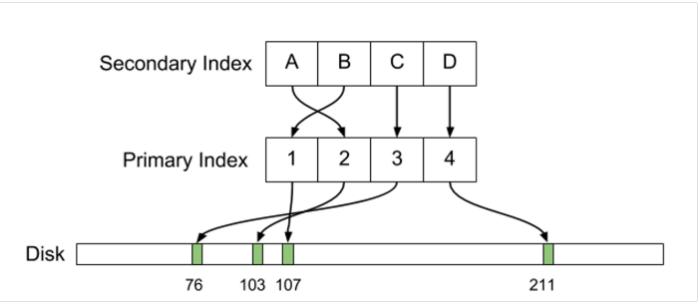
С SSH многие знакомы давно, но, как и я, не все подозревают о том, какие возможности таятся за этими магическими тремя буквами. Хотел бы поделиться своим небольшим опытом использования SSH для решения различных административных задач.
Оглавление:
1) Local TCP forwarding
2) Remote TCP forwarding
3) TCP forwarding chain через несколько узлов
4) TCP forwarding ssh-соединения
5) SSH VPN Tunnel
6) Коротко о беспарольном доступе
7) Спасибо (ссылки)
Оглавление:
1) Local TCP forwarding
2) Remote TCP forwarding
3) TCP forwarding chain через несколько узлов
4) TCP forwarding ssh-соединения
5) SSH VPN Tunnel
6) Коротко о беспарольном доступе
7) Спасибо (ссылки)




 В Java 8 появился новый класс
В Java 8 появился новый класс 


 Автор статьи —
Автор статьи —