With the recent progress in Neural Networks in general and image Recognition particularly, it might seem that creating an NN-based application for image recognition is a simple routine operation. Well, to some extent it is true: if you can imagine an application of image recognition, then most likely someone have already did something similar. All you need to do is to Google it up and to repeat.
However, there are still countless little details that… they are not insolvable, no. They simply take too much of your time, especially if you are a beginner. What would be of help is a step-by-step project, done right in front of you, start to end. A project that does not contain «this part is obvious so let's skip it» statements. Well, almost :)
In this tutorial we are going to walk through a Dog Breed Identifier: we will create and teach a Neural Network, then we will port it to Java for Android and publish on Google Play.
For those of you who want to see a end result, here is the link to
NeuroDog App on Google Play.
Web site with my robotics:
robotics.snowcron.com.
Web site with:
NeuroDog User Guide.
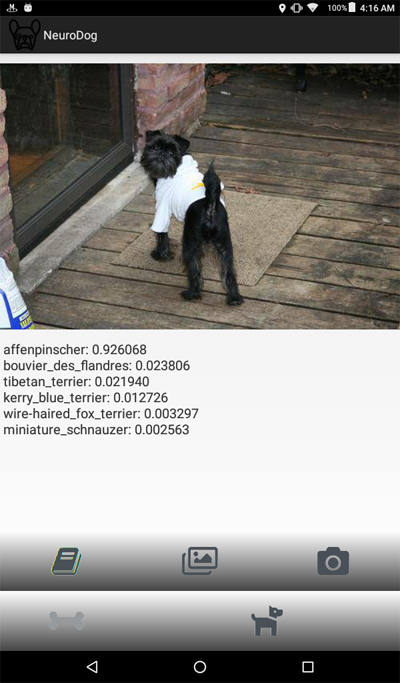
Here is a screenshot of the program: