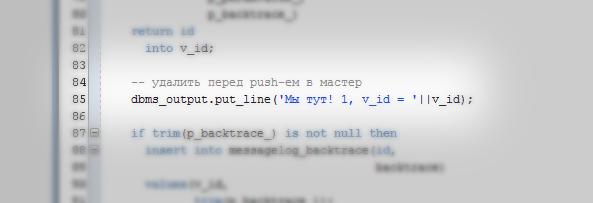
Добрый день! Работая разработчиком Oracle PL/SQL, часто ли вам приходилось видеть в коде dbms_output.put_line в качестве средства debug-а? Стоит признать, что к сожалению, большинство (по моему личному мнению и опыту) разработчиков Oracle PL/SQL не уделяет должного внимания логированию как к «спасательному кругу» в случае возникновения ошибок. Более того, большая часть разработчиков не совсем понимает зачем нужно логировать информацию об ошибках и самое главное, не совсем понимают что делать и как использовать эту информацию в будущем.

На картинке представлен пример обработки одной и той же ошибки. В первом случае ("красный" квадрат) представлен результат стандартной обработки ошибки. Во втором случае ("зеленый" квадрат) представлен результат кодирования ошибок в событийной модели логирования. Помимо информативности текста ошибки для пользователя, мы можем реализовать сбор статистики возникновения ошибки, идентификацию места возникновения ошибки. О том как это можно сделать, постараюсь описать в данной статье.

Я думаю, что все уже знают мое мнение о MERGE и почему я держусь от него подальше. Но вот еще один антипаттерн, который я постоянно встречаю, когда требуется выполнить UPSERT (UPdate inSERT — обновить строку, если она существует, и вставить, если ее нет):

В SQL Server наименьшая единица хранения — это страница в 8 КБ с 96-байтовым заголовком, в котором хранится системная информация.
Данные в таблицах могут быть организованы двумя способами:
Кластерный индекс (clustered index)
Данные хранятся в виде B+ — дерева в соответствии с заданным ключом кластерного индекса. SQL Server сохраняет строки в правильной логической последовательности.
Куча (heap)
Куча — это таблица без кластерного индекса. Данные в куче хранятся без какого-либо логического порядка. Между страницами нет никакой связи. Хотя для кучи можно создать некластерный индекс, который будет содержать физический адрес исходных данных. В некластерном индексе для каждой записи содержится номер файла, номер страницы и номер слота внутри этой страницы.



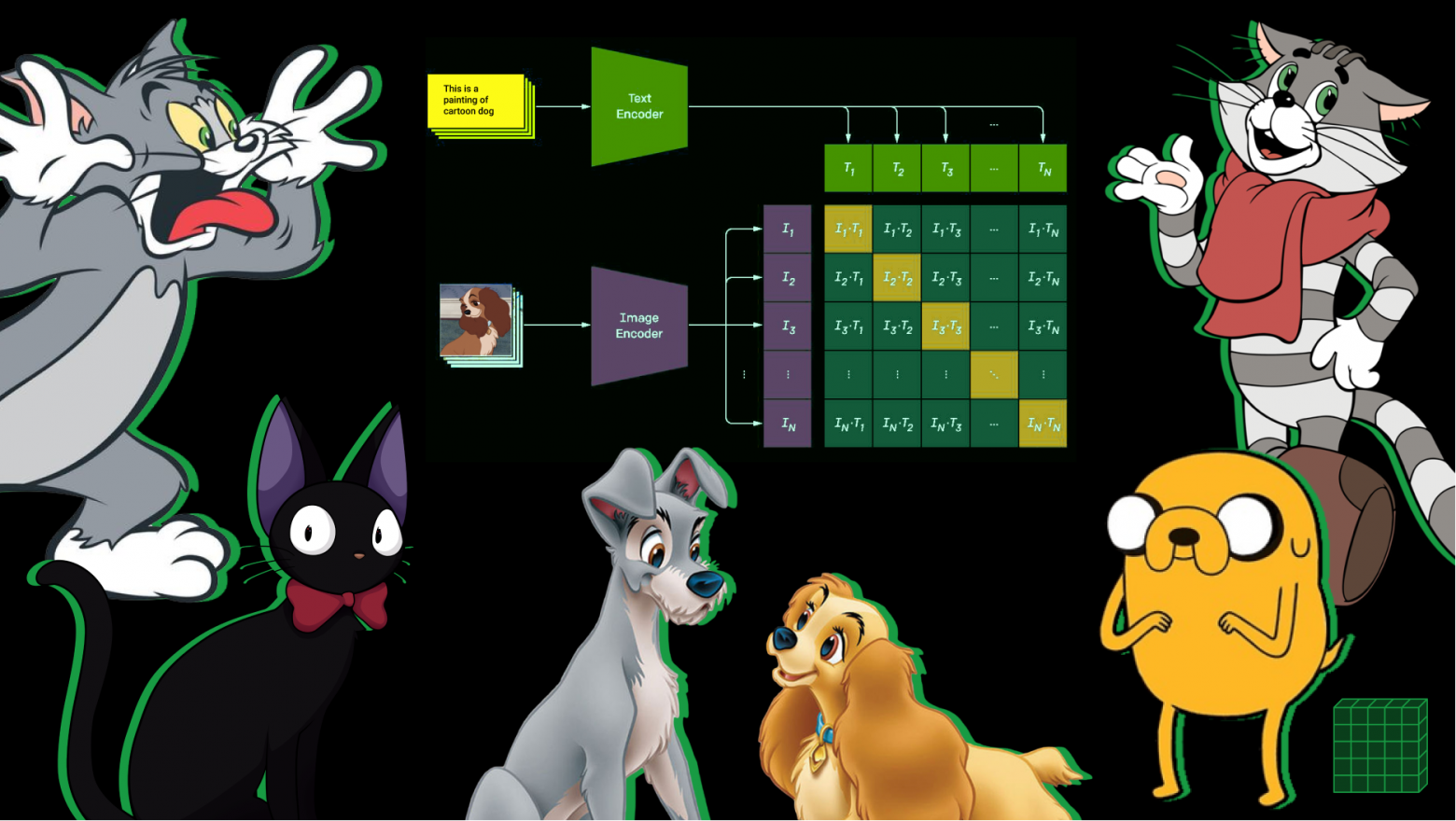
Туториал: Собираем нейронную сеть на примере классификации нарисованных животных в режиме "обучения без обучения".
Цель: Научиться быстро создавать классификаторы для множества задач, без данных и без разметки, используя нейросеть CLIP от OpenAI.
Уровень: Туториал подходит под любой уровень: от нулевого до профи.
Совсем недавно я писал статью про нейронную сеть CLIP от OpenAI — классификатор изображений, решающий практически любую задачу, и который вообще не нужно обучать! Теперь давайте посмотрим, как CLIP работает на практике. Собираем CLIP из рубрики: Разбираем и Собираем Нейронные Сети на примере мультфильмов. На написание кода, и создание готового обученного классификатора у меня, и у любого, даже не знакомого с Python, уйдет именно пять минут. Интересно как? На самом деле все очень просто.
Туториал + Рабочий код: Читай и запускай! Приятного прочтения!

Это третья часть рассказа про опционы, где мы поговорим про биномиальную модель, риск-нейтральную меру и разберёмся, как рассчитать цену опциона.

В своих статьях на Хабре про английский язык мы часто ныряем в исторические дебри. Лингвистика неотрывно связана с историей, и в большинстве материалов есть упоминание про древнеанглийский, среднеанглийский или ранненовоанглийский.
Сегодня мы решили расставить точки над «i» и рассказать про историю английского языка. Как он появился на Британских островах, как развивался и изменялся на протяжении веков. Расскажем, почему исторические названия английского такие странные и чем они отличаются от современного языка. Поехали.
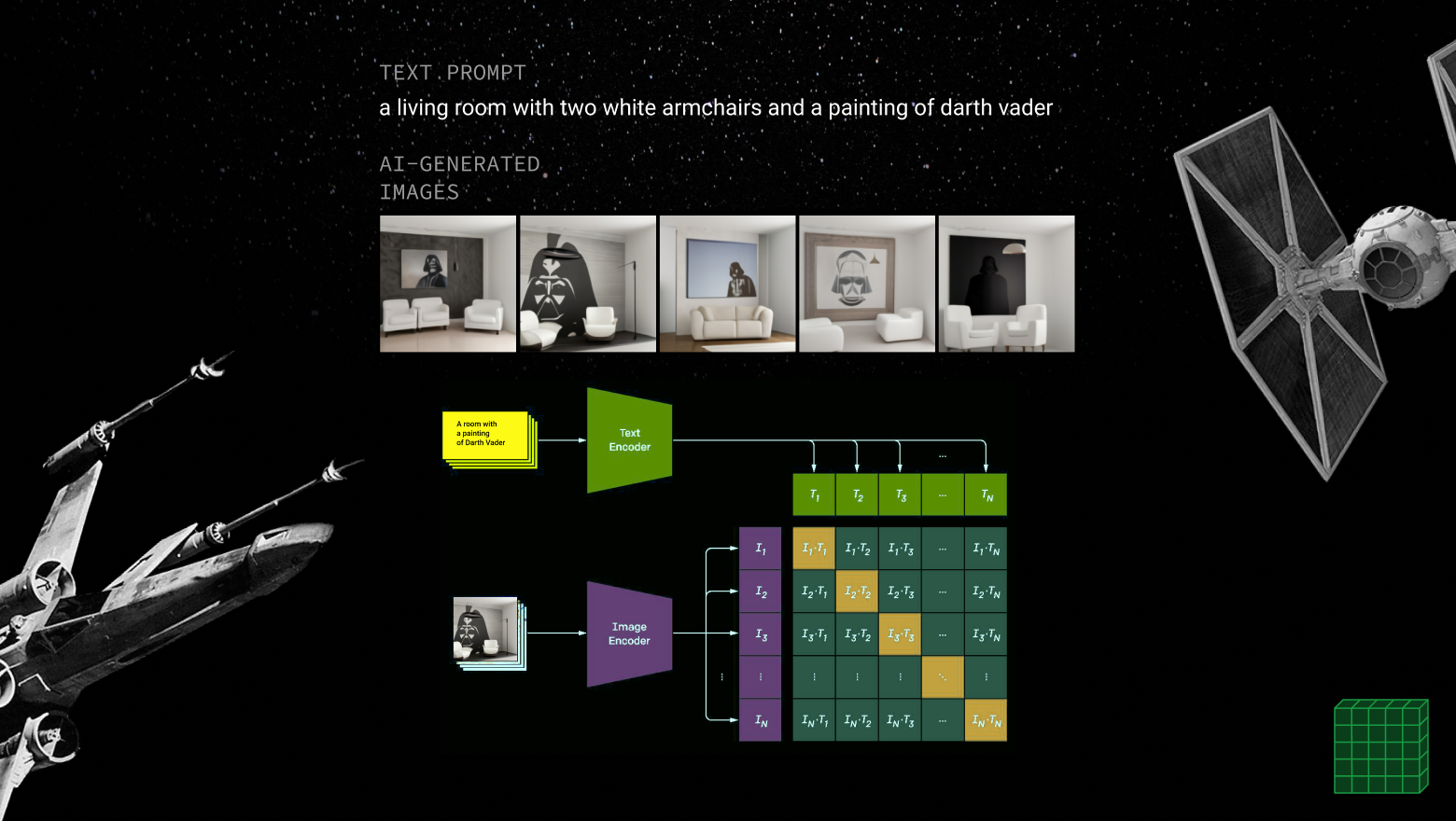
Можете представить себе классификатор изображений, решающий практически любую задачу, и который вообще не нужно обучать? Это новая нейросеть CLIP от OpenAI. Разбор CLIP из рубрики: Разбираем и Собираем Нейронные Сети на примере Звездных Войн!
Нет данных, нет разметки, но нужен классификатор изображений для конкретной задачи? Нет времени возиться с обучением нейронной сети, но нужно получить классификацию высокой точности? Все это стало возможным. Вам нужно обучение без обучения!
Готов и туториал: Собираем нейросети. Классификатор животных из мультфильмов. Без данных и за 5 минут. CLIP: Обучение без Обучения + код
Подробно и доступно разбираем что такое "обучение без обучения" и саму нейросеть CLIP от OpenAI. Стираем границы между Текстом и Изображением. Внимание: статья подходит под любой уровень: от нулевого до профи. Приятного прочтения!
На дворе осень и сын все чаще остается дома, уткнувшись в телефон или планшет, слабо реагируя на внешние раздражители. Меня это огорчает. Сам я начал программировать, как мне кажется, с того, что к моему первому компьютеру БК 0010-01 игры то на кассетах в комплекте шли, а вот магнитофон не шел. Пока добывали магнитофон с подходящим линейным выходом, я успел попробовать Бейсик, спасибо отцу за первые уроки. Так что, когда смог со скрипом загрузить первую графическую игру, то смотрел на нее уже не как на то, во что наконец буду играть, а очарованно думал, как бы сделать свою не хуже. Сына же, в его 8 лет, давно поглотил мир видеоигр и ютуба, так что начинать программирование с трели на встроенном динамике, похоже, впечатления не произведет.