С помощью VSTS можно автоматизировать развертывание и тестирование программного обеспечения в различных средах. Суть Continuous Integration заключается в выполнении частых автоматизированных сборок проекта для скорейшего выявления и решения интеграционных проблем. В частности CI позволяет автоматизировать регрессионное тестирование приложений.
В качестве ознакомления с возможностями VSTS предлагаю опубликовать и настроить Continuous Integration c Unit тестами простого UWP приложения.
Здравствуйте! Я работаю проектным менеджером около года. Одни проекты складывались удачно — подводные камни не топили продукт, и теперь он живёт и развивается. Другие сопровождались непрофессиональным поведением и глупыми ошибками.
Однако мне нравится моя работа, и мне не лень покопаться в этих ошибках, чтобы найти их причину. А она, как правило, следующая: кто-то что-то не понял. Разработчик не понял задачу, клиент не понял команду, менеджер не понял смысл проекта, и так далее. Недопонимание ведёт к срыву сроков и бюджетов, к неправильным ожиданиям клиента, к недоумению конечных пользователей и к беспокойному сну менеджера.
Источник недопонимания — отсутствие эффективной коммуникации. Когда её нет, то нельзя построить и эффективную систему назначения и выполнения задач. Своими советами я хочу помочь вам это исправить.
От переводчика: Уже опубликовано много материалов по MVC и его производным паттернам, но каждый понимает их по-своему. На этой почве возникают разногласия и холивары. Даже опытные разработчики спорят о том, в чем отличие между MVP, MVVM и Presentation Model и что должен делать тот или иной компонент в каждом паттерне. Ситуация усугубляется еще и тем, что многие не знают истинную роль контроллера в классическом варианте MVC. Предлагаю вашему вниманию перевод хорошей обзорной статьи, которая многое проясняет и расставляет всё по своим местам.
Современная поисковая система, качество работы которой воспринимается как данность, является сложнейшим программно-аппаратным комплексом, создателям которого пришлось решить огромное количество практических проблем, начиная от большого объема обрабатываемых данных и заканчивая нюансами восприятия человеком поисковой выдачи. На курсе второго семестра Техносферы «Современные методы и средства построения систем информационного поиска» мы рассказываем об основных методах, применяемых при создании поисковых систем. Некоторые из них — хороший пример смекалки, некоторые показывают, где и как может применяться современный математический аппарат.
Авторы курса — создатели поисковой системы на портале Mail.Ru — делятся собственным опытом разработки систем искусственного интеллекта. В курсе рассказывается, насколько интересно и увлекательно делать поисковую систему, решать задачи обработки текстов на естественном языке, а также какие используются методы и средства решения таких задач.
Лекция 1. «Введение в информационный поиск»
Алексей Воропаев, руководитель группы рекомендаций Поиска Mail.Ru, дает определение понятия информационного поиска и делает обзор существующих поисковых систем, рассказывает об индексации и поисковых кластерах.
Это вводная часть материала, основанного на докладе, прочитанном мной прошлым летом. Печатный материал предполагает больше информации, т.к. в одном докладе обычно не получается рассказать обо всех деталях.
Мы разберемся с процессом аутентификации пользователя, работой технологии единого входа (Single sign-on/SSO), дадим общее представлении о технологии OAuth2 и принципах ее работы, не углубляясь в особенности конкретной технической реализации. В следующей статье в качестве примера удачной реализации мы рассмотрим библиотеку Thinktecture Identity Server v3, подробнее остановимся на ее функциональных возможностях, поговорим, как собрать минимальный набор компонент, необходимый для работы в микросервисной архитектуре и достойный использования в боевой системе. В третьей части мы покажем, как расширять эту библиотеку, подстраиваясь под нужды вашей системы, а завершит цикл статей разбор различных сценариев, встречавшихся в жизни многих разработчиков с рекомендациями для каждого случая.
В процессе подготовки задачи для вступительного испытания на летнюю школу GoTo, мы обнаружили, что на русском языке практически отсутствует качественное описание основных метрик ранжирования (задача касалась частного случая задачи ранжирования — построения рекомендательного алгоритма). Мы в E-Contenta активно используем различные метрики ранжирования, поэтому решили исправить это недоразуменее, написав эту статью.
С прошлого митапа про Sphinx прошло уже больше года, так что самое время собраться снова. 18 июня состоится второй SphinxSearch meetup, территориально снова в Avito, регистрируйтесь и присоединяйтесь! Что-то интересное обещают порассказывать Avito, Ozon.ru и Нетология, ну и я тоже буду присутствовать, участвовать и состоять. Опять же пицца, кофе, печеньки. Под катом чуть подробнее о докладчиках и программе. Ну — и куда в точности приходить тоже там!!!
Вот вы там все сидите и ничего не знаете, а мы, тем временем, пилим помаленьку мега-релиз поискового движка Sphinx за номером 3.0. Грядет ряд больших переделок. Часть из них, как полагается, ещё даже как следует не начата. Однако большая часть уже скорее готова, чем нет. А отдельно взятые изменения даже протекли в публичную ветку 2.3. Так что, пожалуй, настало время вкратце начинать рассказывать, чего ожидать в светлом будущем: надеюсь, не столь отдалённом. Кому интересно почитать, все под кат; кому послушать, приходите на meetup в эту субботу. Если совсем вкратце, то: прощай, концепция дополняющего основную базу движка; привет, хранилище документов, тотальный RT, репликация, REST и ряд других известных ключевых слов.
Привет, Хабр. В этой статье я кратко расскажу о деталях реализации микросервисной архитектуры с использованием инструментов, которые предоставляет Spring Cloud на примере простого концепт-пруф приложения.
Код доступен для ознакомления на гитхабе. Образы опубликованы на докерхабе, весь зоопарк стартует одной командой.
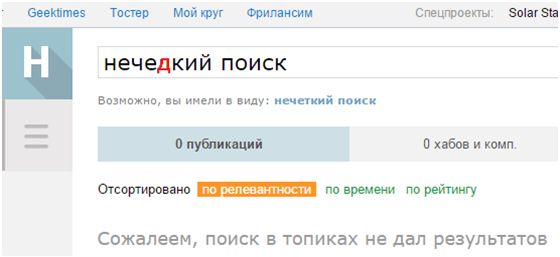
Статья написана об использовании алгоритма вычисления расстояния Левенштейна для нечеткого поиска в тексте, без использования вспомогательного словаря.
Расстояние Левенштейна используется для сравнения двух слов или двух строк, чтобы определить их схожесть. Некоторое время назад передо мной встала схожая задача — в заданной строке искать вхождение слов, словосочетаний и формул, похожих на образец.
В первой части статьи мы рассмотрели универсальный автомат Левенштейна — мощный инструмент для фильтрации слов, отстоящих от некоторого слова W на расстояние Левенштейна не более заданного. Теперь пришло время изучить способы применения этого инструмента для эффективного решения задачи нечеткого поиска в словаре.
В ближайшее время читайте пост о русском переводе долгожданной книги "Создание Микросервисов" Сэма Ньюмена, которая уже отправилась в магазины. Пока же мы предлагаем почитать перевод статьи Аруна Гупты, автор которой описывает самые интересные паттерны проектирования, применимые в микросервисной архитектуре
После прочтения статьи о полезных и бесплатных плагинах для SSMS — TOP (10) бесплатных плагинов для SSMS, я решил поделиться своим списком бесплатных инструментов, которые могут быть очень полезны разработчикам баз данных, и не только. Инструменты ориентированны на разработку под Microsoft SQL Server. Некоторые инструменты, платные, однако содержат достаточно полнофункциональные бесплатные редакции, которых с головой хватает для небольших проектов.
До того, как начать работать с SQL Server я толком то и баз данных в лицо не видел… Помню, что мне установили SQL Server Management Studio 2005 и дали задание активно «крутить педали». По прошествии пары недель, как бы так сказать, моя производительность по написанию запросов была явно в районе плинтуса…
Более опытный коллега с недоумением на меня посмотрел и посоветовал поставить пару плагинов для SSMS… после этого работать стало явно веселее.
В данном посте я хочу поделиться моим топ списком бесплатных плагинов для SSMS, которыми чаще всего пользовался.
Три дня назад я рассказал о тех докладах конференции DotNext 2015 Piter, которые, согласно опросу участников, заняли места с 6 по 10. Теперь пришло время рассказать про лучшую пятерку докладов.
5 место
Кирилл Скрыган, JetBrains — ReSharper vs. Roslyn
Средняя оценка: 4.33
Казалось бы, ReSharper — плагин к Visual Studio, который расширяет возможности IDE. Roslyn — компилятор (набор компиляторов). Что общего?
Дело в том, что для того, чтобы делать все возможные рефакторинги, подсказки и пр., ReSharper строит собственную модель, собственное синтаксическое дерево. А значит, в нем есть, фактически, половина компилятора, компиляторный front-end. А значит, его можно сравнить с фронтэндом Roslyn, что Кирилл и сделал в этом докладе.
Акценты Кирилл расставил не в пользу Roslyn:
ReSharper на 10 лет старше, в нем гораздо больше фич
Roslyn работает только для C# и VB, никаких JavaScript и прочих прелестей
синтаксическое дерево у ReSharper изменяемое и поэтому быстрое, а у Roslyn неизменяемое, генерит много memory traffic и поэтому медленное.
Основной вывод, который сделал я — Roslyn еще пока довольно сырой продукт, а почти все описанные Кириллом болезни — «детские». Пройдет время и наверняка от всех от них Рослин избавится. Ну а что будет на самом деле — покажет время.
Сегодня мы представляем вашему вниманию адаптированную подборку инструментов (в том числе облачных) для разработчиков, которые позволяют создавать по-настоящему качественные проекты. Здесь представлены исключительно SaaS, PaaS и IaaS сервисы, предоставляющие бесплатные пакеты для разработчиков инфраструктурного ПО.
Если вы решили попробовать замечательный язык Go, но не знаете с чего начать, вам прямая дорога в этот пост, где я постарался перечислить все необходимые для новичков ресурсы.
Тестирование с помощью SpecFlow прочно вошло в мою жизнь, в список необходимых технологий для «хорошего проекта». Более того, несмотря на ориентированность SpecFlow на behaviour тесты, я пришел к мысли, что и integration и даже unit тесты могут получить преимущества этого подхода. Конечно, в написании таких тестов уже не будут участвовать люди из BA и QA, а только сами разработчики. Разумеется, что для небольших тестов это привносит немалый оверхэд. Но насколько же приятнее читать человеческое описание теста, нежели голый код.
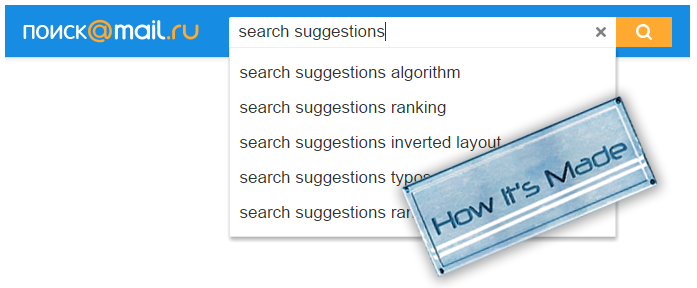
Ночная зала. Тысячи таинственных ликов в темноте, подсвеченных голубоватым свечением мониторов. Оглушительный треск миллиона клавиш. Подобные выстрелам автомата удары по клавишам «Enter». Зловещее стрекотание сотен тысяч мышек… Так, наверняка, играло воображение каждого разработчика высоконагруженной системы. И если его вовремя не остановить, то может выйти целый триллер или фильм ужасов. Но в данной статье мы будем гораздо ближе к земле. Мы кратко рассмотрим известные подходы к решению задачи поисковых подсказок, как мы научились делать их полнотекстовыми, а также расскажем о парочке уловок, на которые мы пошли, чтобы придать им скорости, но при этом не научить жадности к ресурсам. В конце статьи вас ждёт бонус — небольшой рабочий пример.












 Тестирование с помощью SpecFlow прочно вошло в мою жизнь, в список необходимых технологий для «хорошего проекта». Более того, несмотря на ориентированность SpecFlow на behaviour тесты, я пришел к мысли, что и integration и даже unit тесты могут получить преимущества этого подхода. Конечно, в написании таких тестов уже не будут участвовать люди из BA и QA, а только сами разработчики. Разумеется, что для небольших тестов это привносит немалый оверхэд. Но насколько же приятнее читать человеческое описание теста, нежели голый код.
Тестирование с помощью SpecFlow прочно вошло в мою жизнь, в список необходимых технологий для «хорошего проекта». Более того, несмотря на ориентированность SpecFlow на behaviour тесты, я пришел к мысли, что и integration и даже unit тесты могут получить преимущества этого подхода. Конечно, в написании таких тестов уже не будут участвовать люди из BA и QA, а только сами разработчики. Разумеется, что для небольших тестов это привносит немалый оверхэд. Но насколько же приятнее читать человеческое описание теста, нежели голый код.