
Самое большое заблуждение начинающих data scientist'ов, или что лучше стоит делать вместо изучения машинного обучения.

backend developer
Самое большое заблуждение начинающих data scientist'ов, или что лучше стоит делать вместо изучения машинного обучения.


Из Википедии веб-краулер или паук – бот, который с просматривает всемирную паутину, как правило, с целью индексации. Поисковики и другие веб-сайты используют краулеры для обновления своего содержимого или индексации содержимого других сайтов.
Давайте начнем!!
Вспомогательный поисковый модуль Metasploit представляет собой модульный поисковый робот, который будет использоваться вместе с wmap или автономно.
use auxiliary/crawler/msfcrawler
msf auxiliary(msfcrawler) > set rhosts www.example.com
msf auxiliary(msfcrawler) > exploitВидно, что был запущен сканер, с помощью которого можно найти скрытые файлы на любом веб-сайте, например:
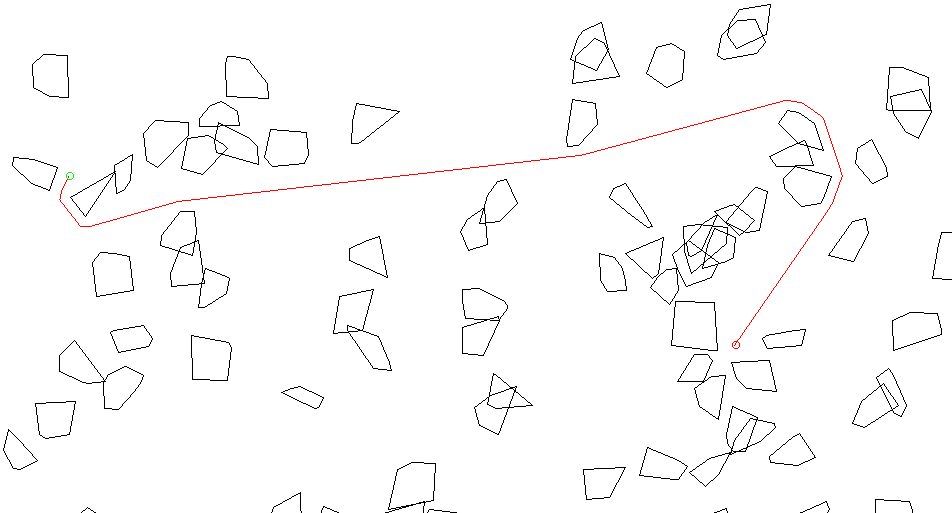
Я недавно сделал маленькую библиотеку для решения задачи поиска кратчайшего пути на 2D карте с выпуклыми препятствиями. В процессе реализации я придумал пару алгоритмов и трюков, описания которых я нигде не встречал. Поэтому делюсь этими "изобретениями" с общественностью.
Горжусь тем, что мое решение работает очень быстро. Для внушительного количества полигонов все операции можно выполнять каждый кадр. Т.е. не надо ничего запекать и вся геометрия карты может меняться в каждом кадре.


Привет, Хабр!
В первой части статьи мы обсудили, зачем может быть необходимо генерировать случайные числа участникам, которые не доверяют друг другу, какие требования выдвигаются к таким генераторам случайных чисел, и рассмотрели два подхода к их реализации.
В этой части статьи мы подробно рассмотрим еще один подход, который использует пороговые подписи.

В этой статье мы попробуем написать классификатор определяющий саркастические статьи используя машинное обучение и TensorFlow
Статья является переводом с Machine Learning Foundations: Part 10 — Using NLP to build a sarcasm classifier
В качестве обучающего набора данных используется датасет «Sarcasm in News Headlines» Ришаба Мишры. Это интересный набор данных, который собирает заголовки новостей из обычных источников новостей, а также еще несколько комедийных с поддельных новостных сайтов.
Набор данных представляет собой файл JSON с тремя столбцами.
is_sarcastic — 1, если запись саркастическая, иначе 0headline — заголовок статьиarticle_link — URL-адрес текста статьи


10 июня компания Digital Security провела онлайн-встречу по информационной безопасности Digital Security ON AIR. Записи докладов можно посмотреть на Youtube-канале.
По материалам докладов мы выпустим цикл статей, и первая из них — об уязвимостях PHP-фреймворков уже ждет под катом.


объем и сложность того, что мы знаем, превзошли нашу индивидуальную способность правильно, безопасно и надежно предоставлять свои преимущества.
Итак, позвольте мне провести вас по этому четкому и краткому списку действий, которые уменьшат вашу рабочую нагрузку и улучшат ваши результаты…

